基于端到端表情识别方法的课堂教学分析
2021-07-28华春杰于雅楠李慧苹
华春杰,于雅楠,李慧苹,刘 航
(1.天津职业技术师范大学信息技术工程学院,天津300222;2.天津中医药大学人事处,天津301617)
2019年,“国际人工智能与教育”大会在北京召开,大会提出我国需高度重视人工智能技术和教育的深度融合,推动教育变革创新。因此,充分体现人工智能在教育应用中的智能化特征,是未来智慧教育的发展方向[1]。“人工智能+教育”是融合现代物联网、大数据、云计算、VR与AR等信息技术手段的增强型数字教育。传统领域与人工智能高度融合,但是相比于工业和制造业来说,人工智能在教育领域的作用还未充分发挥。在传统的教室课堂上,学生经常被学习之外的事物吸引,导致听课效率低下。目前,课堂教学中教师主要采用观察的方式了解学生的表情和行为信息,根据学生表情判断其对当前知识的掌握程度,但当教师的教学管理任务较多时,可能会出现信息传递不足或滞后的情况,降低了课堂教学的效率。而在课堂教学中加入表情识别技术可以极大地改善这一问题。
表情是人的情绪最真实的反映。研究者采用基于知识、统计模型等方法来检测人脸,提取五官特征、人脸表情特征、图像纹理等特征对表情进行分类。随着人工智能领域的高速发展,以深度学习为代表的机器学习技术在计算机视觉领域中取得了突破性的进展,一系列人脸检测的网络被提出,如MTCNN[2]、Fast RCNN[3]、Faster R-CNN[4]、YOLOv3[5]和SSD[6];基于深度学习的经典表情识别模型有VGGNet[7]、GooGleNet[8]、ResNet[9]。Mase[10]使用光流法,结合K-近邻算法[11]进行表情识别;Jung等[12]设计了DTAN和DTGN两种网络,将人脸图像分为双通道,分别输入其中,在数据集上取得了较高的识别率;李勇等[13]提出了跨连接的LeNet-5卷积神经网络,其融合了低层次和高层次特征构造分类器,以便提高识别率;张璟[14]设计了VGGNet-19GP、Res Net-18和Ensemble Net三种不同深度神经网络模型来进行表情识别,均取得了较高的识别率。以上网络均属于大型网络,计算量巨大,在实际应用中效果较好,但不适宜环境单一的课堂情况。因此,本文设计一种较轻巧的端到端表情识别模型,对课堂上的学生进行人脸检测和表情识别,帮助教师充分了解课堂教学效果,以提高课堂教学质量。
1 人脸检测和人脸表情识别方法
1.1 传统人脸检测和表情识别方法
人脸检测最早起源于人脸识别,主要分为基于知识和基于统计模型的方法。基于知识的方法需要将人脸各种基本特征提取出来。汪济民等[15]利用空间灰度共生矩阵的参数特征来表示纹理特征,但此方法仅可以用于低分辨率的人脸检测。传统的人脸检测方法在拍摄角度、人脸的亮度发生变化时,检测的结果会有所不同。基于统计模型的方法主要分为基于人工神经网络算法[16]、基于支持向量机算法[17]和基于AdaBoost算法[18]。人工神经网络中大量的神经元相互连接,并且能够反映输入和输出点之间的关系。支持向量机的方法能够有效地将少量样本信息、复杂的模型及较强的学习能力结合起来,获得了更好的推广力。而AdaBoost算法在同一个训练集训练不同的分类器,再把这些弱分类器相结合,形成一个强分类器。
传统的表情识别方法的主要任务是人脸面部表情特征提取。一张人脸图片所含的信息量很大,但在一个视频序列中,表情会在帧序列中发生变化,因此在进行表情识别时,提取图像的有效信息,如五官特征、图像的纹理特点等,该方法对识别的速度与准确性具有很大的影响。
传统的表情特征提取主要有基于全局、局部与混合式的提取方法。人脸上的肌肉运动导致人产生不同的表情,当肌肉运动时,面部的纹理也会发生相应的变化,而这些变化可以由人脸表情图像表现出来并对其产生全局性的影响,由此提出基于全局的特征提取方法。基于集合特征与基于纹理特征的方法是局部特征提取最常用的方法,随着研究的深入,研究者将基于全局与局部的特征提取方法相融合,提高了识别率。
1.2 基于深度学习的人脸检测和表情识别方法
2006年,深度学习由Hinton等首次提出,2012年卷积神经网络(convolutional neural network,CNN)提出并被广泛应用,如MTCNN、Fast R-CNN、Faster R-CNN、YOLOv3和SSD,这些网络首先从全图上学习特征以获取人脸在图像中的具体位置,再进行分类和定位。
基于以上成果,许多研究者开始将深度学习由图像识别领域转向了表情识别。与传统的表情识别不同,基于深度学习的表情识别技术将特征提取与表情分类同时进行,并在特征提取方面做出了极大的改进。目前流行的基于深度学习的表情识别模型有VGGNet、GoogleNet、ResNet等。以上网络在复杂场景的实际应用中效果较好,但是这些网络均属于大型网络,计算量巨大,不适宜相对简单的课堂环境。
2 人脸检测和表情识别的教育应用
百年大计,教育为本,我国历来重视教育的发展和教育质量。课堂是教师、学生交流与学习的场所,传统的教学形式往往以教师在课堂上讲授学科知识为主,有时候忽视了学生的接受程度,学生反馈给教师的信息不足,特别是智能手机与平板的出现,课上“低头族”成了普遍现象,教学质量便随之降低。合理准确的课堂教学质量评估对于课堂教学十分重要,近年来研究开发出很多种教学评估方法,如问卷调查法、生理观察法、计算机视觉法等。由于受视频监控以及计算机视觉算法等限制,目前使用的计算机视觉来对学生进行检测的方法多数应用于在线课堂学习中的师生互动场景。
在线课堂目前仅对单人或者单一场景进行面部识别,对传统教室中师生互动的课堂进行检测和评估的算法甚少。因此,本文就教室中课堂上学生的抬头情况与表情识别做了研究,通过基于端到端的表情识别算法对教室视频监控系统采集到的信息进行分析,检测出上课时学生的抬头情况,识别学生的微表情,判断学生的学习状态,结合教师与学生的互动情况和学生的行为模式综合测评课堂的教学效果。再将对学生的分析结果反馈给教师和学校,为学校制定更加合理的规章制度、更加高效的教学计划提供参考。同时,可以实时检测到学生的异常行为,及时传递给教师、家长,避免发生不必要的意外。
3 基于CNN人脸表情识别技术的实现
本文采用的端到端的表情识别模型,命名为CNN-Specific,其主要包括搭建并训练卷积神经网络以及实现面部表情识别两部分。用训练后的模型分别进行了静态图片识别和实时检测识别。
3.1 网络框架
CNN-Specific模型的整体框架如图1所示。首先将数据集中的人脸图像进行一系列预处理,然后将处理后的图片作为输入放入卷积神经网络模块进行训练,在模型的最后,计算人脸对应的每个表情得分值,得分值最大的表情类别为该人脸所属的表情。
图1中的CNN模块包含有4个卷积层、3个池化层和2个全连接层,网络内部参数如表1所示。本文在输入层后加入了1*1的卷积层,以达到输入非线性的目的,并使网络的深度得到增加,增强了网络模型的表达能力。在每个卷积层之后使用Relu函数进行激活,在2个全连接层引入Dropout防止过拟合。

