融合内容特征和时序信息的深度注意力视频流行度预测模型
2021-07-30李泽平杨华蔚王忠德
武 维,李泽平*,杨华蔚,林 川,王忠德
(1.贵州大学计算机科学与技术学院,贵阳 550025;2.贵州财经大学大数据应用与经济学院,贵阳 550025)
0 引言
提前预测视频的受欢迎程度是许多应用的重要部分,如推荐、广告和信息检索等[1]。通过对YouTube 视频网站上的大量用户反馈行为观察发现,部分视频在发布后的一段时间内,经用户反馈后该视频的流行度呈增长趋势。为了捕获视频流行度的动态变化过程,本文首先采用循环神经网络(Recurrent Neural Network,RNN)建模并计算出视频的流行趋势指数,同时离散化视频的点赞量和点踩量,把流行度预测任务转化为分类问题;将视频的流行度分为“受欢迎”和“不受欢迎”两类,采用神经网络模型对视频的内容特征进行建模;最后融合视频的流行趋势和内容特征以预测视频的流行度。
基于用户反馈量的宏观积累过程来预测流行度有很大的实用价值,长短期记忆(Long Short-Term Memory,LSTM)网络能够有效地捕捉事件的变化过程[2],被广泛应用于股票走势预测[3]、温度变化趋势预测[4]以及医学研究中的抑郁趋势预测[5]等。LSTM 网络能够有效地捕捉视频的流行趋势,目前已有研究者采用LSTM 网络对视频的流行动态进行建模和预测流行度,且取得了较好的效果[6]。受到这些研究工作的启发,本文采用LSTM 网络对视频的流行趋势进行建模,捕获视频流行度的变化趋势。
最近,基于深度学习的模型被应用于用户的偏好预测[7]、App的流行度预测[8]、电影的受欢迎程度预测[9]。部分深度学习模型主要分析了内容特征对预测性能的影响[10],而另一部分较为新颖的研究工作则重点关注分类模型的性能[11],其中较为著名的基于深度学习的分类模型是神经网络因子分解机(Neural Factorization Machine,NFM)[12],它比传统的深度神经网络模型具有更优秀的特征表达能力。NFM 是一种新颖的深度学习模型,结合了线性的二阶特征交互和非线性的高阶特征交互,能有效地学习稀疏特征。实际情况下的流行度受外部因素影响容易波动,难以捕捉,但是用户反馈事件的变化趋势在很大程度影响了视频的流行度,NFM 能够有效地学习内容特征,但它不能捕捉内容的流行趋势,因此如何结合视频流行度变化过程和内容特征建模是流行度预测研究工作的难题。
综合分析现有的研究成果可知,流行度动态变化过程难以捕捉,但视频的内容特征对流行度预测模型的性能有很大的影响。目前,联合流行度变化过程和内容特征建模的研究工作较为少见。LSTM 网络应用于流行度的动态变化过程建模具有高效性[13],能够有效捕捉流行度的变化趋势。以NFM为例的基于深度学习的模型有效地结合了线性的二阶特征交互和非线性的高阶特征交互,具有优秀的模型表达和泛化能力,但无法捕获视频的流行度变化趋势。对此,本文提出一种融合内容特征和时序信息的深度注意力视频流行度预测(Deep Attention video popularity prediction model Fusing Content and Temporal information,DAFCT)。该模型融合了视频的内容特征和时序信息,具有优秀的特征表达及泛化能力,并且能够捕获视频的流行趋势。
1 相关工作
1.1 基于LSTM网络的流行趋势预测
基于注意力机制的LSTM 网络减少了对外部信息的依赖[14],已经被广泛应用于文本分类、情感分析、点击率预测等领域。2017 年,Wu 等[15]提出了一个深度时间上下文网络(Deep Temporal Context Network,DTCN),通过对facebook 推文的流行度动态变化过程建模从而预测帖子的流行度,预测结果表明该模型对预测长期的流行动态有显著的能力。2018年,Yuan 等[16]通过将注意力引入LSTM 网络对引文的流行趋势建模,从而预测引文的流行度,在computer science 引文数据集上准确 率可达85%。2019 年,Varuna 等[17]通过分 析Github上项目的Fork、Star等反馈事件,构建了时间序列信息,采用LSTM 网络对Github 上的时间序列信息建模并预测流行趋势。同年7 月,在国际人工智能大会上,Liao 等[18]分析了在线文章的点击量、浏览量、转发量、点赞量等宏观事件发生的次数,将注意力机制引入LSTM 网络对微信文章随时间的变化过程进行建模以预测流行趋势,进一步融合了内容特征,从而预测出微信文章的流行度。该文的流行度趋势建模过程如下,其中,c是当前的视频为注意力权重为序列向量,为隐层输出,为权重矩阵。
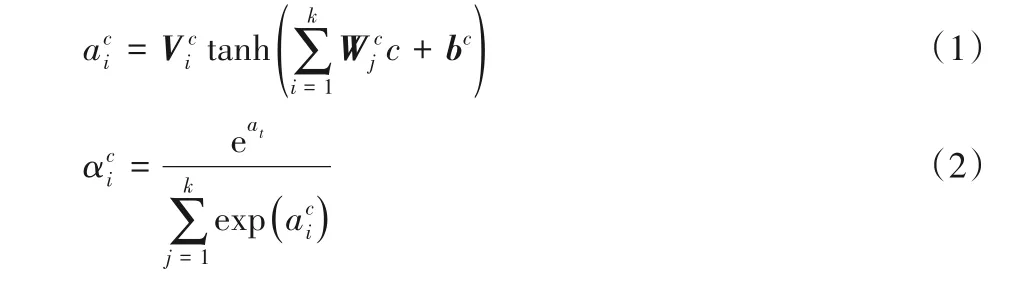

