改进的TF-IDF算法在文本分类中的研究*
2021-07-24李禾香李骥然
张 伟,石 倩,何 霄,王 晨,李禾香,李骥然
(1.中国石油工程技术研究院有限公司 北京石油机械有限公司,北京102206;2.中国人民大学 信息学院,北京100872)
0 引言
TF-IDF算法结构简单,类别区分力强,且容易实现,被广泛应用于信息检索、文本挖掘、文本分类、信息抽取等领域中。但是,该算法仅考虑词频方面的因素,没有考虑词语出现的位置、词性、样本分布等信息,存在一定局限性。对此很多研究者都提出过改进算法,王小林在传统TF-IDF算法基础上,提出利用段落标注技术,对处于不同位置的词语给予不同的位置权重,并对分词结果中词频较高的同词性词语进行相似度计算,合并相似度较高的词语,改进传统算法中忽视特征词位置因素和语义对相似度的问题[1]。覃世安针对传统TF-IDF算法在分类文本类的数量分布不均时提取特征值效果差的问题,提出使用特征值在类间出现的概率比代替特征值在类间出现次数的改进TF-IDF算法[2]。叶雪梅认为传统的特征词权重TF-IDF算法未考虑到网络新词,针对特征项中的新词对分类结果的影响给予不同权重值,提出基于网络新词改进文本分类TF-IDF算法[3]。这些改进算法都有效提高了模型性能,优化分类结果,取得了不错的实验效果。但以往改进算法研究主要集中在通过完善算法本身的缺陷以实现词条在文本中更加准确的权重赋值,忽略了其他类别区分特征因子。
在对企业日常经营活动文本的数字化处理中,包含信息抽取和文本分类的多任务应用场景,信息抽取结果蕴含大量文本信息,是文本重要的类别区分特征。对此,本文提出一种改进的TF-IDF算法,将文本信息抽取结果作为文本重要类别区分特征,引入信息增益方法得到改进的权重计算公式,进而得到改进的文本特征向量空间表示,再构建文本分类模型。实验结果显示,改进的TF-IDF算法可以有效提高分类器文本分类的正确率。
1 文本分类
1.1 问题描述
文本分类问题包括学习和分类两个过程,学习过程的目标是根据已知的训练数据构建分类模型得到分类器;分类过程的任务是利用得到的分类器,预测新数据的类别。假设{(x1,y1),(x2,y2),…,(xn,yn)}表示已作类别标注的文本训练数据集,n表示文本个数,xi表示文本实例,yi表示xi对应的类别标号,学习系统以训练数据集为基础,从中学习到分类器y=f(x),分类器对新输入实例xn+1进行分类,以预测其输出的类标记yn+1[4]。分类问题描述如图1所示。

图1 分类问题描述图
1.2 文本分类关键技术
中文文本分类问题包含文本预处理、文本预处理、文本表示、特征降维、分类算法等。其流程图和关键应用技术如图2所示。

图2 文本分类关键技术
1.2.1 中文文本预处理
