基于聚类分析的个性化异构数据发布
2021-07-28吕小红杨知方
聂 静,常 涛,刘 维,吕小红,王 晨,杨知方
(1.国网重庆市电力公司,重庆 400014;2.输配电装备及系统安全与新技术国家重点实验室(重庆大学),重庆 400014)
在如今的大数据时代,数据的价值已经越来越被人们所重视[1-2]。对于公共数据发布中存在的隐私保护问题也越来越受到关注,如何实现安全有效的数据发布成为了一个研究热点[3]。
在大数据中,异构数据已经越来越普遍。异构数据通常由关系数据和集值数据组成,因此异构数据的隐私保护一般分为关系数据匿名化与集值数据匿名化[4]。对于关系数据匿名化问题,文献[5]隐藏识别属性和敏感属性之间的相关性,并生成k-匿名相似性数据以显示身份和属性。文献[6]通过在泛化过程中添加不确定性,可以有效发布差分隐私数据。对于集值数据匿名化问题,文献[7]提出一种数据分区技术,用于断开标识属性之间的关联,并在最终查询结果中添加噪声。文献[8]提出KP匿名模型,通过区分集值属性中的敏感项和非敏感项,满足多样性相关性来防止属性泄漏。虽然上述方法取得了一定的效果,但是许多方法均是单独处理关系数据或集值数据,对于异构数据来说是否有效还需进一步研究,且均没有考虑。
针对异构数据匿名化,也有一系列研究,文献[9]提出一个差分隐私回归分析模型,将目标函数转化为多项式形式,并对多项式表示的系数加入噪声。文献[10]将差分隐私与决策树相结合,提供分类器的隐私保护,还使用小批量梯度下降算法来保护训练数据的隐私。虽然这些工作针对某些特定数据考虑了异构数据的聚类性能,但是缺乏泛化性能,即上述匿名化过程不考虑一般性的聚类分析任务,因此用户在使用时缺乏灵活性与实用性。
针对上述问题,现提出一种基于聚类分析的个性化异构数据发布方法。利用聚类标签对聚类结构进行编码,并结合泛化技术和输出扰动来掩盖原始数据。以期有效解决异构数据发布问题。
1 差分隐私
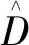
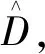
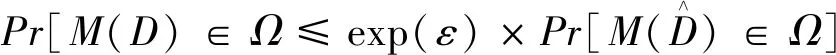
(1)
参数ε被称为隐私预算,它是通过随机机制M来控制隐私保证的程度。ε越小意味着隐私保护程度越高。ε默认为一个正数并且它的数值通常比较小,如0.1、0.5和0.8。
附加噪音的量不仅取决于隐私预算ε还取决于随机机制的全局敏感度。全局敏感度反映了两个相邻数据集上函数输出的最大差分。
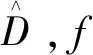
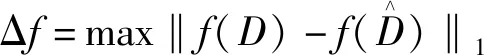
(2)
定义3(拉普拉斯机制)[12]:给定一个数据集D,隐私预算ε和一个随机函数f:D→R,其全局敏感度是Δf,算法M(D)=f(D)+Lap(Δf/ε)满足ε-差分隐私。
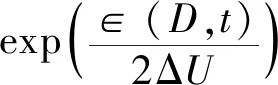
