基于边缘智能的心电信号处理方法及监测系统*
2021-07-24甄鹏华韩玉冰
甄鹏华,韩玉冰
(齐鲁工业大学(山东省科学院)计算机科学与技术学院,山东 济南250353)
0 引言
边缘智能是十分新颖的研究领域,它集合了边缘计算和人工智能的优势,能够以较低的资源消耗和较快的运行速度提供较为精确的分析结果[1-2]。边缘设备及边缘计算也是分析心电信号常用的方法。
然而传统的心电信号分类研究是针对大量样本进行的单纯分类研究,并不适用于实时小样本分析的边缘智能场景。这是由于传统研究通常是基于大量有完善的位置标记的样本,在处理过程中依赖样本数量进行特定的处理。在边缘智能场景中,预测过程中心电信号是实时产生的,且要求产生一条数据即分析一条数据,以满足实时性的要求,上述基于样本数量的处理方法无法实现。
为此,本文提出了一种可行的心电信号处理方法,主要是信号的预处理(Preprocessing)方法,并为其搭配适当的人工智能模型。实验验证结果表明,该心电信号处理方法具有一定的实用性,能够在一定程度上满足边缘智能场景的要求。
1 心电信号基本概念
心电图是利用心电图仪从体表记录心脏每一心动周期所产生的电活动变化图形,心拍的波表示了心脏各部位的兴奋传导变化情况,是非常重要的特征,可以向医护工作者传递重要的生理信息[3]。
根据美国医疗仪器促进协会(The Association for the Advancement of Medical Instrumentation,AAMI)的ANSI/AAMI EC57:2012标准[4],心拍可以分为五大类,如表1所示。

表1 AAMI心拍分类标准
心脏搏动频率或节奏的异常可能会导致多种常见的心血管疾病,例如心率失常。上述心拍分类中,除N类别外,其余类别均不能排除心率失常疾病的可能性。心率失常若没有得到及时有效的治疗,有可能会导致人死亡。
由美国麻省理工学院(Massachusetts Institute of Technology,MIT)提供的MIT-BIH心电数据库[5]是用于研究心率失常的数据库,也是国际上公认的可作为标准的三个心电数据库之一。
2 心电信号的预处理
信号的预处理包含数据集的划分、数据样本的分段、数据样本的平衡处理和信号的降噪处理。
2.1 数据集的划分
