基于依存关系的命名实体识别
2021-07-23张雪松郭瑞强黄德根
张雪松,郭瑞强,2,黄德根
(1. 河北师范大学 计算机与网络空间安全学院,河北 石家庄 050024;2. 河北师范大学 河北省供应链大数据分析与数据安全工程研究中心,河北 石家庄 050024;3. 大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
命名实体识别(named entity recognition,NER)是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,即自然文本中的实体边界识别和类别识别,其性能好坏对自然语言处理下游任务有直接影响。
在命名实体识别任务中,现有的方法主要采用基于双向长短时记忆网络(bidirectional long short-term memory,BiLSTM)和条件随机场(conditional random field,CRF)的模型[1-3],均达到了较为理想的识别效果;为了进一步改善命名实体识别效果,研究者也尝试通过预训练语言模型来提高命名实体识别性能[4-5]。这些模型大多只是将句子作为一个单词序列去处理,忽略了句子中潜在的句法信息。
依存句法分析为句子中的每个词语找到其依存核心词语,依存弧由核心词语指向修饰词语,并指定一个依存关系类型,从而构成一棵反映句子中各个单词之间语法关系的语法树。如图1所示,“The Dixie Chick are the big winners at the Country Music Awards in Nashville”,例句通过依存句法分析得到了一棵依存树。图中显示了依存关系对于命名实体识别的影响,“The Dixie Chick”是一个“ORG”实体类型,其中有一条外部的依存弧,该弧由单词“winners”指向“Chick”,依存类型为“nsubj”;实体内部存在两条依存弧,由单词“Chick”指向“The”和“Dixie”,依存类型分别为“det”和“nn”。这些依存弧所蕴含的单词间的语法信息对于命名实体类别和边界的识别有辅助作用,但现有模型并未充分考虑句子中所潜在的句法信息,存在长距离依赖问题。

图1 句子依存关系示意图
针对上述问题,我们提出一种新颖的基于依存关系的命名实体识别模型(CPBiLSTM-Att-CRF)。该模型通过在BiLSTM上分别融合单词在依存树中的子节点(Child)和父节点(Parent)信息来进行编码,并通过注意力机制(attention mechanism)动态选择两者特征,最后使用条件随机场模型来预测实体的标签。