差分隐私有两个重要的属性。它们在判断一种机制是否满足差分隐私中起着重要的作用。
顺序组合表明当许多差分隐私被应用于相同的数据集时隐私预算和噪声会线性增加。
属性2(平行组合):M={M1,M2,…,Mm}是一组隐私机制。如果每个Mi在不相交的数据集子集上提供ε-差分隐私,则Mi将提供(max{ε1,ε2,…,εm})-差分隐私。平行组合表明当应用于不同数据集子集中的一组差分隐私,其隐私保护程度取决于εi的最大值。
2 问题描述
假设数据所有者希望通过将特定于个人的数据发布给数据接受方来进行聚类分析。这些原始数据可以被定义为一组记录D={r1,r2,…,rn}},每个记录ri(1≤i≤n)代表一种具有d属性A={A1,A2,…,Ad}的个人信息。假定每一种属性Aj(1≤j≤d)可以是分类的,数值的或集合值的,并且为每个分类或集合值的属性给出了分类树。在发布之前,应删除明确的标识符,如名称和驾驶执照编号。
聚类分析的任务是将对象分成若干组,使相似的对象在组中,不同的对象在不同的组中,聚类的结果可以用聚类结构来表示。
定义5(聚类结构)[14]:设g是聚类的个数,数据集D={r1,r2,…,rn}的聚类结构被定义为一个矩阵Un×g,矩阵的每个元素ei,j∈{1,0}(1≤i≤n,1≤j≤g)代表了记录ri到第j个聚类的聚类分配,也就是说,当ei,j等于1时记录ri属于第j个簇,而当ei,j等于0时ri不属于第j个簇。
基于上述假设,有如下定义:
定义6(聚类分析差分隐私异构数据):给定一个数据集D={r1,r2,…,rn}和隐私预算ε,对异构数据进行聚类分析的匿名化问题是使是使数据集D使不同类型的属性上匿名化。例如,满足ε-差分隐私并且尽可能与D的聚类结构保持相似的匿名数据集D′={r′1,r′2,…}。
3 异构数据发布方法
3.1 差分隐私的泛化算法
首先,数据所有者在原始数据集D上使用一种聚类算法来确定初始的聚类结构,同一聚类中的记录有相同的聚类标签。与数据集D相比,标记的数据集D*具有d+1个属性A*={A1,A2,…,Ad,Class},其中Class表示类标签;即除了D中的原始属性d,D*中的每条记录ri也有一个类标签。因此,保存D的聚类结构意味着在匿名化过程中保留识别这些类标签的能力,然后通过在D*上执行所提出的差分隐私算法来获取匿名数据集D′。如果D′不够令人满意,则数据所有者可以返回到第一步并且调整算法因子,即分类树,聚类算法的选择和聚类的数量。重复上述步骤直到得到效能满意的D′。第四步,数据所有者将数据集D′释放给数据接收者。
为异构数据提出了一种称为DPHeter的差分隐私的泛化算法,该算法基于自上而下的专业化技术[15]。专业化从最一般的状态开始,然后通过将某些值替换为更具体的值来迭代下降,直到达到预定义的专业化数量。专业化过程就是根据相应的分类树,由表示将父值p→Children(p)替换为其直接连接的子值Children(p)。交替使用术语“子节点”和“子值”。在下文中,还将可以替换为其直接关联的子值的父值称为“cut”。
