MU-GAN: Facial Attribute Editing Based on Multi-Attention Mechanism
2021-07-23KeZhangYukunSuXiwangGuoLiangQiandZhenbingZhao
Ke Zhang,, Yukun Su, Xiwang Guo,,Liang Qi,, and Zhenbing Zhao,
Abstract—Facial attribute editing has mainly two objectives:1) translating image from a source domain to a target one, and 2) only changing the facial regions related to a target attribute and preserving the attribute-excluding details. In this work, we propose a multi-attention U-Net-based generative adversarial network (MU-GAN). First, we replace a classic convolutional encoder-decoder with a symmetric U-Net-like structure in a generator, and then apply an additive attention mechanism to build attention-based U-Net connections for adaptively transferring encoder representations to complement a decoder with attribute-excluding detail and enhance attribute editing ability. Second, a self-attention (SA) mechanism is incorporated into convolutional layers for modeling long-range and multi-level dependencies across image regions. Experimental results indicate that our method is capable of balancing attribute editing ability and details preservation ability, and can decouple the correlation among attributes. It outperforms the state-of-the-art methods in terms of attribute manipulation accuracy and image quality. Our code is available at https://github.com/SuSir1996/MU-GAN.
I. INTRODUCTION
FACIAL attribute editing aims to replace some attributes of a source facial image with target attributes, such as changing a subject's hair color, gender or expression. Facial attribute editing plays an important role in human-robotics interaction and bionic agents, which has extensive applications in such fields as face reconstruction [1], privacypreserving [2] and intelligent photography [3].
The difficulty in facial attribute editing lies in accurately manipulating a given image from a source attribute domain to a target one while keeping attribute-independent details well preserved. Facial image needs to satisfy strict geometric constraints and correlations among facial attributes. Besides, it is difficult to achieve both attribute manipulation and detail retention ability. These make facial attribute editing a difficult task. Recently, significant breakthroughs have been made with the development of generative adversarial networks (GAN)[4]–[9]. Some previous studies [3], [10], [11] are based on an encoder-decoder architecture, which is adopted for extracting source image representation and reconstructing it under the guidance of target attribute vectors.
Although it is widely used in image-to-image translation, an encoder-decoder architecture has some limitations especially in high quality attribute editing. Facial attributes have different levels of abstraction and can be divided into local attributes such as beard and facial aging texture, global attributes such as bald and hair color, or more abstract attributes such as gender. Convolutional downsampling or spatial pooling can be used to obtain different levels of abstract attributes. A generator in [3] uses an encoder-decoder with residual layers [12], [13]. However, the introduction of residual bottleneck layers means that latent presentations are highly compressed and image details are thus lost during frequent down-up sampling. The innermost latent representation with minimal spatial size cannot contain all the useful details, which leads to blurry attribute-editing results and serious content-missing problems. The preservation of the details is the guarantee of image reality and quality. As a remedy, researchers [14] attempt to add skip-connections between an encoder and a decoder to supplement decoder representations. Encoder representations are employed as a supplement of decoder branches with detailed information.The use of direct skip-connections can transfer abundant complementary details to make images more realistic, but also transfer a lot of details, which are related to the original attributes, resulting in information redundancy and thereby weakening attribute manipulation ability. As shown in Fig. 1(see top of next page), the model with direct skip-connections performs bad in local attribute editing, e.g., beard, with limited attribute manipulation ability. In previous studies,detail retention and attribute manipulation are difficult to reconcile.

Fig. 1. Image examples generated by AttGAN [3], STGAN [15], and MUGAN.
The introduction of convolutional neural networks (CNNs)[16] have promoted the development of GANs [3], [10], [11].Researchers [17] believe that CNN-based GANs are good at editing local attributes and synthesizing images with few geometric constraints. Taking the landscape images as an example, a slight deformation of mountains and rivers does not affect the reality of an image. However, they have difficulty in editing images with geometric or structural patterns, such as facial attribute editing. As shown in Fig. 1,when dealing with a bald attribute, CNN-based GANs [3],[17] often simply paint the hair color of the original image with skin color to create the illusion of bald, ignoring the outline of a face and generating visually weird samples. One possible explanation is that CNN-based GAN relies on convolutional kernel to model global dependencies across long-range regions. Due to the limited receptive field of a convolution kernel, it is difficult to capture the dependencies among long-distance pixels in a picture.
It is also known that there are complex coupling relationships among facial attributes, e.g., gender and beard.In some facial attribute editing tasks, it is unavoidable to generate samples that do not exist in the real world, such as a woman with a beard in the third row of Fig. 1. Results generated by attribute generative adversarial network(AttGAN) [3] change hair length and produce serious artifacts. Although a sample generated by selective transfer generative adversarial network (STGAN) [15] is more like a woman, it still suffers from poor attribute decoupling, which makes an undesired change in beard. Thus, a desired model needs to have the ability to decouple attributes in order to meet the requirements of target labels.