表1 CNN-Specific模型网络内部参数
3.2 模型训练与测试
3.2.1 数据集预处理
使用标准静态图片训练模型时,每张图片都是正面且表情清晰,但在实际应用中,采集到的图像会由于角度、亮度的不同导致同一人脸的同一表情差别也很大。因此,本文先对训练图片进行一系列预处理操作,如翻转、调整大小、调节亮度、裁切等。对图片的预处理过程如下:
(1)将原始图片从左向右随机翻转图像。
(2)调整图像的亮度。调整亮度的随机因子范围为-32/255~23/255。
(3)调整图像的对比度。调整对比度的随机因子范围为0.8~1.2。
(4)裁剪图片为指定大小。
3.2.2 训练优化
在神经网络模型中所搭建的网络越复杂,训练难度越大,训练时间就越长。但是,对于复杂问题的处理又是必不可少的,要对网络模型进行优化以提高训练效率。本文使用Adam算法来进行优化。自适应梯度算法(Adagrad)为每个参数都保留一个学习率来提升在稀疏梯度上的性能;均方根传播(RMSProp)根据最近权重梯度平均值为每一个参数设计适应性学习率。而Adam算法结合了Adarad和RMSProp算法的优点,Adam算法更新自适应学习速率过程如下:
(1)计算t时间步的梯度。