图1显示了数据的专业化过程。首先,将每个值都概括为图1所示对应的分类树上的最上面的值,并且初始值∪cut为{[19,75],ANY_SEX,**}。假设将ANY_SEX剪切以向下切割,然后由于ANY_SEX→M,F和当前∪cut被更新为{[19,75],M,F,**}。
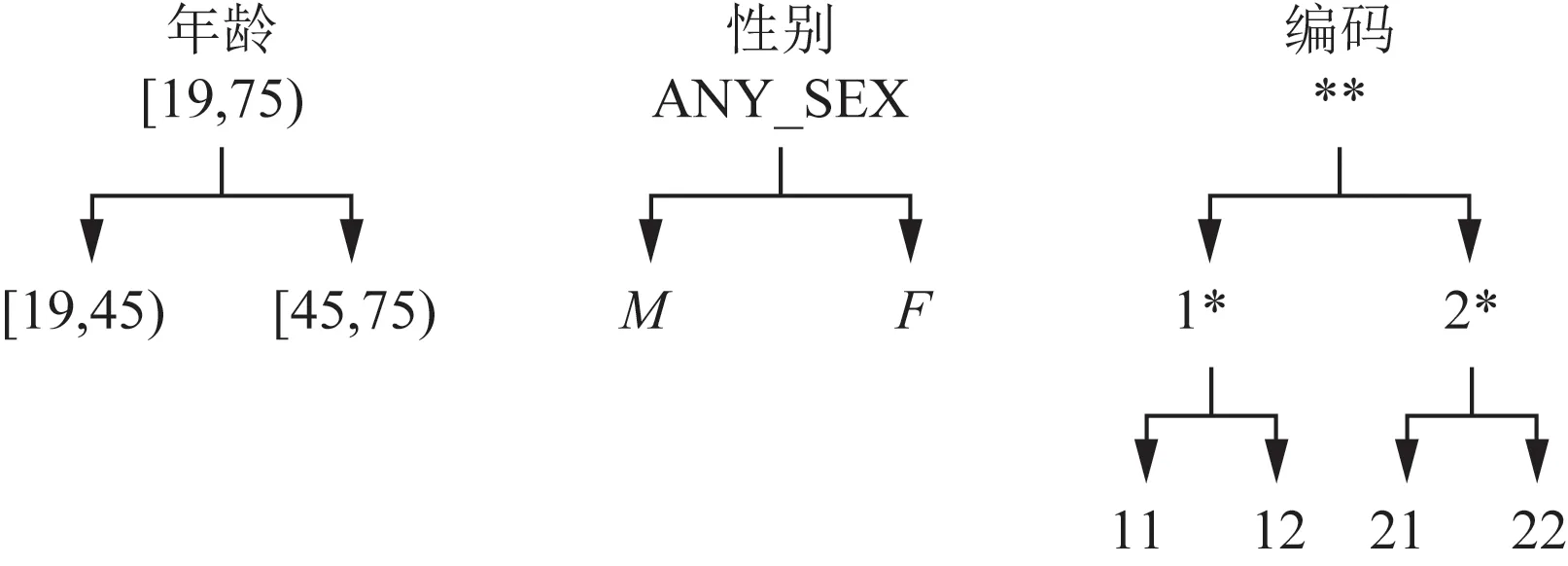
图1 分类树示意图Fig.1 Schematic diagram of classification tree
确保专业化过程满足ε-差分隐私的关键是确定匿名化的每一步都是差分隐私的。其关键步骤包括切割选择和划分记录。
选择用指数机制来选择割集是因为该机制是为离散备选方案设计的。根据定义4可知,这个过程是需要效用函数的。另外采用属性与类标签之间的信息增益作为效用函数。这是因为切割上的每个专业化的过程中都倾向于通过生成特定的属性值来增加信息,并且信息增益能够基于这些值使类标签“更可预测化”。计算数据集D中属性值x的熵的方法为

(3)
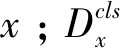
一般化为其子值的属性值p的效用函数定义为
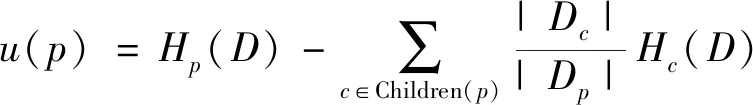
(4)
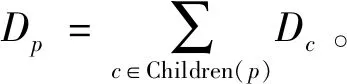
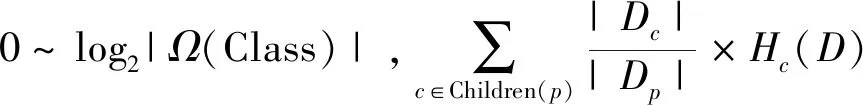
在每一次的专业化过程中,首先通过式(4)完成每个割集候选的效用分数,然后根据指数机制有效地选择一个割以向下划分。Children(ANY_SEX)={M,F}。根据式(4)中ANY_SEX效用分数计算为
与上述计算类似,u([19,75])=0.281 2,u(**)=0.095 4,根据指数机制,[19,75],ANY_SEX,**被选择为切割的可能性分别是56.12%、24.85%和19.04%。
选择剪切后,原始记录分为不同的组。因为它们具有预定义的分类树,所以分类属性的划分策略是固定的。因此分类属性的分区函数的全局敏感性为1。根据当前选择的分类切割和相应的分类树,记录分区的步骤应满足差分隐私。
与分类属性相比,集值属性专门化的区别在于子节点组合的存在。假设选择一个设定值p,在它对应的分类树上有t个子节点。在p上的一般化将产生总共2t-1个子集。为了提高DPHeter的效率,应该尽早的剪掉子集。由于差分性隐私需要不确定性,因此通过验证其噪声大小是否大于阈值,将其视为“非空”。也就是说,如果子分区的噪声大小大于阈值,则保留该子分区。否则,将其视为“空”,应该修剪。阈值可以由数据所有者控制。
如文献[15]中所述,无需为数字属性提供分类树。如果选择了数字分割以向下分割,则在搜索分割的分割值时将动态生成或扩展其相应的分类树。不应为分割随机选择分割值,因为从不包含该值的数据集中选择相同值的可能性为0。这意味着对数值属性的分割值的选择是概率性的。再次使用指数机制,计算数字切割中每个属性值的效用得分,并使用指数机制选择属性值作为数字切割的分割值。选择属性值c作为数字割点p的分割值的概率定义为