本文主要贡献如下: ①构建一个融合依存树中子节点和父节点信息的BiLSTM的端到端模型,将文本的句法信息和上下文信息引入模型中进行学习; ②提出将依存树构建为有向图,通过图卷积神经网络来聚合模型输入数据在依存树中的子节点信息; ③提出利用注意力机制动态选择模型特征,增强模型对依存树信息的有效利用; ④在不同语言的多种数据集上进行实验,验证了模型的有效性。
1 相关工作与研究
在命名实体识别任务中,Mikolov等在文章中描述了循环神经网络模型(recurrent neural network,RNN)[6],RNN针对文本的时序特征进行建模来提取上下文信息,从理论上看RNN可以记录文本中的所有历史信息,但在实际训练中,会导致梯度消失,出现长距离依赖问题。为了解决RNN导致的梯度消失问题,Hochreiter等提出了长短时记忆网络(long short-term memory,LSTM)[7],通过引入“门”这一机制对输入的文本信息进行有针对性的保留和丢弃,使得网络处理长距离依赖的能力得到增强;Huang等提出利用BiLSTM-CRF来处理序列标注任务[1],从其实验结果来看BiLSTM-CRF优于CRF模型、BiLSTM模型、LSTM模型。
在利用依存树信息进行命名实体识别的研究中,Sasano等在支持向量机上引入日语的依存关系来提高模型的命名实体识别性能[8];Ling等提出使用依存弧信息作为特征并利用条件随机场模型进行细粒度的命名实体识别[9];Jie等提出使用半马尔科夫模型来利用依存关系进行命名实体识别[10],同时减少了模型的运行时间;Miwa等利用双向树型长短时记忆网络来获取单词序列和依存树结构信息,并通过在模型中共享参数来进行实体识别和实体间关系抽取[11];Jie等通过将依存关系引入长短时记忆网络来获得依存树信息的方法构建模型,以进行命名实体识别[12],将完整的依存图引入命名实体的模型,证明了通过依存关系来捕获长距离依赖对于命名实体识别性能的提高是有利的。
本文的主要工作是探索一个能够同时利用单词在依存树结构中的子节点和父节点信息以及文本的上下文信息,来提高命名实体识别性能的神经网络模型。
2 模型
2.1 CPBiLSTM-Att-CRF模型结构
BiLSTM-CRF将一组序列信息作为输入,得到一组返回序列,通过学习得到文本中的单词与输出标签之间的关系,最终确定输出的命名实体及其类别。BiLSTM可以充分记录文本的上下文信息,并在一定程度上减弱循环神经网络所存在的长距离依赖问题。Jie等提出将依存树信息融入BiLSTM中来增强单词间的长距离依赖能力[12],但只加入了单词在依存树中的父节点信息,忽略了子节点信息对于命名实体识别的影响。