(2)计算梯度的指数移动平均数,m0初始化为0,β1为指数衰减率,用来控制权重分配,一般设置为接近1的值,默认值为0.9。
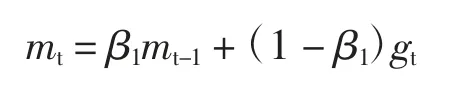
(3)计算梯度平方的指数移动平均数,v0初始化为0,β2为指数衰减率,用来控制之前梯度平方的影响情况,默认值为0.999。

(4)由于m0初始化为0,因此在训练初期会使mt偏向于0,因此需对梯度均值mt的偏差进行纠正。

(5)同理,由于v0初始化为0,导致训练初期vt偏向于0,对其偏差进行纠正。

(6)更新参数,初始的学习率α乘以梯度均值于梯度方差的平方根之比。学习率初始值为0.001,ε的值设置为10-8。
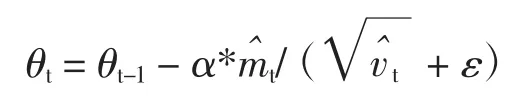
3.2.3 检测和识别结果显示
此模块分为静态图片测试与人脸实时检测,主要使用的库为Opencv库,在静态图片检测阶段,调用Opencv库中Haar特征分类器detectMultiScale函数,检测出人脸,并根据给出的人脸位置画出矩形框图,再根据模型输出结果中给出的表情分类。实时检测与静态图片检测不同,需要摄像头捕捉图像和从图像上识别表情同时进行。摄像头采集模块使用Opencv库中的VideoCapture函数,然后将捕捉到的图像传送至训练好的模型进行检测,实时显示人脸检测和表情识别的结果。
4 验证分析与课堂评价
4.1 数据集
本文采用FER2013人脸表情数据集进行训练,每张图片为48*48的灰度图。数据集共有64 594张图片,训练集有35 886张,测试集有28 708张,公共验证图和私有验证图平均分配。数据集包含生气、厌恶、恐惧、开心、难过、惊讶、中性7种表情,分别对应0—6这7个标签。将训练集图片和对应标签输入模型进行训练,最终将训练好的模型运用到实际工作中。训练过程中,若将照片全部载入内存,则每次训练将数据集重新载入,会出现耗损大、占据内存空间大等现象。基于此问题,本文将数据集中的图片转化为.tfrecord格式,每次训练仅载入一部分数据,训练与读取数据同时进行,加快训练速度。
4.2 实现环境
实验采用CPU为Intel core i5,使用的语言为Python,在深度学习框架Tensorflow下进行相关设计,使用Adam优化器训练10 000次。实验检测阶段分为静态人脸图片检测和相机实时检测。在实时检测阶段,将USB相机固定在教室的讲台位置,该相机可360°旋转,实时将采集到的图片传递给模型进行识别。
4.3 实验结果分析
为了评估CNN-Specific模型的性能,本文使用普通的卷积神经网络模型CNN和经典模型VGGNet作为对比实验,CNN模型有4层卷积层,卷积核大小分别为5、5、3、3;池化层大小分别为3、3、2、2;步长均为2。以上3个模型在同一实验环境下分别进行训练,得到的表情识别测试集准确率如表2所示。