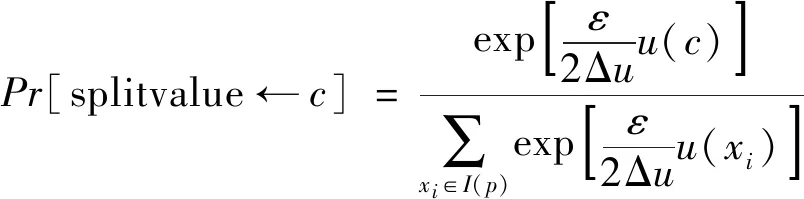
(5)
式中:ε为隐私预算;Δu为式(4)的全局敏感度;u(c)(或u(xi))为c(或xi)的效用分数;I(p)为剪切p的属性值的集合。Age属性最初被概括为[19,75)cut。如果选择[19,75)cut进行分割,将计算每个属性值在19~75范围内的效用得分,并且概率地选择一个值作为[19,75)cut的分割值。考虑21类属性;然后,根据等式(4),u(21)计算如下:
u(21)=H21(D)-
0.144 5。
在计算完所有的u(·)后,式(5)用于计算每个值被选作实际拆分值的概率。首先,为dnum数值属性初始化分割值,其中dnum是数值属性的数量。然后,针对每一轮专业化,概率性地选择切割。如果切割是设置值的,则应验证其非空子节点,以确定它们是否真的是“非空”;如果切割为数字,则为其选择分割值。请注意,这两种情况是互斥的。每个叶分区节点中的确切记录数不能直接发布,因为对于不同的数据,该数目可能不同。可以通过在每个节点中的记录数量上增加噪声来掩盖这种差分。
3.2 隐私分析
定理1DPHeter满足ε-差分隐私。
定理2DPHeter时间复杂度为O(h·nlog2n)。
证明:DPHeter为数值属性选择一个时间复杂度为O(nlog2n)地分割值,其中n是输入的大小数据集。dnum数值属性确定拆分值,其时间复杂度为O(dnum·nlog2n)。通过遍历具有d属性,其时间复杂度为O(d·nlog2n)的输入数据集,然后DPHeter无需遍历所有数据记录,而是根据为∪cut中候选数据保留的某些信息来计算效用分数;因此相应的时间复杂度仅要求是O(n)。根据定义4,从指数机制选择切割时,它的成本与离散切割的数量成正比。因此,基于概率选择算法的成本为O(|∪cuti|),其中|∪cuti|是∪cuti的大小,数值属性选择的时间复杂度为O(nlog2n)的分隔值。通常|∪cuti|比n小的多。因此,循环迭代效能满意算法成本为O(h·nlog2n)。其他计算均可以在恒定的时间O(1)内被完成。因此,DPHeter的总运行时间为O(h·nlog2n)。
4 实验与分析
4.1 实验设置与数据集
所有的实验都是在一台3.4 GHz的CPU为英特尔酷睿i7,内存大小为16 GB,操作系统为Windows 10(64位)的个人电脑上进行的。下面所给出的每个结果都是运行5次以上的平均值。
实验使用了两个公开的数据集,即Adult和MIMIC-III。Adult数据集包含人口普查记录,文献表明,该数据集已广泛用于测试匿名方法。在实验中,删除了类标签,并将此数据集用于聚类分析。为了综合一个异构数据集,假设一个人可以有多个职业,然后将具有相同属性值的记录组合到一条记录中,从而使职业属性为集值。为了综合处理,放弃了三个数值属性(即fnlwg,资本收益和资本损失)、因为它们可能产生更少的异构记录。因此,保留了28 308条记录,这些记录具有7个分类属性,6个数字属性和一个集值属性。为简化问题,将合成数据集称为Adult。
