基于DMA与特征划分的多源文本主题模型
2021-07-26许伟佳秦永彬黄瑞章陈艳平
许伟佳,秦永彬,黄瑞章,陈艳平
(1.贵州大学计算机科学与技术学院,贵阳550025;2.公共大数据国家重点实验室,贵阳550025)
0 概述
随着计算机网络技术的快速发展,各种各样的Internet/Intranet 应用在全球范围内日益普及,产生了大量的文本信息。研究人员将来自多个应用平台的不同来源的文本集合到一起构成多源文本数据集。在一般情况下,多源文本数据集中的主题信息要比单源文本数据集中的主题信息更加全面准确。因此,研究一种能挖掘多源文本数据集中主题信息的文本挖掘模型是非常必要的[1]。
主题模型是目前较流行的文本挖掘模型,因此需研究一种针对多源文本数据集的主题模型来挖掘多源文本数据集中的文本信息,但传统主题模型挖掘多源文本数据集信息时存在两方面的问题。一方面,在多源文本数据集中,每一篇文档都由大量的词来表示,包括特征词和大量的无关噪声词,并且由于书写风格的不同,因此来自不同数据源的噪声词也不同,不相关的噪声词会干扰模型构建,导致模型性能不佳。另一方面,每个数据源中相同主题的词分布相似但不相同也会影响主题模型的性能,例如新闻网站和社交媒体论述同一主题,部分能够明确指向主题含义的词语会同时出现在这两个数据源中,但由于描述角度的不同会导致一些特定词语只出现在其中一个数据源中。因此,直接采用传统主题模型挖掘多源文本的词特征等信息会因为不同来源的主题的书写风格差异以及描述角度的不同严重影响模型性能,并且在多源文本数据集中对主题数量的估计也非常困难。对于多数传统主题模型而言,主题数量被认为是需用户事先确定的参数,但在进行主题模型挖掘前提供正确的主题数量是不切实际的。此外,对于不同的数据源,主题数量通常是不同的,从而大幅增加了主题数量正确估计的难度。因此,如果多源文本主题模型能够自动地估计每个数据源的主题数量,则对于模型的推广和应用是非常有利的。本文提出一种新的多源文本主题模型MCDMAfp。MCDMAfp 以狄利克雷多项式分配(Dirichlet Multinomial Allocation,DMA)模型为基础。当主题数量无穷大时,DMA 模型近似为狄利克雷过程混合(Dirichlet Process Mixture,DPM)模型[2]。DMA 模型作为DPM 模型的近似模型,能够自动推断出数据集的主题数量,而无需提前设置主题数量。
1 相关工作