本文提出CPBiLSTM-Att-CRF模型,利用单词在依存树中的子节点和父节点信息学习文本中潜在的语义信息,以增强模型的长距离依赖能力。模型如图2所示,分为4个部分: ①融合子节点信息的双向长短时记忆网络(左侧①部分); ②融合父节点信息的双向长短时记忆网络(右侧②部分); ③注意力层; ④条件随机场层。
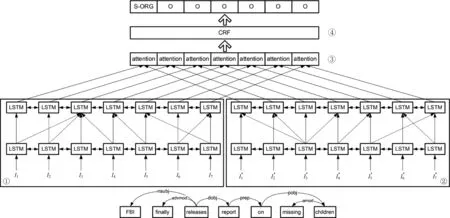
图2 CPBiLSTM-Att-CRF模型
2.1.1 融合节点信息的双向长短时记忆网络
本文提出将单词在依存树中的子节点信息融入BiLSTM中,如图2左侧①所示,模型设置一个两层的BiLSTM,将第一层网络的输出,输入到第二层网络的对应位置和单词在依存树中父节点的对应位置。因此在第二层的BiLSTM中每个单词节点可以额外获得其在依存树中对应的子节点信息。例如,图2例句中单词“report”作为父节点在第二层网络中可以额外获得其子节点“on”的信息;同时作为子节点在第二层网络中将信息传递给其父节点单词“releases”。
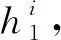
(1)
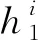
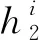
以上,通过改变BiLSTM的层间传播方式,将子节点信息融入BiLSTM,使得模型可以学习单词在依存树中的子节点信息和文本的上下文信息。
2.1.2 融合父节点信息的双向长短时记忆网络
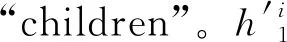
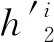
以上,通过改变BiLSTM的层间传播方式,将父节点信息融入BiLSTM,使得模型可以学习单词在依存树中的父节点信息和文本的上下文信息。
2.1.3 注意力层
Rei等将输入表示中字符级特征向量和词向量的拼接改为权重求和的方式来增加注意力[13],从而动态地选择字符级特征和词级特征来获得更好的实验效果。因此本文提出通过构建注意力模型动态选择融合子节点和父节点信息的BiLSTM的两部分输出。两部分在输出的结果上具有相同维度的向量表示。即把两个向量添加可学习的权重后进行求和,并通过一个两层的网络进行学习,如式(6)、式(7)所示。
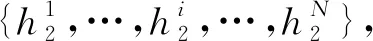
最后将注意力模型的输出H3输入到CRF层中,由CRF层得到最后预测的命名实体标签序列y1,y2,…,yn,完成文本中句子的序列标注。
2.2 CPBiLSTM-Att-CRF模型输入
模型输入分别是融合子节点信息的表示I={I1,…,Ii,…,In}和融合父节点信息的表示I′={I′1,…,I′i,…,I′n}。