从以上对流行趋势预测的最新研究成果的分析总结可知,LSTM网络能够很好地捕获视频的流行趋势,因此,本文采用了基于注意力机制的LSTM网络来捕捉视频的流行趋势。
1.2 基于深度学习的流行度预测模型
基于深度学习的流行度预测模型自2016 年以来便一直是学术界和工业界的研究热点,对深度学习的流行度预测模型的关注始于2016 年Chen 等[19]提出的基于深度神经网络(Deep Neural Network,DNN)的模型,该模型基于图像像素以及图像描述等内容特征建模,最初应用于广告的点击率预测,后来被广泛应用于流行度预测研究当中。为了提高预测性能,2017 年He 等[20]对深度学习模型进行改进,提出了一个基于神经网络的协同过滤(Neural Collaborative Filtering,NCF)模型,经实验验证NCF 模型的预测准确率达到了87.30%。2019 年,Luo 等[21]提取了新媒体中的政策信息,分析了政策信息中的内容特征,采用DNN 建立了一个基于政策信息的流行度预测模型,实验结果显示该模型优于梯度提升决策树(Gradient Boost Decision Tree,GBDT)模型。基于深度学习的流行度预测模型大多都是基于DNN改进的,计算公式如下:

以上研究成果只基于单个项目的内容特征进行建模,忽略了流行趋势对流行度预测模型性能的影响,在实际情况下视频的流行度常常受到外界因素的干扰不容易建模,因此如何联合内容特征和流行趋势建模是流行度预测研究亟待解决的问题。
2 本文模型
2.1 Attention-LSTM模型
本文采用LSTM 网络捕捉视频的流行趋势,将注意力机制引入LSTM 网络以降低外界因素的干扰,构建了基于注意力机制的Attention-LSTM 模型。为了更形象地表征流行度的增长趋势,本文使用OA-L表示视频流行度的趋势指数,由Attention-LSTM 模型计算可得,Attention-LSTM 模型如图1 所示。通过分析用户的点赞、浏览、评论等反馈信息,给定时间间隔t,将随时间变化的用户反馈量构建为时间序列dt,则得到反馈序列,LSTM网络的计算公式改写为:

图1 Attention-LSTM模型Fig.1 Attention-LSTM model

Attention-LSTM模型计算过程如下:
给定某一时间间隔t,将n个隐层输出记为Hi:

这些隐层输出hi经softmax层后,得到注意力权重:

将注意力权重记为Ai:

则Attention-LSTM模型输出此时的流行趋势:

