基于深度学习的计算机网络数据包路由策略
2021-07-26龚方生
◆龚方生
(广州涉外经济职业技术学院 广东 510540)
1 引言
计算机网络中的路由器经历了几代硬件上的更新升级,但由于构建网络核心和无线-有线异构架构的方式基本保持不变,其路由算法背后的主要思想也基本相似。为了适应网络流量的激增,网络核心基础结构只是通过添加更多、更大的路由器和更多、更快的网络连接的方式来继续扩大规模,越来越大的核心网络导致网络运营商的投资收益正在下降。流量管理的软件方面主要集中在新路由策略的应用上,而新的路由策略的应用可能要等到新一代功能强大的硬件体系结构出现之后才能实现,因此软件驱动的路由策略的应用总是落后于流行的路由策略。为了应用针对由不同网络服务开发的最新软件驱动的路由算法,有必要提高核心路由器的可编程性。然而,由于其专有的硬件架构,设计可编程路由器是一个充满挑战的研究领域。因此,研究人员考虑使用软件定义路由器,该软件在商品硬件体系结构上部署了可编程路由策略以执行数据包的处理和传输。
尽管多核中央处理器(CPU)主导了相关研究领域,但图形处理器(GPU)同时运行成千上万的线程来有效地处理数据包的能力使得GPU 加速的软件定义路由器成为新的研究热点。同时,GPU 也可与多核CPU 协作以同时执行不同的指令,GPU 和CPU 的协作可以显著提高定义路由器的数据包处理吞吐量。在本文中,我们专注于数据包路由策略的设计。传统上,每个路由器都会定期将信号数据包转发给其他路由器,以告知其到邻居的链路的延迟值或其他度量参数。然后,每个路由器都可以利用该信息来计算下一个节点,以将数据包发送到目标路由器。由于每个路由器都可以根据所获得的所有网络链路信息做出最佳决策,因此该方法在大多数情况下效果很好。但是,当网络中的某些路由器由于流量需求旺盛而拥塞时,用于计算下一个节点的常规方法会出现收敛缓慢的问题。同时,周期性的信号数据包交换加剧了业务拥塞。此外,传统的路由方法无法应对网络环境继续变得更加复杂的情况。为了利用各种指标之间的复杂关系来确定最佳路径,基于机器学习的智能网络流量控制系统已在网络环境中引起了广泛关注。但是,由于传统的机器学习技术在处理多个网络参数方面效率低下以及表征输入和输出的困难,这些智能策略仍基于传统的基本规则的路由。深度学习方法已应用于许多复杂的活动中,来自动探索各种输入之间的关系,因此在本文的其余部分中,我们设计了一种基于深度学习的数据包路由策略。
2 基于深度学习的数据包路由策略设计
本节介绍如何设计深度学习模型并在GPU 加速的SDR 上实现路由表的构建。首先,我们介绍了深度学习模型输入和输出的详细表征,然后描述所选择的深度置信网络架构,最后介绍所提出的数据包路由策略如何在GPU 加速的SDR 上工作。
2.1 输入/输出设计
由于在每个路由器上检测到的流量模式是该路由器流量状况的直接指示,因此我们将流量模式用作深度学习模型的输入。深度学习模型用于计算数据包的路由路径,因此我们选择路由路径作为模型的输出,如图1所示。
图1 系统输入与输出表征
至此,本设计的挑战在于如何量化表征深度学习模型的输入和输出。我们以每个路由器的流量模式来表征输入,将其定义为每个时间间隔内路由器入站数据包的数量。假设对入站数据包进行计数的时间间隔为Δt 秒,则对于每个路由器,可以采用最后一个αΔt(α为正整数)秒内每个时间间隔内入站数据包的数量作为其流量模式。因此,假设整个网络由N 个路由器组成,则网络中所有路由器的流量模式可以使用α行和N 列的矩阵来表示,并将矩阵中的αN 个元素的值输入到深度学习网络的输入层。由于太长时间以前的流量模式对当前网络分析没有影响,因此α的值不应太大。另外,过大的α值将提高深度学习模型的复杂度,降低其运行效率。结合深度学习模型仿真结果,可设置α=1。因此,深度学习模型的输入可以看作是N 维向量,其中第i 个元素是最后Δt 秒内第i 个路由器的流量模式。