中文文本不同于英文文本,词与词之间没有明显的区分,需要使用分词器对中文文本分词。具体到实际应用中,因为不同行业都有较多属于自己行业内不常用的专业术语、特殊词汇,并且不同类型文本中常用词的表达也有差异,单使用分词器的通用词库获得的分词结果错误率较高,会直接影响文本特征的表示效果。所以通过加入自定义行业词典和文本关键词词典,来有效提高分词器对中文文本分词的准确率。
文本预处理时还需要过滤掉常见停用词和标点符号,这类词和符号往往对文本类别区分没有什么作用,但会占用大量文本特征向量维度空间,增加计算复杂度。通过载入停用词表,除去分词结果中不重要的词条,保留重要的词条。
1.2.2 文本表示
文本预处理结果为多词条集合的文本数据,分类算法无法直接处理文本数据,需要把文本数据表示为计算机能处理的数值型数据[5],目前常用的文本表示方法有:布尔模型、向量空间模型(Vector Space Model)、概率模型、图空间模型[6]、词嵌入模型[7]。
向量空间模型(简称VSM)是目前应用最广泛的文本表示方法,VSM把每篇文档都表示为特征词-权重向量形式,把文本看作是一系列特征项t的集合,对每个特征项赋予对应的权值。如表1所示,其中t1,t2,…,tn可以看作文本中的词条,w1,w2,…,wn表示词条对应的权重值,d1,d2,…,dm表示每篇文本映射的一个特征向量。特征项权重值的计算方法有:TF-IDF权重法、布尔权重法、熵权重法[8]。
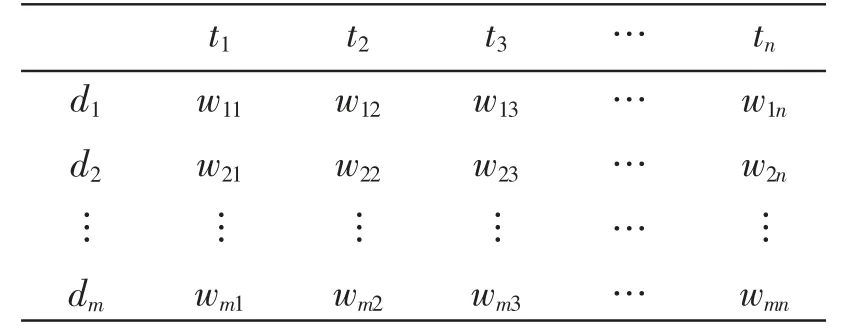
表1 文本特征向量空间
1.2.3 特征降维
在使用VSM模型时,如果训练文本集较大,文本特征向量的维度可能过大,十分浪费计算机的资源,不利于计算,同时,特征的冗余以及缺乏有效关联也会影响分类性能[9]。因此,对文本特征降维尤为重要。
特征降维的方法包括特征选择和特征抽取两种,特征选择指不改变原始特征空间的性质,只是从原始特征空间中选择一部分重要的特征,组成一个新的低维空间,常用的特征选择方法有互信息、信息增益法,卡方检验法,文档频次(Document Frequency)法等。特征抽取则通过将原始高维度特征空间进行映射(或变换),生成低维度的特征空间[10]。常用的特征抽取方法有主成分分析(Principle Component Analysis)、特征聚类等。
1.2.4 分类算法
得到了文本的数值型向量空间表示后,可以使用分类算法构建分类模型、训练分类器。常用的传统机器学习分类算法有:朴素贝叶斯、K最近邻、支持向量机、决策树等。通常情况下,作为有监督学习,其分类准确率高于无监督和半监督方法[11]。
1.3 评价
文本分类任务结果包含4种情况,TP表示属于该类别的文本,被正确分类为该类的文本数;FN表示属于该类的文本,被错误分类为其他类目;FP属于其他类的文本,被错误分类到该类目;TN表示属于其他类的文本,被正确分类到其他类目;一般以精确率P、召回率R和F值作为文本分类性能的评价指标,其计算公式如式(1)~式(3)所示[12]。