第二个数据集MIMIC-III是医疗研究的重要公共资源。它由一些临床注释表组成,包括护理记录和出院摘要。具体来说,根据共享的subject_id列将三个表连接在一起。然后,将相同subject_id的多个ICD-9代码合并为一行。检索了48 612条记录,并选择了7个分类属性,即性别、婚姻状况、宗教、种族、入学类型、保险方式、入学来源和一个集值属性ICD-9代码。
选择K均值和平分K均值仅包含一个算法参数,即聚类数K,而不是考虑聚类参数的不同组合[16-17]。任何聚类算法都需要某种方法来测量对象之间的距离或相似性。因此介绍两个异构记录的语义距离度量。如果让x1、x2表示来自同一域的两个属性值,则x1和x2之间的距离计算如下:
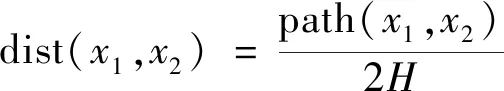
(6)
式(6)中:path(x1,x2)为x1和x2之间最短路径的长度;H是相应分类法树的高度。归一化定义的优势在于,分类树的所有叶节点可以具有不同的深度。两个异构记录之间的距离,即r1和r2,定义为
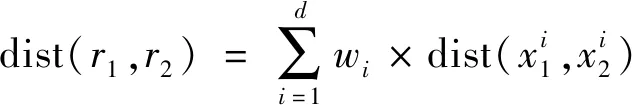
(7)
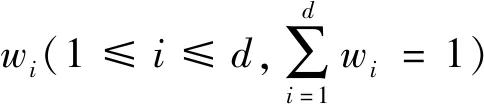
PPDP的目标是在保护可观数据实用性的同时保护原始数据集的私人信息。通过匿名前后的聚类结构的相似性来确定数据实用性。也就是说,匿名化前后的聚类结构越相似,匿名化数据集的效用就越高。在实验中,应用两个指标F-measure和MatchPoint评估两个聚类结构的相似性。
考虑两个聚类结构T和P,将T中的每个聚类Ti视为“真实聚类”,将P中的每个聚类Pj视为“预测聚类”。令numij表示同时包含在Ti和Pj中的记录数,并且|·|表示聚类中对象的数量。Ti和Pj的聚类精度(Precison)、召回率(Recall)和F测度F-Measure计算如下:
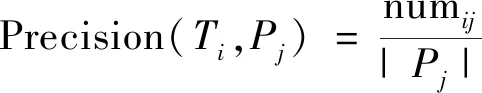
(8)
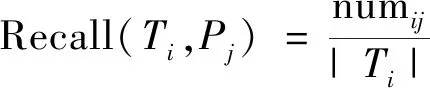
(9)
F(Ti,Pj)=2×
(10)
它测量聚类Pj预测的准确性,该预测基于Precison和Recall描述了真实的聚类Ti。真实聚类Ti的成功预测是通过Ti的“最佳”预测聚类Pj来衡量的,即Pj的最大化F(Ti,Pj)。因此,加权最大F-Measure的总和用于评估聚类结构P的质量,并且P的整体F-Measure计算为
(11)
式(11)中:|D|是原始数据集D中的记录数。F-Measure(P)的范围是0~1。F-Measure(P)的值越大,比较的两个聚类结构越相似。
如果两个保留在同一个聚类C1中的记录在C2中一起保存,并且C1中不同聚类的两个记录被分在C2中不同的聚类里则说明两个聚类结构C1和C2相同。对于每个聚类结构,都将生成一个方矩阵Matrix(·)来表示每对记录之间的关系。也就是说,如果第i个记录和第j个记录在同一聚类中,则Matrix(·)的第(i,j)个元素等于1;否则等于0。然后,定义MatchPoint来表示Matrix(C1)和Matrix(C2)中出现的相同值的百分比:
