Vision Based Hand Gesture Recognition Using 3D Shape Context
2021-07-23ChenZhuJianyuYangZhanpengShaoandChunpingLiu
Chen Zhu, Jianyu Yang,, Zhanpeng Shao,, and Chunping Liu
Abstract—Hand gesture recognition is a popular topic in computer vision and makes human-computer interaction more flexible and convenient. The representation of hand gestures is critical for recognition. In this paper, we propose a new method to measure the similarity between hand gestures and exploit it for hand gesture recognition. The depth maps of hand gestures captured via the Kinect sensors are used in our method, where the 3D hand shapes can be segmented from the cluttered backgrounds. To extract the pattern of salient 3D shape features,we propose a new descriptor–3D Shape Context, for 3D hand gesture representation. The 3D Shape Context information of each 3D point is obtained in multiple scales because both local shape context and global shape distribution are necessary for recognition. The description of all the 3D points constructs the hand gesture representation, and hand gesture recognition is explored via dynamic time warping algorithm. Extensive experiments are conducted on multiple benchmark datasets. The experimental results verify that the proposed method is robust to noise, articulated variations, and rigid transformations. Our method outperforms state-of-the-art methods in the comparisons of accuracy and efficiency.
I. INTRODUCTION
H AND gesture recognition is a popular topic in computer vision and plays an important role in humancomputer interaction (HCI) [1]–[4]. Its research and development affect the communication of intelligent devices and humans, which makes HCI more flexible. Nowadays,hand gesture recognition has been widely applied to all aspects of human life and industry [5], e.g., virtual reality,sign language recognition, visual tracking, video indexing,and automated surveillance.
The development of hand gesture recognition is based on three main types of hand gestures: static 2D hand gestures,dynamic 2D hand gestures, and 3D hand gestures. The static 2D hand gesture [6] is the simplest form of hand gesture data for recognition. The 2D shape information is acquired to identify static hand gestures, such as a fist or fingers open.This technique can only recognize static gestures without perceiving continuous changes of hand gesture. The dynamic 2D hand gesture recognition methods [7], [8] are more complex in tracking the movements of hands [9], [10].Researchers usually extract different types of features of the hand trajectories and use various combinations of them to represent the dynamic 2D hand gesture. Features extracted from dynamic gestures include richer information than those extracted from static gestures. With the appearance of depth cameras, e.g., the Kinect sensor [11], 3D hand gesture recognition [12]–[14] has been developed rapidly. The output of a depth camera is a depth map, which is sometimes mentioned as a depth image or depth frame according to context. A depth map contains depth information corresponding to the distances of all the pixels from the surface of the object to the sensors. Compared with a conventional color image, a depth map provides several advantages. First, depth maps generated by a structured light or time-of-flight depth camera are insensitive to changes in lighting conditions. Second, the 3D information collection of the object is hardly affected by the cluttered background.Third, depth maps provide 3D structure and shape information, which makes several problems easier to deal with, such as segmentation and detection. Hand shapes can be detected and segmented robustly from the RGB-D images captured by the Kinect sensor. Therefore, this new type of data enables a different area of information which has rarely been touched by traditional hand gesture recognition research on color or gray scale videos.
The effectiveness of hand gesture recognition is greatly improved by 3D hand gesture recognition methods. In recent years, there has been a vast set of literatures which report promising results [15]–[21]. However, many methods[15]–[17] cannot recognize hand gestures robustly with severe articulated variations and rigid transformations. Renet al.[22]propose a part-based method to solve these problems, but they cannot capture the global features of hand shape. So the description of hand gestures is defective with missing global shape information. Furthermore, some of the 3D hand gesture recognition methods, e.g., the methods based on hand motion trajectories [23], [24], usually have high computational cost.These methods are not so efficient for real-time applications.Thus, effective and efficient hand gesture recognition is still a challenging task.

Fig. 1. Overview of the proposed method. The depth maps are captured via the Kinect sensor and then the 3D hand shapes can be segmented from the cluttered backgrounds. The 3D-SC information of each 3D point is extracted in multiple scales and is summarized in respective histogram. A hand gesture is thus represented by the combination of histograms of all the contour points. Finally, the improved DTW algorithm is used for hand gesture recognition.
Additionally, based on the way of feature extraction, hand gesture recognition methods can broadly be divided into two categories: global-feature-based methods [25]–[27] and localfeature-based methods [28]–[31]. Global methods process hand gesture as a whole in recognition. Global features are defined to effectively and concisely describe the entire 3D hand gesture. However, hand shape details are missed. On the other hand, local-feature-based methods extract only local 3D information around a specific selected key point. The local methods are generally better in handling occlusion compared to global methods. However, they cannot capture the global information of hand gestures. Therefore, in order to utilize both the local and global 3D information of hand gestures, the features should be extracted in multiple scales. This motivates us to design a discriminative descriptor which considers both the local and global 3D information of hand gestures.Moreover, a hand gesture recognition method with both high accuracy and efficiency is required.
