基于RISC-V的卷积神经网络专用指令集处理器
2021-07-26廖汉松吴朝晖
廖汉松,吴朝晖,李 斌
(1.华南理工大学微电子学院,广州510641;2.人工智能与数字经济广东省实验室(广州),广州510330)
0 概述
RISC-V 是一种基于精简指令集计算(Reduced Instruction Set Computing,RISC)原则的开源指令集架构,由于其相较于x86、ARM 架构可以更低成本地针对不同应用领域进行定制和优化,因此成为近年来的研究热点[1-3]。另一方面,人工智能现已渗透到各行各业,出现了诸多智慧化产品。在主流的运算平台中,GPU 功耗和成本过高[4],FPGA 资源和速度有限,ASIC 通用性较差[5-7],技术积累深厚的CPU 平台更适合对成本敏感、算法灵活多变和计算步骤复杂的领域,但目前通用的CPU 仍难以满足神经网络大规模计算的要求。
由于登纳德缩放比例定律失效和摩尔定律减缓,物联网领域常用的CPU 平台难以单纯地通过提高处理器工作频率、集成更多核心等手段来满足神经网络算法对端侧算力日益增长的需求[8]。采用领域专用架构(Domain Specific Architecture,DSA),面向领域应用定制处理器核心和集成异构核心能够更有效地提高能效,然而此方案却受限于主流x86、ARM 架构的商业局限性而难以普及,而具有先进设计理念优势的开源架构RISC-V 则能有效避免这些问题。
为应对计算强度特别高的算法(如神经网络算法),本文参考领域专用处理器架构,基于RISC-V 指令集,针对特定应用领域的需求设计专用拓展指集处理器,利用卷积神经网络(Convolutional Neural Network,CNN)的并行性对常见网络运算进行硬件加速,使其同时具备CPU 的通用性、灵活性和ASIC 的高能效优势。
1 研究背景
1.1 RISC-V 架构处理器
RISC-V 是2010年由伯克利加州大学研究者研发的开源指令集架构,相比于x86 和ARM 等架构,其无需考虑前向兼容性,可对多年来旧架构暴露的问题和缺陷进行完善改进,而无须将一些冗余低效甚至错误的设计保留在其中[2],如去除分支延迟槽、去除使用频率低却影响处理器乱序执行的条件执行指令、仅实现一种简洁的内存寻址模式等。编译器软件随着多年发展得以完善,许多使用硬件优化的手段可被软件取代,硬件设计可以更加简洁。以往依赖于硬件加速的设计,可能已经不再发挥作用,甚至阻碍优化。RISC-V 还采用了不同寻常的模块化设计,将不同的指令划分成可选的拓展。使用基础指令集+拓展指令集的模式,除了基础指令集必须实现外,还可以根据应用的需求、高性能或是低功耗,选择是否添加这些拓展指令集。而且这个开放的指令集中保留了大量的操作码空间,以便添加用于领域专用加速器的自定义指令。RISC-V 的这种设计既能满足软件生态的兼容,又能在保证处理器尽可能精简的同时添加领域专用加速器。