MatchPoint[Matrix(C1),Matrix(C2)]=
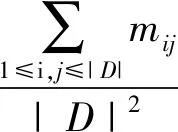
(12)
如果Matrix(C1)和Matrix(C2)中第(i,j)个元素的值相同,则mij=1;否则,mij=0,并且|D|是原始数据集D中的记录数。MatchPoint的范围是0~1。MatchPoint的值越大,比较的两个聚类结构越相似。
4.2 结果分析
4.2.1 数据实用性和隐私
在该实验中,改变了隐私预算ε,专业化数目h和聚类数k,以观察F-measure和MatchPoint。
图2~图5显示了Adult的结果。其中,图5(a)显示了当ε=0.1且h=4时,最小F-measure为0.540 8。图5(a)还显示当ε=0.1且h=16最大F-measure为0.784 0。与F-measure相比,不同于ε和h值的MatchPoint值的跨度较小,在0.727 0~0.931 4范围内。有一个明显的趋势表明随着较高的ε导致较少的干扰和较少的噪音,F-measure随ε的增加而增加。另外,F-measure和MatchPoint也随着h的增加而增加,因为更详细的信息保留在用于聚类的匿名数据集中。但是,从一定的h开始,随着h的进一步增加,F-measure和MatchPoint保持相同或减少。这是因为h的值越高,表示分区树中的叶子节点越多,并且叶子节点的数量越多,作用于这些叶子中的记录数的拉普拉斯机制产生的噪声越多节点。图6~图9显示了MIMIC的F-measure和MatchPoint值的相似趋势,只有在获得最佳性能的情况下和h的值不同。这些结果表明,DPHeter即使对于不同的匿名性要求,也可以在匿名化后保持原始数据集的相似聚类结构。

图2 3均值Adult数据的效用Fig.2 3 utility of mean Adult data

图3 5均值Adult数据的效用Fig.3 5 utility of mean Adult data
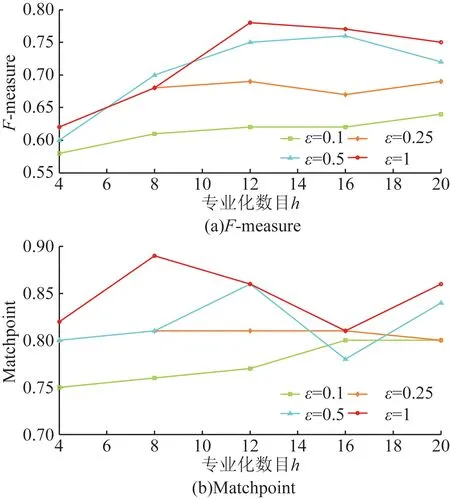
图4 对等分3均值Adult数据的效用Fig.4 The utility of Adult data with equal 3-means
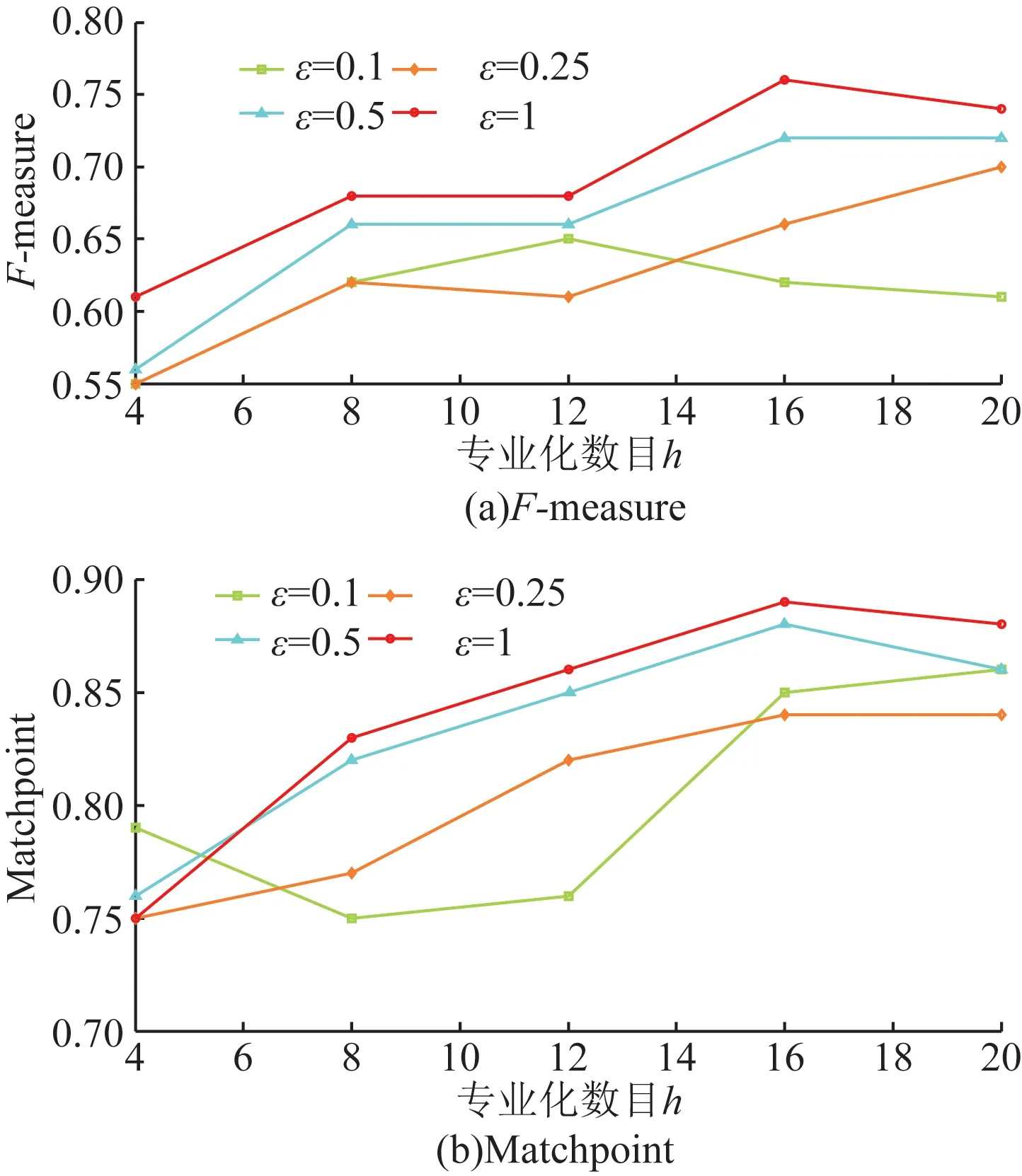
图5 对等分5均值Adult数据的效用Fig.5 The utility of Adult data with equal 5-means
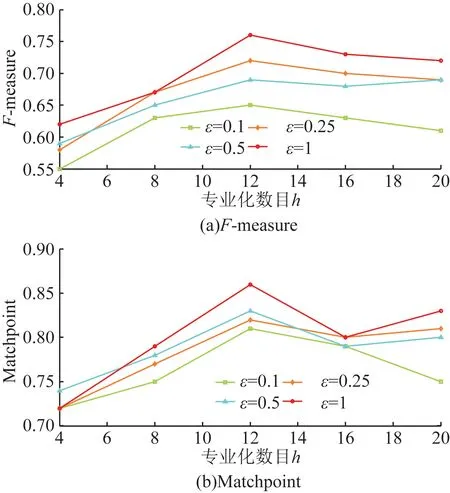
图6 3均值匿名MIMIC的数据效用Fig.6 3 utility of mean MIMIC data
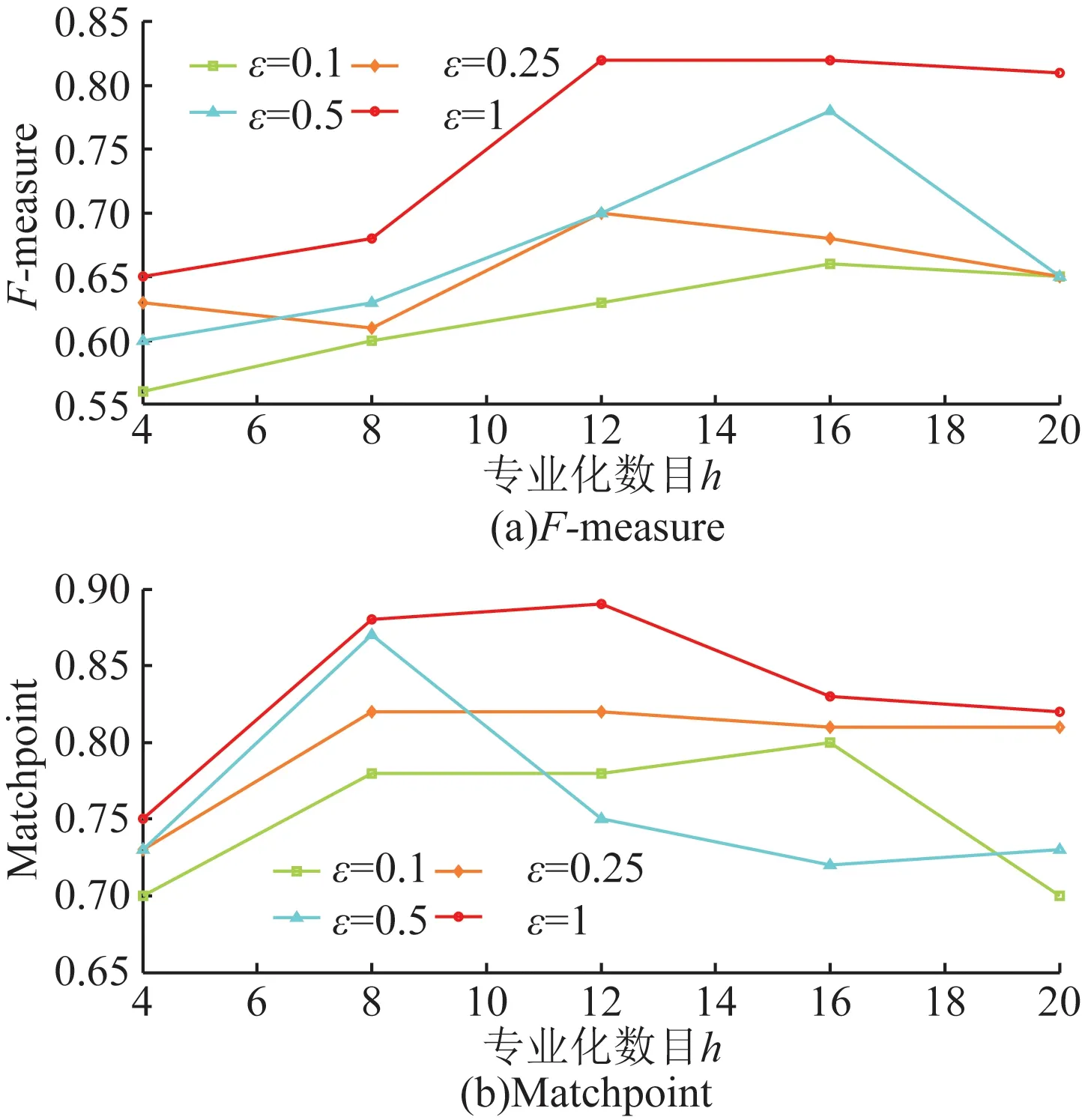
