基于AE-FFNN神经网络的橡胶树叶片磷含量定性研究
2021-07-29叶林蔚唐荣年李创
叶林蔚, 唐荣年, 李创
(海南大学机电工程学院, 海口 570228)
天然橡胶为四大工业原料之一,对于促进我国经济发展至关重要。橡胶树是天然橡胶的直接来源,我国橡胶树主要种植于华南地区,海南是主要植胶区。提高橡胶产量对生态保护和国民经济发展都有重要意义。磷在橡胶树的生长和产胶过程中起着重要作用,磷缺乏会导致橡胶树早衰、割胶期缩短,且抗病能力明显下降。相反,过量施用磷肥会导致橡胶树成熟缓慢、产胶质量下降且容易污染土壤和水源。合理施用磷肥是管理橡胶树的重要环节。海南农垦橡胶树诊断施肥已开展多年,其中,判断施肥量以叶片养分含量为主,土壤养分含量为辅。这为以橡胶树叶片的养分含量判断橡胶树的整体养分含量提供了依据[1]。同时,土壤磷含量与橡胶树叶片磷含量有强线性关系[2],而施用肥料后叶片相应元素和叶绿素含量均出现相同的增加趋势,对橡胶树的生长发育起到重要影响[3]。
橡胶树叶片的磷含量能够指导肥料的施用。传统的理化分析方法精度较高,但其对叶片样本具有破坏性,且操作流程复杂,需要专业的实验仪器和分析人员[4]。利用近红外光谱和高光谱对植株、土壤、叶片等样本的磷元素含量进行快速无损检测是近几年的研究重点,相关研究主要围绕特征选择和模型建立,提出的方案主要结合线性回归算法和波段选择方法。其中,如何特征选择能够得到最具关联性的特征组合及线性回归算法能否建立磷元素和高光谱之间的关联机制值得探究。
高光谱技术作为快速无损的检测技术,虽然已在植物磷素营养诊断方面取得了较为成熟的应用,但相关研究大多使用线性回归算法。如利用支持向量机回归和偏最小二乘回归建立柑橘叶片磷含量的回归模型[5],利用敏感波段、随机森林建立苹果叶片磷含量诊断模型[6]及利用一元线性回归建立土壤磷含量的高光谱估测模型[7]。但橡胶树叶片磷含量与高光谱之间不仅存在线性信息,还存在非线性信息[8]。因此,引入非线性模型诊断橡胶树叶片磷含量,有利于将线性和非线性信息考虑在内。
目前,深度学习因其能提取光谱深层特征,逐渐被应用到光谱的快速检测。除了对蔬菜水果进行分类[9],通过改变获取数据窗口的大小,卷积神经网络还应用于蓝藻的藻蓝蛋白与叶绿素a定量检测[10]。堆叠自适应加权自编码器同样可提取特征作为分类器的输入[11]。此外,卷积神经网络等深度学习算法也可用于光谱的波长选择[12]。因此,应用深度学习建立高光谱和磷元素含量之间的关联机制,可以有效将非线性信息考虑在内。
此外,波段选择作为特征提取的思路已有大量研究。针对橡胶树叶片磷含量的检测效果不佳,特征提取旨在减少数据维度,并提取出有效的特征供后续使用以提升模型的效果。