基于随机森林和XGBoost算法的二手车价格预测*
2021-07-28郑婕
郑婕
(北方工业大学,北京 100144)
0 引言
随着机器学习的广泛发展与应用,简单的学习器或模型已经满足不了需求,集成算法应用而生。所谓集成算法,需要构建多个学习器,然后用一些方法巧妙的将它们结合在一起,再来完成学习任务的,这样可以获得比单一学习效果更好的学习器。周志华[1]指出个体学习器的“准确性”和“多样性”本身就存在冲突,一般准确性很高之后,要增加多样性就需牺牲准确性。产生并结合‘好而不同’的个体学习器,正是集成学习研究的核心。按照个体学习器之间的关系,分为Bagging、Boosting、Stacking三大类。
Bagging的原理首先是基于自助采样法(bootstrap sampling)一些样本被随机的得到来训练出不同的基学习器,然后对这些不同的基学习器进行投票,得出分类结果,随机森林就是这个算法的典型代表[2]。随机森林具有广泛的应用,宋欠欠[3]在运用随机森林对高维数据变量筛选的研究中指出利用随机森林算法进行变量筛选结果稳定,并能够保证良好的预测效果。
Boosting,提升算法,它通过反复学习得到一系列弱分类器,一个强分类器由这些弱分类器组合得到,此时,弱学习器是强学习器提升的过程[1]。总体而言,Boosting的效果要比Bagging好,但是这个算法中新模型是在旧模型的基础上生成的,就不能用并行的方法去训练,并且由于对错误样本的关注,也可能造成过拟合。Boosting的算法族中有很多有名的算法,比如Adaboost、GBM、XGBoost[4]。陈天奇[5]在对XGBoost的算法研究中指出稀疏数据和加权分位数草图提供了一种新的稀疏感知算法,用于近似数学习算法上的优化使得在利用其进行预测计算时可以得到更加准确的结果。最后一类Stacking训练一个模型用于组合其他各个基模型。具体方法是把数据分成两部分,用其中一部分训练几个基模型A1,A2,A3,用另一部分数据测试这几个基模型,把A1,A2,A3的输出作为输入,训练组合模型B,Stacking可以组织任何模型,实际中常使用单层logistic回归作为模型[6]。
在用算法进行预测时,常用到的算法有X GBoost、GBDT、LightGBM、神经网络算法等,魏长亮在对岩柱稳定性的预测研究中使用了这三种算法进行对比,并使用五重交叉验证寻求每个模型的最优参数配置再进行预测[7]。谢勇对每月住房租金进行预测时使用了XGBoost和LightGBM两种算法进行预测对比,发现 XGBoost的表现更好[8]。所以通过文献综合本文在进行二手车价格预测上选择了比较经典的XGBoost算法,同时将它和GBDT、LightGBM两个算法进行对比,得出XGBoost预测误差最小,性能最好。
我国有一个庞大的二手车需求市场,二手车的销售对市场经济有很大的作用,市场潜力很大,但是目前它的潜力还没有完全发挥出来。二手车的交易价格受许多因素的影响,车的型号,行驶里程,车的配置,实用年限,包括车的车系、颜色、品牌溢价这些因素都会影响二手车的交易价格。当然,对于不同的二手车交易市场,所处的地理位置的消费水平,人均可支配收入等,也影响着二手车的交易价格[9]。
1 数据预处理
二手车的数据来自于阿里云天池大赛,共有3个数据集,这里用到的是Car train数据集,由于原始数据集并非结构化数据,因此数据预处理首先对数据集进行结构化处理。用众数填充缺失值较多的样本。原始数据包含31列变量信息,其中15列为匿名变量,共150000个样本。本文运用scikit-learn中的train_test_split函数对数据集进行拆分,测试集的比例设为20%,最终训练集和测试集的划分如表1。