图7 5均值匿名MIMIC的数据效用Fig.7 5 utility of mean MIMIC data
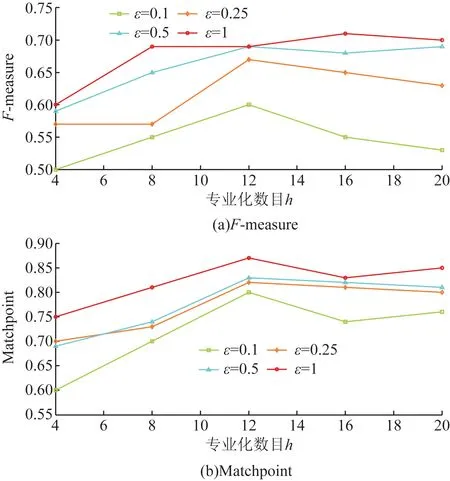
图8 对等分3均值匿名MIMIC的数据效用Fig.8 Data utility for 3-means anonymous MMIC
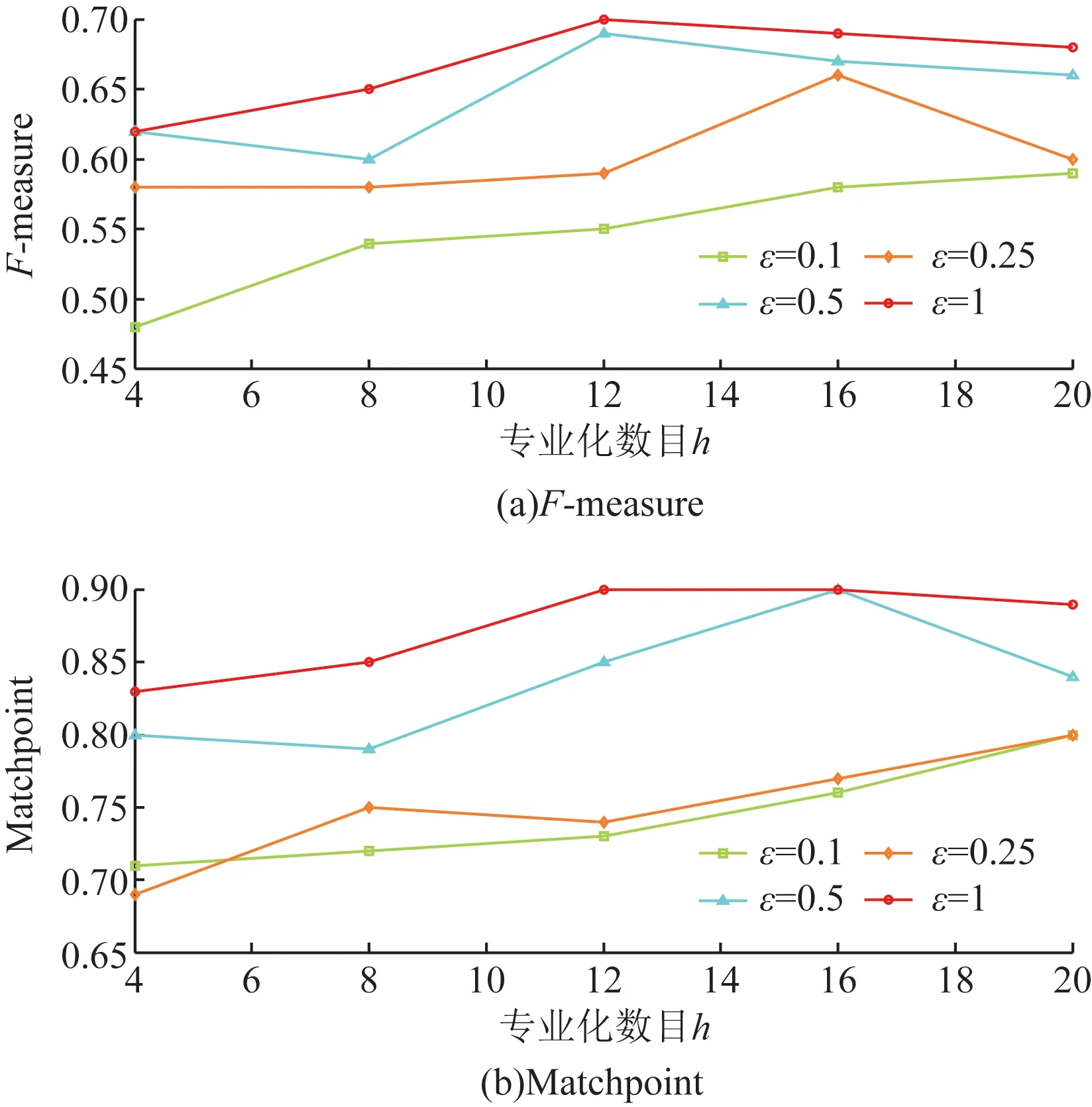
图9 对等分5均值匿名MIMIC的数据效用Fig.9 Data utility for 5-means anonymous MIMIC
4.2.2 不同匿名化算法上的数据实用程序
为了验证提出的聚类算法聚类质量是否比没有这倾向的一般差分隐私的聚类质量更好,在ARX工具中将本文算法与(ε,δ)-差分隐私进行了比较。(ε,δ)-差分隐私是ε-差分隐私的松弛版本,因为前者允许以δ为边界的错误概率。因为只有关系数据可以输入到ARX,所以首先将异构的Adult和MIMIC转换为关系数据。具体来说,将为值属性集合的每个值创建一个二进制属性。例如,如果属性是值集合的并且具有两个值,即x1和x2,则记录的模式将为“0 1”“1 0”或“1 1”。此类转换仅对ARX执行,对DPHeter不执行。之所以为(ε,δ)-差分隐私设置δ=1×10-5和δ=1×10-11,是因为对于该工具,这两个值分别是最大和最小可接受值。将DPHeter的h固定为16。结果如图10~图13所示。这些数字表明,在每个隐私预算上,DPHeter的F-measure值明显优于(ε,δ)-差分隐私。例如,在图11(a)和图13(a)中,即使ε=0.1,Adult的F-measure为0.633 1,而MIMIC的F-measure为0.642 8,而当δ=1×10-5时Adult和F-measure的(ε,δ)-差分隐私的F-measure分别仅为0.201 5和0.332 8,但是,MatchPoint值之间的差分较小。这是因为匿名前后位于不同聚类中的两个记录的情况也对MatchPoint的值起了积极的意义。

图10 Adult数据不同的5-均值匿名算法Fig.10 Different 5-means anonymity algorithms for Adult data
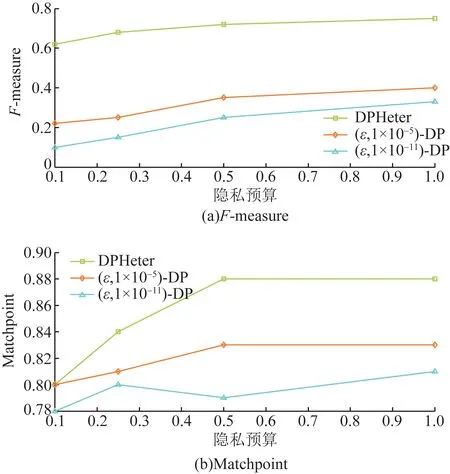
图11 Adult数据不同的对等分5-均值匿名算法Fig.11 Different 5-means anonymity algorithms for Adult data
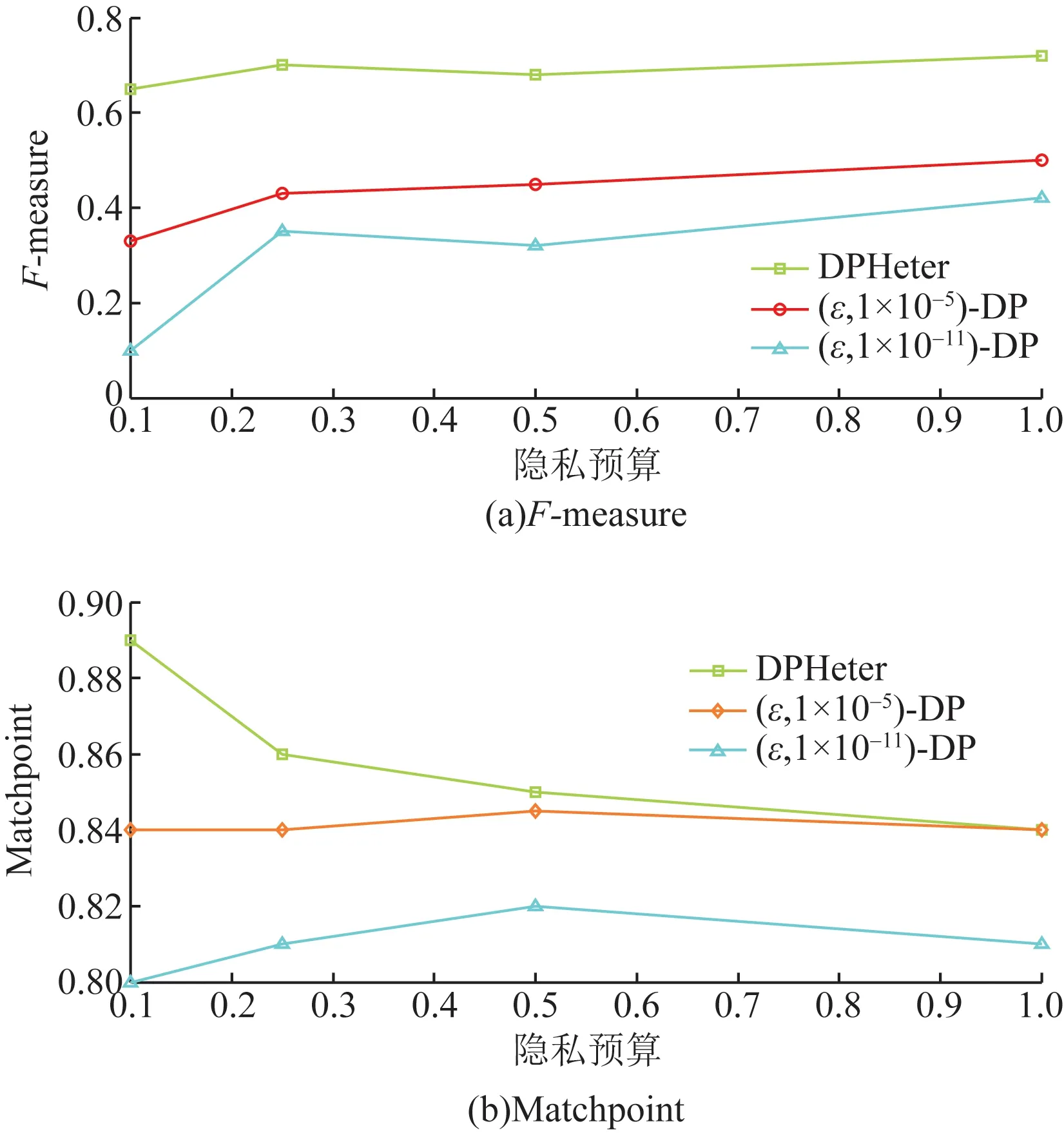
图12 5均值的MIMIC匿名算法Fig.12 5 mean MIMIC anonymous algorithm
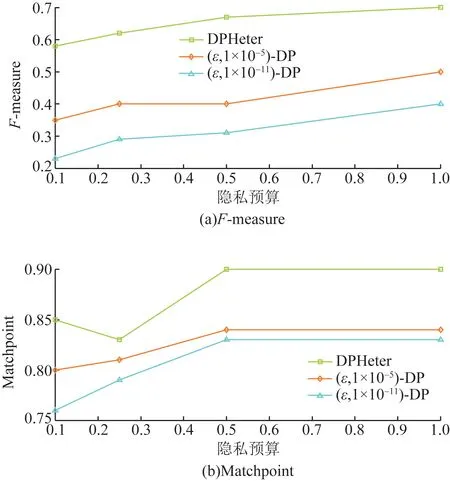
图13 对等分5均值的MIMIC匿名算法Fig.13 5 mean MIMIC anonymous algorithm