神经网络模型使用的数据需要划分为训练集和测试集。在心电信号分类的相关研究中,通常有以下两种数据集的划分方式:
(1)患者内(Intra-Patient)。即训练集和测试集中的数据绝大多数甚至完全来自同一个或一组患者。
(2)患者间(Inter-Patient)。即严格遵守训练集和测试集中的数据来自不同的患者的规定。
为了能够真实地模拟边缘智能环境下的心电信号分类,应当采用“患者间”的数据集划分方式,将MIT-BIH数据集划分为训练集和测试集。采用AAMI推荐的“患者间”的分组方式将数据集分为DS1、DS2两组,DS1作为训练集用于训练模型,DS2作为测试集用于测试模型。在边缘智能环境下的心电信号分类研究中,DS1所代表的训练集可以理解为边缘智能系统部署时使用的最早期训练数据,DS2所代表的测试集可以理解为在边缘智能系统运行中,物联网终端(即心电图仪)持续产生的数据。
2.2 数据样本的分段
对于一整条心电信号数据来说,需要将其划分为若干个不同标记的数据样本片段,心电信号分类研究主要依靠以下两种数据样本分段方式[6-8]:
(1)直接标记利用方式。即直接利用数据库中由医学专家人工标记的QRS波群位置标记,将一个QRS波群及前后一定采样点(通常是能够包含一个或两个完整的心拍的采样点)的数据作为一个样本。
(2)心拍定位检测方式。即利用QRS波群检测算法来定位各个心拍在整条数据上的位置,再将一个QRS波群及前后一定采样点(要求同上)的数据作为一个样本。
这是两种最常用的心电信号数据样本的分段方式,然而,这两种方式并不能很好地应用在边缘智能场景中,原因分别如下:
(1)对于直接标记利用方式,其在单纯的分类研究上是可行的,但在边缘智能场景中,数据不是已经生成好的,而是持续不断生成的,要将数据实时处理为规范的样本,相当于时刻需要人工干预来添加QRS波群位置标记,这显然是不可能的。
(2)对于心拍定位检测方式,其在边缘智能场景中,需要一个时刻运行的QRS波群检测算法,这将消耗更多的计算资源和花费额外的时间,这与边缘智能的初衷相违背。其次,该方式依赖于QRS波群检测算法的精确度,由于个体身体情况存在差异,特别是患者的心率更加不规律,QRS波群定位总会存在偏差,这会影响后续的神经网络训练和预测。