To solve these problems, we construct a new generator with a novel encoder-decoder architecture and propose a multiattention U-Net-based GAN (MU-GAN) model. First, for detail preservation, a symmetric U-Net architecture [14] is employed to replace the original asymmetric one to ensure that the abstract semantics of latent representations at both sides of an encoder-decoder are in the same level, and avoid the information loss caused by sharp decrease in channel count numbers of the last decoder layer. Second, an additive attention mechanism is introduced to U-Net skip-connections,so that attribute-excluding representations are selectively transferred under the guidance of an attention mask, which is complementary to decoder representations and helps us balance detail preservation and attribute manipulation abilities. Third, self-attention (SA) layers are introduced to an encoder-decoder as a supplement to the convolutional layers.A self-attention mechanism helps us model long-range dependencies among image regions. It can effectively capture multi-level presentations and help GAN enforce complicated geometric constraints on generated images. In addition, the use of a multi-attention mechanism makes the model more powerful in attribute decoupling.
Our method is capable of generating facial images with better perception reality, attribute manipulation accuracy, and geometric rationality, compared with the state-of-the-art approaches. Moreover, the new generator architecture can balance attribute manipulation and detail preservation abilities. As shown in Fig. 1, our model performs well in attribute editing tasks at different semantic levels with strong attribute decoupling capability. In summary, this work makes the following contributions:
1) It constructs a symmetric U-Net-like architecture generator based on an additive attention mechanism, which effectively enhances our method's detail preservation and attribute manipulation abilities.
2) It takes a self-attention mechanism into the existing encoder-decoder architecture thus effectively enforcing geometric constraints on generated results.
3) It introduces a multi-attention mechanism to help attribute decoupling, i.e., it only changes the attributes that need to be changed. Qualitative and quantitative results show that MU-GAN outperforms the state-of-the-art methods in facial attribute editing.
The rest of the paper is organized as follows. Section II briefly reviews related work for generative model, image-toimage translation and facial attribute editing. The proposed method is illustrated in Section III. Experimental results and analysis are presented in Section IV. Ablation study is described in Section V, leading to conclusions in Section VI.
II. RELATED WORK
A. Generative Model
A generation model is devoted to learning real sample distribution and have attracted upsurging attention in attribute editing. There are two main approaches for facial generation models: variational auto-encoder (VAE) [1] and GAN. The former's goal is to maximize variational lower bounds, while GAN aims to reach Nash equilibrium through a binary minimax game. Experimental results show that VAE’s training process is more stable, but the results are fuzzy. GAN has better generation quality and creativity than VAE, but lacks appropriate constraints. To address the above issues,wasserstein generative adversarial networks (WGANs) [18],[19] improve stability of the optimization process by replacing Jensen-Shannon/Kullback–Leibler divergence [20] with Earth-Mover distance to measure the distance between real and generated sample distribution, thus solving the problem of vanishing gradient. A conditional image generation task has also been actively studied. Several methods [21]–[33] use category information such as attribute labels to generate samples. GAN [34], [35] has exhibited a remarkable capability in various fields, and has been used in several applications such as image generation [18], [19], [34], [36],style translation [5], [6], [11], [37], [38], super-resolution,image reconstruction [1], [39], and facial attribute editing [3],[6]–[9], [15], [40]–[42].
B. Image-to-Image Translation
Image-to-image translation means manipulating a given image attribute from a source domain to a target one with other image contents untouched. Existing works [4], [10],[43]–[46] have made remarkable progress in image translation. For example, pix2pix [43] adopts conditional generative adversarial network (CGAN) [21] for multi-domain image-to-image translation tasks with paired images.However, paired image datasets are unavailable in most scenarios. To address this issue, researchers [4], [10], [28]propose unpaired image translation methods. unsupervised image-to-image translation networks (UNIT) [4] combine VAE [1] and coupled generative adversarial network(coGAN) [37] to build a GAN architecture, where two generators share the same weights to learn the joint distribution of images in cross domains. Cycle-consistent generative adversarial network (CycleGAN) [10] preserves the key representation between the input and generated images by minimizing cycle consistency loss. The idea of dual learning allows Disco generative adversarial network (DiscoGAN) [28]and CycleGAN [10] to learn reversible mapping among different domains in unpaired image-to-image translation.However, the aforementioned methods cannot perform image manipulation on multiple domains. Their inefficiency results from the fact that in order to learn all mappings amongkdomains,k×(k−1) generators have to be trained. Recent studies [5], [11], [38] focus on multi-domain conversion and propose some multi-domain image translation models such as augmented CycleGAN [38], star generative adversarial network (StarGAN) [11], and AttGAN [3].