其中,除MC-UVE-SPA法(monte carlo-uniformative variable elimination-successive projections algorithm, 蒙特卡洛-无信息变量消除法-连续投影算法)挑选特征波长提升了橡胶树叶片的检测精度外[13],AIRF-CARS(adaptive interval random frog-competitive adaptive reweighting algorithm, 自适应间隔随机蛙-竞争性自适应重加权算法)和CARS-SPA(competitive adaptive reweighting algorithm-successive projections algorithm, 竞争性自适应重加权算法-连续投影算法)等联用方法也被用来提取样本氮元素的光谱特征[14-15]。另外,环境因素与高光谱的结合能够有效提升营养元素的诊断效果[16]。
针对以上问题,本文拟使用深度学习中的神经网络解决磷元素与近红外光谱之间线性关系较弱的问题。综合深度学习和特征提取方法的优势,本文使用自编码器(AE)对橡胶树叶片的高光谱进行特征提取和降维,将变换后的光谱特征作为前馈神经网络(FFNN)的输入,应对不同精细程度的分类任务,建立橡胶树叶片磷含量高光谱定性分析模型,并与传统线性分类器朴素贝叶斯和非线性分类器支持向量机和随机森林比较。
1 材料与方法
1.1 试验材料
1.1.1试验样本 供试橡胶树品种为RY-7-33-97,种植于中国热带农业科学院海南省儋州市试验基地。
1.1.2仪器设备 通过FieldSpec3光谱仪(美国ASD公司)采集橡胶叶片样品的近红外高光谱。该仪器具有高分辨率、高灵敏度、采集速度快等特点,因此被国内外学者广泛应用于采集光谱图像数据。整个系统可分为三个部分:①光谱采集系统,波长范围为926~1 678 nm,光谱采样间隔为3.25 nm,共230个光谱点;②信息处理系统;③运动控制平台,包括步进电机和底部有光源的透射光谱采样平台。运动控制平台和光谱采集系统被置于暗箱中,使整个系统不受外界光源的干扰。
1.2 试验数据采集
在自然生长环境下,随机选取不同橡胶树植株,采集完整、无虫害的健康成熟叶片作为实验样本,总计147个。首先,使用光谱仪扫描整个叶片,通过式(1)校正图像获得叶片的高光谱数据。
(1)
式中,Ic为校正后的高光谱,Io为光谱仪扫描得到的高光谱,B为黑帧,W为白帧。
测定光谱反射率后,为了得到叶片磷含量真实值,首先将每个叶片样品105 ℃干燥30 min,70 ℃干燥8 h,然后将干燥的叶片磨碎并通过1 mm的筛网。干燥和研磨后的样品用浓硫酸和30%过氧化氢的混合物消化。最后用钼锑比色法[17]测定147个叶片的磷含量。
1.3 分析方法
本文所提出的核心思路是对近红外高光谱进行非线性特征分析,即先对光谱进行特征提取和降维,然后使用光谱特征建立分类模型。本文提出了AE进行特征的第一步提取,然后使用FFNN[18]对提取的特征进行建模。最后使用十则交叉验证(10-fold cross-validation)测试模型准确性。进行10次十折交叉验证,再求其均值,作为对模型准确性的估计。
自动编码器由MATLAB2020a实现,其结构如图1所示,自动编码器的隐藏层作为前馈神经网络的输入。自编码器通过编码提取特征解码重构样本,隐藏层神经元即为提取的特征。