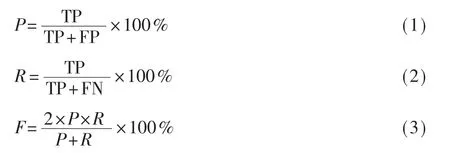
式中:P(Precision)为精确率,它表示在所有被分类为该类的文本中分类正确的概率;R(Recall)为召回率,它表示在所有属于该类的文本中分类正确的概率;F值为精确率和召回率的调和平均值。
2 TF-IDF算法
2.1 传统的TF-IDF算法
2.1.1 权重值计算
TF-IDF(Term Frequency and Inverted Document Frequency)是最常用的权重值的计算方法,用以评估某一词条对于整个文件集或语料库中的某一份文档的重要程度。词频tf表示该词项在文档中出现的频率;逆向文件频率idf反映该词项在文档数据集中的重要程度[13],主要计算公式如式(4)~式(6)所示。
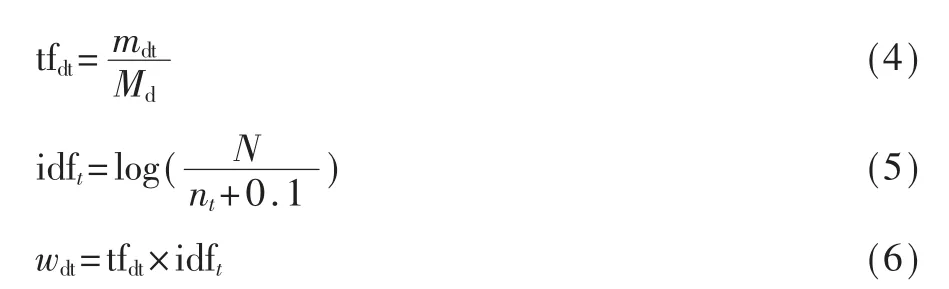
tfdt值通常需要被归一化,一般是特征项t在文本d中出现的频次mdt除以文本d中总词数Md,以防止它偏向长的文件。idft由总文件数N除以包含特征项t的的文件数nt(加0.1是为了避免分母为0的情况),再将得到的商取对数得到。wdt表示特征项t在文本d中的权重值。
2.1.2 归一化
为使各特征项权重值都处于[0,1]区间内,使用余弦归一化的方式进行归一化处理,得到新的权重计算公式如式(7)所示,k为文本d中特征项个数。
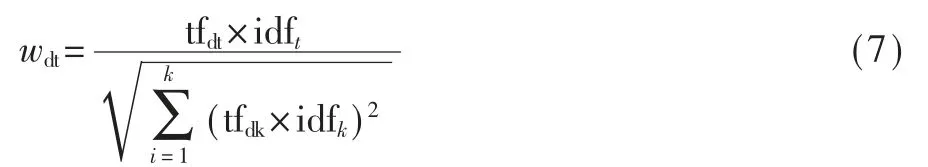
2.2 改进的TF-IDF算法
2.2.1 定义文本关键词集合
信息抽取任务是指从自然语言文本中抽取指定类型的实体、关系、事件等信息,其中包含大量文本特有内容,对文本具有很好的类别区分能力。在使用基于规则的信息抽取任务中,通过识别文中触发抽取任务的关键词来定位要抽取信息所在的位置[14]。构建与信息抽取结果直接关系的文本关键词集合。
2.2.2 信息增益方法
信息增益(InformationGain,IG),定义为数据集D的信息熵H(Y)与条件X给定条件下Y的条件熵H(Y|X)之差[15]。信息增益值越大,说明特征项对数据类别区分能力越强。具体公式如式(8)~式(10)所示。
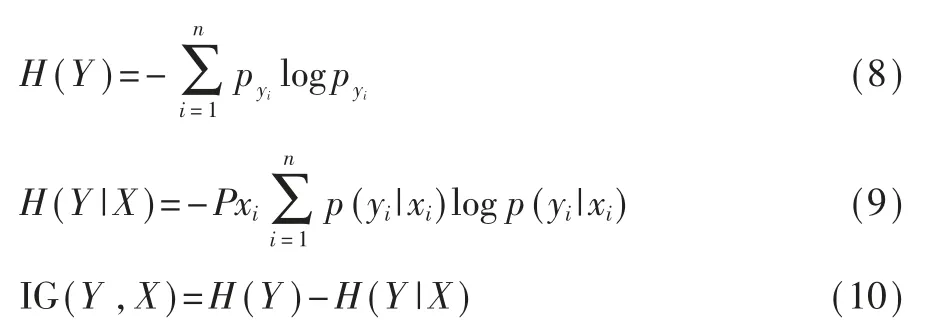
在分类问题中,通过统计某一特征项xi在类别yi中出现与否,来计算信息增益值。其计算公式如式(11)所示,pyi表示yi类别文本在语料中出现的概率,即yi类别文本数除以总的文本数;pxi表示语料中包含特征项xi的文本的概率,即包含特征项xi的文本数除以总的文本数;x¯i表示不包含特征项xi的文本;p(yi|xi)表示文本包含特征项xi时属于yi类别的条件概率,即包含特征项xi且属于类别yi的文本数除以包含特征xi的文本数。