C. Facial Attribute Editing
The objective of facial attribute editing is to generate a face with a target attribute while preserving the attribute-excluding facial detail. Facial attribute editing has been a hot topic in computer vision. Existing methods [6], [7] are designed for modeling an aging process. Face aging is mainly reflected by wrinkles. Since the subtle texture information is more salient and robust in a frequency-domain, a Wavelet-domain global and local consistent age generative adversarial network(WaveletGLCA-GAN) [6] uses wavelet transform to synthesize aging images. Several studies [8], [9], [47] are conducted to solve a facial expression synthesis problem. Other studies propose facial attribute editing methods. DNA generative adversarial network (DNA-GAN) [41] can be regarded as an extension of gene generative adversarial network(GeneGAN) [40], which swaps attribute-relevant latent representations between given image pairs to synthesize“hybrid” images, and can transform multiple attributes simultaneously. Fader network (FaderNet) [5] imposes adversarial constraints to enforce the independence of latent representations. Its decoder then takes latent representation extracted from an encoder and target attribute vector as the input to generate desired results. Invertible conditional generative adversarial network (IcGAN) [42] and FaderNet [5]impose the constraints of mutual independence of attributes on the latent space such that latent representations from different classes can be independent of attribute decoupling. On the contrary, experimental results [3] show that it is too strict to impose independent constraints on latent space. Then, AttGAN[3] applies attribute classification constraints to generated images to ensure attributes being translated correctly. The generator of AttGAN consists of five convolution and deconvolutional layers. Then, it applies one skip-connection between encoder and decoder to improve image quality. Note that AttGAN’s encoder-decoder is not a symmetrical structure,and sharp decrease in the number of channels in the last deconvolutional layer of its decoder results in detail loss.Limited by the receptive field of a convolution kernel, CNN layers cannot model long-range, multi-level dependencies across image regions, which makes it difficult to synthesize image classes with complex geometric or structural patterns.Previous work [14] adopts skip-connections to enhance detail retention at the cost of reducing attribute manipulation ability.Adding direct skip-connections cannot fundamentally balance the attribute manipulation and detail retention abilities.AttGAN and its variants face three problems: 1) Loss of image details; 2) Insufficient attribute manipulation ability; and 3)Poor enforcement of geometric constraints. STGAN [15], a variant of AttGAN, introduces gated recurrent unit (GRU) [48]to build selective transfer units to selectively transmit encoder representation. However, memory-based approaches, e.g.,GRU [48] and long short-term memory (LSTM) [35], [49]–[51]mainly focus on sequential processing rather than visual tasks,which is limited by memory capacity and low computational efficiency.
III. PROPOSED METHOD
Fig. 2 shows an overview of our method. In order to solve the problem of AttGAN and STGAN, we present MU-GAN for facial attribute editing. First, instead of using an ordinary encoder-decoder [3], we use a symmetric U-Net structure to build our generator and construct MU-GAN by replacing direct skip-connections with attention U-Net connections(AUCs). Second, we adopt self-attention layers as complement to convolution layers. Finally, a discriminator and objective function of MU-GAN are provided.
A. Generator
1) Attention U-Net Connection:Fig. 3 shows the architecture of the proposed generator and AUCs. For detail retention and blurry image problems, we replace the original asymmetric CNN-based encoder-decoder with a symmetrical Attention U-Net architecture. Besides, instead of directly connecting an encoder to a decoder via skip-connections, we present AUCs to selectively transfer attribute-irrelevant representations from an encoder, and then, AUCs concatenate encoder representation with decoder ones to improve image quality and detail preservation. With an attention mechanism,AUCs are capable of filtering out representations related to original attributes while preserving attribute-irrelevant details.It can promote the image fidelity without weakening attribute manipulation ability. By using an attention mechanism, AUCs solve the problem of information redundancy caused by direct skip-connections.
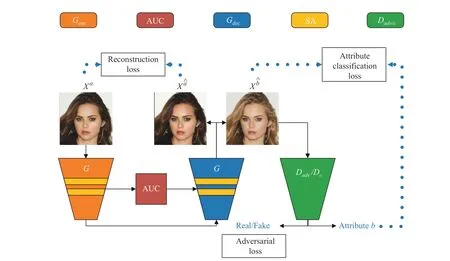
Fig. 2. The architecture of MU-GAN. SA denotes a self-attention mechanism. MU-GAN consists of a generator G and a discriminator D . D consists of two sub-networks, i.e., real/fake adversarial discriminator Dadv and attribute classifier Dc, which share the weights of the same convolutional layers. AUCs bridge an encoder Genc and a decoder Gdec to selectively transform encoder presentation, making it complementary to decoder presentation.