为此,需要一种更加适用于边缘智能场景的数据样本分段方式。文献[9]提出了一种对信号直接切片的方式,其将心电信号直接切分为每段5 s的片段,直接利用与QRS波群无关的分段片段进行神经网络的训练和预测。这种分段方式十分适用于心电信号实时监测的边缘智能场景。对于神经网络模型来说,采用这种切片方法,还具有以下优点:
(1)分段方式简单,速度极快,非常适合于边缘智能环境中将数据快速预处理后进行预测的需求。
(2)数据不需要定位QRS波群及心拍位置,减少神经网络模型对心电数据形式的依赖。
(3)由于信号片段中QRS波群及心拍出现的位置和数量不固定,能够减少训练出的神经网络模型对此的敏感性,提高模型的泛化性。
通过这种方式获得的一个数据样本中可能存在多个心拍,为此采用了以下规则来标记片段的标签:
(1)当片段中全部心拍类型为正常心拍,不存在任何类型的异常心拍时,该片段标记为正常类型;
(2)当片段中存在异常心拍时,将片段中出现数量最多的异常类型标记为该片段的类型;
(3)当片段中存在多类且数目相同的异常心拍时,以最先出现的异常类型作为该片段的异常类型。
容易分析,边缘智能场景下的心电信号分类结果的接收者(即医护人员)最关心的是患者实时的心率情况,即患者此刻是否心率正常,若不正常,是哪种类型异常心率的可能性最高。基于这种考虑,这种注释标记方式在一定程度上能够满足需要。
考虑到神经网络模型的训练过程,这种规则仍有缺陷,其可能使得部分异常心拍被隐藏,这取决于片段的长度,若片段长度过长,则被隐藏的心拍类型越多,标签越不准确;但如果片段的长度太短,则包含信息太少,可能存在标记的类型出现严重错误的情况。无论片段过长还是过短,都会使片段的特征和标签对应关系减弱,因此文献[9]采用的片段长度为5 s这一设定可能并不恰当。
为此,需要通过实验来确定最佳的片段长度。以450采样点(1.25 s)为一个间隔划分为8组不同的数据样本。一般地,1.25 s能够包含至少一个完整的心拍。采用这种分段间隔进行多组对比实验,可以有效地测试不同分段长度下的分类效果。
2.3 数据样本的平衡
在MIT-BIH心电数据库中,各类心拍的数量本就相差甚远,在将心电信号数据分段为数个数据样本并重新对数据样本生成标签后,由于部分心拍的注释标记存在被隐藏的可能,特别是数据样本分段的长度也会影响每段的标签,数据集中的数据样本类别不平衡问题将更加严重。按不同长度进行分段后DS1数据集的类别标签的分布情况如表2所示。
