基于补丁特性的漏洞扫描研究
2021-07-24刘思琦王一鸣
刘思琦,王一鸣
(北京交通大学 计算机与信息技术学院,北京100044)
0 引言
在时间维度上,漏洞都会经历产生、发现、公开和消亡等过程,不同的时间段,漏洞有不同的名称和表现形式。1day漏洞是指在厂商发布安全补丁之后,大部分用户还未打补丁的漏洞,此类漏洞依然具有可利用性。在各类型软件中,许多漏洞的寿命超过12个月,针对此类漏洞的通用应用修复办法是使用代码匹配[1],但是往往通过补丁做出的修补都是一些细微的变化,这会导致许多代码匹配的方法不精确且不通用,造成结果高误报。
基于以上问题和背景,本文设计了一种由源代码到二进制的基于补丁特性的漏洞扫描模型Bin-Scan;基于现存算法设计了一种源代码漏洞检测算法,构建了基于公开网站的漏洞信息数据库,并得到了基于补丁源代码检测漏洞情况的初步结果;提出了一种利用补丁前后文件形成漏洞库,基于CFG和代码相似性的二进制漏洞检测算法;实现了通过识别二进制文件补丁是否存在以检测漏洞。
1 相关工作
1.1 研究背景
漏洞扫描包括静态漏洞扫描和动态漏洞扫描,静态漏洞扫描主要包括已知漏洞扫描和未知漏洞扫描,已知漏洞扫描又根据研究对象不同分为源代码扫描和二进制代码扫描。为提高漏洞检测的准确率并降低误检率,确保检全率与正确率的平衡,源代码漏洞扫描检测代码复用,主要使用方法有利用正则化窗口匹配的Redebug[2],利用签名匹配的VUDDY[3]、VulPecker[4]以及基于深度学习的漏洞检测系统VulDeePecker[5]等。关于二进制代码的漏洞扫描方法包括bug签名、树编辑距离、控制流图和过程间控制流分析等。2016年CCS发布Genius[6],它将CFG转换为数字特征向量用哈希技术实现搜索,可针对不同平台的二进制代码检测,但检测精度却只有28%;2017年CCS发布Gemini[7],其在Genius的基础上进行改进,使用神经网络嵌入算法大大减少嵌入生成时间和培训时间;2016年NDSS发布discovRE[8],使用控制流图计算相似度,识别其他架构的类似函数,可跨架构进行二进制代码的漏洞检索;2019年S&P提出Asm2Vec[9],可通过提取出函数特征之间的关系设计针对汇编代码语法以及控制流图的表示学习模型。
漏洞扫描中,一方面,设计的漏洞检测方法需要无视与漏洞无关的代码更改部分,如函数升级和编译器优化的情况;另一方面,检测方法也需要足够的检测精度才能过滤掉那些已经进行过补丁修复而不存在漏洞的函数。基于上述情况,这就需要利用补丁特征检测代码中存在的已知漏洞。将源代码漏洞检测与二进制扫描结合在一起,可以将源代码级的漏洞检查能力应用到二进制代码中。2014年USENIX发布BLEX[10],这是最先利用基于补丁的漏洞产生工具。2018年USENIX发布FIBER[11],其从补丁生成二进制签名,尽可能保留源码补丁信息查找二进制漏洞。
1.2 相关理论
1.2.1 例子
在之前的实验中笔者发现源代码检测经常会出现诸如模糊匹配及单纯结构匹配不精确的问题,如图1的CVE-2013-2852,它的目的是解决Linux内核中利用格式字符串说明符获取用户访问权限的漏洞,在文件中体现为main.c文件的b43_request_firmware函数存在格式字符串漏洞,补丁文件在代码层面只是增加了参数的类型,改动非常细微,若单纯结构匹配发现不了此漏洞。

图1 CVE-2013-2852的补丁
1.2.2 代码重用
代码重用在软件中非常普遍,所以对代码进行检测其实很多情况下都是对重用的代码进行漏洞的检测。
如图2所示,如果S1部分包含漏洞,S部分是S1的代码重用,那么代码文件P1包含漏洞,P也包含漏洞。
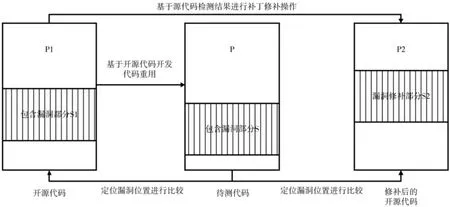
图2 检测代码重用漏洞的定义
二进制检测时无法使用类似源代码的补丁文本匹配,二进制差异性分析可以找到待检测二进制文件P与P1、P2哪个更相似,来判断是否有漏洞。
2 基于补丁特性的漏洞扫描模型构建
图3为BinScan方法概述,以源代码、CVE漏洞的补丁diff文件、二进制待检测代码为输入,输出为二进制代码是否含有CVE。此方法的核心有三部分:基于补丁的源代码漏洞扫描方法、基于CFG的漏洞特征库生成方法和基于代码相似性匹配的二进制漏洞扫描方法。