本文定制的Rocket 处理器是由伯克利大学的ASANOVIĆ 等人开发的一款经典5 级流水线的单发射标量处理器核心[9]。该处理器由基于Chisel(Constructing Hardware in a Scala Embedded Language)构建的开源SoC 设计平台Rocket Chip 生成。面向对象语言使得开发硬件更加灵活,通过Rocket Chip平台,可以对处理器进行高度定制化。除了面向特定应用开发专属的自定义模块,只需要调整参数即可对已有的处理器核心数、指令集拓展、Cache 配置、总线等进行调整,最后编译出所需的定制处理器。由于专用指令集处理器的设计十分复杂,生产成本也很高,为确保可靠性,一般都会采用模拟器对处理器进行建模和验证。由于Rocket Chip 平台原本就由高级语言进行构建,因此能够快速生成配套的C++模拟器,大幅缩短处理器的验证时间,降低开发成本。
此外,Rocket Chip 平台还提供RoCC(Rocket Custom Coprocessor)接口用于加入自定义的加速器。加速器可使用以下3 种方式接入:
1)接入处理器的指令处理流水线。Rocket 核将相关指令发射到RoCC 接口,加速器只能通过指令和通用寄存器获取命令与数据,完成特定运算后给出响应并回传数据到通用寄存器。
2)增加一级数据高速缓存(L1 D-Cache)访问接口。L1 D-Cache 中缓存了处理器频繁访问的数据,加速器直接通过高速缓存读写数据,能够更高效地获取所需处理数据和回写结果。
3)完全解耦。通过总线直连到外部内存系统,更适用于数据庞大且重用性低的情况。
1.2 轻量化卷积神经网络
为获得更好的性能,神经网络研究向更深、更复杂的方向发展。然而在使用神经网络落地解决实际问题时,受限于终端设备的算力、内存大小和低功耗、低成本的应用场景,很多经典的网络模型都难以实现。因此,研究者着手于网络优化,通过以1×1 和3×3 卷积核取代大尺寸的卷积核、以全局池化层取代全连接层等手段简化模型的复杂度,减少网络参数的数量[10-12]。经典网络模型与轻量化网络模型比较[13-15]如表1所示。可以看出,准确率相近的SqueezeNet网络与AlexNet网络参数量相差约50 倍,前者显著降低了计算时对算力的需求和内存的消耗。

表1 经典网络模型与轻量化网络模型的对比Table 1 Comparison of classical network model and lightweight network model
2 处理器设计方案