表1 数据集表Tab.1 Data set table
在对特征变量进行观测时发现变量“seller”和“offer Type”存在严重的偏态分布,特征倾斜严重的变量直接删除。同时对预测变量的分布观测发现不符合正态分布如图1。
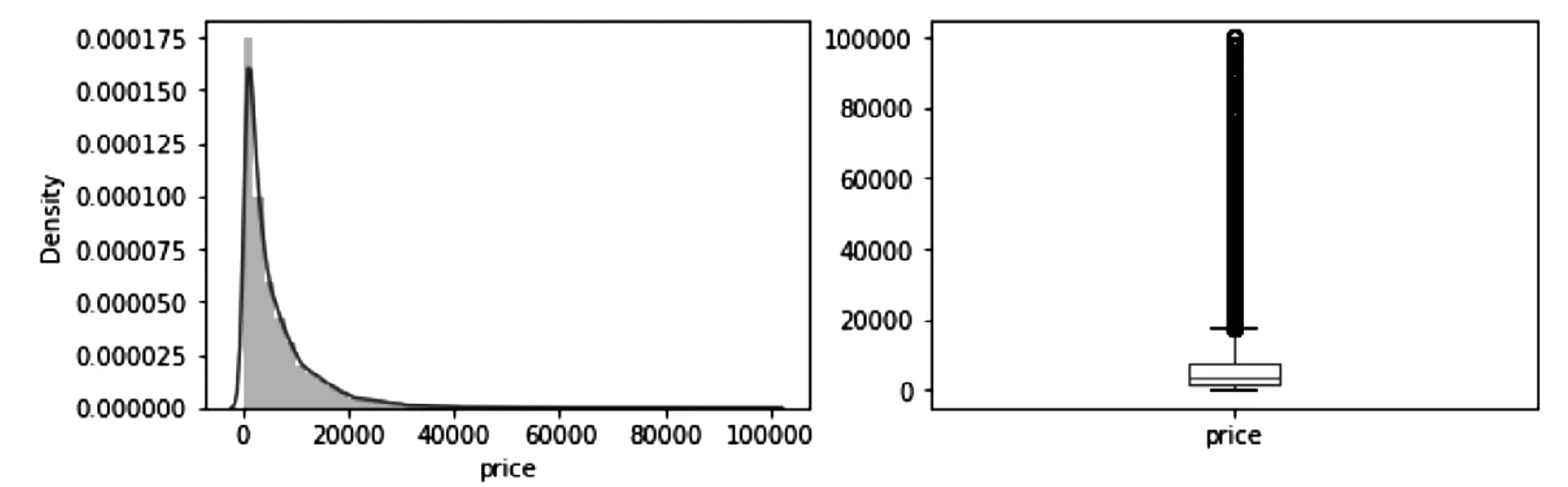
图1 Price分布图Fig.1 Price distribution
所以对预测变量price采取对数变换得到如图2。
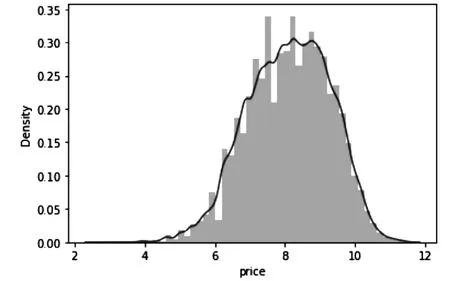
图2 对数变换后Price分布图Fig.2 Price distribution graph after logarithmic transformation
数据预处理这个过程运用了python中的numpy、pandas等模块,结合excel等办公软件,大大提高了数据预处理的工作效率。
2 变量选择
经过数据预处理后对数据变量进行特征工程,对原有的变量进行特征构建得到新变量,例如汽车使用时间为creatDate- regDate,城市信息从regionCode也就是邮编中提取,通过brand和price计算品牌的销售额,构造新的变量进行预测。
二手车的数据集中有150000个样本,每个样本都有31个变量,1个观测变量,30个特征变量,为找到可操作变量中的主要因素,更好地预测二手车的价格,找到影响二手车价格的最高因素,本文选择使用随机森林算法进行变量选择。
随机森林是从数据表中随机选择K个特征建立决策树,重复n次。这K个特征经过不同随机组合建立起n棵决策树,对每个决策树都传递随机变量来预测结果,从n棵决策树中得到n种结果。决策树会预测输出值,通过随机森林中所有决策树预测值的平均值计算得出最终预测值,最终得到筛选出的K个变量的重要度。在随机森林中某个特征X的重要性的计算方法如下:
(1)在随机森林中的每一棵决策树,都用它对应的袋外数据即OOB,去计算它的袋外数据误差即errOOB1。
(2)在袋外数据OOB的每一个样本的特征X加入噪声干扰这样可以随机改变样本在特征X处的值,然后再计算袋外数据误差,记为errOOB2。
(3)当我们假设随机森林有N棵树时,用∑(errOOB2-errOOB1)/N来表示X的重要性,特征被随机加入噪声后,如果袋外准确率下降很多,就表明此特征对样本分类结果影响很大,这表明它的重要程度高[10]。
通过随机森林对变量重要度进行排序,变量包括汽车交易ID、汽车交易名称、汽车注册日期、车型编码、汽车品牌、车身类型、燃油类型、变速箱、发动机功率、汽车已行驶公里、汽车有尚未修复的损坏、地区编码、汽车上线时间、匿名特征,以及包含v0-14在内15个匿名特征。本文选择分数不为零的变量作为预测价格的特征变量,共9个变量,如表2所示。
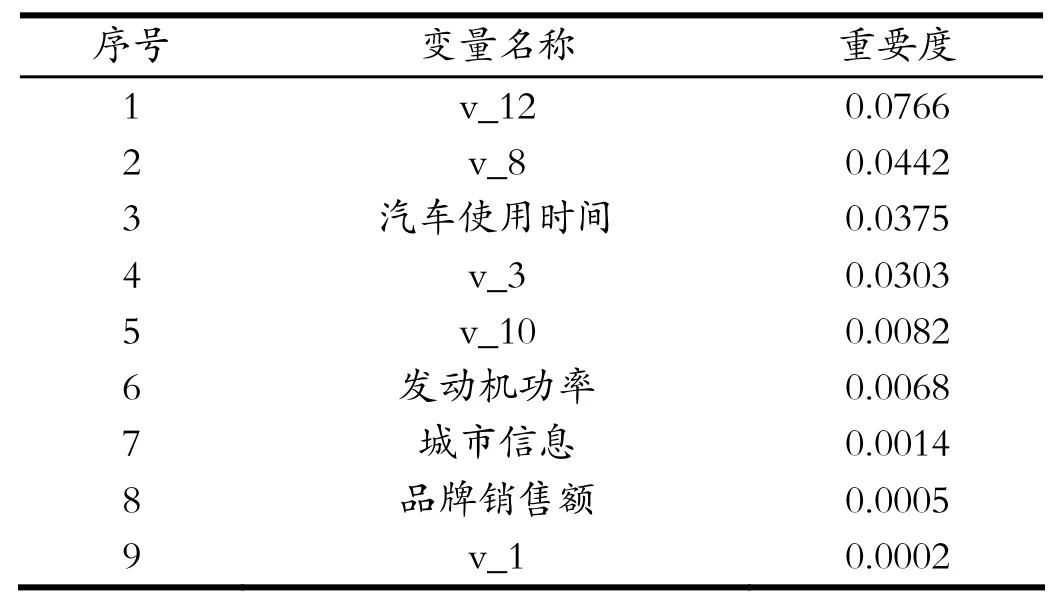
表2 变量名称表Tab.2 Variable name table
3 建立模型
运用随机森林筛选出9个变量后,用XGBoost进行回归任务,建立XGBoost模型对二手车的价格进行预测,使用训练集进行参数训练,测试集进行预测[11]。
3.1 XGBoost原理

