一种基于深度学习的驾驶员打电话行为检测方法*
2021-07-29代少升黄向康王海宁
代少升,黄向康,黄 涛,王海宁,梁 辉
(1.重庆邮电大学 通信与信息工程学院,重庆 400065;2.东北大学 计算机科学与工程学院,沈阳 110167)
0 引 言
随着智能手机在日常生活中的频繁使用,驾驶途中的打电话行为越来越多。研究表明,开车打电话会导致驾驶人注意力下降20%,如果通话内容很重要,则驾驶人的注意力会下降37%[1]。因驾驶员打电话导致的道路交通事故报道不时见诸新闻[2],而且开车时打电话亦是违反交通法的行为,因此能实时准确地对驾驶员打电话行为进行检测并预警具有很大的市场需求[3]。
目前,对驾驶员打电话行为检测的方法主要分为两种:一种是基于手机信号检测,另一种是基于机器视觉检测。基于手机信号检测是通过监测手机信号的变化来确定驾驶员是否在打电话,因为接打电话时的手机功率相较于待机状态更强。Rodriguez[4]等人通过在固定区域安装天线,监控行驶中车辆上的手机信号来判断驾驶员打电话行为,但此方法容易受到乘客手机信号的干扰,误检率较高。
基于机器视觉的检测方法是通过分析采集到的驾驶室视频,运用图像处理算法监测是否存在打电话行为[5]。王丹[6]通过将驾驶员行为分解为一系列包含时序关系的原子动作,如手部动作、头部姿势等多项信息,再由此来综合判断打电话动作,但检测结果在头部偏转和光照比较强烈时误差较大。吴晨谋等人[7]基于人体三维姿态估计的方法,获取驾驶员上半身的8个骨骼节点的三维坐标,对驾驶员的行为识别分析,以此判断驾驶员是否接打电话。李兆旭等人[8]提出的基于局部二值模式(Local Binary Pattern,LBP)特征和极端梯度提升(eXtreme Gradient Boosting,XGBoost)级联分类器的手机检测算法,对手机的识别率达到不错的检测效果,但非驾驶员的打电话行为以及车内其他位置的手机都会对检测结果产生干扰,无法准确判别是否出现驾驶员打电话。张波等人[9]综合灰度共生矩阵(Gray-level Co-occurrence Matrix,GLCM)与方向梯度直方图(Histogram of Oriented Gradient,HOG)提取图像特征确定手部位置,最后运用模式逻辑判别打电话行为。王尽如[10]采用支持向量机(Support Vector Machine,SVM)算法来进行检测,但该方法受驾驶环境影响较大,误判率比较高。熊群芳等人[11]采用渐进校准网络算法和改进YOLOV3算法判断驾驶员是否处于打电话状态,虽然该方法能达到较高的检测准确率,但多层卷积神经网络算法中包含大量的矩阵运算,只适用于配备GPU等计算加速模块的PC端使用。现有检测方法都存在一定缺陷,包括检测准确率低、无法检测免提接听电话行为、对设备性能要求较高、检测速度慢等问题。