本文提出如图1所示的专用指令集处理器设计方案,主要分为两个部分,即Rocket 核和用于卷积神经网络运算的加速器。为使处理器尽可能精简,在Rocket 核部分选择RV32IMAFC 架构,其中32 位宽的处理器足以覆盖物联网设备的内存范围。Rocket 核负责完成算法的逻辑控制和图像预处理,在此基础上使用自定义拓展指令触发加速器完成CNN 中的密集计算。通过自定义拓展指令配置卷积神经网络各层的信息,对输入数据进行分组并灵活调整加速器的数据通路,从而适应不同大小的输入数据,减少片上缓存需求,同时适应轻量化网络的常用运算操作和结构。加速器接收到相关指令后,从片外存储器中获取相应数据,根据指令完成CNN 中卷积、激活、局部池化和全局池化等耗时操作,并将结果回写存储器以待后续处理。加速器没有接入D-Cache,而是以更大位宽的独立读写端口对片外存储器进行访问,完成与Rocket核的数据传递。由于卷积神经网络数据量庞大,因此若不能匹配Cache 大小,则会导致访存命中率低和数据频繁进出,从而降低效率。

图1 本文处理器系统框图Fig.1 System block diagram of the proposed processor
2.1 Rocket 核配置与设计
本设计中处理器并未使用高性能和过多配置,目的是节省更多空间留给CNN 加速器运算单元,具体配置如表2所示。
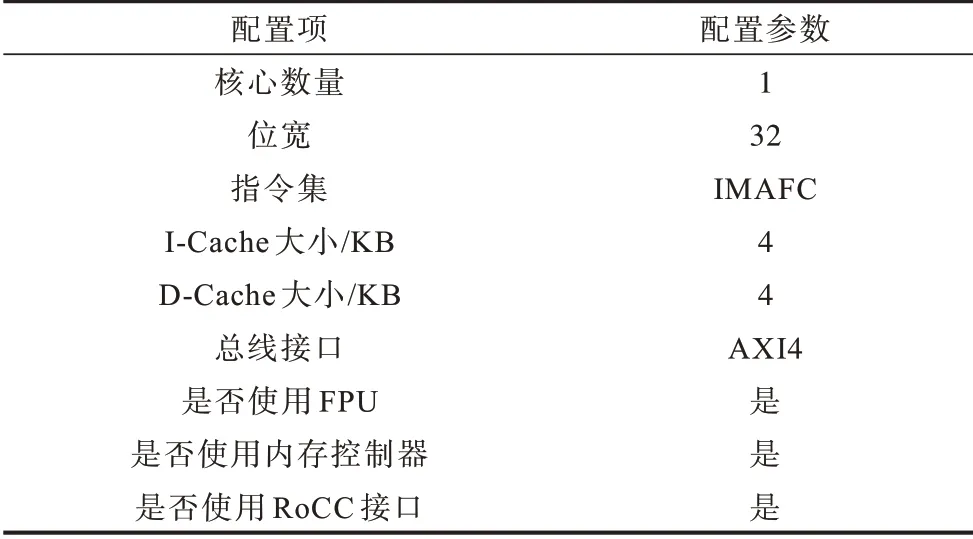
表2 处理器配置Table 2 Configuration of processor
本文设计了如图2所示的2种指令用于CNN加速,包括用于配置加速器寄存器的设置类指令和用于计算的操作类指令。指令中第0 位~第6 位为opcode 字段,处理器解码得到0001011 后会将此类指令发射到加速器模块,第28 位~第31 位的funct4 字段用于标识不同的指令类型,最高位取0 表示为设置类指令,取1 表示为操作类指令。位操作类指令的第28 位~第30 位分别用于指定加速器是否进行卷积、池化操作,第15 位~第19位的rs1字段、第20位~第24位的rs2字段、第25位~第27 位的offset3 字段则用于指定主处理器通用寄存器堆中的编号。其中,offset3 为相对rs2 指定寄存器编号的偏移量,即第3 个寄存器通过[rs2+offset3]来寻址,因此,每条指令最多可传递3 个32 位的源操作数对加速器进行配置。第12 位的xs2 字段、第13 位的xs1 字段、第14 位的xd 字段用于标识是否使用相应字段指定的通用寄存器进行数据传递。xs1 设置为1 表示使用rs1、rs2 指定的通用寄存器传递数据。操作指令中xs2设置为0,表示不需要配置第3 个通用寄存器数据。由于设计中加速器的运算数据通过独立访存端口进行传递,并不需要回传到主处理器的通用寄存器堆,因此xd设置为0,且修改原本用于指定目的寄存器的第7 位~第11 位字段用于传递更多信息。设置类指令中修改为addr 字段,用于指定3 组加速器中用于配置的寄存器,分别存储输入数据、输出数据和网络参数信息。操作类指令中修改为info 字段,用于指定各计算操作的类型,如卷积和池化操作的窗口大小、运算步长、数据四周是否补零。加速器并未实现太细颗粒度加速,而是以每层为单位进行加速。虽然会牺牲一定灵活性,但是细颗粒不利于进一步优化运算,且数据频繁进出加速器影响效率。