网络信息随着互联网的高速发展呈现爆炸式增长,如何快速准确地从这些海量数据中获取有用的信息成为研究人员关注的焦点。主题模型是目前较流行的文本挖掘模型,其中较常见的隐含狄利克雷分配(Latent Dirichlet Allocation,LDA)模型由BLEI等[3]于2003年提出。后续的主题模型多数建立在LDA 模型的基础上,例如针对短文本集的PYPM 模型[4]以及TRTD 模型[5],其中,PYPM 模型可在无需人为提前设置主题数量的情况下进行主题聚类,TRTD 模型利用词的贴近性和重要性,解决了短文本集信息稀疏的问题。但是,目前文本信息的来源多样,而上述模型均在单源数据集上进行,不能直接应用于多源数据集。
近年来,针对多源文本的主题模型被陆续提出,例如DLDA 模型[6]、DDMAfs 模型[7]和DDMR 模型[8],这3 种模型的主要思想是利用辅助数据源的文本信息提升目标数据源的主题发现效果,但其目标仍是解决单个数据源的建模问题。除此之外,一部分多源文本主题模型虽然旨在解决多数据源的建模问题,但仅能应用于特定领域[9],例如:结合ATM[10]与LDA 模型的HTM 模型[11],HTM 模型假设Twitter文本为ATM 模型生成,新闻文本由LDA 模型生成,两者受同一主题-词分布影响,提升了整体聚类效果;COTM 模型[12]是针对新闻及其评论数据源的主题模型,能从这两个数据源中学习相应的主题,并提升整体聚类效果;HHTM 模型[13]主要针对新闻报道和用户评论,提高了摘要生成质量。
由于上述主题模型仅能应用于特定领域,不具备普适性,因此针对多源文本的主题模型的研究也逐渐增多。文献[14]提出的mf-CTM 模型适用于多源文本数据集,基于CTM[15]模型扩展得到,继承了CTM 的优点,能够对主题之间的相关性进行建模,并且能对多领域及多数据源进行主题建模,但mf-CTM 模型假设所有数据源的文本集共享相同的主题分布参数,而现实生活中不同数据源通常有不同的主题分布,这就导致了mf-CTM 模型不能很好地应用于多源数据集主题模型的构建。文献[16]提出的Probabilistic Source LDA 模型能够为每个数据源计算潜在主题,维护源之间的主题-主题对应关系,保留每个数据源独特的特征,但是该模型的构建需要已知数据源的先验知识,这提升了模型构建的难度,并且该模型是标准的LDA[17]扩展模型,不能自动推断每个数据源的主题数量。文献[18]提出的C-LDA 和C-HDP 模型扩展了ccLDA 以适应集合主题级的不对称性,使得两个模型能发现具有不同主题数量的任意集合之间的主题关联性。C-LDA 模型与LDA 模型类似,需要人为提前设定主题数量。C-HDP 模型继承了HDP 模型[19]的优点,无需人为设定主题数量,方便了模型的应用。但是,C-HDP 与C-LDA 模型多数针对同一数据源的多个数据集,若应用于多源数据集,则不能较好地学习每个数据源的源级词特征。