为解决上述缺陷,本文采用改进多任务卷积神经网络(Multi-task Convolutional Neural Network,MTCNN)算法检测人脸[12],并根据人脸坐标通过浅层卷积神经网络进行手持电话行为检测,同时根据脸部关键点由级联形状回归算法得到嘴巴特征点及其宽高比来进行讲话行为判别,然后使用交叉验证法训练优化模型,最终将两种行为的检测结果相“与”的方法进行驾驶员打电话行为判别。另外,此套方案已成功加载至CEVA DSP硬件平台,进一步验证了算法在实际驾驶场景下的检测效果。
1 驾驶员打电话行为检测方法
本文所采用的驾驶员打电话行为检测方法可同时检测听筒和免提接听两种状态,并融合手持电话与讲话两种行为的检测结果,作为最终的打电话行为判别结果。其检测流程如图1所示。
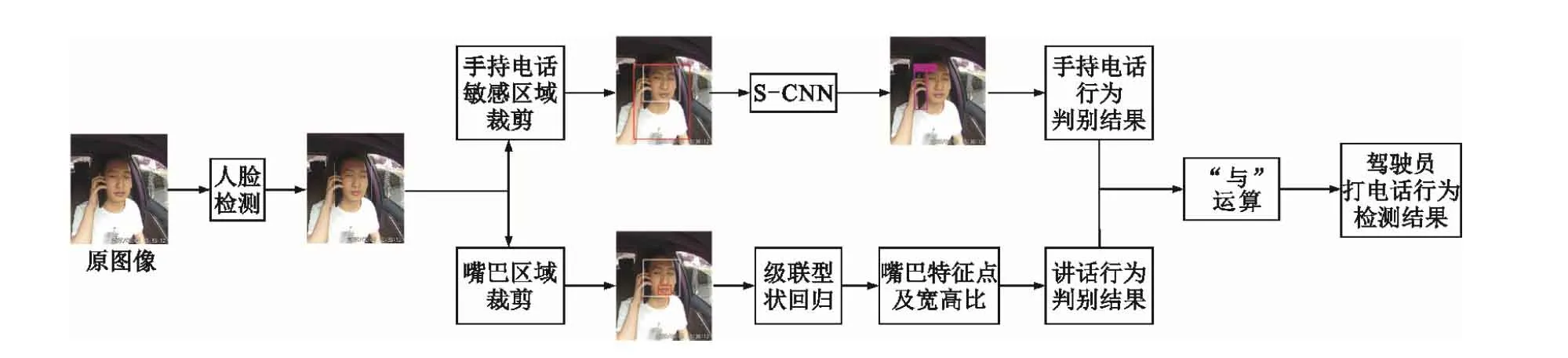
图1 算法流程图
1.1 驾驶员人脸检测
针对DSP端的处理器性能、内存大小等限制[13],本文使用优化后的级联卷积神经网络算法来检测图像中的人脸及面部关键点,其中框架采用的是基于NCNN的卷积神经网络架构。NCNN框架是腾讯公司专门为移动端设计优化的一个高性能神经网络前向计算框架,它具有纯C++实现利于跨平台、计算速度快、内存占用低、无需借助GPU加速以及自带库体积小等优点,利于ARM、DSP等嵌入式平台开发使用[14]。
人脸检测算法采用级联卷积神经网络算法,该算法借鉴MTCNN(Multi-task Convolutional Neural Network)人脸检测算法[15],将MTCNN算法改进后用于驾驶员人脸检测。其检测顺序如下:对输入图像做相邻帧对比→图像金字塔→P-Net(Proposal Network)→人脸框初步判别→R-Net(Refine Network)→人脸框二次判别→O-Net(Output Network)→人脸框信息与面部5个特征点坐标。
相比较于MTCNN检测算法,改进后的人脸检测算法针对驾驶室环境做了特殊处理,主要包括以下几点:
(1)由于开车过程中驾驶员的脸部位置一般移动较少,因此本文将新一帧的待检测图像与上一帧图像在人脸框区域进行差异度对比,若重复度大于85%,则延续使用上一帧图片的人脸检测结果,否则重新进行人脸检测。