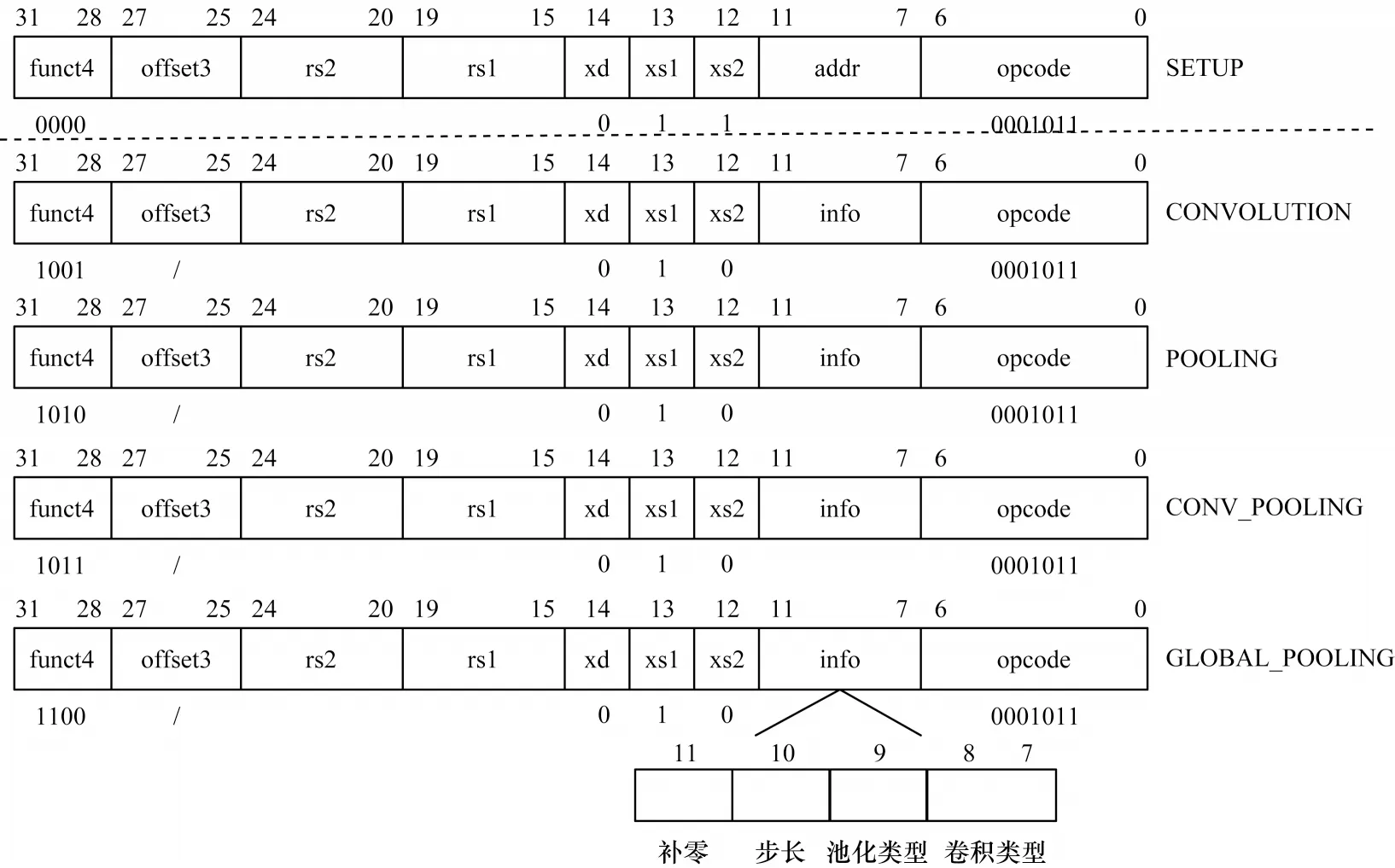
图2 卷积神经网络专用拓展指令Fig.2 Special extension instructions of convolutional neural network
2.2 CNN 加速器设计
2.2.1 数据量化
为在有限资源下实现CNN 加速器设计,本文采用英伟达的使用饱和截取的线性量化方案[16],将网络权重和激活值量化为8 bit。经SqueezeNet 网络验证,与浮点卷积相比,量化后虽然Top1 准确率下降了0.58%,Top5 准确率下降了1.39%,但仍能保持较高准确率。
2.2.2 卷积运算单元设计
卷积模块运算单元如图3所示,采用内存带宽占用相对较低的二维PE 阵列,由16×16 个PE 阵列组成,支持并优化轻量化网络中常用的1×1 和3×3 两种大小的卷积,通过不同映射实现多种并行方式和数据复用。此外,为精简常规PE 阵列之间繁琐的互连,本模块以广播数据的方式,将权值、输入特征图分别从水平方向、垂直方向加载到PE,并且PE 计算结果仅会在一行内累加。
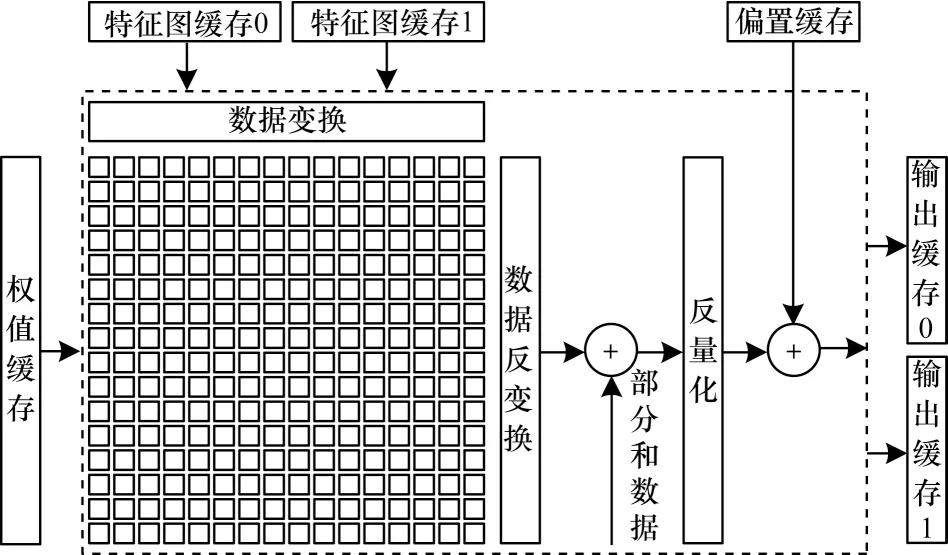
图3 卷积模块Fig.3 Convolution module
卷积过程采用保留卷积核的方式,以1×1 卷积为例,即完成当前16 输入通道内所有数据与卷积核的卷积、卷积核彻底用完,才加载下一组16 通道输入特征图和卷积核。遍历所有输入通道后才能获得完整的输出特征图,中间产生的部分和数据需要保存在输出缓存中。此种方式能够更好地提高数据重用性,卷积时可复用输入缓存内和PE 内的输入特征图,也便于之后模块实现3×3 的池化操作。
为方便阐述该结构实现卷积的运算过程,对PE 阵列进行简化,并分别对1×1 和3×3 两种卷积映射进行分析。
1×1卷积映射如图4(a)所示。每个PE 都可以独立完成运算,并行计算6 通道输入、6 通道输出。PE 阵列不需要分组,数据也不需要变换。6 通道输入特征图分别并行加载至6 列PE,计算结果输出至每行加法树,可同时输出6 通道输出特征图。由于1×1 卷积不需要复用多行数据,PE 内缓存不需要进行额外控制,计算完该6通道输入后,向缓存请求下一组权值和6通道输入,因此遍历所有通道输入特征图并完成部分和叠加,即可得到6 通道完整输出特征图。
3×3卷积映射如图4(b)所示。以步长为3将PE阵列划分为4组,同一列的组处理相同输入特征图,同一行的组处理相同输出特征图。该阵列可并行计算2 通道输入、2 通道输出。每组内3 行PE 分别计算同一输入特征图通道内的3 个卷积窗口,行内每个PE 并行计算卷积窗口内3 个乘法。为简化控制逻辑,每列PE 数据都是广播写入,因此,缓存内写入数据都相同。根据PE位置的不同,卷积时按不同的顺序使用缓存内数据。PE 内有3 个输入特征图局部缓存,最多可缓存3 行输入特征图,实现3×3 卷积行间数据的复用。