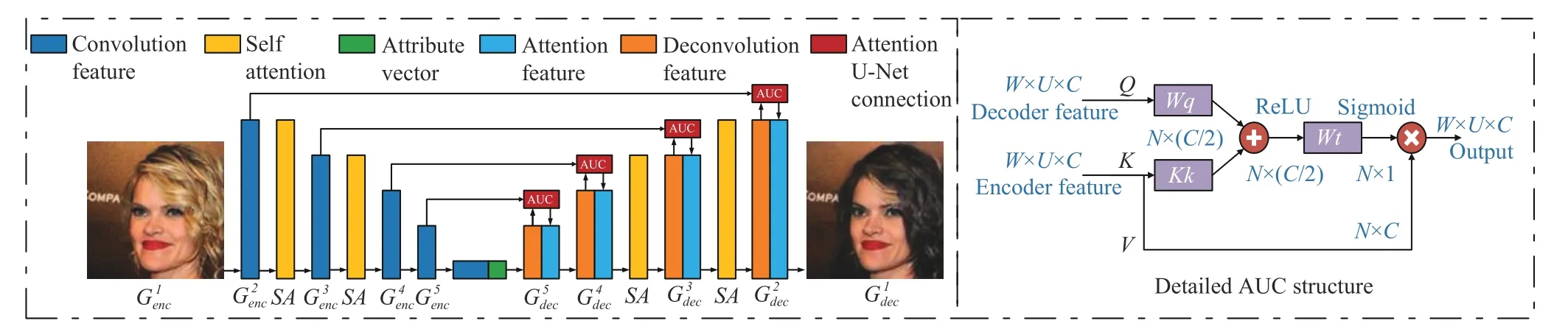
Fig. 3. The architecture of the proposed generator. AUCs bridge the two ends of an encoder-decoder, and calculate attention coefficient α between encoderdecoder representations of the same size. Under the guidance of α, it selectively transfers encoder representation as supplementary information of a decoder.Green block represents target vectors used to guide attribute editing. Besides, we follow SAGAN and put self-attention layers behind convolutional layers with feature map sizes of 64 and 32, respectively.



AUCs progressively suppress representation responses in source-attribute-related regions, and retain image details that are independent of the attributes. Representations transferred by AUCs are used as supplementary to decoder representations to compensate for the irreversible information loss caused by convolution downsampling, and enrich the details of a concerned image.
More importantly, as shown in Fig. 3, AUCs helpGaggregate information from multiple image scales, which increases the image fidelity and achieves better performance,without weakening attribute manipulation ability.
Note that our method adopts a symmetrical encoder-decoder to settle the issue of highly-compressed representation and loss of details caused by the sharp decrease in the number of channels. In addition, the abstract-level of representations at both ends of a symmetric encoder-decoder are similar, which are highly correlated with each other and contain significant reference values for attribute editing.
2) Self-Attention:Most GAN-based models for facial attribute editing are built with convolutional layers. Limited by the receptive field of a convolution kernel, the convolutional layer can only process information from adjacent pixels. Therefore, many CNN-based GAN models share similar problems, i.e., their results poorly meet global geometric constraints, and the networks are not competent for an image manipulation task with complex composition and strict geometric constraints.
For example, the task of facial attribute editing requires rigorous arrangement of facial features, and a tiny unreasonable-deformation can cause salient visual irrationality. As shown in the 2nd row of Fig. 1, the edited results fail to meet appropriate structural and geometric constraints. Thus, we utilize a self-attention mechanism [17],[53] as a supplement to convolutional layers inG, to efficiently model dependency across long-range separated spatial regions. The details of a self-attention mechanism are shown in Fig. 4.
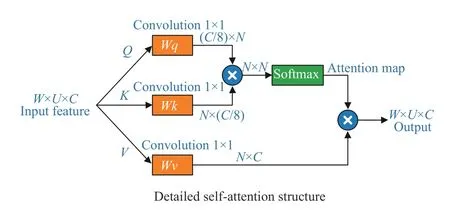
Fig. 4. Structure of a self-attention mechanism, where ⊗ represents matrix multiplication. After the features pass through Wq, Wk and Wv, their feature size are reshaped. Note that N=W×H.


B. Discriminator

C. Loss Functions


Next, we cover the adversarial, attribute classification and reconstruction losses.