图3 BinScan方法概述
由于NVD等漏洞信息存在不一致的问题[12-13],并不确定源代码是否已经进行了补丁修补。因此采用源代码漏洞扫描方法对给定版本的代码进行扫描,以确定给定版本的源代码存在哪些漏洞,排除那些源代码中不存在的漏洞,缩小对二级制代码漏洞的检测范围,提高检测效率。
基于补丁的源代码漏洞扫描方法:BinScan在输入待测Linux Kernel源代码后,首先利用漏洞信息库使用检测算法进行细粒度匹配,其次利用影响版本号库进行粗粒度筛选,最后生成源代码所存CVE漏洞结果。
基于CFG的漏洞特征库生成方法:利用源代码检测CVE结果生成补丁前后二进制文件,提取结构信息形成特征。
基于相似性匹配的二进制漏洞扫描方法:计算待测二进制文件与漏洞补丁前后二进制文件相似度,检测补丁是否存在。
2.1 源代码漏洞扫描方法
系统中找到所有含有漏洞、未修补的重用代码是很困难的,这需要综合考虑很多问题。比如语句的顺序是否会改变匹配的精确度、算法设计考虑语义还是语法等。
针对以上问题,结合对现存的源代码漏洞扫描方法的研究,本文提出的BinScan漏洞检测工具应满足以下几点需求:(1)本文虽主要针对Linux Kernel的源代码及漏洞信息进行实验,但BinScan也应具备一定范围的通用性。其他应用工具代码按所述步骤操作后也能适用本节设计的算法,其中MySQL、OpenSSL、Firefox等工具已经通过实验验证;(2)要最大限度地减少误报率和漏报率;(3)尽可能集成化,简化使用者的操作步骤,减少参数配置,生成清晰简洁的检测报告;(4)可迁移性强,适应多种环境配置。
本文采用的源代码漏洞扫描方法基于补丁代码的函数定位与漏洞匹配,具体步骤如下:
首先数据预处理标准化每个文件,包括删除语言注释和所有与代码逻辑无关的语句,寻找漏洞影响路径,根据函数进行定位,将待检测原始代码的片段与补丁代码的片段相互匹配。根据diff文件特性,可利用更改函数中的改变位置前三句和后三句共六句定位语句进行精确定位。
根据补丁文件的“+”“-”前缀语句,可以判断一个文件是否含有此CVE漏洞。通过代码定位可找到目标更改函数,查看函数中的补丁定位语句前三句,针对每一句修改语句进行源代码检索,匹配源代码中此条语句查看是否已经进行修改,若整个文件“+”语句并未添加,“-”语句没有删除,也就说明此版本还存在这个漏洞未修复。以此类推,逐行检测,将搜索到函数后三句定位语句作为结束的标志。
最后利用漏洞影响版本库中最大的漏洞影响版本号与待测文件版本进行比较,加入版本限制。
2.2 基于CFG的漏洞特征生成方法
基于2.1节所述源代码已知漏洞扫描方法,既能够构建完整的源代码漏洞检测系统,获取源代码漏洞检测结果;也能够将源代码漏洞检测结果作为标准值,进一步用于二进制漏洞检测方法中。
在源代码补丁前后分别进行make编译,之所以不用gcc操作是因为Linux Kernel引用的头文件太多,在gcc的过程中很可能出现各种故障,使二进制文件的bin文件不可读。使用xxd语句形成hex文件,用UltraEdit查看、用diff语句得到差值并用compare初步分析可发现补丁修复变化过于复杂,于是用objdump-d语句将二进制文件转换为可读的反汇编文本文件。
由于编译的复杂性及地址的随机性,二进制代码检测无法使用类似2.1节所述源代码的补丁文本检测方法。如图4所示,file.c文件函数中加入语句inode_dio_wait(inode),即使只更改函数中的一条语句,二进制文件中都会有很大的改动。在这种情况下,利用CFG和操作码可以解决这个问题。
利用IDA Pro处理待测二进制文件及补丁前后二进制代码,生成包含上下文信息的控制流图(Control-Flow Graph,CFG)和基本块的特征向量,每个基本块特征信息包括两部分,分别是生成标记嵌入和生成特征向量。生成标记嵌入时曾尝试使用ACFG(Attributed Control Flow Graph)方法,它是一种基于神经网络的嵌入,但是本文主要针对的还是补丁变化,将图表示作为整体进行评估会忽略细节。本文在实现时首先对二进制文件执行预处理,然后应用DeepBindiff[14]算法,该方法运用了Word2Vec算法[15]生成词向量的思想以及deepwalk随机游走技术生成了网络节点的表示。通过在图上随机游走生成文章,每个游走序列都会包含一些基本块。然后,通过标准化和模型训练得到标记嵌入模型并生成标记嵌入,这里的标记指的是操作码或者操作数。由图4可知每个基本块都包含了多行指令,每个指令都包含了多个操作数及MOV、CMP等操作码,操作码与操作数是一对多的关系,于是指令的嵌入就可以用操作码的嵌入与操作数的平均嵌入值来连接获得。式(1)[14]具体解释了区块特征向量的计算方法。其中,b表示一个块,p是操作码,embedpi是操作码嵌入,weightpi是上述模型中的TF-IDF权重,setti是操作数,embedtin是操作数嵌入的平均值。