出于数据包路由的目的,深度学习模型需要输出路由路径。输出的形式可以有两种,一种是将输出层设计为像集中式路由一样提供整个路径,另一种是像分布式路由策略一样仅给出下一个节点。我们选择后者,因为其具有较低的复杂性和较好的鲁棒性。对于由N 个路由器组成的网络,我们使用由N 个二进制元素(0 或1)组成的向量表示模型的输出。在输出向量中,只有一个元素的值为1,其他为0。如果N 维向量中的第i 个元素为1,则将网络中的第i 个路由器选择为下一个节点。综上,我们可以使用两个N 维向量x 和y 来表示深度学习结构的输入和输出,并且x 和y 的示例如下所示:
x=(tp1,tp2,…,tpN)
y=(0,1,…,0)
2.2 深度学习结构设计
为了完成计算具有流量模式的下一个路由器的任务,选择深度学习模型中最为常见和有效的深度置信网络(DBA)来设计深度学习结构,所设计的深度学习网络结构图如图2a所示。假设深度置信网络由L 层构成,包括输入层x、输出层y 和(L-2)层隐藏层。其中(L-2)层隐藏层可看作是受限玻尔兹曼机(RBM)的堆栈,顶层是一个逻辑回归层。每个RBM 的结构如图2b所示,可以看出,每个RBM 由两层组成,即可见层v 和隐藏层h。两层中的单元通过加权相互连接,同一层中的单元不连接,在两层中给每个单元分配一个加权偏差。其中,wij表示连接隐藏层中第j 个单元和可见层中第i 个单元之间的连接权重,ai和bj分别表示可见层中第i 个单元和隐藏层中第j 个单元的偏移量。隐藏层中学习到的单元激活值用作深度置信网络中上层RBM 可见层的输入。
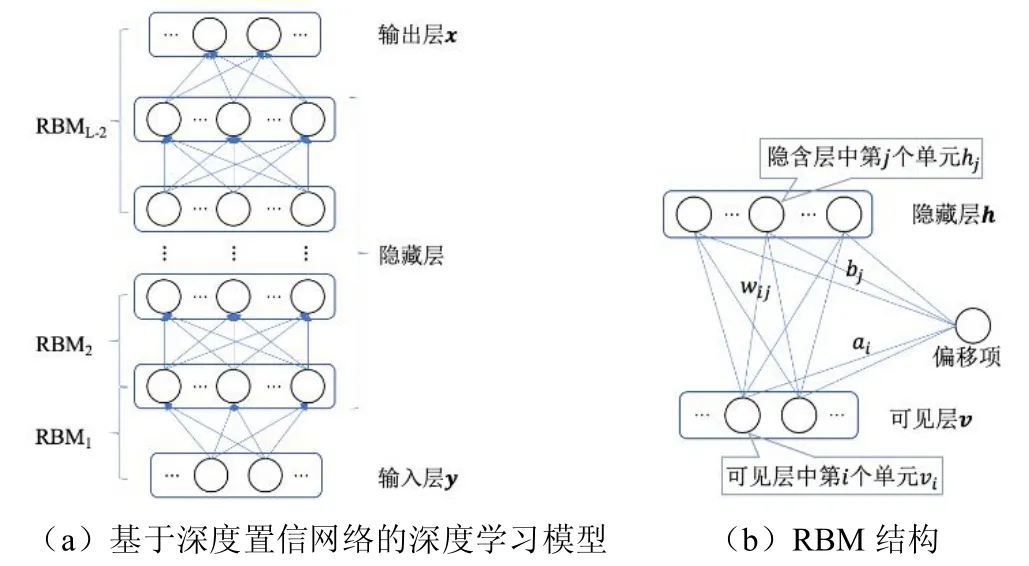
图2 所提出的深度学习模型
深度学习训练过程包括两个步骤:采用逐层贪婪训练法对模型进行初始化结构,采用反向传播算法对结构进行调优。深度置信网络的初始过程是对每个RBM 进行训练,这是一个无监督的学习过程,因为RBM 是一种无向的图形模型,其中可见层中的单元使用对称加权连接到随机隐藏单元。在训练RBM 时,会将未标记的数据集提供给可见层,并反复调整权重和偏差的值,直到隐藏层可以重建可见层为止。因此,训练后的隐藏层可以看作是可见层的抽象特征,训练RBM是使隐藏层的重建误差最小化的过程。
2.3 基于深度学习模型的路由器架构设计
本节简要介绍GPU 体系结构以及上述基于深度学习模型的数据包路由过程。GPU 由全局内存、二级缓存和几个流多处理器(SM)组成,每个流多处理器由多个流处理器(SP)组成。由于GPU 具有许多计算核心,因此它在接收工作负载时会同时启动多个线程,每个线程在相同的程序上运行不同的数据集。因此,GPU 非常适合运行深度学习的单指令多数据编程模型。
运行于普通PC 上的GPU 加速SDR 的报告线速可高达40 Gbps,可满足常用需求,因此本文选择基于PC 的通用SDR 来构建路由表并执行基于深度学习的路由算法。在转发过程中,数据包会经过SDR架构中的四个相关部分,即GPU、CPU、网络接口卡(NIC)和主存储器。为了运行基于深度学习的路由算法,需要在训练阶段初始化每个SDR,在此期间,网络中的SDR 不需要处理任何数据包,只需利用其GPU 训练其DBA 并记录其参数即可。在训练阶段之后,网络中的所有路由器都需要将其DBA 的参数值发送给所有边缘路由器。因此,每个边缘路由器都可以使用这些参数来还原任何DBA,可以在运行阶段中成功构建到任何目标路由器的完整路径,而内部路由器只是根据路径转发数据包。数据包在SDR 中传输的过程可以描述如下:(1)进入NIC 的数据包通过直接内存访问(DMA)复制到主机内存中;(2)在整个过程中,CPU 从主内存复制一些数据包以填充其缓冲区;(3)运行在CPU 上的软件会分析这些数据包并采取一些必要的处理,例如错误检查,缩短生命周期等,而且,CPU 对不同类型的数据包采取不同的处理;(4)CPU 提取数据包的标头并将其发送到GPU 的全局内存,将整个数据包发送到GPU 的内存;(5)在从CPU 获取报头和数据包后,在边缘路由器的GPU 上运行的软件使用数据包携带的流量模式作为已恢复DBA 的输入,DBA 可以输出下一个节点,边缘路由器的GPU 可以利用这些节点构建数据包的整个路径,并将相应的路径附加到接收的标头;(6)CPU 从GPU 复制回已处理的数据包的标头,并且将数据包复制回主存储器;(7)CPU指示NIC 将批处理转发到何处,NIC 通过另一个DMA 从主存储器中获取数据包。