在词表示上使用词向量和字符级特征向量两部分拼接表示,由于词向量将单词作为原子单位进行学习时会忽略单词内部的特征,因此通过双向长短时记忆网络将单词的字符级信息进行编码,可以更好地学习单词的形态学特征,并起到降维的作用,也可以自然地解决OOV问题[14]。
在输入数据表示上,除了单词自身的表示信息外,额外加入依存树中该节点的子节点和父节点信息。将依存树中的依存弧表示为一个三元组(xi;xp;r),其中xi为子节点,xp为父节点,r表示该依存弧所表示的两个单词间的依存关系。模型的输入由四个部分拼接得到,分别是: ①词向量表示; ②字符级特征向量表示; ③该词在依存树中与子节点或父节点的依存关系嵌入; ④该词在依存树中子节点或父节点的词表示。
2.2.1 融合依存树中子节点信息的输入
在输入表示中融合依存树中子节点信息,如图3所示,本文利用词向量w和字符级特征向量wc得到的图节点属性[w;wc],以及利用单词间依存关系r的随机初始化嵌入得到的边属性wr,来获得融合依存树中子节点信息的输入。
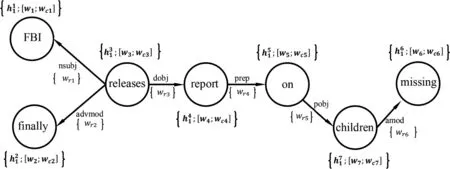
图3 利用依存树构造的有向图
由于依存树中每个节点拥有0到多个子节点,本文提出利用图卷积神经网络来聚合每个单词的子节点信息以及与子节点的依存关系。通过图卷积神经网络聚合单词的子节点表示为wch,聚合单词与子节点的依存关系表示为wchr,如式(8)、式(9)所示。
(8)
其中,0≤j≤nj≠i,j为单词i的子节点,n为子节点个数,W1为可学习权重,wch={wch1,…,wchi,…,wchn}。
(9)
其中,0≥j≥nj≠i,n为子节点个数,W2为可学习权重,wchr={wchr1,…,wchri,…,wchrn}。
通过上述方式得到的输入I=[w;wc;wch;wchr],包含词表示和该单词在依存树中的子节点信息以及与子节点之间的依存关系信息。
2.2.2 融合依存树中父节点信息的输入
在输入表示中融合依存树中父节点信息,将词表示与该单词节点的父节点信息进行拼接。其中,将单词的词向量表示为w,字符级特征向量表示为wc,单词与父节点的依存关系嵌入表示为wpr,父节点表示为wp=[w′;w′c],其中w为父节点单词的词向量表示,w′c为父节点的字符级特征向量表示。从而融合父节点信息的输入表示为I′=[w;wc;wp;wpr]。通过这种方式获得的输入I′包含了词表示和该单词在依存树中的父节点信息以及与父节点之间的依存关系信息。
3 实验
3.1 数据集及数据预处理
实验选择三种不同语言的数据集来证明所提出模型的有效性,分别是OntoNotes 5.0 English和OntoNotes 5.0 Chinese[15]以及SemEval-2010 Task 1 Spanish[16]。