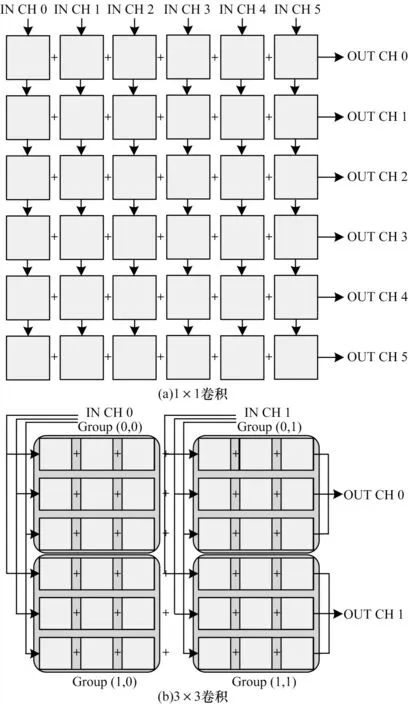
图4 PE 阵列映射示意图Fig.4 PE array mapping diagram
图5 展示了PE 组Group(0,0)计算步长为1 的3×3 卷积时的过程。计算卷积第1 行时,该行的卷积核固定,在#0 时刻这9 个PE 可计算出前3 个卷积结果的中间值。5 个周期后完成该行输入特征图计算,切换到第2 行卷积核与第2 行输入特征图相乘,第3 行执行相同步骤。分割位宽16 的特征图经核大小为3、步长为1 的卷积后有效数据只有14 个,因此,#4 时刻会有一项无效数据。3 行特征图乘积共15 个周期,中间值叠加后即得到完整的一行14 个卷积结果。卷积过程中的3 行输入特征图在PE 内分3 片局部缓存存放,除卷积开始前需要提前加载3 行数据,计算下一行卷积时,只需要将第1 行输入数据替换成第4 行输入数据,即可减少片内数据的重复传输。
从图5 可以看出,每行PE 计算时进行了不同的映射,如在#0 时刻时,第1 个卷积窗口的数据D(0,0)、D(0,1)、D(0,2)分配到PE(0,0)、PE(0,1)、PE(0,2),而第2个卷积窗口的数据D(0,1)、D(0,2)、D(0,3)则分配到PE(1,1)、PE(1,2)、PE(1,0)。两个卷积窗口间是彼此重叠的,PE(0,1)与PE(1,1)、PE(0,2)与PE(1,2)以及PE(1,0)与下一时刻的PE(0,0)使用的是相同的数据。使用该方法排序后,同一列PE使用的是相同的输入特征图,数据传输变得非常规则,可简化PE阵列的互连与控制、同时减少PE内部局部缓存的大小。针对卷积步长为2 的运算,横向上数据流向不做调整,后续模块可通过数据有效信号过滤无效数据,而纵向上修改输入特征图的数据请求逻辑,当每个卷积窗口计算完时共替换两行数据,减少数据计算量。若是进行四周补零后再卷积的运算,数据请求时在输入特征图局部缓存首位加入数据0,即行首补零,而行末补零乘积结果为0,通过禁用该列PE 实现,即拉低该列PE 使能信号。卷积过程中首尾两行补零行不写入输入特征图局部缓存,调整缓存读出控制减少计算量,叠加卷积中间值时也少叠加一次。

图5 PE 阵列组内卷积计算过程Fig.5 Convolution calculation process in PE array group
2.2.3 局部池化运算单元设计