In this paper, we propose a new hand gesture recognition method, 3D shape context (3D-SC), which sufficiently utilizes both the local and global 3D information of hand gestures.The proposed method is inspired from the shape context (SC)method [32], while our method extracts rich and discriminative features based on the 3D structure and context of hand shape in multiple scales, which are robust to noise and articulated variations, and invariant to rigid transformations.The overview of the proposed method is illustrated in Fig. 1.Firstly, the depth map is captured via the Kinect sensor and the hand gesture is segmented from the cluttered background.Then the edge detecting algorithm is used to achieve the hand contour. After that, we use a set of vectors originating from one contour point to all the rest to express the spatial structure of the entire shape relative to the reference point. The 3D-SC information of each 3D point is extracted in multiple scales and is summarized in the respective histogram. The description of all the 3D points makes up the hand gesture representation. Finally, we improve the dynamic time warping(DTW) algorithm [33] with the Chi-square Coefficient method [34] to measure the similarity between the 3D-SC representations of hand gestures for recognition.
Our contributions in this paper can be summarized in three aspects as follows:
1) A new method for 3D hand gesture representation and recognition is proposed. Both the local and global 3D shape information in multiple scales are sufficiently utilized in the feature extraction and representation of our method. The 3D shape context information of hand gestures is extracted at salient feature points to obtain a discriminative pattern of hand shape. This method is invariant to geometric transformations and nonlinear deformations, and is robust to noise and cluttered background.
2) We improve the DTW algorithm with the Chi-square Coefficient method, where the Euclidean distance is replaced when calculating the similarity between hand gestures.
3) Our method achieves state-of-the-art performances on five benchmark hand gesture datasets, including large-scale hand gesture datasets. The efficiency of our method outperforms recent proposed methods as well, which is fast enough for real-time applications.
The invariance and robustness of the proposed descriptor is evaluated through extensive experiments. The proposed method is invariant to geometric transformations and nonlinear deformations, especially to articulated variations.The experimental results validate the invariance of our method to these variations. Our method is also verified to be capable of capturing the common features for hand gestures with large intra-class variations. We also validate the robustness of our method to cluttered background and noise. The effectiveness of our method is evaluated with experiments on five benchmark RGB-D hand gesture datasets: the NTU Hand Digit dataset [22], Kinect Leap dataset [35], Senz3d dataset[36], ASL finger spelling (ASL-FS) dataset [37], and ChaLearn LAP IsoGD dataset [38]. All the data are captured by depth cameras and the last two datasets are large-scale.Only depth maps are used in our method, without the RGB images. Experimental results show that the proposed method outperforms state-of-the-art methods and is efficient enough for real-time applications.
The remainder of this paper is organized as follows. We begin by reviewing the relevant works in the next section.Section III describes the hand gesture representation of the proposed method in detail and shows how it can be used to obtain rich 3D information of hand gestures. Hand gesture recognition is introduced in Section IV. Section V gives the experimental evaluation of the invariance and robustness of our method as well as the performances of hand gesture recognition on five benchmark datasets. This paper is concluded in Section VI.
II. RELATED WORK
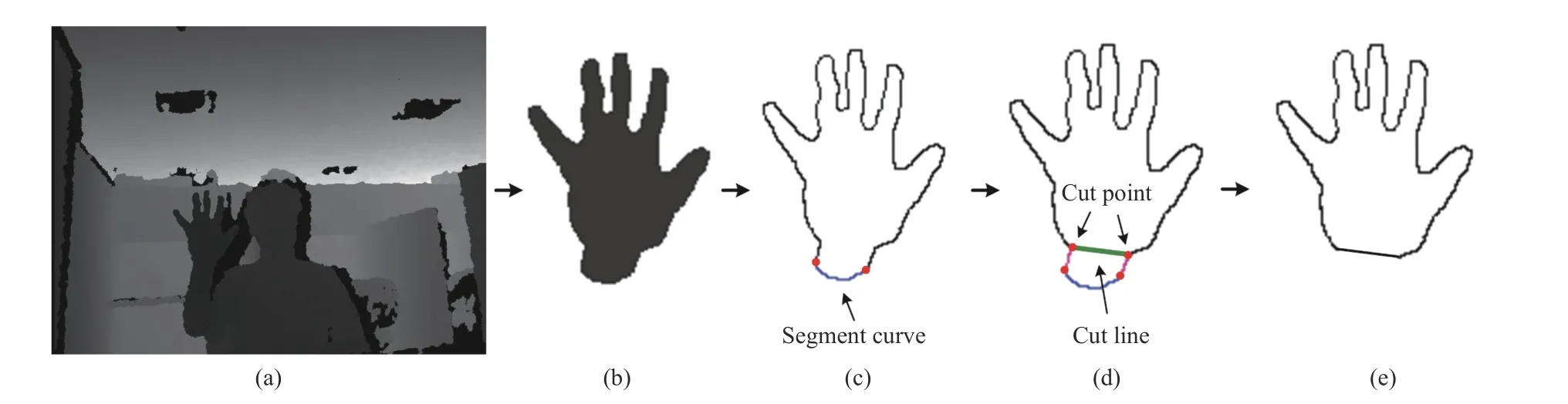
Fig. 2. An illustration of hand shape segmentation.