其中K为分类器的总个数,f(x)表示第k分类器,表示集成K个分类器后对样本xi的预测结果,损失函数表示为:
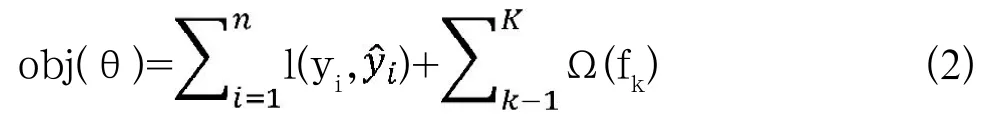

显然无法直接通过计算得出f*(x)的解,所以我们要考虑优化的方法,f(x)为决策树模型,给出权重w和树结构q即可确定一棵决策树,而树结构q实质上就是划分分裂节点的问题,所以f*(x)可以转化为找最优权重w和划分分裂节点的问题[6]。
…
此时利用泰勒展开式近似目标函数:

通过安全管理制度的应用,可以有效的约束建筑施工过程中存在的不安全行为,减少安全事故的发生,保障建筑工程的顺利开展。但是很多建筑工程的安全管理体制都存在不完善的情况,要么是从其他建筑项目“生搬硬套”而来,不符合企业本身特点,导致在应用过程中很难有效执行落地;要么安全管理制度形同虚设,缺少执行力,导致建筑施工项目的安全事故仍时有发生。
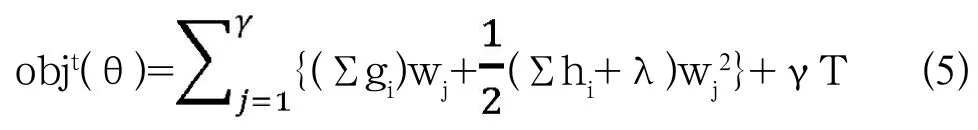
此时令Gi=∑gi;Hj=∑hi,代入上式wj求偏导,使其导函数等于0得到:

3.2 网格搜索
网格搜索法是一种寻找最优参数的方法,它是将估计函数的参数用交叉验证的方法得到的一种算法,将每个参数的可能取值进行排列组合,把所有可能的形式用“网格”的形式表示出来,再对它进行评估,在计算机上对每种可能的参数形式进行计算训练狗,得到一个最优的参数组合。网格搜索虽然比较耗时,但是它有很广泛的搜索范围,有很大可能找到最优参数组合[12]。使用GBDT、LightGBM和XGBoost模型建模分析时,参数的选择对模型的预测结果有着较大的影响,故需要对若干参数进行调优使用网格搜索对上述模型参数进行自动寻优, 首先确定学习率,把learning_rate设置成0.1,其他参数使用默认参数,使用GridSearchCV函数进行网格搜索确定合适的迭代次数,找到合适的迭代次数后使用GridSearchCV函数对模型的其他两个主要参数进行网格搜索自动寻优,减小(增大)学习率,同时增大(减小)迭代次数,找到合适的学习率是使得在误差最小时迭代次数最少,找到最优参数[13]。
3.3 实证分析
网格搜索的结果分别如表3所示。

表3 XGBoost网格搜索结果Tab.3 XGBoost grid search results
由网格搜索结果可以得出,max_depth=9,它表示树的最大深度为9,main_child_weight=7,决定最小叶子节点样本权重和,它是为了防止过拟合。n_estimators=300,是弱学习器的最大迭代次数,或者说最大的弱学习器的个数。一般来说n_e s t i m a t o r s太小,容易欠拟合,n_estimators太大,计算量会太大,并且n_estimators到一定的数量后,再增大n_estimators获得的模型提升会很小,该模型中选择的值是300。Scores=0.9345858224796677这个参数状态下的模型打分约为0.935,效果较好。
由网格搜索结果表4可以得出,树的深度为7,main_child_weight=1,n_estimators=95时Scores=0.9333038265 163888这个参数状态下的模型打分约为0.933,效果较好。

表4 LightGBM网格搜索结果Tab.4 LightGBM grid search results
由网格搜索结果表5可以得出,树的深度为7,main_samples_split=1,n_estimators=100时Scores=0.93492 00615330541这个参数状态下的模型打分约为0.935,效果较好。

表5 GBDT网格搜索结果Tab.5 GBDT grid search result
将网格搜索出的最优参数分别带入到GBDT、Light GBM和XGBoost中进行预测,得到如表6所示结果。
由表6对比结果所示,XGBoost模型在预测值与实际值的拟合度上表现较好。其预测性能高于GBDT模型的预测性能,与lightGBM模型进行比较也具有相对优势。表6显示XGBoost模型在MSE具有出色的表现。
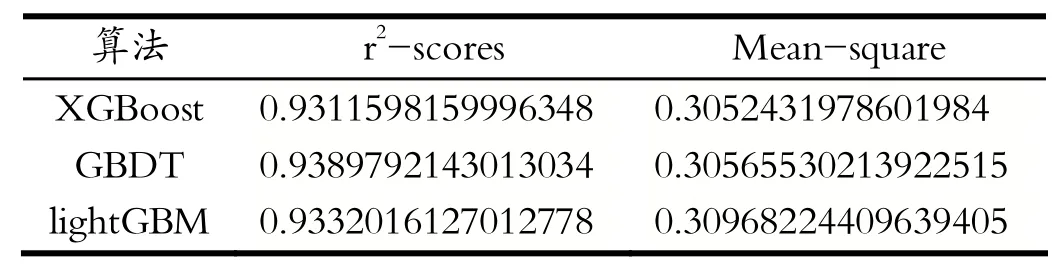
表6 对比结果Tab.6 Compare results
4 结论与建议
本文使用3种机器学习模型对二手车价格进行预测,XGBoost和lightGBM作为机器学习近年提出的新方法,比传统GBDT能达到更好的预测精度,同时XGBoost在模型拟合程度和均方误差上的表现都远超Light GBM和GBDT。本文的不足之处在于XGBoost虽然能够得到较好的预测精度,但是XGBoost是基于启发式算法,寻找的解为局部最优并非全局最优。