(2)由于驾驶座位前后可调整范围较小,因此在摄像头所采集图像中驾驶员人脸大小变化不大,所以图像金字塔的构建本文只使用三层缩放,缩放比例依次为上一层的0.8倍,来减少多层缩放导致的计算量增加。
(3)在前两层级联CNN网络后分别加入人脸检测框判别,只有当本层网络的检测结果中包含疑似人脸框时才进行之后的运算,否则便终止此帧图像的检测流程,开始新一帧图像的检测,如此便能减少大量非必要的运算,降低算法冗余度。
通过上述步骤加速优化后的人脸检测算法相较于MTCNN算法既保证了人脸检测的高准确率,同时使检测速度平均提升了7倍,极大限度地提高了检测效率。
1.2 手持电话行为判别
本文采用浅层卷积神经网络[16]S-CNN进行特征提取并判别检测手持电话行为,其中不仅包括正常的听筒接听电话状态,还包括免提接听状态。该方法首先根据前一部分检测到的人脸框坐标及大小裁剪脸部两侧及下方区域作为手持电话行为待检测区域,然后对待检测图像通过S-CNN进行特征提取以及行为分类判别。
待检测区域指的是用于判别驾驶员手持电话行为的图像区域。驾驶员在打电话过程中可能会采取两种方式:一种是听筒接听,此方式一般手握电话靠近耳旁进行通话;另一种是免提接听,此方式一般会手握电话于脸部下方区域接听电话。故本文通过裁剪两侧耳旁及脸部下方区域图像来进行手持电话行为检测。根据第一部分人脸检测框的坐标及大小,裁剪出的手持电话行为待检测区域如图2中红框区域所示。

图2 手持电话行为待检测区域
对此区域图像,本文参考AlexNet[17]和VGG[18]等网络来构建轻量级卷积神经网络,旨在减少卷积参数及计算量;同时,由于卷积神经网络的浅层网络所提取到的特征图,感受野更加关注的是图像中形状、纹理等特征。而手持电话行为含有丰富的边缘特征信息,手机与手部相结合的形状特征明显,这对于手持电话行为的判别非常重要。由于光线变化或车辆后排物体的影响,可能导致手持电话的颜色及大小与所处背景相近,进而提取出的候选区域可能不是手持电话图像而是背景图像,为此,我们将待检测区域图像均调整为32 pixel×32 pixel大小送入网络,将非手持物品行为的图像剔除。
针对32 pixel×32 pixel的输入图像,对其进行多层卷积、池化等操作,并将全部卷积层的输出特征进行可视化显示,以观察各层的处理效果及最终的分类结果。经过可视化后发现,卷积层第1层是各种边缘探测器的集合,几乎保留了原始图像中的所有信息,而随着层数的加深,卷积层所提供的特征越来越抽象,即视觉可观察到的信息越来越少,关于类别的信息越来越多,但训练参数也更多,计算量与过拟合风险增加。最终,本文采用5个卷积层与2个全连接层构建一个轻量级卷积神经网络S-CNN分类器,对于其中的每个卷积层,分别对上层通道的图像四周补0,采用卷积核大小均为3×3,通过设置不同的步长提取边缘信息,对于下采样操作设置步长为2,其他为1,激活层均采用ReLu函数。该网络的结构图如图3所示,每一卷积层运算后的可视化二维特征图如图4所示。