According to a survey of hand gesture recognition approaches [39], [40], these approaches can be broadly divided into two classes, i.e., approaches for static hand gestures and dynamic hand gestures. In the static hand gesture recognition, only the “state” of hand gestures can be recognized. The “continuous change” of hand gestures cannot be perceived. Keskinet al. [41] use pixel-level features to describe the hand gesture with high computational cost. In[42], a 3D facets histogram is proposed to describe the shape information of the 3D hand gesture. Also, high-level features can be extracted from the contour of the hand gesture. Yanget al. [43] propose a finger emphasized multi-scale descriptor which incorporates three types of parameters in multiple scales to fully utilize hand shape features. Generally speaking,by analyzing the hand gesture images and comparing them with the preset image patterns, the meanings of hand gestures are understood. These approaches are sensitive to illumination and background interference.
In the dynamic hand gesture recognition, the temporal information of the motion of hand gestures can be captured.When a hand gesture starts and when it ends are recorded.This task is extended to recognize more complex and meaningful hand gestures. Also, we can realize the visual tracking and online understanding of hand gestures based on the approaches for dynamic hand gestures. In [44], a novel feature fusion approach fuses 3D dynamic features by learning a shared hidden space for hand gesture recognition. Elmezainet al. [23] realize a hidden Markov model (HMM)-based continuous gesture recognition system for real-time dynamic hand gesture recognition. Additionally, an effective representation of 3D motion trajectory is important for capturing and recognizing complex motion patterns. In [24], a view invariant hierarchical parsing method for free form 3D motion trajectory representation is proposed. The proposed parsing approach well represents long motion trajectories and it can also support online gesture recognition.
In the past few years, many traditional learning algorithms[45], [46] have been applied for hand gesture classification.Panget al. [47] extracted light flow and movement features and used the traditional HMM to recognize hand gestures.Keskinet al. [48] use random decision forests (RDF) to train the hand model and design an application based on a support vector machine (SVM) for American digital hand gesture recognition. In [49], a set of pre-processing methods is discussed and a DTW-based method is proposed. It can emphasize joints which are more important for gesture recognition by giving them different weights. These machine learning techniques are always complicated due to the essential large-scale training data for feature extraction and classifier training. Thus, Keskinet al.[50] propose a clustering technique which can significantly reduce the complexity of the optimal model and improve the recognition accuracy at the same time.
III. HAND GESTURE REPRESENTATION
A. Hand Shape Segmentation

To extract shape features and weed out redundant contour points, the ADCE method [52] is employed for contour evolution. The evolution results of a sample hand shape are shown in Fig. 3 with the numbers of remained contour points.We can see that the evolved shape preserves the salient shape features of the original shape with less redundant points.Additionally, the computational cost of subsequent operation is largely reduced by the contour evolution.
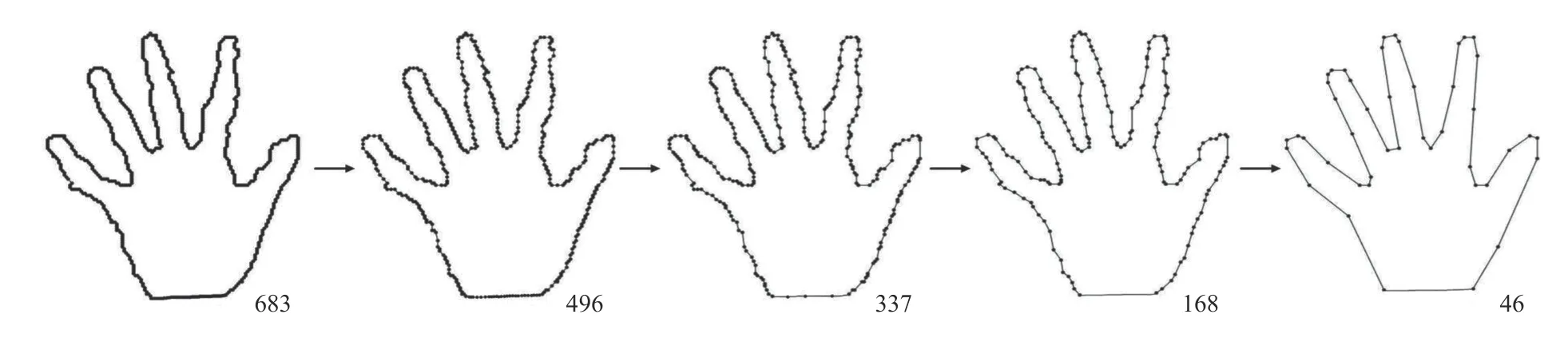
Fig. 3. The ADCE evolution process of the hand shapes with the numbers of remained contour points.