1) Adversarial Loss:In order to make the distribution of generated images close to the distribution of real images, we introduce adversarial learning in the proposed method, thereby improving the visual reality of the generated image. WGAN uses Earth-Mover distance as a metric to measure the distance between two probability distributions, which can make the training process more stable and avoid mode collapse from happening. Following WGAN, we formulate adversarial loss betweenGandDadvas follows:


IV. EXPERIMENTS
A. Implementation Details
To evaluate the proposed method, we compare MU-GAN with AttGAN [3] and STGAN [15] and conduct extensive experiments on the CelebA dataset. The models involved in the experiment are trained on a workstation equipped with an Intel (R) Xeon (R) CPU E5-2620 v4 @ 2.10GHz and NVIDIA GTX1080ti GPU. All the experiments are conducted in the Pytorch 0.4 environment, with Cuda 8.0.44 and cuDNN6.0.20. The baseline model is trained under original experimental setting. There are 100 epochs in the training phase and models are trained by Adam optimizer ( β1= 0.5,β2= 0.999), and the initial learning rate is 0.002, which drops to 1/10 of itself for every 33 epochs. We use 5 discriminator update steps per generator update during training. The weights of the objective function are set as λ1= 3, λ2= 10, and λ3=100.178×218are center-cropped and resized to 128×128.According to the official division, CelebA is divided into a training set, a validation set, and a test set. The training and validation sets are used to train our method, while the test set is used in the evaluation phase.
CelebA is a large-scale facial attributes dataset including 10 177 celebrities and 202 599 facial images, each of which have 40 binary attribute labels. In order to compare with the previous work [3], [15], the same data preprocessing method is adopted. Thirteen attributes with intense visual impact are selected, including Bald, Bangs, Black hair, Blond hair,Brown hair, Bushy eyebrows, Eyeglasses, Male, Mouth slightly open, Mustache, No beard, Pale skin and Young.These attributes cover most distinctive facial attributes,containing practical information about human-computer interaction, and are also widely used in relevant work [3],[15]. In this experiment, CelebA source images with a size of
B. Qualitative Results

Fig. 5. Comparisons with AttGAN [3] and STGAN [15] on editing specified attributes.
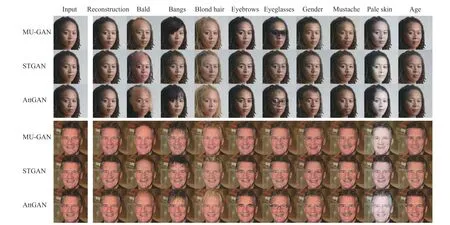
Fig. 6. Facial attribute editing results of AttGAN [3], STGAN [15] and MU-GAN. Please zoom in for better observation.
The qualitative results are shown in Figs. 5–6. Some samples generated by AttGAN and STGAN suffer from lowquality problems, i.e., artifacts and blurry to some extent,while the results of our method are more natural and realistic.MU-GAN aims to change only the facial attributes that need to be changed. The performance of detail preservation ability can be evaluated in two aspects. One is the preservation of details in the visual spatial regions, which is mainly reflected by whether the model can distinguish the attributerelevant/irrelevant regions. The other one is the ability to disentangle attributes in abstract semantics. As we know,some attributes are highly correlated with other attributes,which may lead to undesired changes in other attributes.
First of all, from Fig. 7(a), our method outperforms other models. Samples generated by MU-GAN have better realism and fidelity of details. However, the results of its competing methods appear to be over-smooth and blurry with artifacts to some extent. One possible reason is that our model adopts a symmetrical U-Net-like architecture to make encoder representations complementary to decoder ones, without reducing its attribute editing ability. Besides, in a symmetric encoder-decoder, the corresponding encoder representation and decoder one are highly correlated.
Secondly, from Fig. 7(b), when editing global attributes,e.g., Black hair, Blond hair, Brown hair, and Pale skin, our method better enforces geometric constraints and is capable of distinguishing spatial regions related/unrelated to attributes,while its peers have difficulty in global attribute manipulation.For example, when the background is close to hair color, its peers often incorrectly recognize the background as hair,resulting in severe artifacts. In the opposite side, benefited from self-attention layers, our method can better distinguish the foreground and background, and accurately edits the hair color. In the same way, when dealing with a pale skin attribute, our method can better segment the faces from the background, rather than simply whitening the center region of an image, as done by its peers.

Fig. 7. Attribute editing results at different abstract-level, compared with the competition methods.