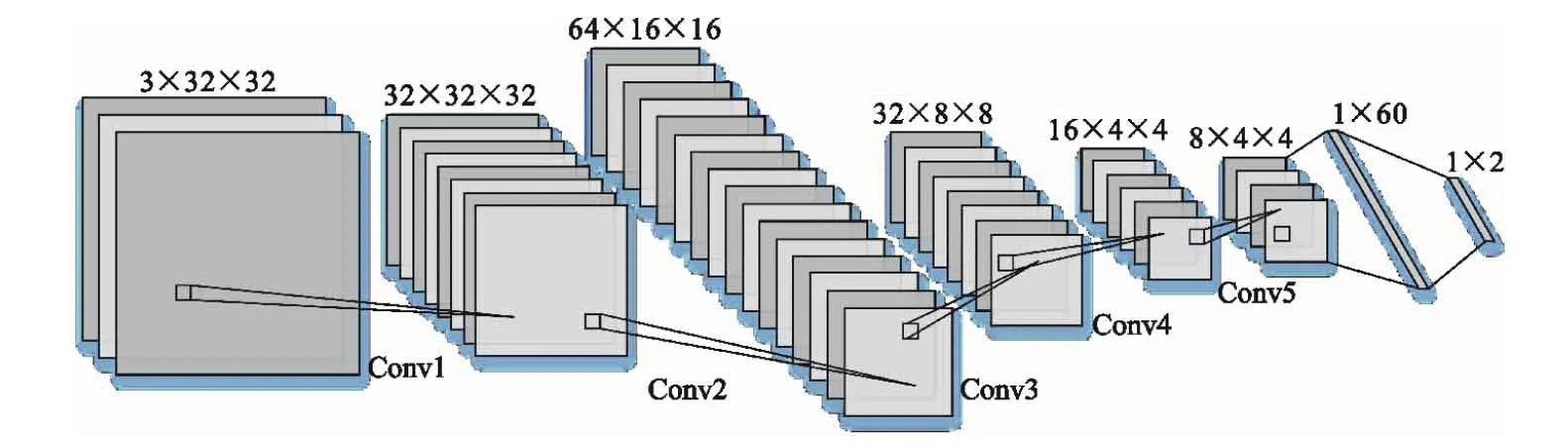
图3 S-CNN网络

图4 S-CNN网络各卷积层可视化二维特征图
由于是二分类任务,因此损失函数采用的是Sigmoid交叉熵损失,其计算公式如式(1)所示:
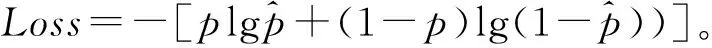
(1)
S-CNN网络经过数据集训练后,在测试视频中的检测效果如图5所示,包括听筒和免提两种接听状态。

图5 手持电话行为检测效果图
1.3 驾驶员讲话行为判别
针对驾驶员讲话行为,本文主要利用嘴巴宽高比的变化来检测[19]。首先,根据人脸检测所得到的基本特征点,其中主要用到左右嘴角特征点和鼻尖特征点,裁剪获取嘴巴区域的图像,并通过级联形状回归算法[20-21]来得到嘴巴的全部特征点,得到的特征点预测形状如图6所示,其中包括三种状态:正常状态、讲话状态和打哈欠状态[22]。
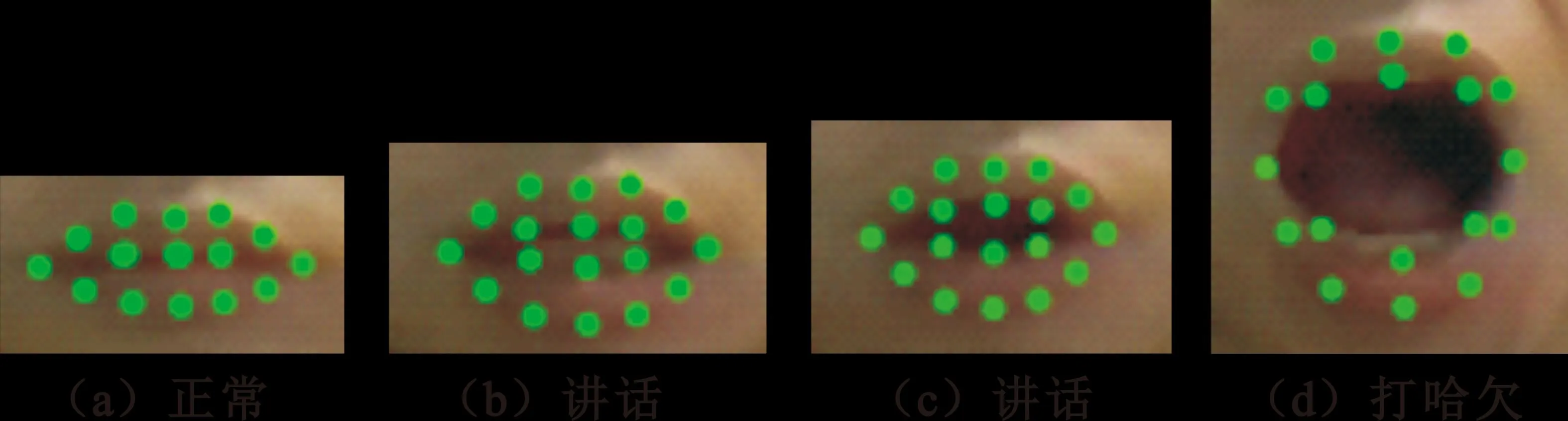
图6 不同状态嘴巴特征点预测图
之后根据特征点计算嘴巴的宽高比,其中宽高比计算中,宽是嘴角两点的距离,高是上下嘴唇相对应的8组特征点距离的均值。然后统计一段时间内的宽高比变化,如图7所示为某段测试视频提取到的宽高比变化图。
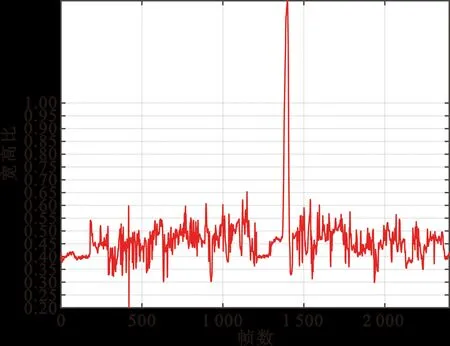
图7 嘴巴宽高比变化统计图
通过统计分析大量的嘴巴宽高比数据可知,在正常、讲话以及打哈欠三种状态下的嘴巴宽高比变化不同。通过研究三种状态的宽高比变化模型得出,正常状态下的嘴巴宽高比值一般较小,并且仅有轻微的波动;打哈欠状态下会出现很高的峰值,一般大于1,且无频繁波动;而讲话状态下最为复杂,嘴巴宽高比值相较于正常状态下的平均高度一般更高但又不会大于打哈欠状态,而且波动范围更大、更加剧烈。
因此,针对上述发现,本文提出了两种方案进行实验,来对比分析找出最优的驾驶员讲话状态检测方案。第一种方案,通过设定固定阈值来区分三种状态,其中包括上、下两个阈值,判别方法为:连续30帧图片的嘴巴宽高比均值高于上阈值为打哈欠,低于下阈值的为正常状态,只有当图像的嘴巴宽高比值处于上下域值之间时才为讲话状态。第二种方案,通过对连续多帧图像的宽高比振荡差值来判断。正常状态下的宽高比值振荡幅度非常小,浮动的峰谷差值基本都在0.03以内;而讲话状态下的却比较激烈,峰谷差值大多数都大于0.05,但最大不会超过0.5;打哈欠状态下的振荡更加剧烈,其差值一般超过0.5,甚至大于1。因此,针对正常、打电话及打哈欠三种状态,设置连续20帧图像的宽高比峰谷差值波动范围分别为[0,0.04]、(0.04,0.5)、[0.5,∞)。