B. 3D Shape Context Descriptor

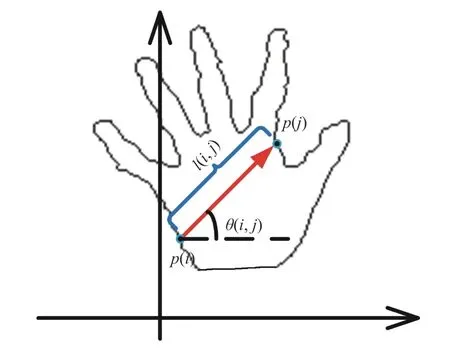
Fig. 4. An illustration of the direction and length of a vector.
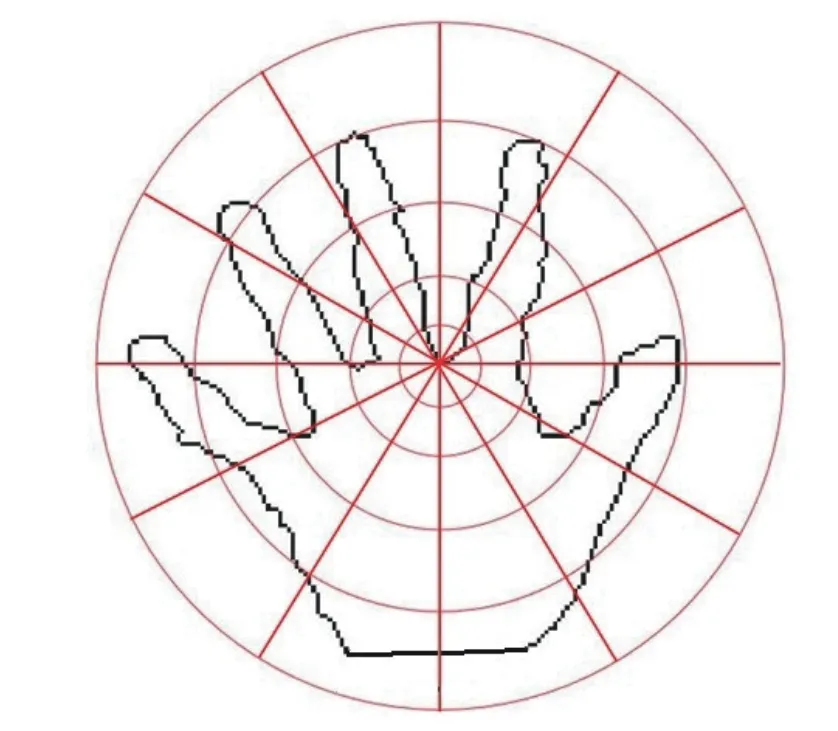
Fig. 5. An illustration of the mesh division with k1=12 and k2=5.
After the hand shape segmentation and contour evolution,we obtain the contour of the hand shape with 3D information which is represented as a sequenceScorresponding bent-block according to their directions and lengths. We divide the vectors based on the logarithms of lengths. Thus, the area of each bent-block far from the reference point is larger than that based on lengths, which avoids the weakening of the role of these bent-blocks. The area of each bent-block which is near the reference point is smaller, which avoids the effect of these bent-blocks being too large. The logarithm of the maximum length is used as the maximum radius for length division so that all the vectors can be assigned to the mesh. Additionally, both local 3D shape context and global 3D shape distribution information in multiple scales are sufficiently utilized in the 3D-SC descriptor which increases the reliability and discrimination of the hand gesture representation.