由上述计算可得OA-L的值为小于1 的数,表征某一视频的流行趋势指数,接下来通过与NFM 模型的预测结果结合,进而计算出视频的流行度。从实验结果来看,Attention-LSTM模型能够有效地捕获视频的流行趋势,且对提高流行度预测模型的性能有很大帮助。
2.2 NFM模型
视频的内容包括视频类型和数值信息,通常能为流行度预测提供有用的信息,是影响视频流行度的关键因素之一。针对不同类型的视频,不同用户的喜好不同,用户的反馈表现则截然不同。本文采用NFM 模型对视频的内容特征建模。NFM 模型首先采用one-hot 编码技术将类型特征转换为onehot 向量,然后将视频类型的one-hot 向量输入到NFM 模型的嵌入(embedding)层,接着视频类型特征和数值特征通过一个二阶特征交互池层组合,输入隐藏层后由激活函数计算得到输出结果。NFM 模型结合了线性的二阶特征交互和非线性的高阶特征交互,能够从稀疏数据中学习特征,有效地提高了特征的表达能力。图2 给出了用于内容特征学习的NFM模型。

图2 NFM模型Fig.2 NFM model
例如,给定视频类型的集合为M={m1,m2,…,mk},对于第i(i=1,2,…,k)个视频mi的类型,将视频类型的one-hot 特征向量x使用嵌入技术进行降维后得到视频类型的embedding向量表示:

其中:λi为第i个视频类型的embedding 向量,xi为第i个视频类型的one-hot向量。
将embedding向量νx输入到二阶交互层:


其中:σ、WL、bL分别为sigmoid函数、隐藏层的权重矩阵和偏置向量,L为隐藏层的层数。
将隐藏层的输出yL输入到全连接层后得到NFM 模型的输出:

2.3 DAFCT
流行度变化过程中的时序信息难以捕获,而视频的内容特征很大程度上决定了视频的流行度,是流行度预测任务必不可少的条件。本文的DAFCT 首先采用RNN 挖掘时序信息以捕获视频的流行趋势,引入注意力机制排除外界因素的干扰;然后采用深度神经网络处理内容特征,针对稀疏的高维特征则采用嵌入技术进行降维以降低模型的计算复杂性;最后,使用concatenate 方法融合时序信息和内容特征。本文DAFCT如图3所示。
如图3给定n个视频,用pi表示视频的流行度,将所有的n个流行度pi表示为P:

图3 DAFCT结构Fig.3 DAFCT structure

式(21)为视频的点赞概率,即为视频的受欢迎程度。结合2.1 节Attention-LSTM 模型的流行趋势 和2.2 节NFM 模型的输出,经一个全连接层计算:

其中:OA-L为视频的流行趋势指数,ONFM是NFM模型的预测结果。代入式(21)后得到流行度:

下面说明DAFCT的信息融合过程及应用:
1)内容特征和时序信息嵌入。本文的研究工作将视频的统计信息分为时序信息和视频的内容,其中时序信息为给定时间间隔t内的用户反馈序列,视频的内容包括视频类型等信息。进行实验验证时,模型训练的时序信息对应的特征为时序特征,视频的内容则对应内容特征,视频的内容包括视频类型等特征。由图3 可知,DAFCT 使用了嵌入技术对高维的特征降维,从而得到低维的稠密特征。假设当前视频有7 种类型,这7 种视频类型表示为{0,1,2,3,4,5,6},如果第i个视频的类型为5,在数据预处理阶段使用one-hot 编码技术得到该视频的类型x=[0,0,0,0,0,1,0],由此得到一个稀疏的向量,而在实际情况中的数据维度往往是非常巨大的,直接输入模型会影响预测性能。针对这种情况,定义一个嵌入(embedding)向 量em=[0,0.1,0.25,0,0,1,0],则m·(em)T=[0.5],可以看到这个值表征了该视频所属的类型。本文只是做了简单的假设,实际情况下的视频类型远远多于这个设定,数据维度往往大得多,计算复杂度高,嵌入向量是根据实验而设定的,各不相同。由此可知使用嵌入技术能有效降低特征向量的维度。
2)信息提取。由图3 可知,DAFCT 的流行度趋势捕捉过程和视频的内容特征处理过程是并行的。Attention-LSTM 模型首先根据输入的时序信息提取时序特征,输入的时序特征经遗忘门后通过一个sigmoid 函数计算出要丢弃的时序信息,然后根据要丢弃的信息更新旧的细胞状态;同时通过输入门将细胞存储的候选信息添加到新的细胞ct中将时序信息存储下来;最后通过输出门输出视频的流行趋势,计算过程如2.1节所示。NFM 模型首先通过一个特征的二阶交互层,使得视频类型与其他内容特征如视频id 等特征之间进行了交互组合,然后将这些组合的特征输入到隐藏层学习内容特征,最后通过一个激活函数输出预测结果,计算过程如2.2节所示。NFM 主要是对组合的特征学习,而不是单一的特征,使用了2 层隐藏层,相对于其他基于神经网络的模型更浅,有效地提高了模型的预测性能。
3)信息融合。如图3 所示,DAFCT 使用了concatenate 方法将Attention-LSTM 模型捕捉的流行趋势和NFM 模型挖掘的内容特征融合起来,计算公式为,其中OA-L为Attention-LSTM模型的输出,ONFM为NFM模型的输出。
4)DAFCT 的应用。为了验证DAFCT,本文设计了深度注意力视频流行度预测(Deep Attention Video Popularity Prediction,DAVPP)算法求解该模型,并应用于视频的流行度预测。
算法1 DAVPP算法。
输入 历史反馈序列dt,t-1 时刻的时序特征xt-1,经one-hot 技术编码后的内容特征向量x,权重矩阵W和U,偏置向量b,视频类型mi;
输出 流行度pi。