针对上述两种方案,本文进行了大量的实验。通过对不同性别、年龄的人物,在白天和夜晚两种情形下进行测试得出结论,方案二的效果要明显好于方案一,后者的检测平均准确率可达到90%以上,而前者的平均准确率却不到70%。方案一在实验过程中,始终难以确定出最合适的阈值范围,经过分析其原因在于不同的人在正常状态下的嘴巴闭合形状不一样,而且说话过程中会出现宽高比均值低于正常状态的情况。综上所示,本文采用方案二的方法进行驾驶员讲话行为判别。
在得出上述两种行为的判别结果后,便可以得到最终的驾驶员打电话行为判别结果。采用的方式是通过两者相“与”运算进行判别,即只有当驾驶员既存在手持电话行为,同时又存在讲话行为时,才可判断其正处于一边开车一边打电话的状态,从而对驾驶员发出警告。如果其中一种行为并未被检测到,便不会发出警告,如此既能避免由于某一种行为的误检而导致的误报,又能保证免提通话一样能够被检测到。
2 实验结果分析
2.1 实验设置及数据
本实验训练模型所使用服务器为64位Ubuntu 16.0系统,配备了Intel Xeon Silver 4215处理器,128 GB内存,2张GeForce RTX 2080Ti显卡,每张显卡显存11 GB。
本文系统最终运行在联咏公司NT96687平台上,此平台由控制核心和运算核心两部分组成。控制核心使用的是Dual Core ARM Cortex-A53芯片,主要实现图像的采集、存储和传输等资源调度以及检测结果的显示和报警功能。运算核心承担着本文算法实现的主要部分,使用的是CEVA DSP XM4芯片,CPU为DualCEVA DSP XM4,RAM 4 GB,ROM 16 GB,OS为FreeRTOS V9.0。
实验数据集由两部分组成:一部分为中科院亚洲人脸数据集CAS-PEAL,它由1 040个个体(包括595名男性和445名女性)的30 900张图像组成,此部分为正常环境下非打电话图片数据集;另一部分为驾驶环境下,使用红外摄像头采集的107位驾驶员在不同角度和光照条件下的打电话数据集,其中包含6 470张打电话图片和13 510张正常驾驶图片,称为驾驶员打电话行为数据集(Driver's Calling Behavior Dataset,DCBD)。以上数据集组成了本次实验的数据集,如图8所示。