池化是一种降采样操作,常用于提取特征信息和缩小特征图尺寸,常见有平均池化和最大池化。以最大池化为例,局部池化运算单元设计如图6所示,其中,左半部分用于当前行数据比较,右半部分用于完成多行数据比较及复用,支持2×2 和3×3 两种大小池化窗口。2×2 池化时,池化窗口间没有重叠,每两周期进行一次比较。第1 行比较时,数据较大者直接压入FIFO。当下一行数据两两比较后,再读出FIFO 中的值进行比较,即可完成一个池化窗口的运算,然后比较数据直接写入输出缓存模块,并清空FIFO。3×3 池化时,增加下方通路比较第3 个数据与前两个数据的较大者,将结果压入FIFO。计算完池化窗口第3 行后,输出当前池化结果,并将第3 行的比较结果写入FIFO。由于3×3 池化存在数据重叠,因此计算下一行池化窗口可直接从第2 行数据开始请求,并复用FIFO 中的结果,减少计算量和片内数据的重复传输。使用此结构进行局部池化,每通道输入特征图只需要请求一次。此外,若池化时输入特征图尺寸除不尽,结果需要向上取整,即输入特征图的右侧与下侧需要补零,此时通过控制Valid 信号,填充数据0 到运算单元中以完成一次完整的池化。
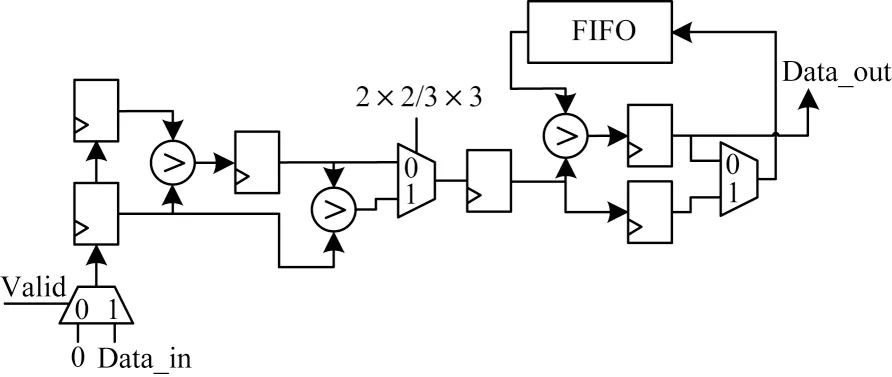
图6 池化模块Fig.6 Pooling module
2.2.4 访存控制与片内缓存设计
加速器使用更大的片内缓存可以减少片外访存需求,提高系统能效。但由于CNN 的特征图、参数量大,限于面积、功耗的成本,因此片内缓存不能设计太大。为适应不同大小的特征图并实现高效的并行运算,设计如图7所示结构对数据进行分块,其中,(i,j,c)表示第c通道第i行第j列数据。读写时特征图以8 通道、宽度16 进行分组,并以行方向、列方向、通道方向的顺序进行连续读写。由于3×3卷积、3×3 池化以及同时进行卷积与池化时存在数据重叠,因此分块时需要根据情况重复读取部分数据。

图7 特征图分块示意图Fig.7 Block diagram of feature map
卷积神经网络运算中需要频繁读取大量的数据,为降低加速器与片外存储器间读写耗时的感知,片内缓存采用乒乓结构。如图8所示,输入和输出缓存均由两块缓存组成,通过重叠读写操作和数据运算时间,增加访存吞吐量。对于输入缓存,当其中一块保存的数据彻底使用完毕且另一块写入一组完整数据块后,交换两块缓存使用权,而输出缓存中还存在卷积得到的部分和数据,需要在计算下一数据块时读出叠加。因此,在最终结果写满一块缓存且另一块缓存数据完全写入片外存储后,才切换输出缓存。

图8 乒乓缓存示意图Fig.8 Schematic diagram of Ping-Pong cache
输入特征图经上述方法分块后,若卷积层中包含所有通道的数据块能够存在一块输入缓存,则缓存中数据可以多次使用。输入缓存所有通道数据遍历一次后无需切换到另一块缓存,也无需从片外存储重新读取,直到输出特征图所有通道计算完成。若包含所有通道的数据块能够在两块输入缓存内存下,则可在两块缓存间切换以完成所有通道输出特征图的计算,也不需要从片外存储反复读取相同数据。