3 实验与结果分析
实验的硬件平台:Dell 服务器6 个CPU 核心,1 颗Nvidia Geforce Raytracing 2080 共享GPU 核,内存32 GB,显存11 GB。软件环境:服务系统Ubuntu16.04,终端系统Windows 10,编译平台Pycharm Profession,Python 3.7,TensorFlow 1.9.0。
3.1 数据预处理
实验采用kaggle(https://www.kaggle.com)平台的YouTube 视频数据集,该数据集是情感分析、文本分类、流行度分析、时间序列变化分析以及训练机器学习算法研究的国际常用数据集之一。本文选取了数据集中2018 年5 月13 日到8 月26 日的历史数据作为数据集,数据预处理分为以下三个部分:
1)时间序列特征构建。
本文的Attention-LSTM 模型主要用于捕获视频的流行趋势,因此在构建时间序列时以view、like、dislike、video_id 等特征构建了时间序列,没有考虑这些操作数的变化规律是否具有周期性。
构建的宏观时间序列为:从数据集中抽出每隔一天的view、like、dislike、video_id 操作数作为宏观时间序列来计算,并将这些数据按照时间顺序进行排序,加上video_id 后得到时间序列数据集。
2)内容特征。
为了保证实验的有效性,内容特征的选取在时间上与时序特征同步,内容特征包括publish_time、video_type、channel、video_id和describe,内容特征的预处理步骤如下:
步骤1 对每个样本计算点赞量与点赞量和点踩量之和的比值,得到的结果若大于0.5,则认为该视频内容是受用户欢迎的;反之则认为该视频不受欢迎。
步骤2 将视频的受欢迎程度分为两类:“受欢迎(1)”和“不受欢迎(0)”。
步骤3 去除数据集中特征取值相同的字段,这些字段会对流行度预测效果产生干扰。
最后,为了使得正负样本平衡,分别采用了上采样和降采样的方式对数据集做了处理,但从实验效果来看降采样方式最佳,于是最终本文采用了降采样方式对数据集做了处理,得到了20 000个正样本和20 000个负样本。最后选取数据集的前80%作为训练集,剩下的20%作为测试集。
3.2 评估指标
本文使用准确率(Acc)、召回率(re)和F1 分数(F1)3 个指标评估DAFCT 的性能。给定训练集V={v1,v2,…,vn},正样本集为,负样本集为FA=,准确率是评估模型整体性能的指标,表示模型预测正确的样本数占所有样本数 |V|的比例:

其中:X表示实际vi∈TR,且DAFCT 算法预测所得为vi∈TR的样本数量;Y表示实际vi∈FA,且DAFCT 算法预测为vi∈FA的样本数量。
召回率表示在所有的实际正例中,被正确预测的样本有多少:

其中:Z表示实际vi∈FA,而DAFCT 算法预测为vi∈TR的样本数量。F1分数表示综合了准确率和召回率之后的性能指标:

其中pre为精确度,表示被分为正例的样本中,实际为正例的比例:

其中:U表示实际vi∈TR,而DAFCT 算法预测为vi∈FA的样本数量。
3.3 实验设置
在使用Attention-LSTM 模型挖掘时序信息以捕捉视频流行趋势时,采用了神经元为128 的单层LSTM 网络;使用NFM模型学习内容特征时,DNN 隐藏层的神经元个数为128,激活函数使用的是ReLU,同时利用L2 正则化对模型参数进行约束;DAFCT 训练过程中的batch size 取1 024,模型在训练过程中训练了60 个epoch,输出层的激活函数采用sigmoid 函数。实验流程如图4所示。

图4 实验流程Fig.4 Experimental flow
3.4 实验与结果分析
为了便于观察模型的预测效果,实验分别与Attention-LSTM模型和NFM模型做了对比。
图5是DAFCT 与Attention-LSTM 模型和NFM 模型的准确率、召回率和F1 分数对比。其中:DAFCT 的准确率、召回率、F1 分数的均值分别为0.892 6、0.780 3、0.765 3;Attention-LSTM 模型的准确率、召回率、F1 分数的均值分别为0.756 9、0.672 1、0.667 3;NFM 模型的准确率、召回率、F1 分数的均值分别为0.844 7、0.747 2、0.734 6。与Attention-LSTM 模型相比,DAFCT 的召回率和F1 分数分别提高了10.82、9.80 个百分点;与NFM 模型相比,召回率和F1 分数分别提高了3.31、3.07 个百分点。由此可见,Attention-LSTM 模型的整体性能不如NFM 模型和DAFCT,虽然Attention-LSTM 模型能够有效地捕获视频的流行趋势,但对时间序列数据要求严格,而且特征的表达能力有限;而NFM 模型虽然特征的表达能力强,但不能有效地挖掘视频的流行趋势,也存在一定缺陷。从实验结果来看,结合二者能够有效地提高流行度预测模型的性能。

图5 三个对比模型的召回率、F1分数和准确率对比Fig.5 Comparison of recall,F1 score and accuracy of three comparison models
从图6 可以观察到,整体上Attention-LSTM 模型的F1 分数最小,DAFCT 的F1 分数最大。Attention-LSTM 模型在第17个epoch 时F1 分数突然增长,第19 个epoch 时突然下降,而后便一直增长,但增速不高,在第56 个epoch 达到平稳,可以看出此时Attention-LSTM 模型开始收敛;NFM 模型在第9 个epoch 时F1 分数突增到0.734 0,在第10 个epoch 时增长至最大值0.738 2 后在第11 个epoch 时降低,而后的几个epoch 内都呈增长趋势,到了大约第17 个epoch 时突然下降并在接下来的几次训练过程中有轻微波动,在第31 个epoch 时趋于稳定,逐步收敛;而DAFCT 在第7 个epoch 前的F1 分数波动较大,由图6 可清晰观察到从第7 到16 个epoch 过程中的F1 分数的增速最快,第17 个epoch 之后增速平稳,约第30 到48 个epoch过程中出现轻微的起伏,而后稳步收敛。由以上分析可知,从评估指标F1 分数来看,与Attention-LSTM 模型相比,本文的DAFCT 的特征学习能力更强,虽然DAFCT 的学习速度没有NFM模型快,但DAFCT更稳定,且整体性能更好。