2 MCDMAfp 模型
2.1 相关定义
单词w是文本的最小单元,是{1,2,…,W}词汇表中的一项。词汇表由所有数据源共享,每个数据源都可以使用词汇表中的部分单词。一篇文档由W维向量xd={xd1,xd2,…,xdW}表示,其中xdj是第d个文档中第j个单词出现的次数。数据源χ是由D个文档组成的集合,表示为χ={x1,x2,…,xD}。多源文本数据集M是由S个数据源组成的集合,表示为M={χ1,χ2,…,χS}。
由于词汇表中只有一部分词对数据集中的不同文档有区分作用,因此本文引入一个潜在的二元向量γ={γ1,γ2,…,γW}来识别有区分作用的特征词,其中Ω表示特征词集。对于每个j∈{1,2,…,W},γ表示为:

本文为γ分配一个先验参数,并假设γ是由伯努利分布B(1,ω)生成的,参数ω可以看作是词汇表中每个单词的先验概率。潜在变量γ采用文献[19]中的随机变量搜索思想进行选择。
2.2 模型基本思想
MCDMAfp 模型的基本思想是:1)多源文本数据集中同一主题的词分布共享同一先验;2)多源文本数据集中每个数据源具有主题分布、主题-词分布以及噪音词分布参数。MCDMAfp 模型的图形化表示如图1所示。
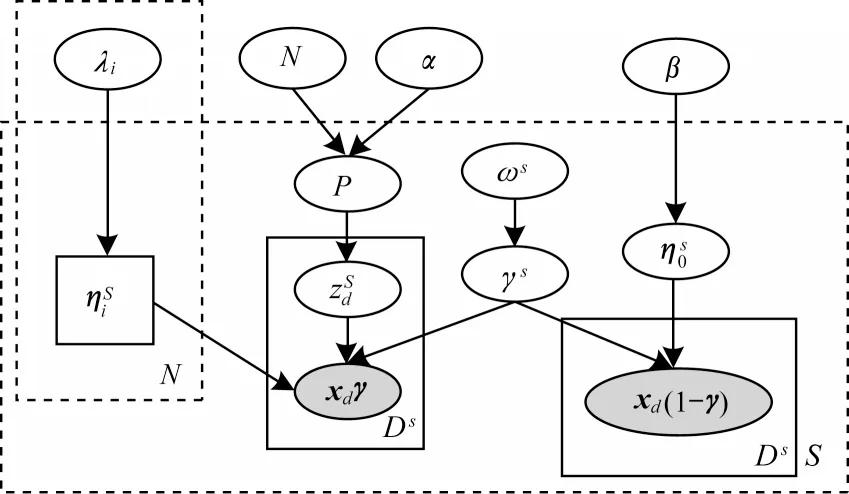
图1 MCDMAfp 模型的图形化表示Fig.1 Graphical representation of MCDMAfp model
本文模型假设多源文本数据集M的生成过程如下:
2)对于每个主题i∈N

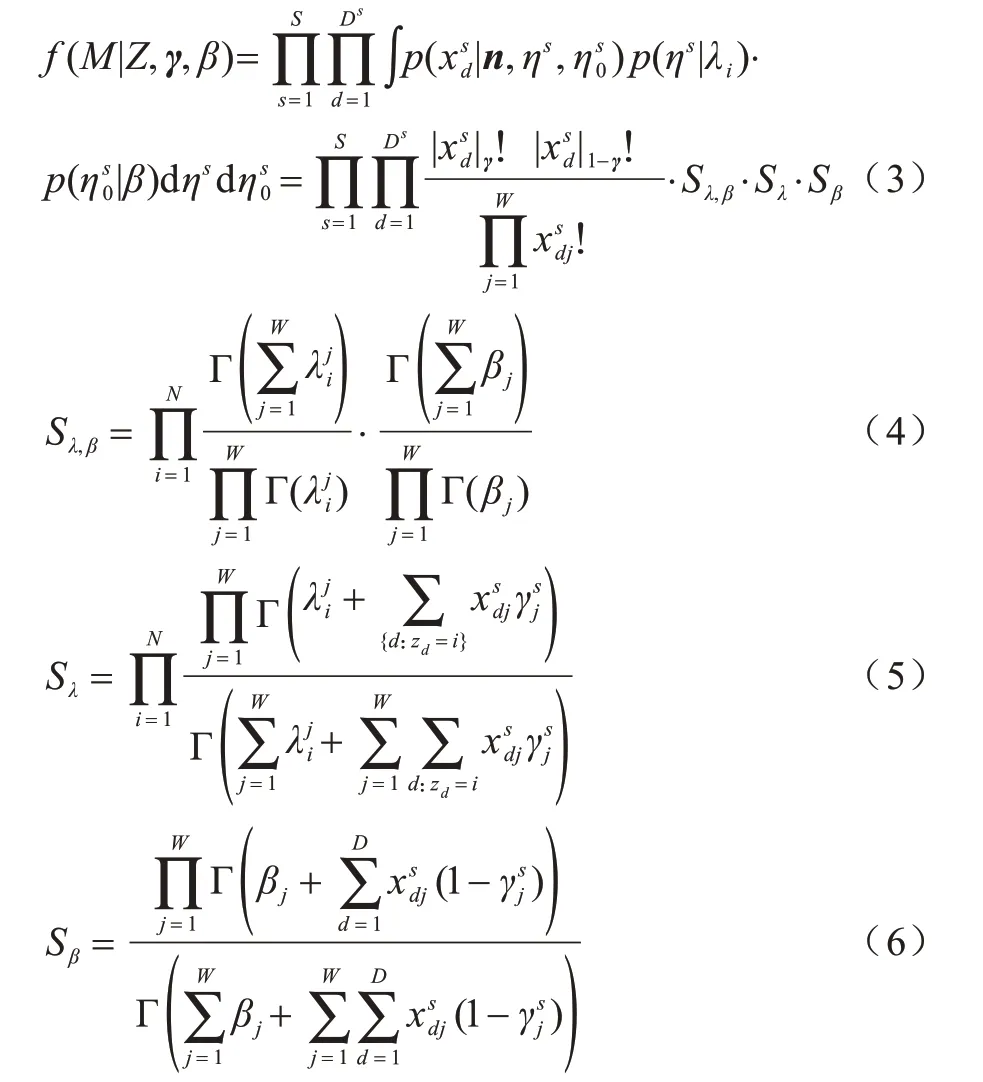
3 Gibbs 采样算法
传统主题模型多数为了方便计算,将主题-词分布的狄利克雷先验参数设置为统一值,但实际上先验参数代表了词的分布情况,例如,表示在主题i中获得单词j的概率比获得单词x的概率大,即单词j在主题i中更具代表性。笔者发现不同数据源具有不同但相似的主题-词分布,因此认为不同数据源的主题-词分布由同一先验产生,通过研究多源文本数据中表现较好的数据源的文本信息得到更具代表性的先验参数λ[21],从而提升模型的整体性能表现。
3.1 先验参数
本文通过优化生成整个数据集的后验概率来获得参数λ,已知多源数据集中数据源χs的概率近似为:

为了方便计算,本文使用对数似然函数进行运算,计算如下:
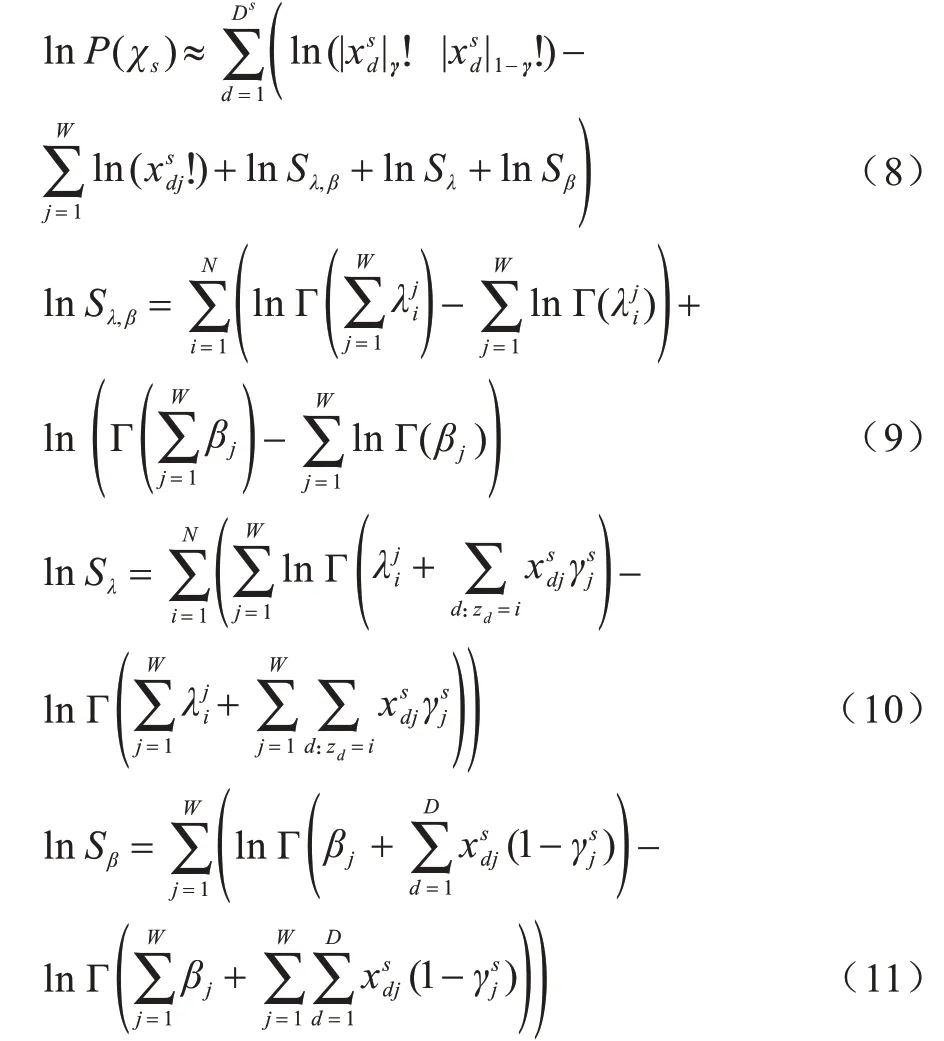
然后得到参数λ的梯度函数:

其中,Ψ(x)是Γ(x)的对数导数函数,由式(12)可得到更新后的:

3.2 基于Blocked-Gibbs 的参数学习
1)通过重复以下步骤R次更新潜在特征词指示符γ:通过随机选取γold中的W个索引中的一个并改变其值,生成新的候选γnew并添加或删除特征词。新候选值被接受的概率q为:

其中,f(γ|χs,zs)∝f(χs|γs,zs)p(γs)。
2)在给定其他潜在变量的条件下,对于i=1,2,…,N,如果i不在中,则从以λi为参数的Dirichlet 分布中得出,否则将T1作为Dirichlet 分布的参数,采样更新:
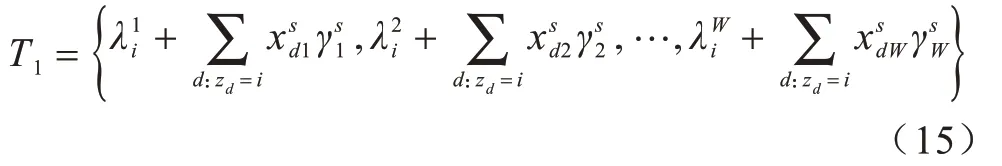
3)将T2作为Dirichlet 分布的参数,采样更新ηs0:

4)将T3作为Dirichlet 分布的参数,采样更新P:
其中,I(zd=i)为示性函数,当zd=i时,I(zd=i)=1,否则I(zd=i)=0。
5)在给定其他潜在变量时,对于d=1,2,…,Ds,通过从参数为{sd,1,sd,2,…,sd,N}的离散分布中采样更新,其中。
在采样过程的不同数据源中,为保证主题的一一对应,即数据源si中的簇类k和数据源sj中的簇类k相同,可在开始时将所有数据源的文本看成单个数据源进行一次采样,再对每个数据源进行单独采样。在采样结果收敛后,根据各个数据源在算法运行过程中的最大生成概率判断表现最优秀的数据集,按照式(15)对参数λ进行更新操作。性能表现差的数据源因为得到了较准确的先验知识,提升了整体效果,作为更新依据的数据源也因为强化了自身的先验知识,整体效果也有所提升。在获得新的参数λ后重复采样过程,便可得到更好的主题发现结果。
4 实验结果与分析
4.1 度量标准
本文使用标准化互信息(Normalized Mutual Information,NMI)来评估聚类质量。NMI 表示主题模型得到的聚类结果与标准结果之间的相似性,其取值区间为(0,1),越接近1,表示主题发现的效果越好,计算公式如下[22]:

其中:D表示文档数;dh表示主题h中的文档数;cl表示集群l中的文档数;dh,l表示主题h和集群l中的文档数。
4.2 数据集
本文使用NASet 和BTSet 两个真实的多源文本数据集来验证MCDMAfp 模型的准确性:
1)NASet 数据集。该数据集包含9 986 篇文本和food 与sport 两个主题,其中,5 000 篇文本来自HuffPost 网站的新闻文章(记为NewSet),剩余文本来自Amazon 网站的评论文本(记为ASet)。