其中OntoNotes 5.0定义了18类实体,使用Stanford CoreNLP将数据集中的选区树转换为斯坦福依存树[17]、OntoNotes 5.0 English[18],利用Pradhan等对数据集的划分方式划分OntoNotes 5.0 Chinese[19]。对于SemEval-2010 Task 1 Spanish,参考Finkel等工作,选择其中主要的三种实体(人名、地名和机构名),并将其他实体标注为“misc”[20]。上述三个数据集均被划分为训练集、开发集和测试集。表1为三个数据集处理后的情况说明。
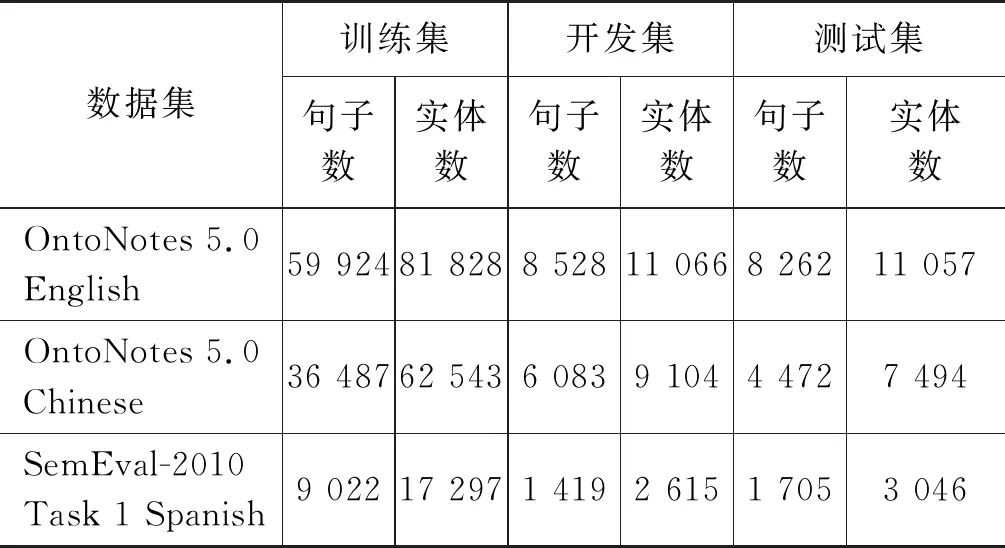
表1 数据集说明
3.2 评价指标
由于命名实体识别是实体边界和类别的识别,在命名实体识别中当两项均识别正确时,才判断为正确,因此本文通过使用精确率(precision)和召回率(recall)来求得F1值,从而衡量本模型的性能,如式(10)~式(12)所示。
其中,N表示模型所预测出的实体总数,M表示通过模型预测得到的正确的实体总数,K表示数据集中所标注的实体总数。
3.3 标签框架
3.4 基线模型
实验选择两层的 BiLSTM-CRF 作为本文的基线模型(BiLSTM-CRF(L=2)word+char)。模型的输入由单词的词向量和字符级特征向量拼接得到。该模型通过将一组序列信息x1,x2,…,xn作为输入来得到一组返回序列y1,y2,…,yn,从而可以学习得到文本中单词与输出标签之间的关系。其中将BiLSTM网络得到的输出进行线性转换,并输入到CRF层中学习标签之间的转换规律来确定输出的命名实体及类别,如式(13)、式(14)所示。
3.5 实验设置
在OntoNotes 5.0 English上,本文选择采用Pennington等提出的 Glove来得到英文词向量嵌入[21]。在OntoNotes 5.0 Chinese和SemEval-2010 Task 1 Spanish上,选择采用Grave等提出的FastText来得到中文和西班牙语的词向量嵌入[22]。实验选用Pytorch框架,GPU选择NVIDIA GeForce GTX 1080 Ti,网络参数优化器选用SGD,超参数设置如表2所示,在该组超参数下数据集获得最优值。
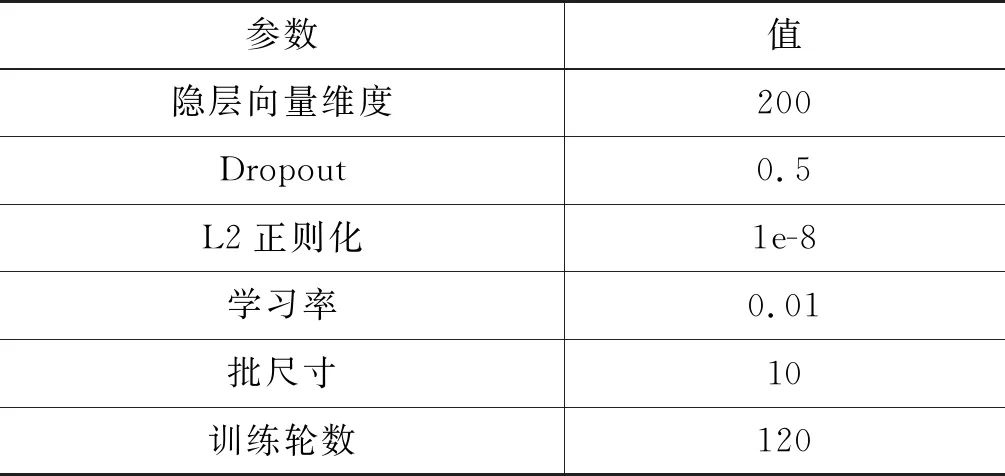
表2 超参数设置
3.6 实验结果与分析
3.6.1 实验结果对比
通过设计消融实验来更加直观地展现本文所提出的模型中各个模块的作用。实验设置5个模型:
(1) 模型BiLSTM-CRF(L=2)word将BiLSTM作为模型编码器,CRF作为模型解码器,输入数据中的单词表示为词向量;