图6 三个对比模型的F1分数对比Fig.6 Comparison of F1 scores of three comparison models
表1 显示了DAFCT 和其他多种模型的预测性能对比,包括逻辑回归(Logistic Regression,LR)[22]分类器、NFM 模型、随机森林(Random Forest,RF)[23]分类器、支持向量机(Support Vector Machine,SVM)[24]、Attention-LSTM 模型。基于神经网络的预测模型大多是由LR 演进而来,LR 通过给特征赋予权重因子来对样本进行分类;NFM 模型通过引入一个二阶交互层使得线性特征和非线性的高阶特征交互来提高模型的特征表达能力;RF 模型是基于决策树的分类器,它结合了多棵树对样本进行训练;SVM是基于特征空间的线性分类器,通过最大化特征的间隔距离将分类问题转化为凸二次规划问题求解;Attention-LSTM是基于循环神经网络的一种特殊的神经网络,通过引入注意力机制过滤掉无关信息。本文的DAFCT 通过引入Attention-LSTM 网络捕获视频的流行趋势,引入NFM模型处理内容特征,此外还引入了注意力机制使得特征的重要程度都能体现,从而达到了更好的预测性能。从实验结果可以看出本文提出的DAFCT 在性能整体上明显优于对比模型。
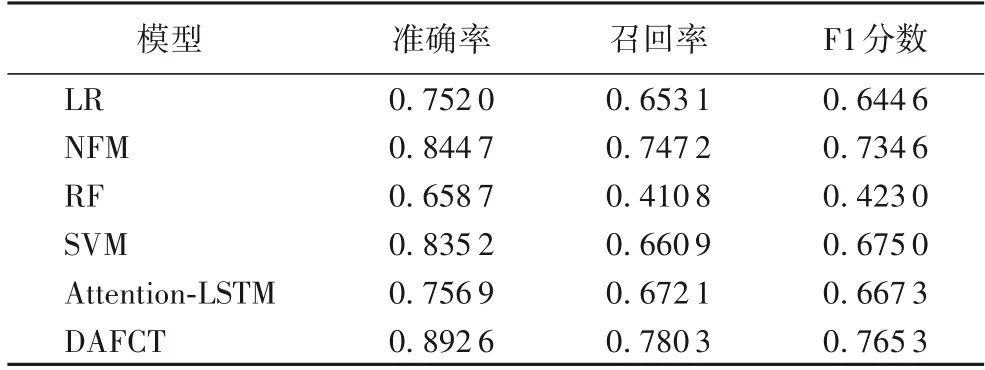
表1 所提模型与其他模型的预测性能对比Tab.1 Prediction performance comparison of the proposed model and other models
为了观察LR、NFM、RF、SVM、Attention-LSTM 和DAFCT的整体分类性能,绘制了各模型的准确率,如图7 所示。从图7 可以看出,RF 模型的分类性能较低,而本文的DAFCT 的性能最好。RF模型开始的学习速度最快,但很快就收敛且增速呈下降趋势;LR 模型的学习速度相对来说较为缓慢;SVM 和NFM 模型虽然稳定,但分类的准确率没有DAFCT 高。由图7清晰可见,本文提出的DAFCT 在训练过程中学习速度快且准确率高。

图7 各对比模型的准确率对比Fig.7 Accuracy comparison of models
基于视频内容特征的分类器性能很大程度上依赖于提取的内容特征,并且预测效果受到限制。Attention-LSTM模型对时间序列要求严格,因此只能捕获视频的流行趋势,模型的特征表达能力较差,从以上实验结果来看存在的缺陷还比较大;基于内容特征的分类器如NFM、LR、RF 等则无法捕捉视频的流行趋势。与其他分类器相比较,本文的DAFCT 能够有效地捕获视频的流行趋势,并且能够有效提高流行度预测模型的性能,且特征的学习和表达能力更强。从以上实验结果分析可知,用户反馈事件的积累量能够有效地表达视频的流行趋势,而且能够帮助提高流行度预测模型的性能,即这些用户反馈的时序信息是影响流行度的重要因素;除此之外,内容特征很大程度上影响了流行度预测模型的效果,是流行度预测研究工作当中必不可少的,因此结合二者才能够使得流行度预测模型的性能更佳。
4 结语
本文提出一种融合内容特征和时序信息的深度注意力流行度预测模型DAFCT,能够有效地表达视频的流行趋势且提高流行度的预测性能。为了排除外界因素的干扰,增加了注意力机制,采用Attention-LSTM 模型挖掘时序信息以捕捉流行趋势,利用NFM 模型处理内容特征,模型成功地捕捉了流行趋势并得到了较好的预测性能。实验结果显示,本文的DAFCT 的分类性能优于其他分类器,但也可以看出本文设计的Attention-LSTM 模型存在局限性,在今后的研究工作当中,将会进一步把模型应用在其他领域,探索该模型存在不足的原因并进行改善;另外,还将对DAFCT 的应用及模型的高效求解算法做进一步的研究。