2)BTSet 数据集。该数据集包含10 000 篇文本和4 个主题,其中:5 000 篇文本来自BBC 网站收集的新闻文章(记为bbcSet),共有travel、bussiness、sport、politic等4 个主题;5 000 篇文本来自Twitter 收集的文章(记为TSet),共有bussiness、sport、politic 等3 个主题。
对于这两个数据集,本文进行以下预处理:1)将字母转换为小写字母;2)删除非拉丁字符和停止字符;3)删除长度小于2 或大于15 的单词。
4.3 实验结果
本文在NASet 和BTSet 数据集上进行实验,并评估MCDMAfp 模型的性能。为便于对比研究,将K-means 模型[23]作为基线模型,对比模型包括基于单源数据集的PYPM 模型以及基于多源数据集的C-LDA 和C-HDP 模型。各模型在NASet 和BTSet 数据集上的聚类效果如表1所示。PYPM 模型与K-means 模型表示将每个多源数据集中每个数据源的文本集单独作为该模型的输入。PYPMall模型和K-meansall模型表示将多源数据集中所有数据源的文本集融合成一个数据集,并当作单源数据集作为该模型的输入。K-means 模型(k=30)表示在K-means模型中设定的主题数量为30,K-means 模型(k为真实值)表示在K-means 模型中设定的主题数量为各数据集中真实的主题数量。PYPMall模型在NASet和BTSet 多源数据集上的NMI 值为0.770 和0.237。K-meansall模型(k=30)在NASet 和BTSet 多源数据集上的NMI 值为0.276 和0.207。K-meansall模型(k为真实值)在NASet 和BTSet 多源数据集上的NMI 值为0.209 和0.110。从表1 可以看出,MCDMAfp 模型相比其他模型聚类效果更好。

表1 5种模型在NASet和BTSet多源数据集上的NMI值Table 1 NMI values of five models on NASet and BTSet multi-source datasets
各模型估计的主题数量如表2所示,其中PYPMall模型在NASet 和BTSet 多源数据集上的主题数量为9 986 和10 000。从表2 可以看出:PYPM 模型估计的主题数量比较多,这是因为PYPM 模型无需提前输入主题数量,而是直接将文档数目当作主题数量,所以PYPM 模型估计的主题数目比较大;MCDMAfp 模型相比其他模型发现的主题数量更接近于真实情况,而且每个数据源都拥有被估计的主题数量,这证明了MCDMAfp 模型能保留多源数据集中每个数据源的主题特征。