本实验根据中国国家标准GB/T 29570—2013[19]对橡胶树叶片进行分类,指标如表1所示。
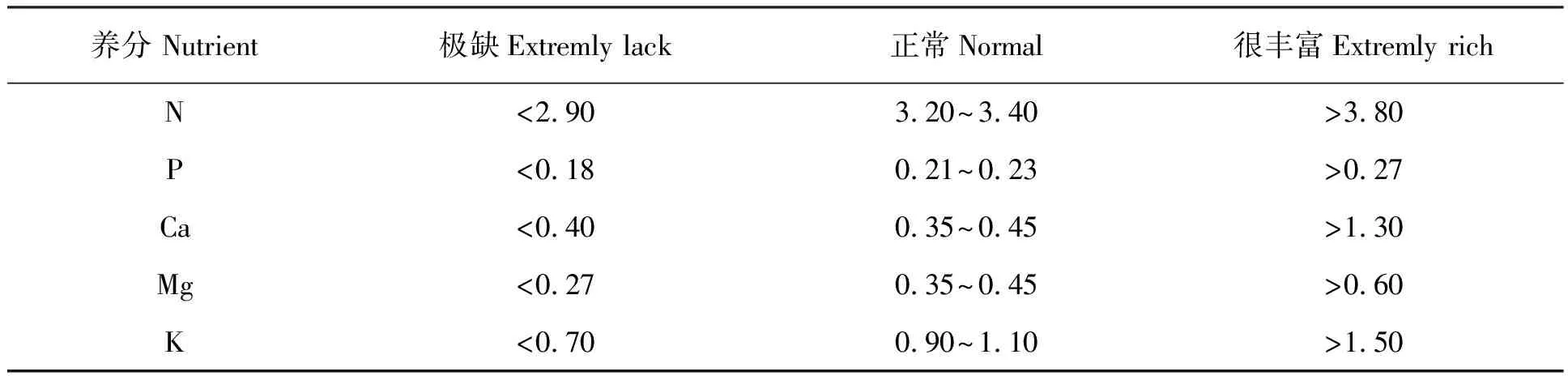
表1 海南省主要品种橡胶树叶片营养诊断指标Table 1 Leaf nutrition diagnosis index of main rubber varieties in Hainan Province
均方根误差(root mean square error,RMSE)是预测值与真实值偏差的平方与观测次数n比值的平方根。RMSE越小,说明预测值和真实值越接近。
1.4 分析软件
本文中数据处理和算法计算都使用MATLAB2020a。
2 结果与分析
2.1 叶片掩模效果分析
图像校正后,提取每个叶片样本的光谱。从图2可以看出,样本原图含有样本数据和背景冗余数据,需要从背景中分离出叶片像素点。利用1 300和1 446 nm的灰度图像构建了掩模图像,其中样品的反射率值与背景值有较大差异。可以看出,该掩模图基本上把样本从背景中提取出来,去掉背景,保留样本数据。然后,将每个叶片样本的像素级光谱平均为叶片光谱。
2.2 样本磷含量分析
经过化学分析,147个叶片样本磷含量分布如图3所示。其中,样本磷元素含量最大值为0.330 3%,最小值为0.122 4%,样本的磷元素平均含量为0.234 1%,标准差为0.049 2%,从磷元素含量标准差值来看比较均匀。对磷含量执行kolmogorov-smirnov(K-S)检验,确定样本服从5%的正态分布,这与自然生长环境下磷元素含量的分布一致,实验有效。
根据国家标准GB/T 29570—2013[19],橡胶树叶片磷含量可分为五个水平。其中小于0.18%属于“极缺磷”、0.18%~0.21%属于“缺磷”、0.21%~0.23%属于“正常”、0.23%~0.27%属于“富磷”和大于0.27%属于“极富磷”,各级别样本数如表2所示。而针对较为粗放的要求,简单判断磷含量缺乏、正常和富有的状态。把“极缺磷”和“缺磷”统称为“缺磷”,“极富磷”和“富磷”统称为“富磷”。本研究将样本划分为:小于0.21%属于“缺磷”,样本数35个;0.21%~0.23%属于“正常”,样本数27个,而大于0.23%属于“富磷”,样本数85个。
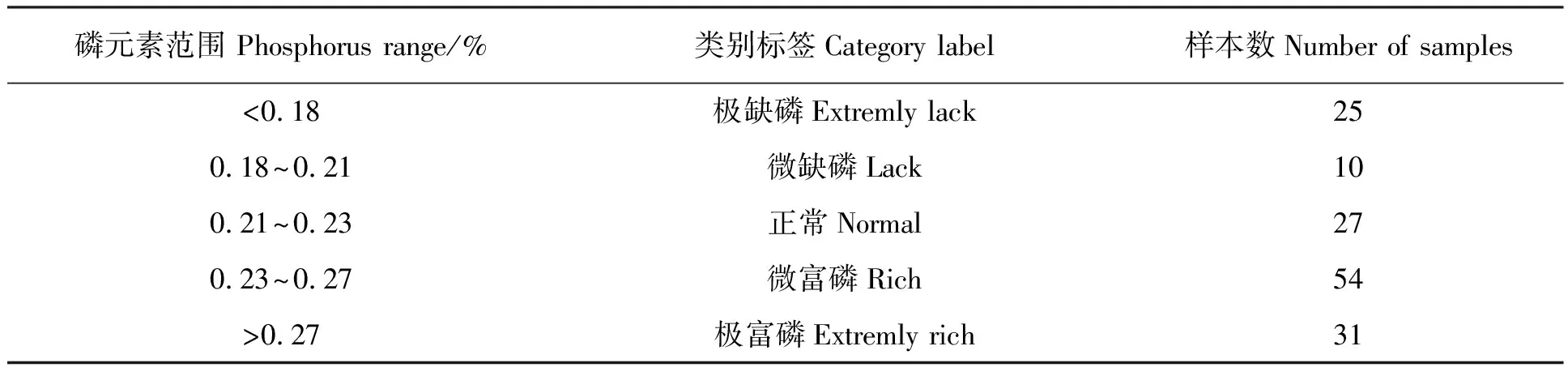
表2 橡胶叶片磷含量精细诊断结果Table 2 Phosphorus content fine diagnosis index of rubber leaves
2.3 分类结果分析
采用朴素贝叶斯(naive bayesian model,NBM)线性判别分析、支持向量机和随机森林非线性判别分析与前馈神经网络对粗细分类效果进行比较,结果如表3所示。可以看出,不管粗细分类任务,非线性分类器都优于线性分类器,均已AE-FENN模型的最高。
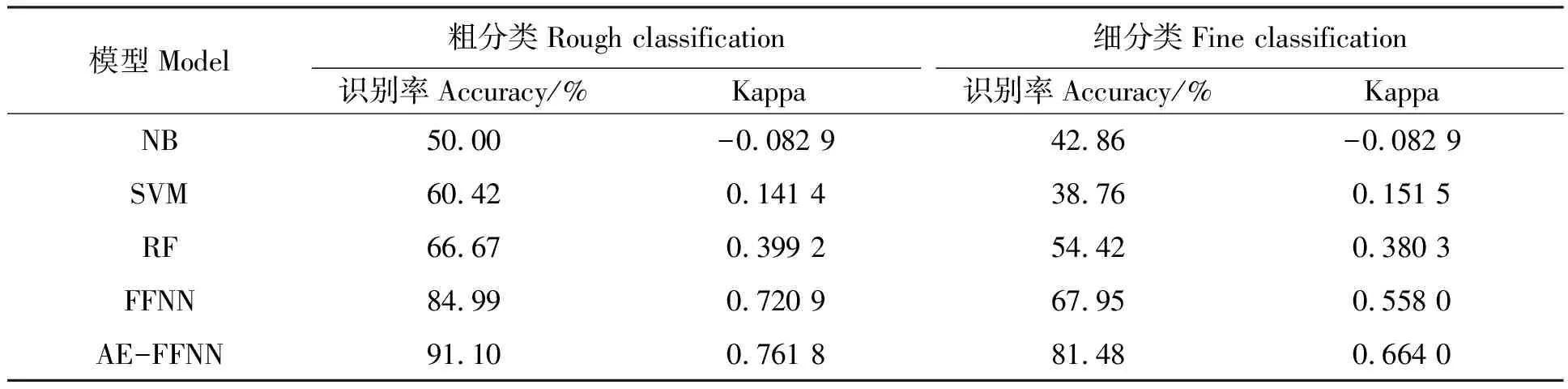