2.3.3 改进的权重计算公式
改进的TF-IDF算法将信息抽取结果项与对文本类别的信息增益值φ,融入到权重计算公式中,以增加特征项对类别区分能力,得到改进的权重计算公式如式(12)所示。

在文本表示过程中,识别文中与信息抽取结果直接关系的关键词,如关键词对应信息抽取结果为真,则使用改进的权重计算公式计算特征项权重值,否则按传统权重计算公式wdt计算。文本特征项权重赋值如式(13)所示。t表示文本中特征项;T表示与抽取结果直接关系的文本关键词集合;R表示对应信息抽取结果为真。
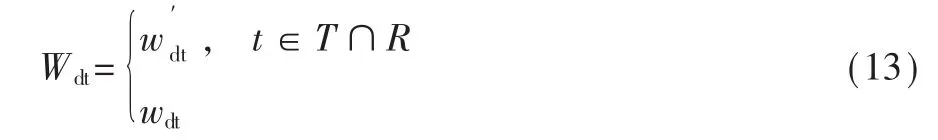
3 实验与结果分析
3.1 实验环境
数据集使用包含信息抽取结果的石油行业中文文本2 006条,文本中包含油服日报、完钻简报、其他3类。本实验编程语言使用Python 3.6;主要运行环境包括Jupyter Noetbook软件、Windows 10系统、8 GB内存。
3.2 实验结果
实验使用结巴分词器加载自定义石油行业和文本关键词词典、去除常见停用词和标点符号,实现对石油行业中文文本分词预处理。使用传统TF-IDF算法和改进的TF-IDF算法在K最近邻、支持向量机、决策树3种不同分类模型下进行对比试验,得到F1-score结果如图3所示。
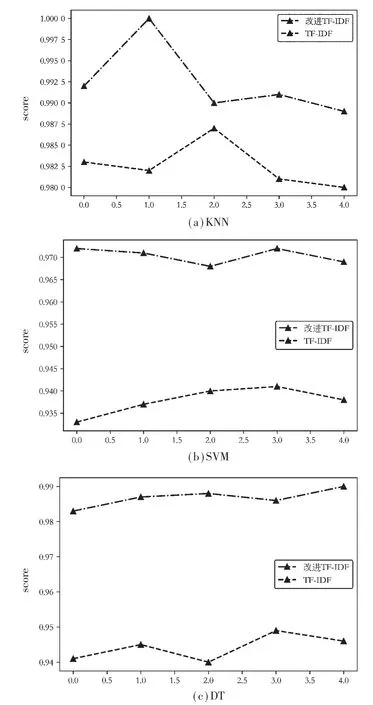
图3 改进的TF-IDF算法在不同分类模型F1值比较
使用准确率P、召回率R、F值等评价指标对油服日报、完钻简报、其他3类文本分类实验结果进行评估,结果如表2所示。
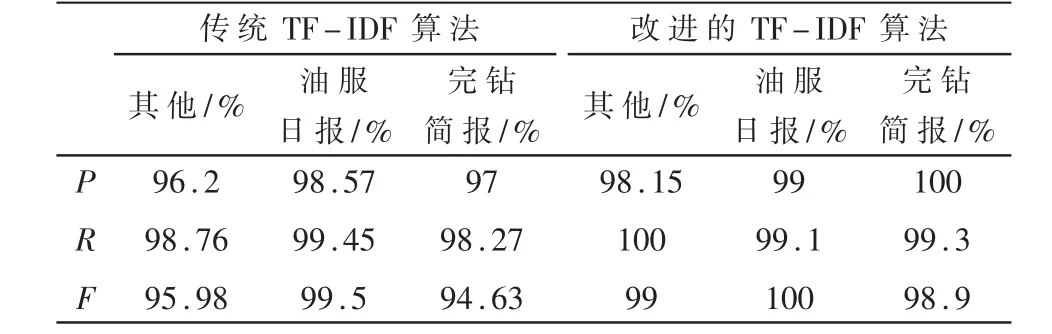
表2 分类效果评价
3.3 结果分析
(1)使用相同TF-IDF算法在不同分类模型下对样本数据的分类效果略有不同,其中K 最近邻分类模型相比于其他两种分类模型分类效果更好。
(2)改进的TF-IDF算法在K最近邻、支持向量机、决策树3种不同分类模型下分类结果都要优于传统TF-IDF算法。
(3)改进的TF-IDF算法对样本数据中不同类别文本的准确率P、召回率R、F值都得到了明显提高。
4 结论
本文针对在包含信息抽取和文本分类的多任务应用场景下,提出一种改进的TF-IDF算法,将文本信息抽取结果也作为文本重要类别区分特征,引入信息增益方法得到改进的权重计算公式,进而得到改进的文本特征向量空间表示,再构建文本分类模型。通过对比实验结果表明,改进的TF-IDF算法具有更好的文本分类效果,可以有效提高分类器文本分类的正确率。但使用基于TF-IDF的向量空间模型,前提是假设特征词之间相互独立的,但在实际中词与词之间会有一定的关联,因而会忽略文本上下文关系,无法表征特征词的语义信息。后期研究可以使用包含语义关系的词向量来替代TF-IDF算法实现文本向量空间表示。