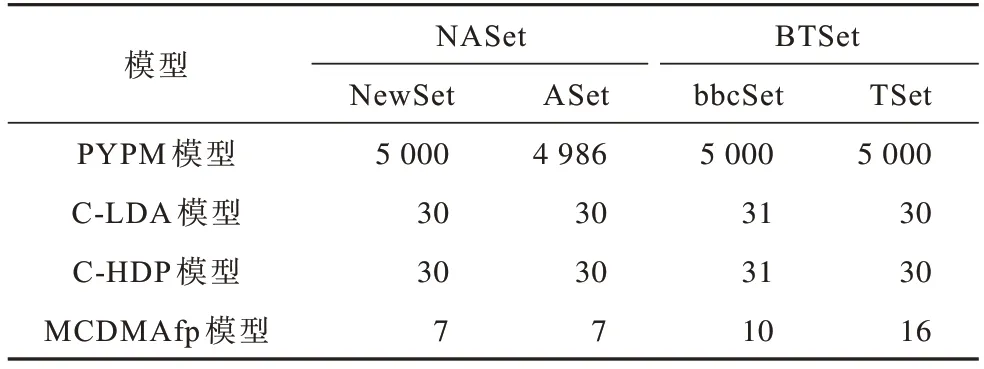
表2 4 种模型在NASet 和BTSet 多源数据集上估计的主题数量Table 2 Number of topics estimated by four models on NASet and BTSet multi-source datasets
本文进一步研究了NASet 多源数据集中每个数据源的部分特征词和噪音词,如表3所示。可以看出,每个数据源的噪音词集不同,并且与特征词集无关。这证明了MCDMAfp 模型能够将每个数据源的特征词集与噪音词集分开,避免了噪音词集对模型的干扰。在表3 中的特征词展示的是每个主题下概率最大的前20 个特征词。针对food 主题,两个数据集都出现了food、chocolate 等词,主要原因为这些词可以明确指示主题的含义,即使数据源不同,这些词也会在不同数据源的词分布中占据重要地位。但因为不同的数据源侧重点不同,taste 和price 等判别词只会较多出现在Aset 数据集中,而几乎不出现在NewSet 数据集中,主要原因为亚马逊的评论通常侧重从食物的价格和味道来评判食物,而新闻主要是从食物本身的风味特征来描述食物,所以不同数据源下相同主题的判别词虽然相似但不同。类似地,对于sport 主题,新闻文章与评论文章都有game、player 等词,但新闻文章通常集中在奥运会等重要的体育赛事上,而评论文章对sport 主题的评论通常与普通赛事有关,这证明了不同数据源具有不同但相似的主题-词分布,而判别词的不同也证明了MCDMAfp 模型能够学习并保留每个数据源独特的源级词特征。

表3 NASet 多源数据集上每个数据源的部分特征词和噪音词Table 3 Some feature words and noise words of each data source in NASet multi-source dataset
4.4 超参数对MCDMAfp 模型性能的影响
4.4.1 超参数ω
本文研究了ω值对MCDMAfp 模型性能的影响,将迭代次数、α、N、λ和β分别设为160、1.0、30、0.9 和4.0,通过改变ω值,观察MCDMAfp 模型的性能变化,其中ω的取值为0.5、0.6、0.8、0.9 和1.0。图2给出了当ω取不同值时,由NMI 评估的MCDMAfp模型的文档聚类性能变化。可以看出,当ω值位于0.5~0.9 时,NMI 值较稳定,当ω取值为1.0 时,多源数据集的NMI 值有明显降低。图3 给出了当ω取不同值时,MCDMAfp 模型发现的噪音词数量的变化曲线。