数据样本的不平衡会导致神经网络模型的训练难以拟合,因此有必要对分段后的数据样本进行类别的平衡处理。由表2可见,分段长度不同,标签类别的分布差异也很大。不同的分段长度中,数据集都存在一定的不平衡问题。数据集尤其是训练集的极度不平衡可能会导致神经网络的学习无效甚至网络不收敛。为了解决这个问题,需要扩充样本数量较少的类型的样本。常用的扩充方法有以下两种:
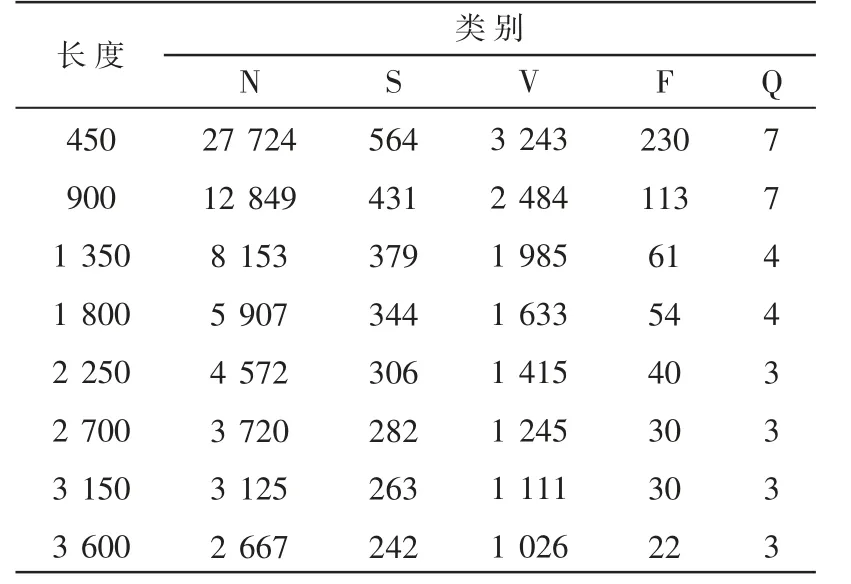
表2 各类别的标签分布情况
(1)欠采样。欠采样是指丢弃样本数量较多的类别中的大量数据,以达到数据集的平衡。
(2)过采样。过采样是指重复样本数量较小的类别中的数据,以达到数据集的平衡。
这两种方法都存在缺点。欠采样会丢弃大量宝贵的数据,而在DS1数据集中数据样本类别的不平衡状况已比较严重,若再丢弃大量数据,会导致神经网络模型不收敛;过采样会使得样本数量少的类别的数据大量重复,会放大其中的噪声对神经网络模型的影响,导致过拟合问题。因此需要一种新的数据扩充方式。
基于心电信号数据的数据样本分段方式,采用一种片段重叠的方式来扩充数据。即对样本数量少的类别的相邻片段间互相重叠采样,以此采集更多的样本。与欠采样相比,这样处理能够保留大量数据,保证神经网络模型的训练质量;与过采样相比,这样处理得到的新样本同原样本之间存在差异,可以防止噪声对神经网络模型的影响。以样本数量最多的类别的数量为基准,对其余片段进行重叠,则其余片段的重叠区间长度如式(1)所示:

式中,l表示重叠的长度,⎿」表示向下取整运算,L表示数据样本片段的长度,n表示该类别的样本数目,N表示样本数量最多的类别的样本数目。
通过上述处理,相当于该类别下每个片段进行了步长一定的重叠重复。数据样本重复步长的计算如式(2)所示:

式中,sp表示数据样本重复步长,「⏋表示向上取整运算,n表示该类别的样本数目,L表示数据样本片段的长度,N表示样本数量最多的类别的样本数目。
由于数据样本片段长度和数量的限制,片段的重复次数是一定的。这个重复次数的计算如式(3)所示:

式中,olp表示重复次数,L表示数据样本片段的长度,sp表示数据样本重复步长。
在进行了上述数据样本的平衡处理后,DS1数据集的类别标签的分布情况如表3所示。