The parameter values ofk1andk2are set to 12 and 5 respectively based on the following theoretical analyses.Obviously, a bigger value ofKindicates that the division of the 3D hand shape is more detailed and the descriptor is more discriminative. However, the computational cost will be higher with meaningless calculations. Thus, to improve the efficiency of our method, we choose the smallest parameter values which can sufficiently represent hand gestures. The criterion is that different fingers should not be included in the same bent-block. Take the hand gesture in Fig. 5 as an example, if the reference point is on the end of the thumb or little finger, i.e., two sides of the hand,k2should be set to at least 5 to fit the criterion. On the other hand, the maximum angle between the thumb and little finger is generally smaller than 150◦. Each finger is distributed approximately in the range of 30◦. Thus,k1should be set to at least 12. As shown in Fig. 5 , the value ofKis 60 and different fingers do not appear in the same bent-block. In order to verify the above analyses,we conduct experiments with different parameter values and this parameter setting achieves the best performance.
The sum of relative depth values of all the contour points in each bent-block is calculated as a respective column value of the log-polar histogram. Take the log-polar histogram of the contour pointias an example, the value of its columnkis calculated as

whered(j) is the absolute depth value of contour pointj.Considering that the distances between hand gestures and the Kinect sensor are different, we calculate the sum of the relative depth values rather than the absolute depth values.The purpose of adding one in (8) is to put the contour points with minimum absolute value into the description of 3D hand shapes. This makes the description more comprehensive.
The 3D-SC information of each 3D point is summarized in log-polar histogram shown in Fig. 6. A deeper grid color indicates a larger value of the corresponding column. A hand gesture is finally represented by the combination of log-polar histograms of all the contour points.
IV. HAND GESTURE RECOGNITION
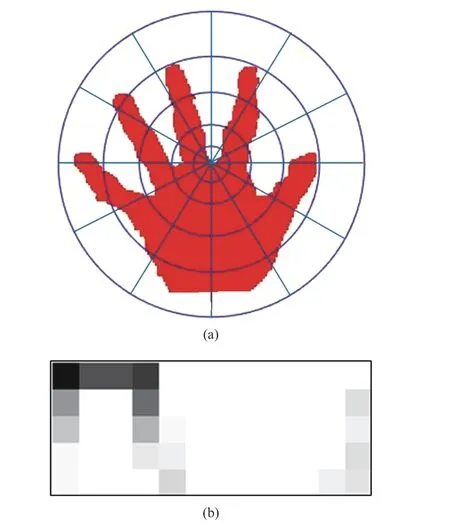
Fig. 6. The sum of relative depth values of all the contour points in each bent-block is calculated as respective column value of the log-polar histogram. (a) The 3D-SC information of a 3D point. (b) The corresponding log-polar histogram.
After the hand gesture representation, we improve the DTW algorithm [33] with the Chi-square Coefficient method [34] to measure the similarity between the 3D-SC representation of hand gestures for recognition. The original DTW algorithm uses the Euclidean distance to calculate the matching cost between two points. However, the correlation between components is not considered. In this work, the proposed 3D shape context descriptor is represented as histograms, and the Chi-square Coefficient is capable of capturing the correlations among histogram components, therefore, we choose the Chisquare Coefficient to measure the similarity between hand gestures for accuracy.
Given two contour point sequences of hand gestureAandB

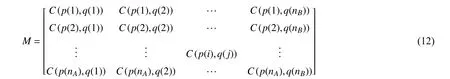

The training sample with the smallest value ofRin each class is selected as the hand gesture template of the respective class. Hand gestures can be finally recognized based on the DTW distances between testing samples and templates.
V. EXPERIMENT
In this section, we evaluate the capability of our method in four aspects: 1) demonstrate the invariant properties of the proposed 3D-SC descriptor for articulated deformation,rotation and scale variation; 2) evaluate the representative and discriminative power by hand gesture recognition experiments on five benchmark datasets, including the NTU Hand Digit dataset [22], Kinect Leap dataset [35], Senz3d dataset [36],ASL finger spelling (ASL-FS) dataset [37], and ChaLearn LAP IsoGD dataset [38]; 3) test the robustness to cluttered backgrounds and noise in recognition; 4) conduct a detailed comparison of efficiency. The experimental results show that our method outperforms state-of-the-art methods.
A. Invariant Properties of 3D-SC Descriptor
In this experiment, we evaluate the invariant properties of the 3D-SC descriptor to rotation, scale variation, and articulated deformation. We select two hand gestures from the same class in the NTU Hand Digit dataset [22] with salient intra-class variations including articulated deformation, and calculate their 3D-SC descriptors as shown in Fig. 7.
In the first column of Fig. 7, the first and the second rows show the original hand gestures with salient intra-class variations. With these two gestures, the angles between fingers are different which indicates large articulated deformation. The third and the fourth rows are the corresponding rotated gestures, the fifth and the sixth rows are scaled gestures, and finally the seventh and the eighth rows are gestures with both rotation and scale variations. The second and the third columns are, respectively, the log-polar histograms and line charts of the points in the same position,i.e., thumb fingertip. From the figures we can find significant correspondences and similarities among the log-polar histograms and line charts of different gestures. The strong correspondence of the line peaks among gestures in the plots indicates the invariance of our method to intra-class variation.These similarities show a reliable evaluation for recognition.In summary, our method is invariant to articulated deformation, rotation, and scale variation.