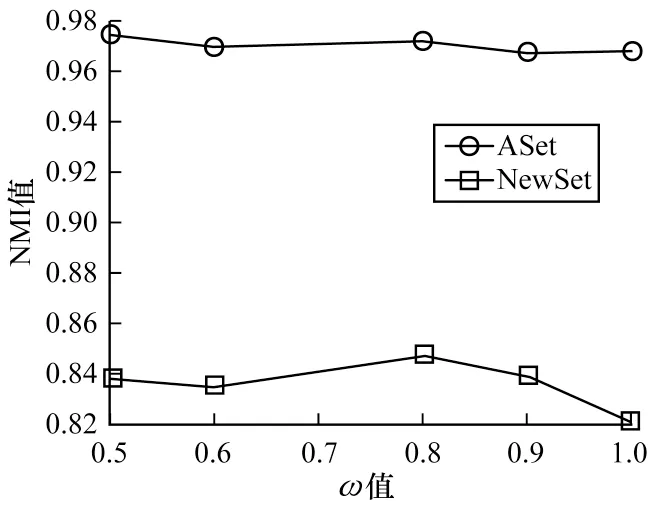
图2 ω 值对MCDMAfp 模型聚类效果的影响Fig.2 The influence of the values of ω on clustering effect of MCDMAfp model
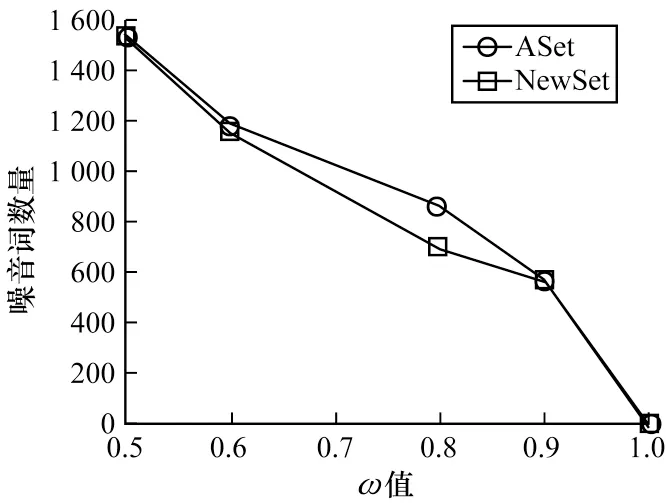
图3 不同ω 值下MCDMAfp 模型发现的噪音词数量Fig.3 The number of noise words found by MCDMAfp model under different values of ω
由图3 可知,当ω值为1.0 时,MCDMAfp 模型发现的噪音词数量为0,这表示没有区分噪音词集与特征词集,因此文档聚类效果较差。随着ω值的增大,MCDMAfp 模型发现的噪音词越来越少,这是因为噪音词的指示符γ服从B(1,ω)的伯努利分布。除此之外,可以看出在ASet 数据集中发现的噪音数总比在NewSet 数据集中发现的多,这是因为新闻文档用词较专业,而评论文档用词较随意。
4.4.2 超参数α
本文研究了α值对MCDMAfp 模型性能的影响,将迭代次数、N、β、λ和ω分别设为160、30、4.0、0.9 和0.9,通过改变α值,观察MCDMAfp 模型的性能变化,其中α的取值为0.2、0.4、0.6、0.8 和1.0。图4给出了当α取不同值时,由NMI 评估的MCDMAfp模型的文档聚类性能变化。可以看出,MCDMAfp模型在不同α值下聚类效果能够保持相对的稳定,这说明α值对MCDMAfp 模型的影响较小。
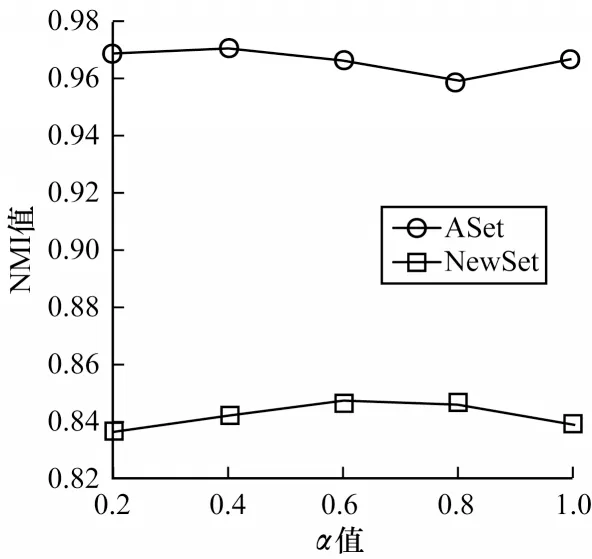
图4 α 值对MCDMAfp 模型聚类效果的影响Fig.4 The influence of the values of α on clustering effect of MCDMAfp model
4.4.3 超参数β
本文研究了β值对MCDMAfp 模型性能的影响,将迭代次数、N、λ、ω和α分别设为160、30、0.9、0.9和1.0,通过改变β值,观察MCDMAfp 模型的性能变化,其中β的取值为2、3、4、5 和6。图5 给出了当β取不同值时,以NMI为评估标准的MCDMAfp 模型的文档聚类性能变化。可以看出,随着β值的改变,MCDMAfp 模型的聚类效果波动幅度不大,这说明β值对MCDMAfp 模型的影响较小。