为保证有足够的数据满足运算单元的需求,输入输出缓存包括多个读写端口。如图9所示,每块片内缓存拆分为16 片并列的RAM 缓存区,缓存区数量与运算单元相关。缓存区使用相同地址访问以简化缓存读写逻辑。片外存储读写时将16 片缓存区分为两组,每次并行写入8 片输入缓存区,从8 片输出缓存区并行读出。

图9 片内缓存示意图Fig.9 Schematic diagram of on-chip cache
不同的运算操作加速器内数据流向和缓存存储数据的顺序不同。进行1×1 卷积时PE 阵列可以并行计算16 通道特征图,因此,当输入缓存写完8 通道上述特征图数据块后,下一数据块写入另一组8 片缓存区中,保证16 通道的输出。如果加速器同时完成卷积和池化运算,激活模块输出16 通道的输出特征图后,流向局部池化模块,通过16 个池化运算单元并行完成池化操作,然后并行写入输出缓存。回写片外缓存时输出缓存中数据的读出顺序与写入输入缓存相同。3×3 卷积时,每组缓存区存满完整通道的数据后才切换至另一组缓存区。PE 阵列每次最多并行计算5 通道特征图,8 片缓存区分成两次进行。与1×1 卷积不同,PE 阵列中每三列PE 的数据都由同一片缓存区提供。3×3 卷积时PE 阵列每次最多输出5 通道数据,若数据流向池化模块,最多也只会同时使用5 个池化运算单元。输出缓存的写入也同样是分两次写入8 通道特征图数据,写满完整通道的数据后切换至另一组缓存区。
只进行局部池化时输入特征图不进行量化,输入缓存占用较大,当输入数据过大时可使用两片缓存区进行存储。从输入缓存读取8 通道数据,并行完成池化运算后,直接写入输出缓存。经局部池化后的数据缩小了4 倍,输出缓存的写入顺序与3×3 卷积相同,写满完整通道的数据后切换至另一组缓存区。而全局池化层常位于CNN 的最后一层,此时的特征图尺寸小、通道多,并且每通道输入都被转化为1×1 输出。因此,采用与1×1 卷积相同的读写顺序,同时从输入缓存读出16 通道数据,运算完成后数据同样并行写入16 片输出缓存区。
3 系统仿真与验证
对本文设计的RISC-V 架构卷积神经网络专用指令集处理器进行验证测试。首先在软件层面上完成对定制的CNN 拓展指令的实现和验证。然后调用拓展指令完成SqueezeNet网络分类算法的程序编程。通过仿真工具仿真处理器加速卷积神经网络计算的过程,完成处理器的功能验证。最后在FPGA 平台上实现,对系统资源占用、功耗、性能等进行评估。
3.1 专用拓展指令调用
本文设计的CNN 拓展指令采用汇编指令的形式嵌入到C 语言程序中,取代CNN 算法中的耗时操作以达到加速目的[17]。通过指定格式在C 语言代码中将拓展指令的汇编语句嵌入,指定传入的数据、通用寄存器,最后编译成相应的RISC-V 指令。完成算法程序编写后,使用RISC-V 交叉编译工具链进行编译,生成程序的二进制文件。
3.2 FPGA 平台验证分析