Additionally, the log-polar histograms of different contour points of one hand gesture are shown in the second column of Fig. 8. The positions of the three contour points are quite different and there are large differences among the log-polar histograms. The third and fourth columns of Fig. 8 shows that contour points in the same position of different hand gestures also have different log-polar histograms. This means that the 3D-SC descriptor can distinguish contour points in different locations and represent the 3D hand gesture effectively.
B. Recognition Experiments
1) NTU Hand Digit Dataset:The NTU Hand Digit dataset[22] includes 10 classes of hand gestures which are captured by the Kinect sensor with cluttered backgrounds. Each class has 100 gestures performed by 10 subjects. Also, the gestures are performed with variations in hand scale, orientation,articulation, etc., which is challenging for hand gesture recognition. As shown in Fig. 9, the first row includes samples of ten classes, the second shows the corresponding depth maps, and the third shows hand shapes. We can see that the hand shapes are segmented accurately from the cluttered backgrounds.
We test our method with DTW matching, and half of the hand gestures are used for training and half for testing. The experiment is repeated over 100 times while changing the training and testing data. Different parameters (k1andk2) are tested in our experiments. As shown in Table I, the best performance we get is 98.7% whenk1=12 andk2=5 , which validates the rationality of the theoretical analyses of the parameter setting in Section III-B. The recognition accuracy of our method outperforms the state-of-the-art methods listed in Table II. Our method shows an impressive performance with the highest recognition rate of 98.7% compared to other methods, e.g., convolutional neural networks (CNN). We use the same structure of CNN as that in [55], i.e., AlexNet. Our method has an obvious improvement compared to the SC algorithm which proves that 3D information is more discriminative than 2D information for hand gesture recognition. The efficiency of our method is higher than the state-of-the-art methods which is discussed in Section V-D and our method is capable for real-time applications.
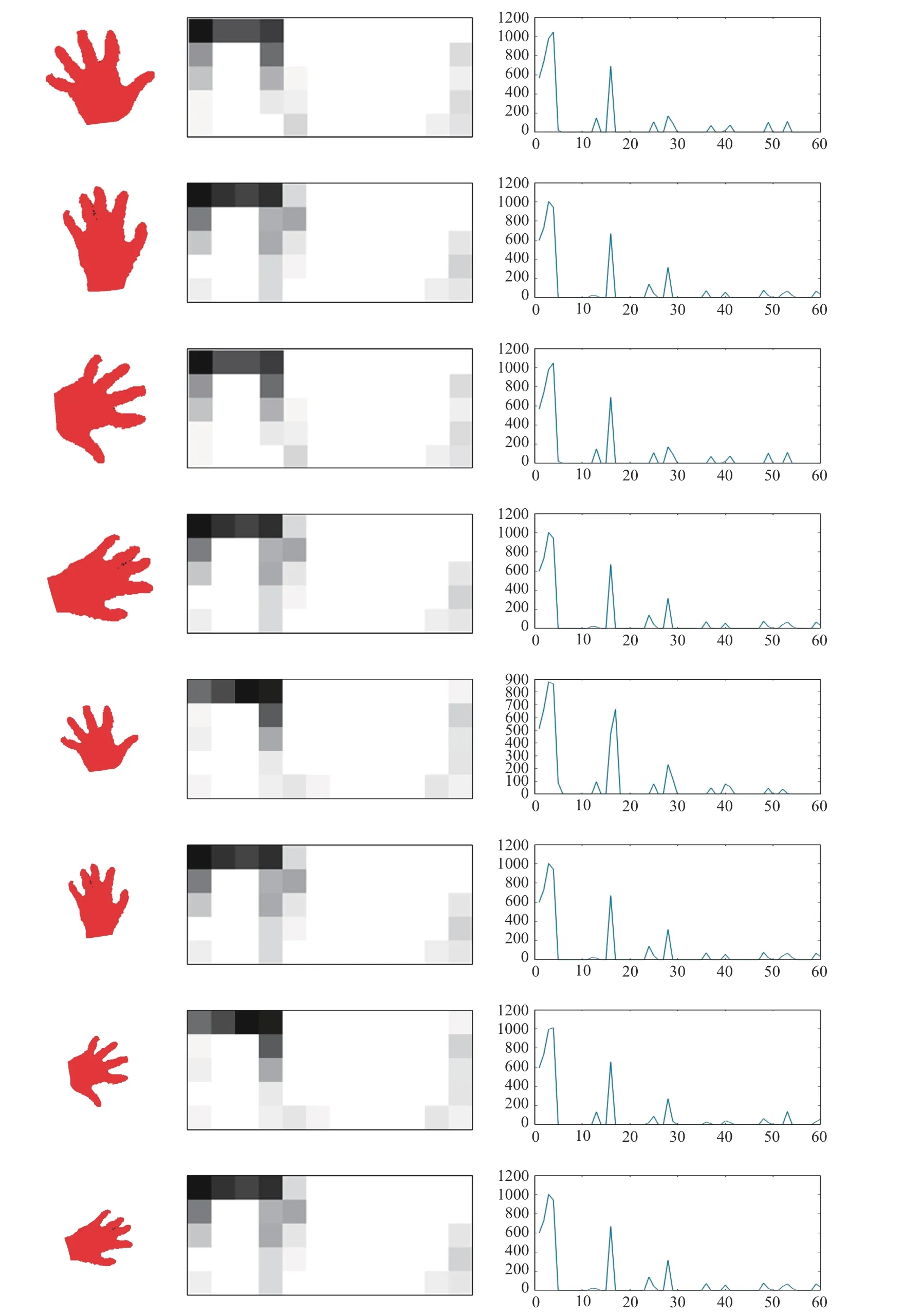