图5 β 值对MCDMAfp 模型聚类效果的影响Fig.5 The influence of the values of β on clustering effect of MCDMAfp model
4.4.4 超参数λ
本文研究了λ值对MCDMAfp模型性能的影响,将迭代次数、N、β、ω和α分别设为160、30、4.0、0.9 和1.0,通过改变λ值,观察MCDMAfp 模型的性能变化,其中λ的取值分别为0.7、0.8、0.9、1.0 和1.2。图6 给出了当λ取不同值时,由NMI 评估的MCDMAfp 模型的文档聚类性能变化。可以看出,当λ初始值在一定范围内变化时,对MCDMAfp 模型的聚类效果没有较大影响。这是因为MCDMAfp 模型会对λ值进行更新,最大程度地减少λ初始值对模型的干扰,从而证明MCDMAfp 模型具有较强的鲁棒性。

图6 λ 值对MCDMAfp 模型聚类效果的影响Fig.6 The influence of the values of λ on clustering effect of MCDMAfp model
4.4.5 主题数量N
本文为证明MCDMAfp 模型能够较好地估计每个数据源的主题数量,研究N值对MCDMAfp 模型性能的影响,将迭代次数、β、ω、α和λ分别设为160、4.0、0.9、1.0 和0.9,通过改变N值,观察MCDMAfp 模型的性能变化,其中N的取值分别为10、15、20、25 和30。图7 给出了当N取不同值时,由NMI 评估的MCDMAfp 模型的文档聚类性能的变化。可以看出,MCDMAfp 模型在不同N值下保持了一定的稳定性,这证明了提前设定的N值对MCDMAfp 模型的影响较小,但随着N值的增加,MCDMAfp 模型的运行时间有所增加。

图7 N 值对MCDMAfp 模型聚类效果的影响Fig.7 The influence of the values of N on clustering effect of MCDMAfp model
5 结束语
本文提出一种基于DMA与特征划分的多源文本主题模型MCDMAfp。MCDMAfp 模型采用Gibbs采样算法自动估计每个数据源的主题数量,并为每个数据源提供单独的主题分布、噪音词分布以及主题-词分布参数学习每个数据源的主题特点,同时利用特征划分方法识别每个数据源内的特征词和噪声词,防止混合后的结果影响主题发现效果。在两个真实数据集上的实验结果表明,MCDMAfp 模型能够保留多源数据集中每个数据源的独特性,并具有较好的主题发现效果。下一步考虑将文字嵌入与多源文本主题模型相结合,进行基于语义的多源文本主题发现研究。