3 基于深度学习的路由策略的过程
本节重点讨论利用DBA 计算核心网络中用于构建下一个节点路由路径的过程,该过程可以分为三个步骤,即初始化阶段、训练阶段和运行阶段。下面详细介绍三个阶段的具体过程。
3.1 初始化阶段
如第2.2 节所述,我们采用监督学习的方式来进行训练所提出的DBA 系统,因此,初始化阶段的目标是获得足够的、由输入向量和相应的输出向量组成的标记数据。如2.1 节所述,输入向量为网络中路由器的流量模式,输出向量应指示对应于给定流量模式的下一个节点。为了获得这种训练数据,我们可以使用可用的数据集资源,例如应用互联网数据分析中心(CAIDA),并提取交通信息和相关的路由路径。另外,我们也可以在网络中运行传统的路由协议,并记录每个路由器的入站数据包数量及其路由表。
3.2 训练阶段
在训练阶段,我们使用获得的数据来训练我们设计的DBA。训练过程包括两个步骤:使用逐层贪婪训练方法初始化每个DBA;使用反向传播方法微调参数θ(w,b)。训练阶段完成之后,我们可以获得θ(w,b)的值。DBA 的输出是代表下一个节点的向量,这意味着它需要多个DBA 来构建整个路径。假设采用类似集中控制策略,即网络中只有一个路由器训练和运行所有DBA,并在网络中生成所有路径,路由器的计算量将非常高。而且中央路由器需要大量的时间和资源来计算所有路径,从而导致延迟增加,准确性下降。为了减少路由器的计算量并提高学习的准确性,将训练任务分为几个部分,并将它们分发到目标核心网络中的每个路由器,即网络中的每个路由器都需要训练几个DBA,每个DBA 都会计算从其自身到目的路由器的下一个节点,路由器需要训练的DBA 数量取决于其目标路由器的数量。令N 和I 分别表示路由器的总数和内部路由器的数量,则每个内部路由器的目标节点数为(N-I),而每个边缘路由器都有(N-I-1)个目标节点,因为源路由器和目标路由器不能相同。因此,每个内部路由器都需要训练(N-I)个DBA,而所有边缘路由器都需要训练(N-I-1)个DBA。
3.3 运行阶段
在运行阶段,网络中的所有路由器都需要定期将其入站数据包的数量记录为流量模式,并将其发送到边缘路由器。然后,每个边缘路由器都可以将流量模式输入到其DBA,以获取到其他边缘路由器的下一个节点。另外,由于每个边缘路由器都获得其他路由器的DBA的参数θ,因此它可以在网络中构造任何DBA,并计算从任何路由器到任何目标边缘路由器的下一个节点。因此,每个边缘路由器都可以利用下一个节点信息来构建从其自身到所有其他边缘路由器的完整路径。使用N 个元素组成的数组P[N]保存网络中N 个路由器的入站数据包数量,以表示流量模式,而θ[N-I][N-1]用以保存网络中所有DBA 的参数。另一个数组R[N-I]用于保存网络中边缘路由器的序列号。在实际网络情况下,R[N-I]用于保存所有目标路由器的IP 地址。系统运行后,每个边缘路由器都可以获取DBA 的输出,以构造到(N-I-1)个边缘路由器的路径。我们可以使用矩阵NR[N][N-I-1]来保存这些DBA 的结果,这些结果可用于构建通往所有其他边缘路由器的完整路径。
4 结论
为满足不断变化的网络需求并应对未来流量激增对路由的挑战,本文重新考虑核心网络中数据包路由策略。本文首先探索当前的SDR 架构,并论证了深度学习可以用来代替传统的路由协议来计算路由路径。考虑到当前GPU 加速的SDR 支持大规模并行计算,不同于传统的基于规则的路由方式,本文提出了一种受监督的深度学习系统,以利用流量模式直接计算路由路径。模拟结果表明,从传统的基于规则的策略到深度学习的转变可以显著提高网络中数据包的路由效率。