表2 模型识别率对比
从表2可以看出,本文使用的CNN-Specific模型的识别正确率低于VGGNet模型,但是远高于普通卷积神经网络模型CNN;但CNN-Specific模型的网络结构和VGGNet模型相比属于轻量级的网络,相比之下网络参数很少,占用内存较少,更加适宜于实时检测。
针对CNN-Specific模型,分析实验得出标签中“生气”和“厌恶”相似度较高,导致整体的识别准确率不高。测试分为静态人脸图片检测和动态相机实时检测。
(1)静态人脸图片测试分别使用了FER2013数据集内的图片、低像素图像和相机拍摄的真实人脸图像,测试结果如图2所示。其中,图2(a)为单人脸,识别效果较好;图2(b)为网络下载课堂场景图片,像素较低,学生在轻度低头时仍然能检测到人脸;图2(c)中大多数学生在抬头听讲,人脸检测和表情识别效果较好,但当学生用手遮挡侧脸时,会对检测模型产生影响,且可能会出现假阳性,将其他位置检测为人脸;图2(d)检测出了图片上的所有人脸,但在某些位置出现了错检,且学生侧脸角度较大时仍然会出现检测不到的情况。

图2 CNN-Specific模型静态人脸图片测试结果
从图2可知,本模型取得了较好的识别效果,对于正脸有较高的识别率,且在多人环境中仍然有较好的识别效果。
(2)动态相机实时检测场景为真实课堂场景,由于视频帧相邻序列人脸表情变化不大,本文只挑选出关键帧展示识别结果。视频关键帧检测和识别效果如图3所示。从图3可以看出,实时检测时模型的人脸检测率和表情识别率均未下降,且对轻度侧脸和低头有一定的包容度,当相机拍摄学生的正脸时,可将所有的人脸检测出来(图3(d)),但相机位于侧方位时,人脸密集区域有互相遮挡的情况,造成部分人脸漏检错检。

图3 CNN-Specific模型动态实时场景测试结果
由图3可知,当人脸处于较正的位置,且教室人较多时,模型有较好的人脸检测率和表情识别效果,但当有一些干扰因素时会降低识别准确度,如学生用手遮挡侧脸、戴帽子或戴口罩时,会导致漏检。除此之外,某些场景会出现假阳性,将无人脸位置错检为人脸。干扰因素下的测试结果如图4所示。