(2) 基线模型BiLSTM-CRF(L=2)word+char;
(3) 模型CBiLSTM-CRFword+char为2.2.1节所提出的融合子节点信息的BiLSTM模型,输入数据中的单词表示为词向量和字符级特征向量;
(4) 模型PBiLSTM-CRFword+char为2.2.2节所描述的融合父节点信息的BiLSTM模型,输入数据中的单词表示为词向量和字符级特征向量;
(5) 模型CPBiLSTM-Att-CRF为本文所提模型,融合单词在依存树中的子节点和父节点信息,输入数据中的单词表示为词向量和字符级特征向量。
据检查预约中心护士长宣姝姝介绍,预约中心在管理上隶属于医院护理部,由医技护理单元护士长负责日常管理工作。作为医技护理单元的护士长,与医技科室的主任沟通协调比较顺畅,便于工作开展。同时,预约中心也接受医务部管理,由其负责协调临床科室、医技科室、行政职能科室。医院的门诊大楼有6层,预约中心选址定在靠中间的三楼,上下楼层的门诊患者走过来都会比较方便;并且与入院准备中心比邻,两个部门可以更好地协调工作。
实验在同样的实验环境下进行,结果如表3~表6所示。可以看出,模型BiLSTM-CRF(L=2)word+char的F1值均高于模型BiLSTM-CRF(L=2)word,证明在单词的表示中除词向量外加入字符级特征向量对于命名实体识别的性能提高是有效的。
表3展示了在OntoNotes 5.0 English上的运行结果,可以看出在同样的实验环境和设置下,CBiLSTM-CRFword+char和PBiLSTM-CRFword+char两个模型的性能均高于BiLSTM-CRF(L=2)word+char。说明无论是融合子节点信息还是融合父节点信息,对于模型性能的提高均是有利的,即模型中加入依存关系对于命名实体识别性能的提高是有效的。从模型CPBiLSTM-Att-CRF得到了最高的F1值可以看出,同时利用单词在依存树中的子节点和父节点信息,可以进一步提高模型命名实体识别的性能。
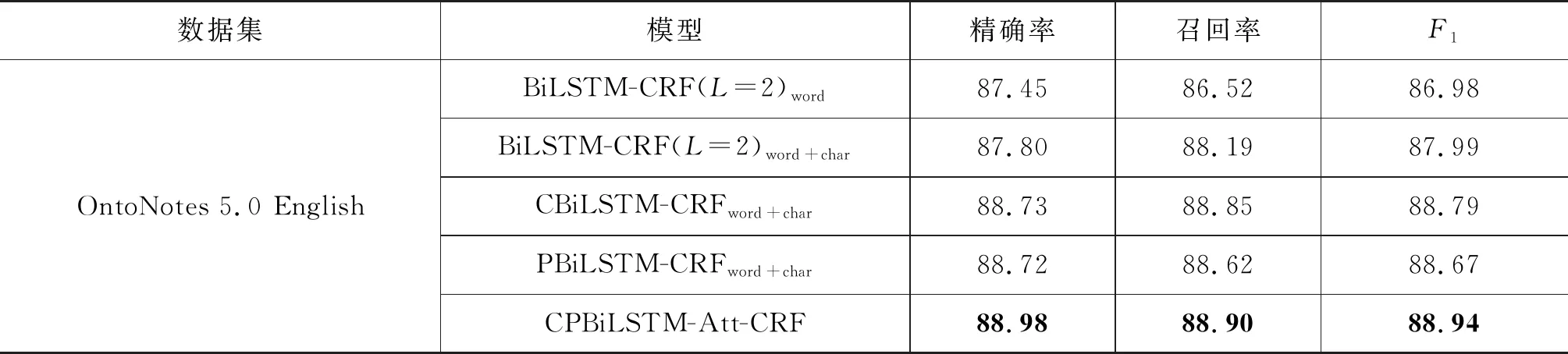
表3 OntoNotes 5.0 English实验结果
表4展示了在OntoNotes 5.0 Chinese上的运行结果,CPBiLSTM-Att-CRF模型得到了最高的F1值,其中召回率较高,但精确率较低。通过分析实验结果可以发现,造成精确率降低的原因有两个: 一个原因是该数据集存在未被标注实体,这些实体被本文模型正确识别,但却被基线模型识别为非实体。例如,“百分之四、五十”“唐山大地震”等实体;另一个原因是在实体类别识别错误的情况下,本文模型识别到的实体边界高于基线模型,如表5中的例句是“这是克林顿赞同明年1月离任以前的最后一次亚太经济合作组织首脑会议”中的“亚太经济合作组织首脑会议”在数据集中被标注为事件实体,基线模型将“亚太”标注为地点实体,而本文模型将“亚太经济合作组织”标记为机构实体,识别到的实体边界高于基线模型。虽然精确率略有降低,但是从另一个方面证明了本文模型在实体边界识别上具有优势。