Fig. 7. In the first column, the first and the second rows are the original gestures with intra-class salient variations. The third and the fourth rows are the corresponding rotated gestures, the fifth and the sixth rows are scaled gestures, and finally the seventh and the eighth rows are gestures with both rotation and scale variations. The second and the third columns are the log-polar histograms and line charts respectively, corresponding to the gestures in the first column.

Fig. 8. The first column is an illustration of different contour points on the same hand gesture (Point A, B, and C). The second column is the log-polar histograms corresponding to the three points in the first column, respectively. The third column is an illustration of the contour points in the same position of different hand gestures (Point D1, D2, and D3), and the fourth column is the log-polar histograms corresponding to the three points in the third column,respectively.

Fig. 9. Hand gesture samples of ten classes (G1 to G10 from left to right) in the NTU Hand Digit dataset.
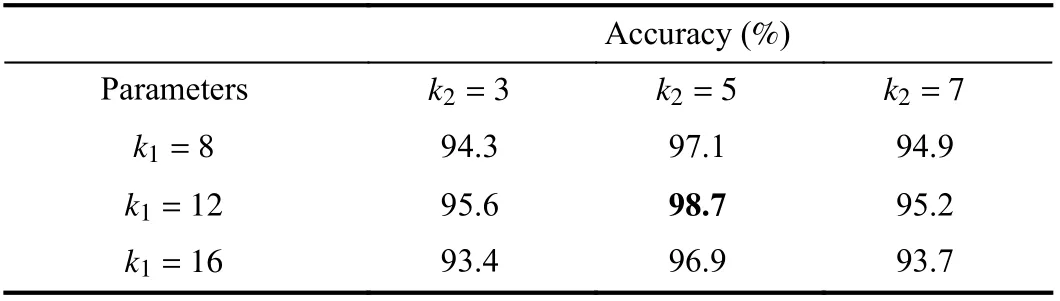
TABLE I RECOGNITION ACCURACIES WITH DIFFERENT PARAMETERS ON THE NTU HAND DIGIT DATASET
The confusion matrix of the recognition results on the NTU Hand Digit dataset is shown in Fig. 10. Each row of the matrix represents the distribution of samples in the corresponding class of hand gestures recognized as respective gesture classes. The numbers in the black grids represent the proportions of correct recognitions, while the numbers in the gray grids represent the proportions of error recognitions.Although G2 is very similar to G9 with each hand gesture showing only one extended finger, the recognition accuracies of these two classes are still more than 98%. We should note that, it is impossible for any descriptor to extract all the gesture features to achieve a 100% recognition rate. However,improving the capability of descriptor is important for hand gesture recognition. The experimental results validate the superior representative and discriminative power of the proposed method for hand gesture recognition.
2) Kinect Leap Dataset:Reference [35] consists of 10 classes of hand gestures, each of which has 140 gesturesperformed by 14 subjects. As shown in Fig. 11, the first row includes samples of ten classes, the second shows the corresponding depth maps, and the third shows hand shapes.We can see that accurate shape contours and depth information can be achieved for later operations.