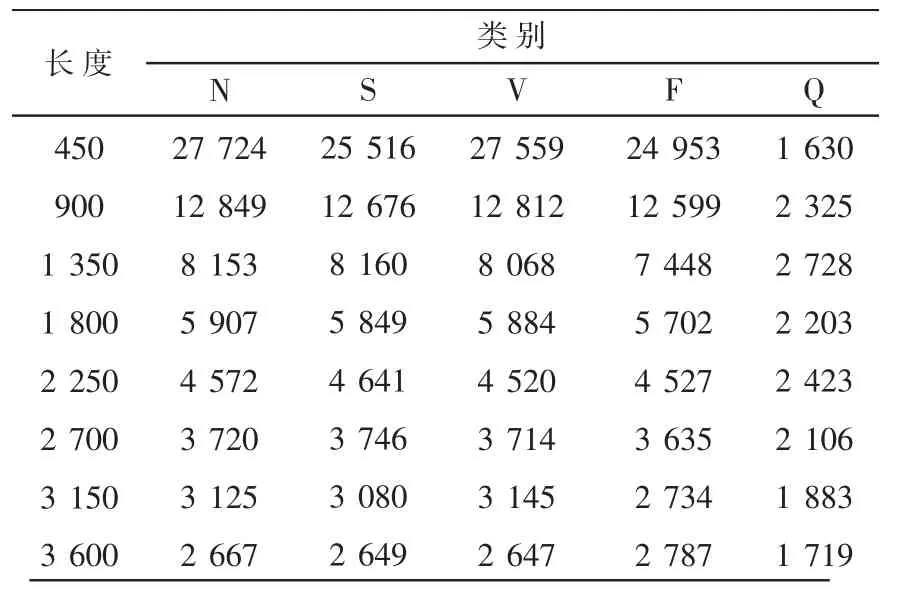
表3 数据平衡后各类别的标签分布情况
由表3可知,DS1数据集的数据样本类别的平衡问题得到了较好的处理。无论片段长度长还是短,N类、S类、V类和F类的数据样本量基本一致,Q类的数据样本量距其他样本仍有差距,但在MITBIH心电数据库中,Q类的心拍极少,为防止神经网络模型在拟合上出现问题,不再对Q类的数据样本进行进一步的扩充处理。
DS2数据集作为测试集,其数据样本类别的不平衡不会影响神经网络模型的训练,不做数据样本类别平衡处理。
2.4 信号的降噪处理
对于神经网络的输入,通常具有一些不能反映相关特征,甚至会干扰相关特征呈现的内容,即噪音(Noise)。由于这些噪音的存在,信号会具有大量无规则的波动,影响神经网络模型的性能。一般地,这些噪音的波段频率较为固定,可以通过一定的方法将其滤除,并保留能够体现相关特征的波段频率信号,使处理过的信号更能清晰地体现原有信号所包含的意义,这一降噪过程是通过滤波技术实现的。经过滤波降噪的信号作为神经网络的输入,可以大幅提升神经网络模型的性能。
人体的心电信号通常十分微弱,通过心电图仪采集的心电信号容易受到各种因素的干扰而产生噪音。为此通常需要对心电信号进行滤波降噪处理[10]。小波变换是一种常用的滤波方法,如式(4)所示:
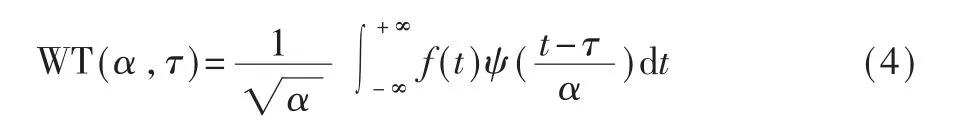
式中,α表示尺度因子(Scale),τ表示平移量(Translation),ψ表示基本小波,t表示时间。
采用小波变换滤波的方式对心电信号进行处理,应用Daubechies小波族中的db5小波作为小波基函数,将原始信号进行九级小波分解,由高频信号至低频信号分别为D1~D9,最后剩余的信号为A9,将高频信号D1和D2视为噪音,将其置为零,再将D1~D9信号和A9信号重组作为新的心电信号。降噪前后的心电信号波形分别如图1(a)和图1(b)所示。
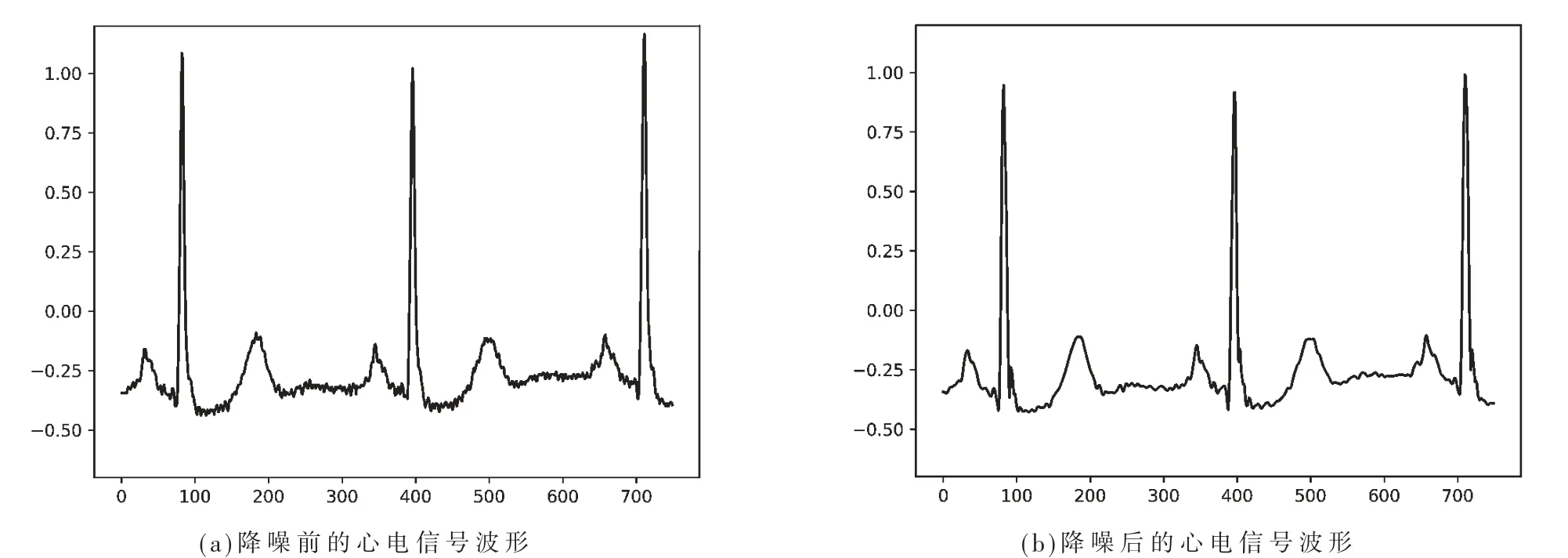
图1 心电信号降噪前后波形对比