图4 CNN-Specific模型干扰因素下的测试结果
在真实课堂环境中,学生表情没有确定的标签,无法准确判断学生的表情分类,故本文使用模型在3个课堂场景中统计了课堂的抬头情况,学生课堂抬头情况统计如表3所示。
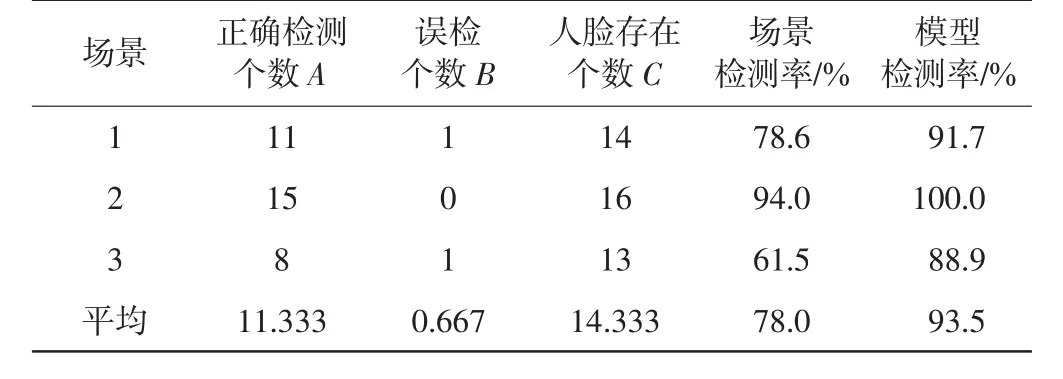
表3 学生课堂抬头情况统计
场景检测率Ps和模型检测率Pm的计算式为
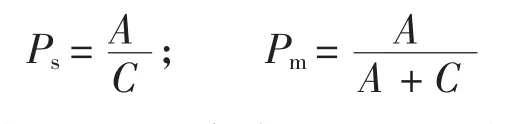
式中:A为正确检测出的人脸个数;B为误将非人脸区检测为人脸的个数;C为该场景中包含的完整人脸个数。
由表3可以看出,实验中场景的平均检测率为78.0%,模型的平均检测率为93.5%,均取得了较高的检测率,可以满足课堂场景中的抬头率检测。
4.4 课堂评价的实现
通过将人脸检测与表情识别技术应用在课堂上,对教室中课堂上学生的抬头情况与表情识别进行了研究,其中以抬头率和学生在教师讲课时的对应表情作为判读检测课堂教学与学生专注程度的标准之一。
(1)课堂抬头率
每隔1 min对教室中的人脸进行检测,计算上课时检测到的人脸数,与全班人数进行比较,计算出当前时刻的抬头率,再计算整个课堂上每分钟抬头率平均值,得到本节课的抬头听课率。图片课堂抬头率θ的计算式为
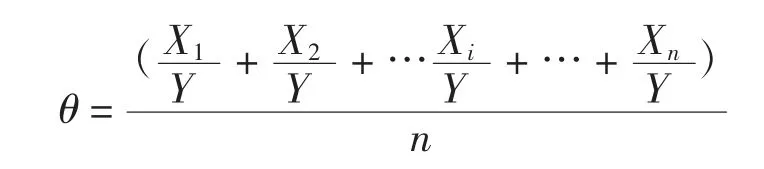
式中:Y为假设课堂人数;n为每节课相机采集次数;Xi为第i次检测到的人脸数。
(2)学生课堂表情分析
当教师讲课时,不同的课堂情景会使学生有不同的心理状态,体现在人物表情上即为不同的面部表情,如当教师提出问题时,积极参与思考的学生会有“疑惑”或者“难过”表情;当学生受到教师的表扬时,会表现出“开心”或者“惊讶”表情。
教师可根据模型识别出的学生表情对应相应的教学情境,将课堂教学情况数字化,综合分析课堂效果、学生对该课程的感兴趣程度等。其课堂效果与传统方法相比有了很大的改进,主要体现在以下方面:①本文将基于深度学习的视觉算法与视频技术相结合,对学校课堂监控系统中的视频帧进行人脸检测和微表情识别,充分利用了视频监控信息,提高了效率。②通过检测学生人脸,判断其在课堂的抬头率;通过识别学生的表情,分析学生的学习状态、精神状态等,帮助学生调整自己的听课状态。③将学生课堂状态的分析结果反馈给教师,教师可结合学生行为模式综合测评课堂教学效果以及学生在本节课的学习效果;帮助教师与学生建立更加高效的互动,调整授课方法。④将学生课堂状态的分析结果反馈给学校,帮助学校制定更加合理的规章制度,更加高效的教学计划。⑤将学生课堂状态的分析结果反馈给家长,使家长进一步了解学生听课状况,便于家长进行更加合理的家庭教育,促进学生健康成长。
5 结语
本文采用基于端到端的设计方法搭建一种表情识别模型,用于评价学生上课出勤率、活跃度等课堂信息。模型的轻巧结构降低了计算量,且有较好的识别率。将训练后的端到端表情识别模型应用于传统的课堂教学过程中,通过对教室中学生的人脸检测,计算出课堂抬头率;识别不同教学情景下学生表情,判读学生的课堂专注度;分析学生感兴趣程度以及教师的教学方式是否合理,综合评价课堂效果。本模型将课堂信息更多地转换成为数字信息,有利于综合分析课堂数据,帮助教师、学校更好地掌握及分析课堂教学情况。