图4 更改函数语句所做改变
特征生成结果如图5所示,将源码的一个版本整体编译成功后,再进行补丁操作,使用补丁前后编译形成的二进制文件,通过建立包含漏洞的文件数据库和修补过的文件数据库形成二进制漏洞数据库,进一步区分修补过和未修补的函数。将漏洞数据库和待测文件输入算法即可得到特征信息。

图5 生成特征
2.3 基于相似度匹配的二进制漏洞扫描
相对于直接从源代码补丁形成漏洞签名,利用源代码漏洞结果信息标定初步漏洞范围,再将待测文件与二进制文件打补丁前后文件进行相似性检测得到块匹配结果可以更好地获取与使用在二进制代码层面的漏洞信息。当一个新的Linux Kernel二进制文件需要检测是否存在漏洞时,需要利用文件特征向量,用TADW算法和k跳贪婪匹配将两文件结合,进行块嵌入生成和块匹配操作,得到补丁前后两次二进制文件所有块的匹配结果。根据匹配结果,即可判断待测文件与补丁前还是补丁后的二进制文件更为相似。若目标二进制文件与补丁前的文件匹配对更多,则此文件未打补丁,存在该检测漏洞;若目标二进制文件与补丁后的文件匹配对更多,则此文件已打补丁,不存在该漏洞。
3 实现与分析
3.1 环境及数据库搭建
本文使用Python3.6在Linux平台和Windows平台上实现BinScan工具。为了构建较全的已知漏洞补丁库,首先分析了各大漏洞披露网站的信息,最后选取NVD网站作为数据来源。本文定义了20个关键词用于漏洞补丁信息的爬取,如Python、Linux Kernel、Wget等,以这些关键词为检索词条获取相关漏洞披露网站的URL。抓取的软件信息OSS表字段包括软件名称(Name)、关键词(Key Word)、软件描述(Description)以及NVD记录信息的总数量(NVD Records Count)。根据表中信息,可利用Python的bs4库定制爬虫,从NVD网站上批量爬取每条软件数据的详细漏洞补丁信息,比如软件的CVE Number、Vulnerability Type、Base Score(包括V3与V2)等信息,以供后续步骤分析和使用;通过CVE参考链接统计工具,将参考链接的网站主站点URL进行计数,并逐一验证是否可以查阅到补丁代码,根据这些信息将Hyperlink信息提取进行排序可以得到前三位有用且占比最大的网站,它们的数量及占比如表1所示。分别编写这三个网站的爬虫,爬取网站结果形成Linux Kernel文件夹,并获取补丁前代码(bm)、补丁后代码(am)、补丁diff文件、危险等级信息(score.txt)以及来源网站(source.txt),这里结果数据库的网站占比如表2所示。最后筛选后Linux Kernel数据库中有2 700条漏洞数据,15 496个patch文件。在此步骤中,本文也使用了其他工具,如OpenSSL、OpenSSH、Firefox、Python等,每换一个工具都需要利用漏洞Hyperlink信息排序,重新编写适合爬取这个工具补丁的网站爬虫。