由图1可以观察出,降噪前的心电信号波形存在大量不规则的颤动,即噪音。降噪后的心电信号波形在完整保留心电信号正常振幅走势的同时变得更加光滑。事实上,如果是面向单纯的心电信号分类研究,仍可以继续对信号进行进一步处理,例如主成分分析法(Principal Component Analysis,PCA),以满足神经网络模型对性能的更高要求。然而考虑到很多方法一般都依赖于样本数量,因此这些方法并不适用于边缘智能环境。在一个实际的心电信号监测的边缘智能场景中,要求产生一个信号片段就要分析一个信号片段,数据样本的预处理是单个独立的,完全无法依赖样本数量,同时,复杂的处理会产生更高的延迟,与边缘智能的初衷相悖。为此,仅使用小波变换滤波处理信号,对DS1数据集和DS2数据集处以相同的处理。
3 实验
在对心电信号进行了相应的预处理之后,进行实验验证其有效性,并根据实验确定最佳的数据样本的分段长度。
3.1 神经网络模型
本实验的初步验证采用一维卷积神经网络模型,具体参数如表4所示。

表4 一维卷积神经网络模型参数
这是一个简单的、经典的一维卷积神经网络模型,其目的是验证心电信号的预处理的有效性,并确定最佳的数据样本分段长度。
3.2 实验结果
评判神经网络性能的指标主要有准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数(F-score)。
对于作为测试集的DS2数据集,其数据样本是非常不平衡的。在数据样本不平衡的多分类研究中,对于占比大的类别预测正确的多少能够直接影响准确率的高低,即占比大的类别成为了影响准确率的最主要因素,因此不宜采用准确率作为判断标准。
精确率、召回率和F1分数的计算分别如式(5)~式(7)所示:

式中,TP表示正样本被预测为正类的数量,FP表示负样本被预测为正类的数量,FN表示正样本被预测为负类的数量。
各评价指标对样本数量取加权平均数的结果随信号片段长度的变化如图2所示。

图2 评价指标随信号片段长度的变化
由实验结果可知,数据样本片段长度在1 350采样点时稳定性最强,召回率最高,精确率亦在较高水平。分析可得,当数据样本片段长度较短时,样本之间差异较明显,预测出的阳性样本中真阳性样本占比高,精确率高;但过低的数据样本片段长度,相同标签类别样本之间的差异也较明显,正样本被识别的概率低,召回率并不能达到最高;当数据样本片段长度适中时,不同样本之间仍能具有明显差异,且相同标签类别样本之间的差异缩小,训练出的神经网络模型对正样本更易识别,召回率较高;当数据样本片段长度过长时,样本体现的特征不明显,且标签模糊,神经网络模型性能较差。