表3 不同分类模型效果比较Table 3 Comparison of different classification models
2.3.1粗分类结果分析 由表3可见,以支持向量机和随机森林为代表的非线性分类器整体优于朴素贝叶斯为代表的线性分类器。由此可见,橡胶树叶片光谱与磷元素的相关性并不强,传统的分类器对磷元素检测效果具有局限性。在此基础上,FFNN发挥其善于提取非线性模型的特点,提升了针对橡胶树磷含量水平的检测精度。FFNN的识别率为84.99%,Kappa值为0.720 9,与传统分类器相比模型性能有很大提升。而AE-FFNN模型的识别率是91.10%,Kappa值为0.761 8,除了识别精度比FFNN更高外,AE-FFNN的模型所用到的变量比FFNN更少,模型更简单。
2.3.2细分类结果分析 由表3可见,由于细分类比粗分类目标更明确,要求更精细,所有细分类模型的效果都不免有所下降。但同时,FFNN的识别率为67.95%,Kappa值为0.558 0,而AE-FFNN模型的识别率是81.48%,Kappa值为0.664 0,识别精度虽然低于粗分类模型,但依然领先于传统分类模型。
2.3.3交叉验证次数的影响 对FFNN和AE-FFNN进行比较,结果如表4所示。在粗分类中,AE-FFNN的平均识别率为91.10%,Kappa值为0.761 8。在细分类中,AE-FFNN的平均识别率为81.48%,Kappa值为0.664 0。无论粗细分类要求,AE-FFNN较FFNN分类的效果更好。

表4 交叉验证次数对FFNN和AE-FFNN分类结果的影响Table 4 Influence of cross-validation fold on classification results of FFNN and AE-FFNN (%)
其中,FFNN和AE-FFNN第一次交叉验证时,无论粗细分类任务,分类效果有所下降,这与样本的划分具有很大关系。同时,随着交叉验证次数的增多,分类效果提升明显并较为稳定。
2.3.4最优模型与分析 从表3可以看出,传统模型中无论线性模型朴素贝叶斯分类器还是非线性模型支持向量机和随机森林,都逊于FFNN和AE-FFNN,其原因在于FFNN和AE-FFNN都是通过神经网络提取较为深层的特征。在不清楚磷元素含量和橡胶树叶片高光谱之间有着怎样的联系的情况下,FFNN让网络自学习。通过迭代学习,建立稳定的磷元素和橡胶树叶片高光谱关系模型。
另外,相较于FFNN模型,AE-FFNN方法在三个方面具有明显优势:①AE相较普通波长点选择方法,不依赖标签而避免了强制建立线性关系;②进一步利用FFNN建立分类模型,FFNN的非线性与AE提取的非线性特征契合;③大大提高了建模效率,使得特征与磷元素的关联更加紧密。这说明,AE-FFNN可以提取出有效的深层特征,改善橡胶树叶片磷含量的分类精度。
2.4 特征数对分类效果的影响
从图4可以看出,无论分类目的是粗分类还是细分类,提取10个特征之后,RMSE降低不明显。同样无论是粗分类还是细分类,特征数在8之后,分类效果逼近极限且出现波动,而特征数在30、90个左右都有不错的分类效果。而同时考虑到模型的复杂度,本文选择31个特征,特征数从230降低到31,使用的数据量仅占总光谱的13.48%。