表1 网站筛选
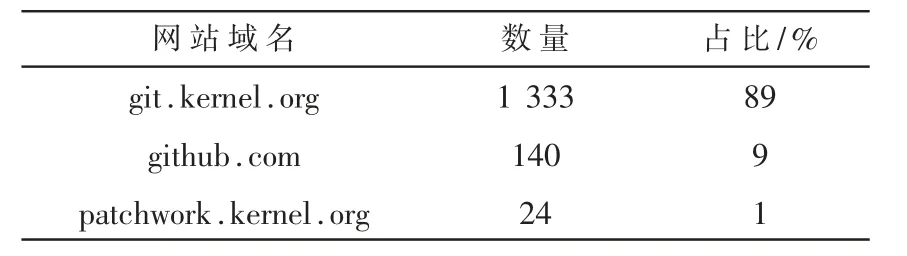
表2 结果数据库网站占比
3.2 程序运行
3.2.1 源代码漏洞检测
源代码漏洞扫描方法实现流程如图6所示,循环查看补丁文件是单文件还是多文件以及patch文件中存在@@定位语句的数目,以Linux Kernel3.10版本为例在算法未优化时运行结果共存在CVE 290条,优化后运行结果共存在CVE 261条。图7为算法粗粒度筛选前后的检测结果对比图,其中第一列CVE_number深色指的是代码不包含但在检测中却检测出的及优化后漏报的漏洞,第二列patch_file深色指在算法优化后去除的错报和存疑漏洞。为呈现清晰,本图忽略了project_file和level内容。经验证,优化后算法准确率明显提高,目前此算法的准确率为93%。

图6 2.1节算法实现流程

图7 2.1节算法约束前后实现结果对比
3.2.2 二进制代码漏洞检测
由于整个Linux内核数据量巨大,下文主要以Linux Kernel 4.2为例,在已经进行版本4.2的源代码漏洞检测基础上,对二进制代码漏洞检测流程进行说明。首先此版本源代码检测出漏洞CVE-2015-8785,存在文件路径为fsfusefile.c,于是在Linux环境中make编译4.2版本的Linux Kernel代码,用此漏洞的diff文件对目标路径文件进行补丁操作,然后进行第二次make编译,将编译前后的obj文件分别存放到补丁前文件夹“before”和补丁后文件夹“after”中,最后将补丁前后文件与待测文件作为input1和input2,共得到3 373节点数及3 307个公共节点数,整个数据大小为26 456,将结果存储到结果特征中并可得到基本块索引。因为此漏洞Linux Kernel最后一个影响版本号是4.3.3,于是再编译4.3版本进行匹配检验,得到此版本的块匹配结果,发现亦存在此漏洞,验证了方法的准确性。
以Linux Kernel的4.19版本为例进行方法验证,将Linux Kernel的vmlinux文件以section形式分开,分开检测代码函数相似度,最后检测结果如表3所示。

表3 验证检测部分结果
3.3 分析及评价
为检验算法的有效性,将BinScan与Redebug等现有源代码检测算法对比,结果表明BinScan可有效提升漏洞检测准确率。使用Redebug工具对源代码进行漏洞检测时会产生误报现象,如检测Linux Kernel4.13版本时,会检测出漏洞CVE-2011-2497,但是实际上这个漏洞并不存在,本文提出的方法可解决此误报问题。除此之外,本文算法还能系统化地生成整个待测源代码包含的所有漏洞信息,而不是针对一个漏洞的一条CVE进行检测。
与利用补丁代码信息形成补丁签名Fiber相比,BinScan还使用了漏洞信息对源代码进行补丁操作,生成补丁前后编译的文件,此工具在对补丁代码本身分析的基础上,联结了上下文信息,增加了比较准确率。本文提出的基于补丁的漏洞检测算法既可以解决二进制代码没有源代码支撑做漏洞检测的问题,也可以利用补丁的精确特性降低漏洞检测误报率。结合上述实验,不仅证明了BinScan工具对Linux Kernel的可用性,而且验证了其他软件工具的可用性,因此可以将本方法迁移到Linux系统的应用工具中,如OpenSSL、OpenSSH等。
4 结论
本文提出了一种针对代码重用的利用源代码检测结果和二进制代码补丁前后的二进制文件进行漏洞检测的方法,设计并实现了由源代码到二进制的漏洞检测模型BinScan工具。它可以实现源代码检测并且将其结果运用到二进制代码的检测中,以及将源代码级的漏洞检测应用于二进制级相似性检测来检测补丁存在性。本文对Linux Kernel的漏洞检测进行评估,结果表明,本文提出的检测算法在一定程度上克服了二进制代码检测不精确且不通用的问题;对于未得到漏洞特征标记的二进制文件,利用源代码检测信息比传统方法更有优势。