将本文使用的FPGA 验证平台为含Xilinx Kintex-7系列FPGA 芯片的Genesys 2 开发板。将处理器工作频率约束在100 MHz,经Vivado 软件综合以及布局布线后,FPGA 内部资源使用情况如表3所示,处理器建立时间裕度为0.189 ns,片上功耗为1.966 W,其中动态功耗占91%。

表3 FPGA 资源使用情况Table 3 FPGA resource utilization
不同卷积神经网络模型的结构各异,其计算的结果可能相差很大。为更好地对本文设计的处理器进行资源和性能评估,此处选用推理相同网络的文献进行对比,如表4所示。因为本文处理器面向物联网终端和移动端设备,考虑到低成本、低功耗的限制,使用了较小规模的PE 阵列、片上缓存,资源消耗较少。相较于文献[18],虽然推理计算速度上没有那么快,但是本文设计具有更好的性能功耗比,提高约25.81%,同时也优于其他对比处理器。

表4 FPGA 平台加速器性能对比Table 4 Performance comparison of FPGA accelerators
本文处理器与常见通用处理器、GPU 和手机处理器推理计算SqueezeNet 网络模型的性能对比如表5所示,其中,AMD Ryzen7 3700X 与英伟达RTX2070 Super 均在Caffe 框架下计算,骁龙835 则在为手机端优化的推理框架NCNN 下计算。由于轻量化卷积神经网络前向推理过程的计算量和参数量对RTX2070 Super 来说负载较小,并不能充分利用内部所有运算单元,因此实际功耗有所下降。通过对比可知,在相同卷积神经网络模型推理上,在FPGA 上实现的本文处理器比骁龙835 单核计算耗时减少40.64%,且性能功耗比是通用CPU Ryzen7 3700X 的25.39 倍、GPU RTX2070 Super 的1.04 倍、手机处理器骁龙835 单核计算时的3.05 倍、四核计算时的1.16 倍。

表5 不同平台性能对比Table 5 Performance comparison of different platforms
4 结束语
本文基于开源指令集RISC-V 设计卷积神经网络专用指令集处理器。面向物联网应用场景,针对轻量化网络模型的基本运算操作定制RISC-V 拓展指令。同时考虑物联网设备的算力与资源限制,对加速器采用量化网络模型、优化运算单元、灵活调整数据通路、设计相应数据结构和片上缓存等方法设计加速方案。基于FPGA 平台的实验结果表明,在100 MHz 工作频率下推理SqueezeNet 网络,处理器计算性能达到19.08 GOP/s,功耗为1.966 W,比手机处理器单核计算速度更快,并且在性能功耗比上较其他平台更具优势。下一步将针对具体应用对主处理器核心进行深度定制,开发相应的编译器,同时使用高级程序语言提高使用效率,保证软件兼容性。