3 讨论
本研究根据国家标准对橡胶树叶片磷元素含量进行分类。通过比较粗分类和细分类在同一水平下不同模型的诊断结果,最终确定AE-FFNN为最佳模型。
在预处理过程中,通过单波长特征图像的阈值分割和主成分分析能够获得样本固定大小的感兴趣区域[20]。但橡胶树叶片的磷含量与整个叶片的大小和每个像素点的磷浓度有关。因此,本研究通过叶片的反射率变化和背景的反射率变化不同,利用1 300和1 446 nm两个敏感波段,从冗杂的原始样本高光谱图像中提取到精确完整的叶片高光谱图像。这相较传统人工划分运行速度更快,并确保叶片区域分离完整。其次,根据国家标准划分的叶片高光谱训练不同模型。模型包括传统线性模型贝叶斯线性判别器、支持向量机和随机森林以及本文提出的FFNN和AE-FFNN。由于磷元素和叶片高光谱数据相关性不强,传统的线性分类器检测效果(粗分类50.00%、细分类42.86%)较差。而传统非线性模型支持向量机(粗分类60.42%、细分类38.76%)和随机森林(粗分类66.67%、细分类65.42%)通过其模型建立磷元素和高光谱非线性关系,使检测效果相较贝叶斯判别器得到提升。最后,本研究提出的FFNN(粗分类84.99%、细分类67.95%)和AE-FFNN(粗分类91.10%、细分类81.48%)利用神经网络的网络特点,经过网络变换,结合高光谱和磷元素之间线性和非线性特征,融合得到深层次稳定且相关性较高的特征,建立了磷元素和高光谱之间较强的联系,极大提升了橡胶树叶片磷元素的检测水平。
神经网络比SVM等传统分类器具有较强较快的学习速度,且精度适当或更高。但神经网络参数都是随机选择的,很大程度上造成了模型不稳定[21]。为了保证模型的稳定性,本研究加入了十次交叉验证。通过对样本多次划分,采用不同的训练集和测试集,防止模型过拟合并保持模型稳定。结果表明,FFNN和AE-FFNN融合了线性和非线性特征,无论如何变换样本集合,分类效果都明显优于传统分类模型。同时,本研究通过AE提取特征,将建模的变量从FFNN的230个减少到31个。传统的橡胶树磷元素光谱诊断方法不仅对磷元素的敏感波段解释不够充分,且没有考虑到高光谱的非线性特征。本研究提出的自编码器提取特征结合前馈神经网络建模,同时考虑线性和非线性特征,从大量高光谱数据中挖掘低共线性的非线性特征,建立基于神经网络的磷元素含量诊断模型。该研究有望从特征融合的角度为诊断模型提供有力的解释支撑。
无论是自编码器还是前馈神经网络,都具有较强的鲁棒性,且实现简单,本研究针对橡胶树叶片磷含量的分类任务将两者结合。因此,通过简单变换网络的层数和神经元个数能够应对不同检测任务,这给未来面对其他定性任务提供模型框架。该模型有望应对复杂的田间情况,结合手持式等设备将在田间实现快速的在线识别。总之,AE-FFNN能够简化橡胶树磷元素含量高光谱检测模型且提升模型检测效果,为快速、精准地估算橡胶树磷含量水平提供思路。