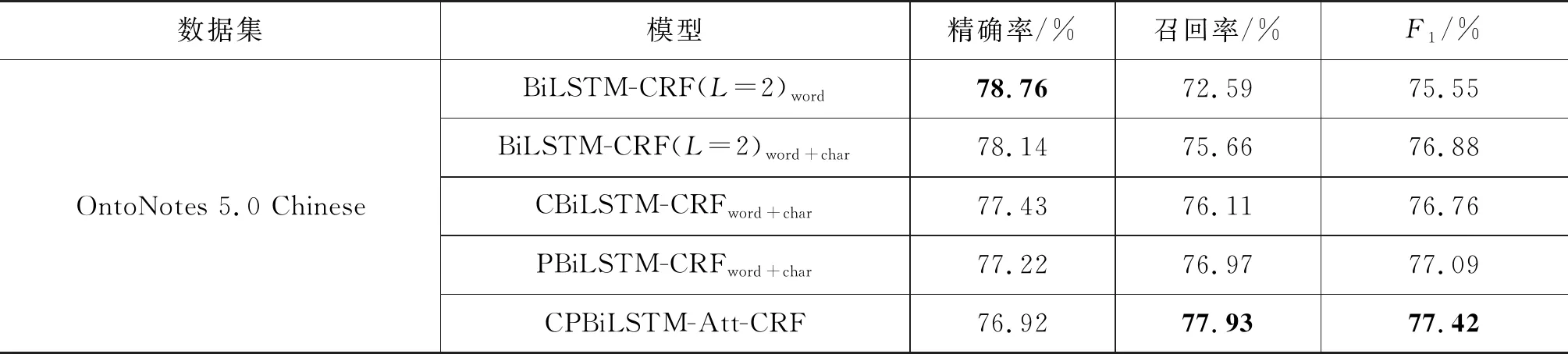
表4 OntoNotes 5.0 Chinese 实验结果

表5 实体在不同模型下的标注对比
表6展示了SemEval -2010 Task 1 Spanish上的运行结果,与OntoNotes 5.0 English得到的结果相似,无论是融合子节点信息还是融合父节点信息,对于模型性能的提高均是有利的。且同时利用单词在依存树中的子节点和父节点信息可以进一步提高模型命名实体识别的性能。
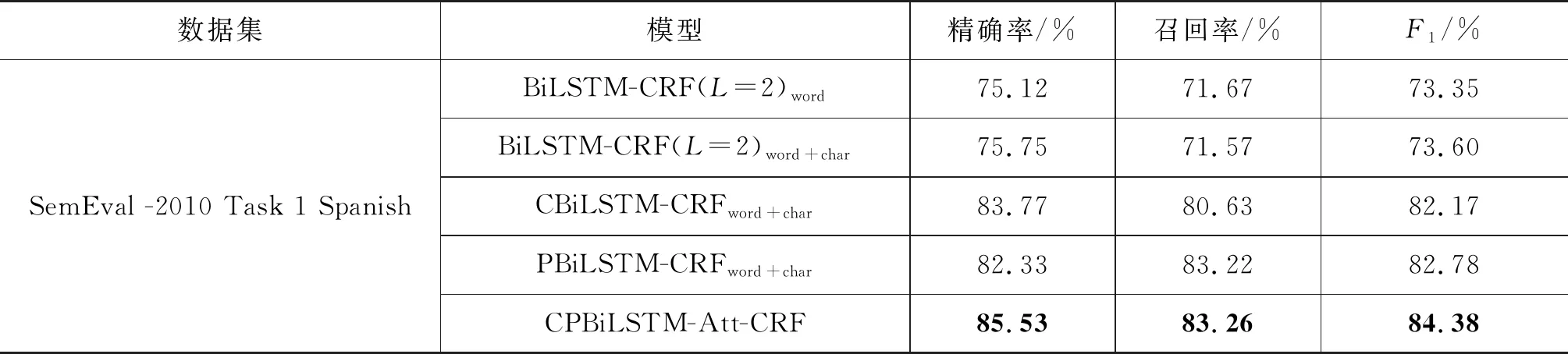
表6 SemEval -2010 Task 1 Spanish实验结果
3.6.2 特定实体类型和不同长度实体实验结果
为了证明CPBiLSTM-Att-CRF模型对于数据集中特定实体类型识别的性能,表7统计了三个数据集中的三类主要实体(人名、机构名和地名)的F1值。可以看出,在OntoNotes 5.0 English和SemEval -2010 Task 1 Spanish两个数据集上,本文所提模型在三类实体上的F1值均高于基线模型,且在SemEval-2010 Task 1 Spanish上高出基线模型7%以上。在OntoNotes 5.0 Chinese上,人名和机构名均高于基线模型2%以上,而地名仅低于基线模型0.39%。
为了进一步证明CPBiLSTM-Att-CRF模型在命名实体识别任务中的性能,本文统计了在不同长度实体下的实验结果,如图4~图6所示。在三个数据集上,基线模型在各个实体长度上均低于本文所提出的CPBiLSTM-Att-CRF模型。可以观察到,模型对于较长跨度实体的识别性能尤为突出。在OntoNotes 5.0 English上,基线模型无法识别出长度为15的实体;在SemEval-2010 Task 1 Spanish上,在实体长度大于9的情况下,基线模型已经基本失去实体识别的能力,而本文所提模型在长度为25的情况下,依然具备识别能力;即使在实体最长为9的OntoNotes 5.0 Chinese上,本文模型在实体识别上也依然具有优势。可以看出,本文模型能够更好地捕捉依存树中实体内部所存在的长距离依赖,而这种长距离依赖能够使得模型在识别跨度更长的实体上具有优势。
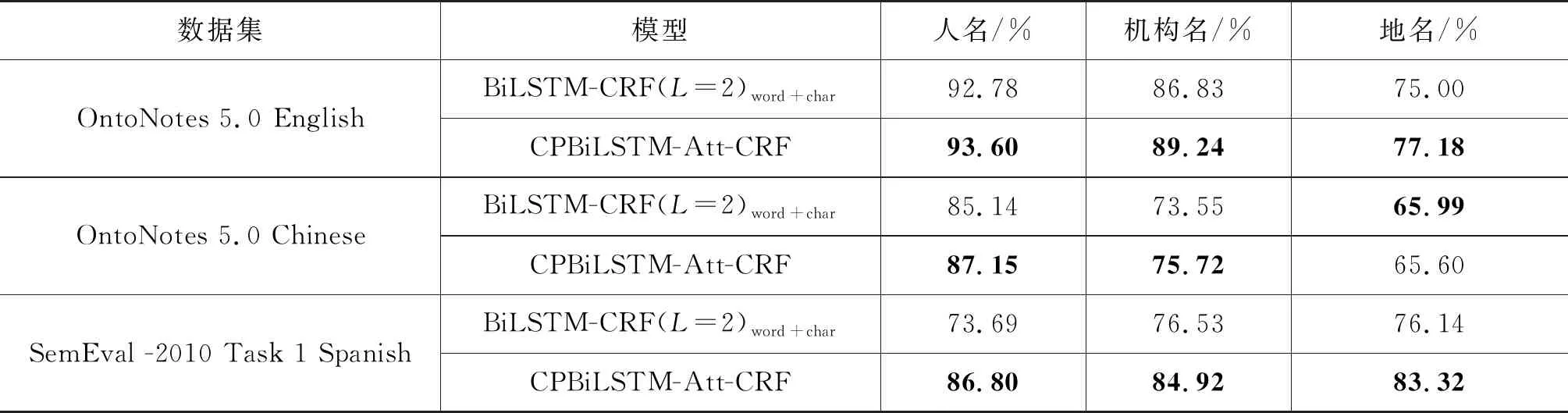
表7 三个数据集中的主要实体F1值