一般地,若发生正样本被预测为负类的情况,其成本代价很高,后果较为严重,为避免产生这种情况,应该着重考虑提高召回率指标。就心电信号实时监测场景而言,非N类心拍被识别为N类心拍所带来的后果非常严重,因此选择追求更高的召回率更为合理。通过本实验可以得出,在数据样本片段长度在1 350采样点时,召回率最高,同时F1分数亦最高,因此认为该长度为最佳长度。
为了更进一步地验证该处理方法的有效性,选用文献[11]提出的卷积神经网络模型,并使用通过该预处理方法处理后的数据对模型进行训练和预测,数据样本片段长度设定为1 350采样点,为了使模型能够正常运行,模型的输入层根据该预处理方法的要求进行了调整。
在与同样应用MIT-BIH心电数据库,并同样采用AAMI的患者间分组方式进行数据集划分的研究对比,得出各项性能指标如表5所示。
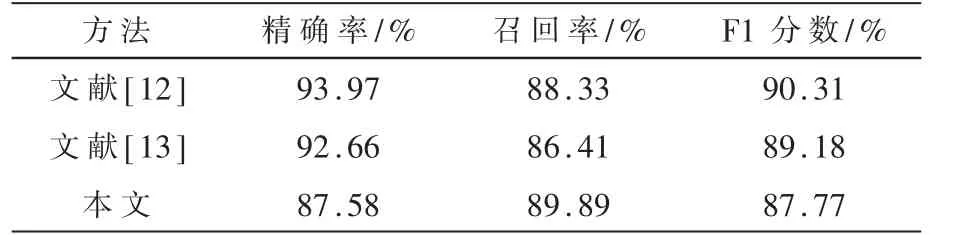
表5 患者间分组实验横向对比
实验结果显示,应用这种心电信号处理方式来训练的神经网络模型的性能能够达到同类相关研究的水平。亦有大量心电信号分类研究采用患者内分组方式,在采用患者内分组方法进行数据集的划分后,得出的各项性能指标如表6所示。
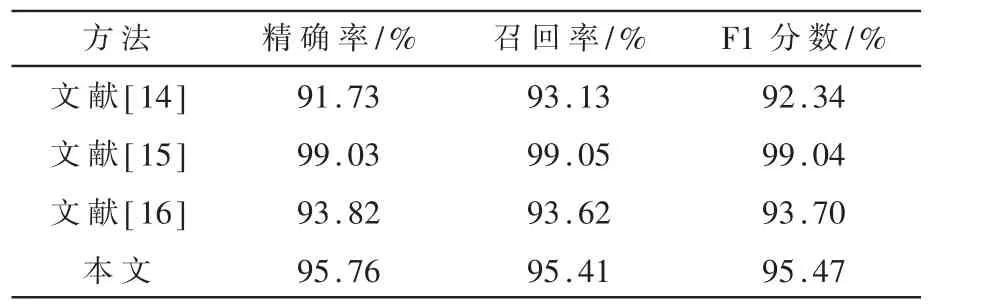
表6 患者内分组实验横向对比
可见,与其他研究所得的结果相比,通过本文提出的预处理方法得出的结果,各性能指标处于同等数量级,部分情况下性能指标更加优异,说明该预处理方法的可用性和有效性较好。
4 心率监测系统仿真
健康监测是最适合于边缘智能的使用场景之一。文献[17]提出了一种轻量级边缘智能框架,该框架基于“物联网终端-网关边缘-云端”的结构,可用于基于心电图的心率监测。
4.1 系统设计
该心率监测系统的软件架构形成的基本类图(Class Diagram)如图3所示。
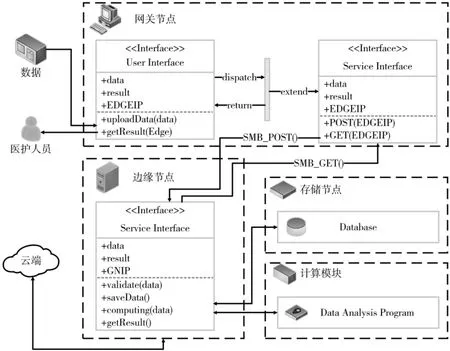
图3 心率监测系统基本类图
在该心率监测系统的运行过程中,其软件架构模型共包括以下三个不同的运行时序:
(1)初始训练时序。为了向边缘节点提供初始的人工智能模型,需要在云端上使用一些历史数据进行训练,以满足边缘节点最初的服务能力。
(2)预测时序。将物联网终端作为数据源,持续进行患者心率情况的分析,并将分析结果通过网关节点呈现给用户。
(3)更新模型时序。边缘节点将数据发送至云端,以供其改进人工智能模型,云端会将模型返回更新至边缘节点。
在该心率监测系统运行后,其软件架构模型运行的基本顺序图(Sequence Diagram)如图4所示。
图4中,数据源同时表示初始历史数据源和物联网终端数据源,时序1.x表示初始训练时序,时序2.x表示预测时序,时序3.x表示更新模型时序。
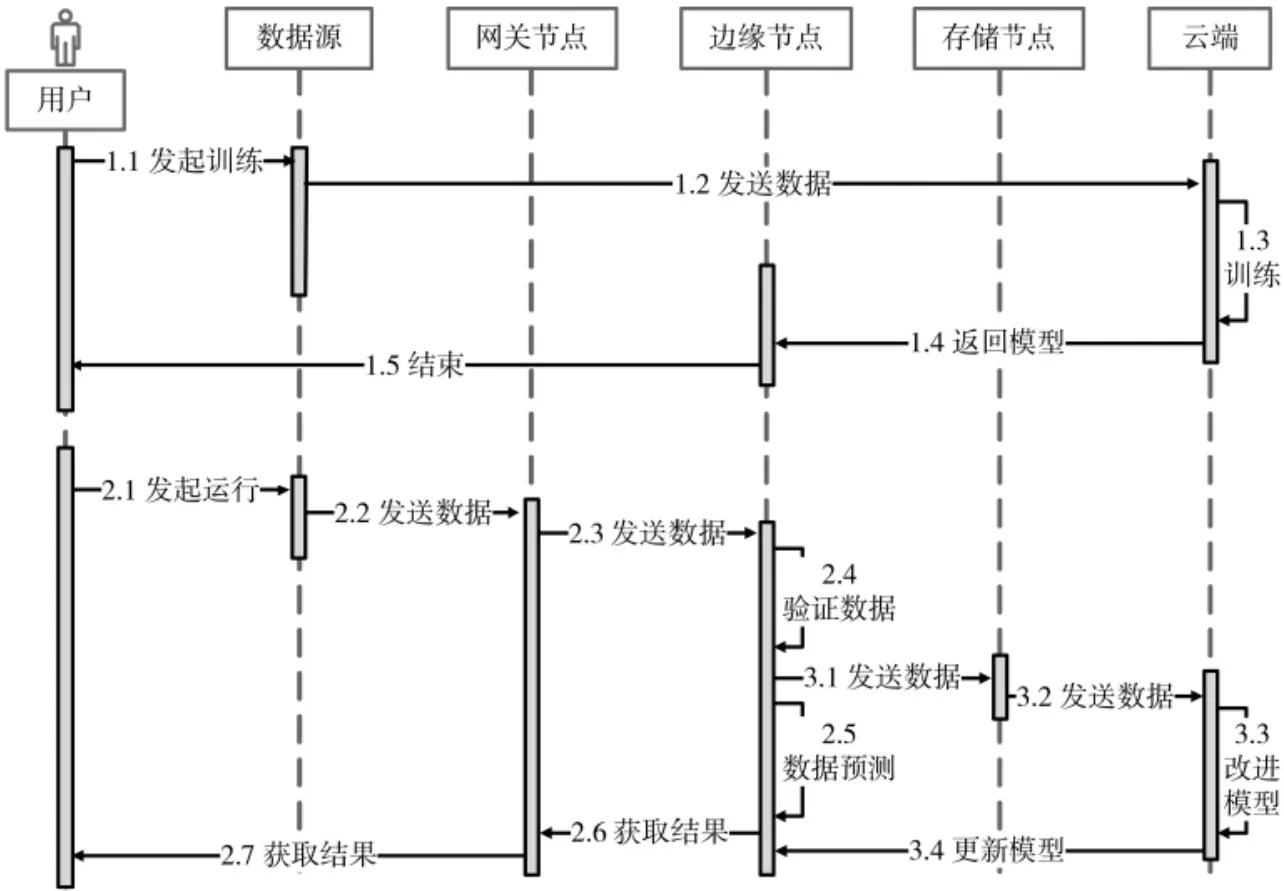
图4 心率监测系统基本顺序图
该系统中的数据源共包括初始历史数据源和物联网终端数据源,为了充分仿真这一环境,将第2节提出的数据集的划分中的DS1数据集作为初始历史数据源,DS2数据集作为物联网终端数据源。DS1数据集用于在云端训练部署在边缘节点上的初始的人工智能模型,DS2数据集用于仿真心电图仪实时产生的数据。
根据第3节得出的最佳心电信号数据样本片段长度,将DS2数据集划分为多个长度为1 350采样点(3.75 s)的片段,随后编写程序,令程序每隔3.75 s随机地输出一段心电信号数据样本片段,以仿真心电图仪在固定的间隔时间输出一段固定时长的心电信号数据。
4.2 仿真结果
将心电数据信号片段按每3.75 s发送一条的频率向网关设备发送,数据经网关设备发送至边缘设备,再由边缘设备发送预测结果至网关设备。网关设备运行接收结果的效果如图5所示。

图5 运行图
实验结果显示,返回结果的平均用时为132.58 ms,可以完全满足边缘智能环境下的心电监测系统的需要。
5 结论
本文提出了一种面向边缘智能环境的心电信号处理方法,并通过实验得出了不同数据样本分段的结果,进一步验证可得,该方法同其他方法性能处于同一量级。基于该方法,本文构建了一个基于边缘智能的心率监测系统,仿真结果表明,该方法在具体的边缘智能框架中真实可用。
在未来的研究中,有以下两点可以继续改进:一是继续探讨更为有效的标签标记方式,使样本标签更加准确清晰;二是在实际应用中,设计更为强大和资源友好型的神经网络模型以满足实际需要。