实验中,人脸检测部分使用了上述数据集的全集。此外,负样本由车载环境下采集的非人脸图像的55 000张图片组成。确定了人脸坐标及检测区域后,打电话行为判别使用DCBD作为数据集,其中的正样本为打电话图片,负样本使用正常驾驶图片。本文通过交叉验证法将数据集的80%作为训练集,另外的20%作为测试集,多次训练测试以达到最优的检测效果。
2.2 结果分析
为了验证模型的检测效果,将算法部署在车载NT96687平台上,通过DSP运算核心的向量处理单元(Vector Process Unit,VPU)、矩阵运算及卷积等操作来加速算法运行,并完成检测任务。测试数据为12名驾驶员在偏僻道路上的驾车行驶途中,通过红外摄像头实时采集视频进行检测。在上述实际场景下,本文算法在某段驾驶视频中的检测效果统计如图9所示。

图9 实际驾驶场景检测结果统计
本文算法的整体检测效果采用检测平均准确率(mean Average Precision,mAP)、平均召回率(Average Recall,AR)、特效度(Specificity,SP)以及平均检测速度(ms/frame)作为评价标准,其中AR和SP的计算公式分别如公式(1)和公式(2)所示:
(1)
(2)
式中:TP代表真正正样本,FN代表假负样本,TN代表真正负样本。各类算法的检测性能指标对比如表1所示。

表1 检测算法对比
由表1可以看出,本文算法在权衡检测精度和速度上要优于其他算法。在实际驾驶环境下,本文的平均检测准确率虽然比YOLOV3少了0.2%,但特效度却达到了98.8%,表明算法的误报率很低,极少出现没有打电话的情况下发出警报,从而避免影响驾驶员的正常驾驶行为。此外,本文算法的检测速度相比较于其他算法缩短了至少一倍,在对比其他各类算法中检测速度最快,对驾驶员的打电话行为检测效果更好,实时性更强。
3 结 论
本文提出了一种基于深度学习的驾驶员打电话行为检测算法,可同时对听筒和免提接听两种状态进行检测,相比较于其他只对听筒接听进行判别的算法更具实用性,而且融合手持电话与讲话行为共同判别驾驶员打电话行为,相比较于以往的检测方法具有更高的检测精度,能极大程度地防止误报。经过在驾驶环境下的实验,分别与Haar+AdaBoost、LBP+XGBoost、HOG+SVM、YOLOV3等算法在检测准确率和速度上进行对比,结果表明,本文所提的检测方法在实际驾驶环境下具有更好的检测效果,在提升检测精度的情况下,检测速度也有很大的提升,在嵌入式平台下的平均检测速度仅在230 ms/frame左右,可对实际驾驶场景下的驾驶员打电话行为进行准确、及时的预警。