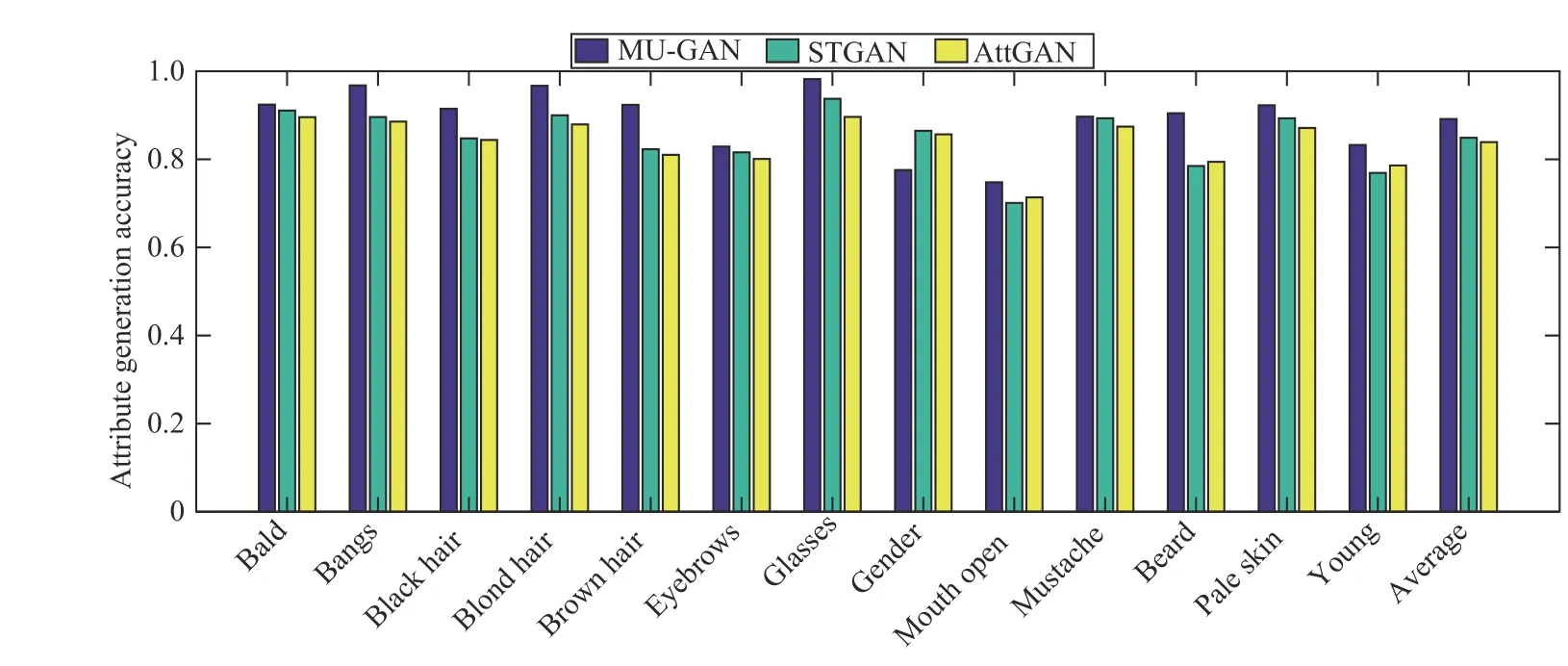
Fig. 8. Attribute generation accuracy of AttGAN [3], STGAN [15] and MU-GAN.
Thirdly, our model can effectively deal with the interference among attributes. Taking gender as an example, because of the sampling bias, the Male group generally have short-hair,while the Female group usually have long hair with neither beards nor mustaches. Hair length, beard and mustache are attributes that are highly related to gender. As a result, these attributes often change with the editing of gender, which can be observed in generated results in the 3rd and 4th rows of Fig. 7(c). The competition models sometimes drop beard attribute, when the image changes from male to female. These changes are very interesting and the generated samples are more realistic in attribute gender, but they can cause serious artifacts like fake long hair or make unexpected changes in other attributes. In our method, attributes are well decorrelated to avoid the interference among attributes and undesired changes in generated images.