当0.1≤ε≤1评估ARX工具中DPHeter相对于(ε,1×10-5)的DPHeter改进时,还对0.1≤ε≤1成对测试用例进行了一系列单尾t检验。证明DPHeter的改善在α=5%时具有显著地统计学意义。从这些结果可以推出,提出的方法在聚类质量方面胜过了一般的匿名化方法。
4.2.3 可扩展性
在可扩展性方面,将DPHeter与ARX中的(ε,δ)-差分隐私进行了比较。与第4.2.2节中的实验相似,为(ε,δ)-差分隐私设置δ=1×10-5和δ=1×10-11,为DPHeter设置h=16。并固定了ε=1并进行了5-均值聚类。通过随机复制它们的记录,生成了多个版本的Adult和MIMIC。为了比较,图14显示了具有200 000~1 000 000条数据记录的DPHeter和ARX在Adult和MIMIC上的结果。该图表明,在运行时方面,ARX比DPHeter更有效,因为ARX不考虑数据分析任务。在搜索数值属性的分割值时,DPHeter将计算当前值范围内所有可能数值的效用分数。在拆分集值属性时,DPHeter根据分类树考虑当前父节点的子节点的组合。通过维护和更新信息,而不是重复扫描所有数据记录,进一步提高了DPHeter的运行速度。而在MIMIC上花费的时间比在Adult上花费的时间更长。这是因为中有成千上万个代码,并且相应的分类树比t中的职业属性树大得多,这意味着选择代码属性进行拆分时需要更多的计算时间。
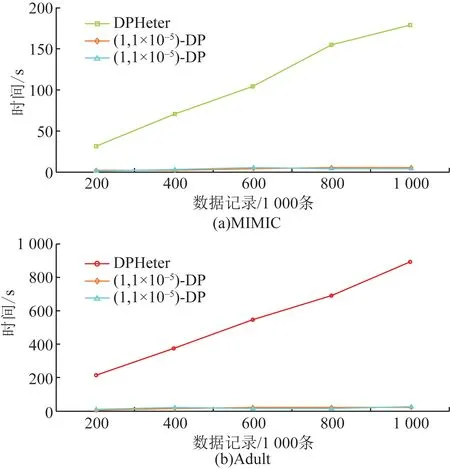
图14 两个数据集的可扩展性Fig.14 Scalability of two datasets
DPHeter的适应性。虽然在第4节中只使用了k-均值和等分k-均值来评估DPHeter的性能,但是其他的聚类算法,如DBSCAN,可以集成到本文算法中。本文算法提供了一个灵活的框架,在这个框架中,聚类算法可以被视为“插件”组件。DPHeter利用将聚类结果对原始数据进行匿名化处理,而并非一种聚类算法。然而,数据匿名化前后用于聚类的距离度量应该保持不变,或者至少相似,以获得更好的数据效用。否则,不同聚类策略所生成的聚类结构将会完全不同。同时,DPHeter的关注点是在数据发布的前后保持聚类结构的相似性。如果原始数据不适用于聚类分析或者某些聚类算法无法产生好的聚类结果,那么DPHeter就无法帮助数据或其匿名版本生成更好的数据。
5 结论
提出了一种用于聚类分析的异构数据发布方法。该方法利用聚类标签对聚类结构进行编码,并结合泛化技术和输出扰动来掩盖原始数据。通过分析实验结果可得如下结论。
(1)提出的方法即使对于不同的匿名性要求,也可以在匿名化后保持原始数据集的相似聚类结构。
(2)引入了差分隐私方法的聚类质量比为引入差分隐私的匿名化方法更高,说明差分隐私有助于聚类性能的提高。
(3)提出的方法提供了一个适应性较强的框架,可以结合不同的聚类算法,且都能够具有良好的数据实用。在这些不同实体聚类算法中使用的记录之间的距离度量应保持相同或相似。否则,由不同聚类算法产生的聚类结构可能完全不同。