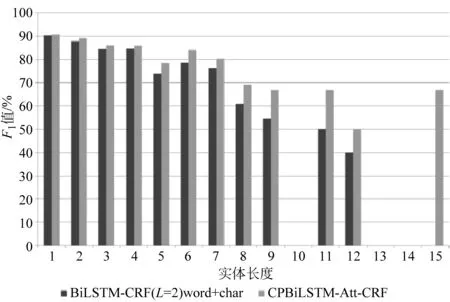
图4 OntoNotes 5.0 English中不同长度实体下的模型性能对比图
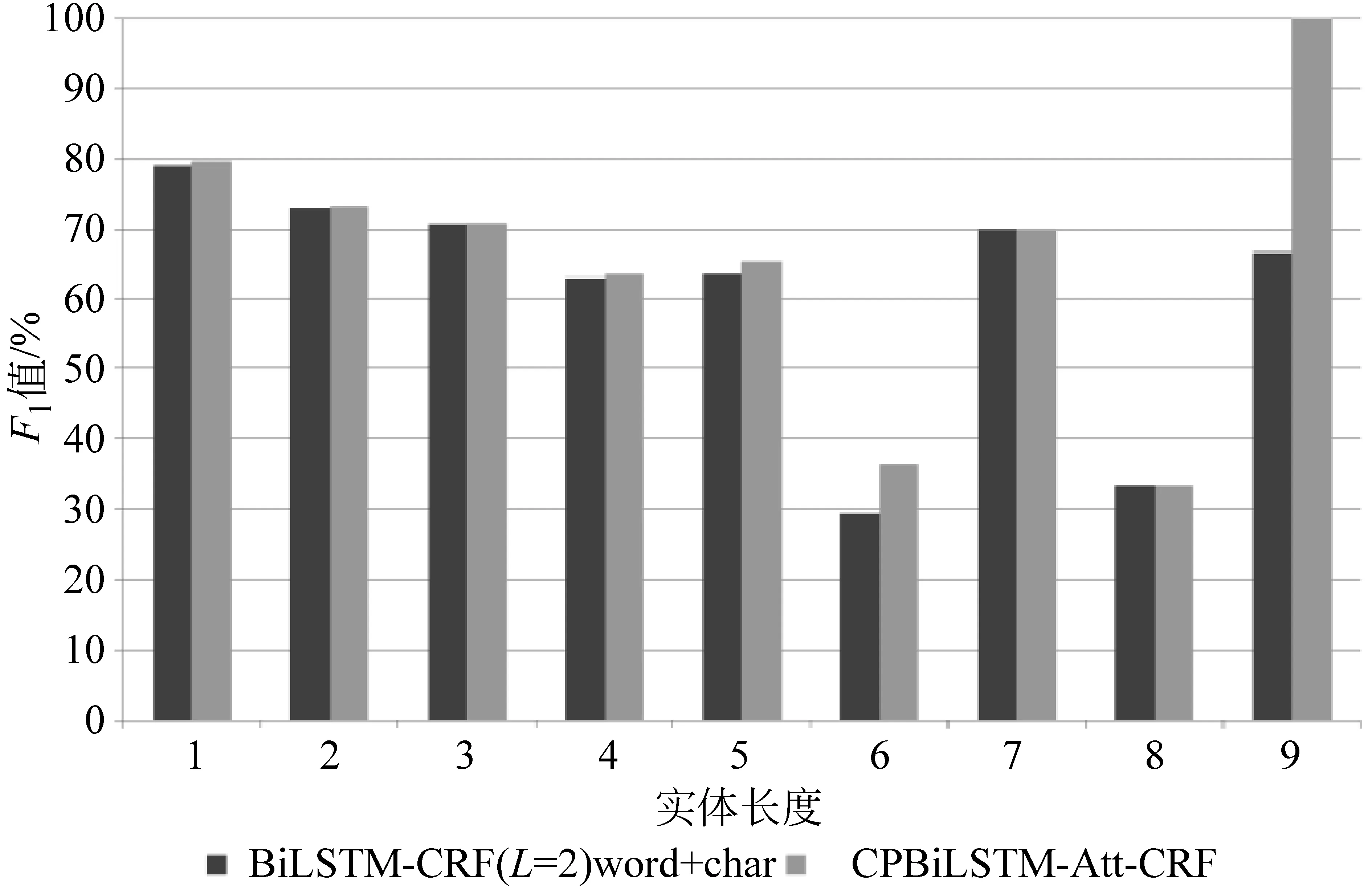
图5 OntoNotes 5.0 Chinese中不同长度实体下的模型性能对比图
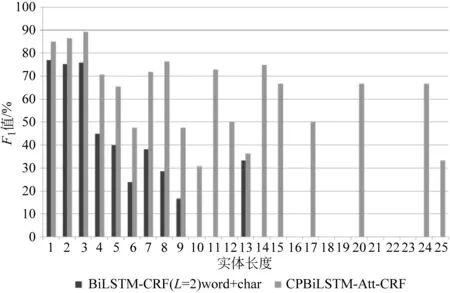
图6 SemEval-2010 Task 1 Spanish中不同长度实体下的模型性能对比图
3.6.3 与现有其他方法的对比
表8给出了在三个数据集上与其他文献所提方法的实验结果对比。Li等提出通过改进一个附加了卷积神经网络的特殊双向递归神经网络,将文本的语言结构加入模型中[23]。与传统的序列标注不同,该模型首先通过识别文本块的语言成分来识别可能存在的实体,在OntoNotes 5.0 English数据集上达到了87.21%的F1值。Ghaddar等提出将词和实体类型嵌入到一个低维向量空间中,通过维基百科远程监督产生的标注数据来进行训练[24],在OntoNotes 5.0 English数据集上达到了87.95的F1值。Jie等提出一个DGLSTM-CRF模型来编码依存树结构[12],从而在模型中加入依存树的父节点信息来提高命名实体识别性能。使用与本文方法同样的词向量的情况下,在OntoNotes 5.0 English和OntoNotes 5.0 Chinese以及SemEval-2010 Task 1 Spanish上分别达到了88.52%、77.40%、83.78%的F1值。通过表8可以看出,本文提出的融合依存树中子节点和父节点信息的CPBiLSTM-Att-CRF模型能够获得较好的性能。
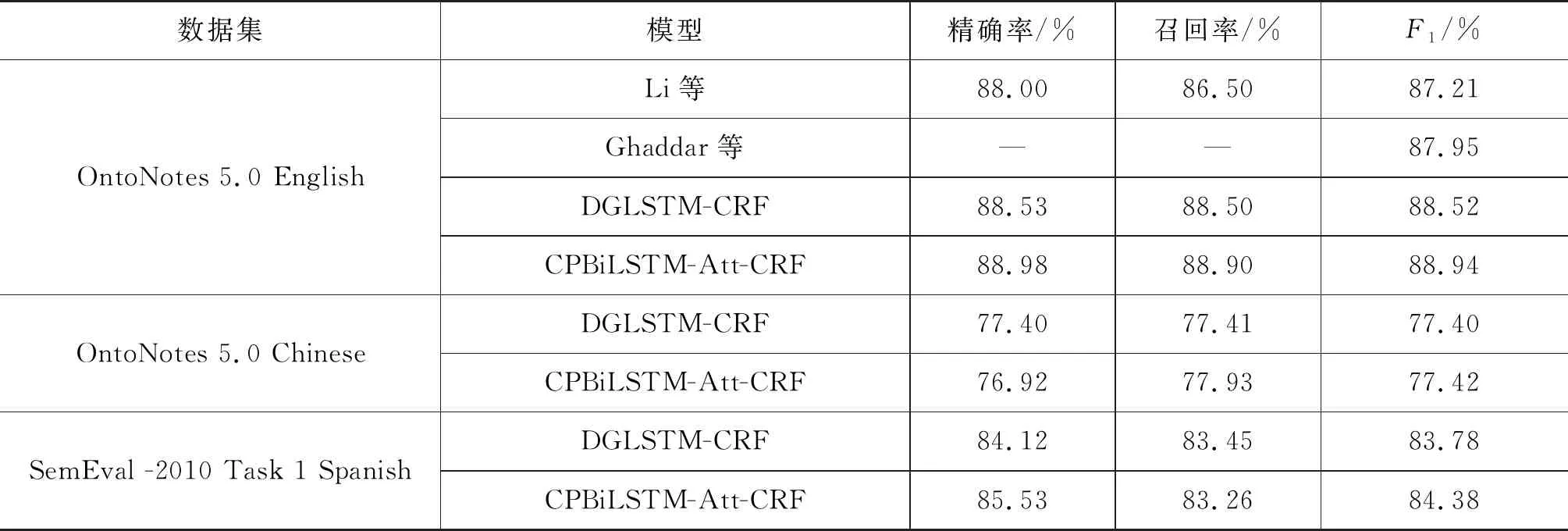
表8 与其他模型的对比实验结果
4 总结
本文提出一个在考虑文本上下文信息的同时,融合单词在依存树中子节点和父节点信息的端到端的命名实体识别模型CPBiLSTM-Att-CRF。该模型利用BiLSTM学习文本上下文信息,通过在输入数据中增加依存树信息以及改变BiLSTM的层间传播方式来利用单词在依存树中的子节点和父节点信息,提高了模型学习文本中潜在语义信息的能力。在OntoNotes 5.0 English、OntoNotes 5.0 Chinese以及SemEval-2010 Task 1 Spanish三个数据集上进行了验证,实验结果表明了该方法在命名实体识别任务中的有效性。
由于使用依存句法分析工具对数据集的依存关系进行预测存在一定的误差,因此未来的工作重点是如何在利用依存树结构进行命名实体识别过程中,降低预测错误的依存树信息对模型的负面影响。