C. Quantitative Evaluation
In a facial attribute editing task, the quality of generated images is mainly reflected in whether they are realistic or whether the source images are accurately manipulated from an original domain to a target one. We take attribute manipulation accuracy and reconstructed image quality for quantitative evaluation. In order to evaluate the former, a multi-class classification method is employed to classify the generated images. First, a specific ResNet variant [12] is trained on the training set of CelebA, attaining an accuracy of 94.79%for 13 attributes on the test set. The classification network consists of three residual groups ( 3, 4, 6) and a fully connected layer with an output dimension of 13. The attribute generation accuracy is shown in Fig. 8. The classification results show that our method outperforms the others in the accuracy of attribute editing. As shown in Table I, the average attribute generation accuracy of MU-GAN is 89.15%, which is a significant improvement over AttGAN’s 83.91% and STGAN’s 84.89%. Besides the gender attribute, the classification accuracies of other attributes are better than those of its peers, especially for the beard, hair colors and eyeglass attributes. As mentioned earlier, gender correlates with other attributes, and MU-GAN is good at attribute decoupling, which is an effective way to prevent unexpected changes when editing target attributes. For example, when an image changes from male to female, MU-GAN faithfully retains the original beard and other correlated attributes,which is easily misjudged by the classification network in quantitative experiments. As we can see from Fig. 7(c),competing methods are more likely to make visually significant but unexpected changes like modifying hair length with serious artifact and other gender-related attributes while samples generated by MU-GAN change only the attributes that need to be changed. The above results also illustrate that MU-GAN not only has better attribute manipulation accuracy,but also has good attribute decoupling capabilities.
The evaluation indexes for reconstruction results are the peak signal to noise ratio and structural similarity(PSNR/SSIM). PSNR is the most common and widely-used evaluation index for images, but it is based on the errorbetween corresponding pixel points, and it dose not take human visual characteristics into account. As a full-reference image quality evaluation index, SSIM measures image similarity in brightness, contrast, and structure. SSIM is better than PSNR in image denoising and similarity evaluation. In order to study the reconstruction ability, reconstruction imagexaˆis generated from source imagexa, conditioned on a source attribute vector. Table II lists the PSNR/SSIM results of reconstruction images for six methods. The quantitative results are consistent with the previous qualitative results [15].From Table II, benefited from AUCs, a symmetrical architecture, and a self-attention mechanism, our method can retain more image information and achieve much better reconstruction results than its five peers. AUCs are capable of generating high quality reconstruction results, which are more natural and realistic while retaining more details.

TABLE I AVERAGE ATTRIBUTE MANIPULATION ACCURACY OF THE COMPARISON METHODS ON 13 FACIAL ATTRIBUTES
V. ABLATION STUDY
In this section, we evaluate the effect of the two main components, i.e., symmetric attention U-Net and self-attention mechanism on MU-GAN's performance. To analyze each’s effect, we try different generator structures. Several MU-GAN variants are constructed, which are trained and tested in CelebA, under the same experimental settings. Ablation experiments between variants can also help to find out the contributions of AUCs, symmetric U-Net architecture, and self-attention mechanism.
We consider four variants: 1)M0: original MU-GAN.2)M1:M0after removing a self-attention mechanism but retaining a symmetrical attention U-Net architecture. 3)M2:M0after removing AUCs, but retaining a symmetric encoderdecoder and a self-attention mechanism. 4)M3:M0with an asymmetric encoder-decoder architecture.
A. Effect of Symmetrical Attention U-Net Structure
First, a comparison of the editing result between symmetric and asymmetric encoder-decoder architectures is shown in Fig. 9. Compared withM0, the generated results ofM3, to some extent, are blurrier and the image details are oversmooth. In addition, qualitative experimental results in Fig. 9 illustrates that the MU-GAN variants with a symmetric encoder-decoder achieve better perceptual results on reconstructed images. One possible reason is that the symmetrical architecture avoids latent representation being highly-compressed, caused by the sharp decrease in the number of decoder channels, which can effectively retain the details and make edited results more natural and realistic.
Second, compared with models without AUCs (e.g.,M2,AttGAN, and STGAN),M0has better attribute manipulation accuracy and higher PSNR/SSIM from Table III and Fig. 10.The additive attention mechanism selectively transfers attribute-irrelevant presentation from an encoder, filtering out the original attribute information to resolve the problems of information redundancy. Therefore, AUCs fuse multi-level features and enrich image details, which guarantees the attribute manipulation ability of AUC-based variants and only changes the attributes that need to be changed.
In addition, we have established many variants, which are based on symmetrical encoder-decoder model without selfattention mechanism to explore the effect of the number ofAUCs on the results.AUCimeans adding AUCs to the firstilayers, andAUC4is completely equivalent toM1mentioned earlier. As can be seen from Table IV, the reconstruction quality and classification accuracy of the model are improved with the increase in the number of AUCs. When there are four AUCs in Generator,AUC4attains the best classification accuracy of 85.15% and PSNR/SSIM increases from 24.07/0.841to 28.14/0.918, which is a big breakthrough compared with the baseline. Therefore, we add AUCs to each layer of the generator.

TABLE II RECONSTRUCTION QUALITY ON FACIAL ATTRIBUTE EDITING TASKS

Fig. 9. Effect of different combinations of the three components.

TABLE III RECONSTRUCTION QUALITY AND AVERAGE CLASSIFICATION ACCURACY OF THE MU-GAN VARIANTS
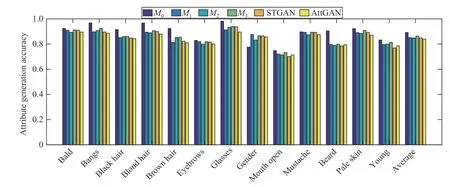
Fig. 10. Attribute generation accuracy of MU-GAN variants, AttGAN, and STGAN, which are conducted on CelebA.
AttGAN’s sparse encoder-decoder over-compresses image information, and loses a large number of details, which leads to low image fidelity. The introduction of skip-connections is one way to increase detail retention ability, but at the cost of severely weakening the attribute operation ability.Relevant/irrelevant information is indiscriminately injected into the decoder, resulting in information redundancy. With the help of the additive attention mechanism, AUCs can obtain the detailed information needed for image reconstruction. Similarly to STGAN, we are committed to selectively transferring useful representation from encoder to decoder. AUCs avoid information redundancy, and then achieve the goal of balancing the detail retention ability and attribute operation ability, simultaneously.
B. Effect of a Self-Attention Mechanism
As shown in Fig. 9, attribute edited results generated by variants with self-attention mechanism, e.g.,M0,M2, andM3,better enforce structural constraints, which can generate visual-reasonable results with rigorous geometry. Especially,our model performs well in global attribute editing such as bald and pale skin. Although the model with a self-attention mechanism can hardly obtain a significant improvement in the quantitative results, the generated images are more realistic in perception.
Benefited from a multi-attention mechanism,M0has strong attribute decoupling ability in abstract semantics. For example, in the task of gender attribute editing, the model with a multi-attention mechanism avoids unexpected changes.Attribute decoupling ability makes the gender attribute manipulation less significant compared with its peers, leading to quantitative classifier misjudgment.
To explore the effect of a self-attention mechanism, selfattention layers are added into different layers of the generator, which is based on symmetrical encoder-decoder model without AUCs. Since the effect of SA is mainly reflected in improving the quality of reconstructed images, so SA has little effect on the improvement of classification accuracy, only the reconstruction experiment has been done here. As shown in Table V, self-attention mechanism seems to be more effective on the high-level feature graph, i.e.,Feat32andFeat64, but has limited performance improvement in the low-level graph.Feat8,16’s performance is even lower than that ofFeat32. Theoretically, introducing self-attention mechanism into all layers of a generator is better. However, it will greatly increase the number of parameters of the model.Limited by hardware resources, we choose to add the selfattention layers on the third and fourth layers.
VI. CONCLUSIONS
The conclusion goes here. In this paper, we introduce a multi-attention mechanism, i.e., AUCs and self-attention mechanism into a symmetrical U-Net-like architecture, thus resulting in MU-GAN. By using AUCs, it can accurately edit desired facial attributes, which not only significantly improves attribute editing accuracy, but also enhances the detail retention ability. Furthermore, self-attention is introduced as a supplement to the convolutional layers and helps us generate results to better meet structural constraints. Experimental results show that our method balances attribute manipulation and detail retention, and has strong decoupling capabilities. It can generate high-quality facial attribute editing results andoutperforms the state-of-the-art approaches in terms of reconstruction quality and attribute generation accuracy. As future work, we intend to explore more appropriate attention mechanisms for AUCs to enhance the performance of MUGAN.

TABLE IV THE INFLUENCE OF AUCS ON RECONSTRUCTION QUALITY AND CLASSIFICATION ACCURACY. THERE ARE MU-GAN VARIANTS WITH DIFFERENT AMOUNTS OF AUCS

TABLE V COMPARISON OF MU-GAN VARIANTS, WHOSE SELF-ATTENTION LAYER IS PLACED IN DIFFERENT POSITIONS. Feati MEANS ADDING SELFATTENTION LAYER TO THE i×i REPRESENTATION MAPS
ACKNOWLEDGMENT
The authors gratefully acknowledge the support of NVIDIA Corporation with the donation of the GPU used for this research.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Distributed Resource Allocation via Accelerated Saddle Point Dynamics
- Fighting COVID-19 and Future Pandemics With the Internet of Things: Security and Privacy Perspectives
- Soft Robotics: Morphology and Morphology-inspired Motion Strategy
- Generating Adversarial Samples on Multivariate Time Series using Variational Autoencoders
- A Unified Optimization-Based Framework to Adjust Consensus Convergence Rate and Optimize the Network Topology in Uncertain Multi-Agent Systems
- Vision Based Hand Gesture Recognition Using 3D Shape Context