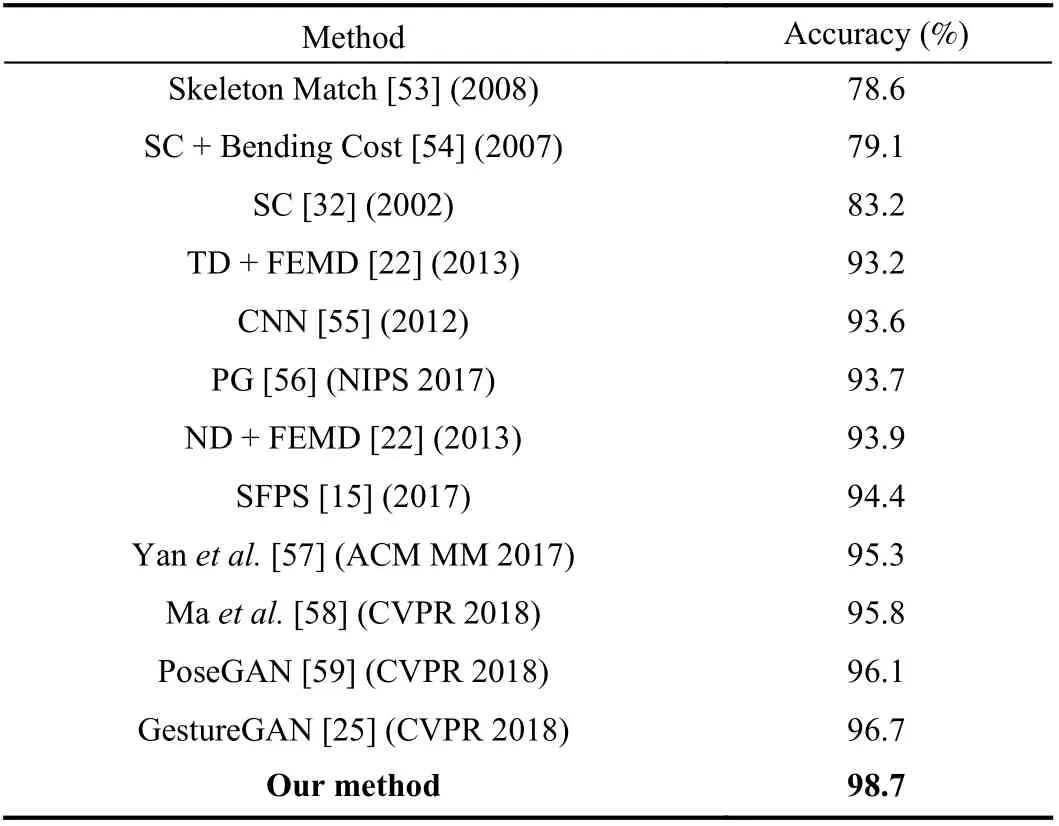
TABLE II RECOGNITION ACCURACY COMPARISON ON THE NTU HAND DIGIT DATASET
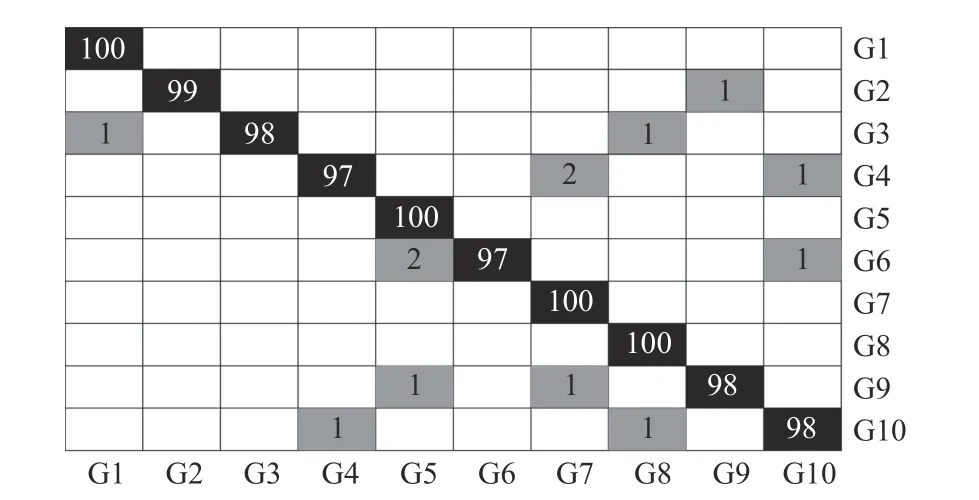
Fig. 10. Confusion matrix of the recognition results on the NTU Hand Digit dataset. Each row of the matrix represents the distribution of the samples in the corresponding class of hand gestures recognized as respective gesture class. The numbers in the black grids represent the proportions of correct recognitions, while the numbers in the gray grids represent the proportions of error recognitions.

Fig. 11. Hand gesture samples of ten classes (G1 to G10 from left to right) in the Kinect Leap dataset.
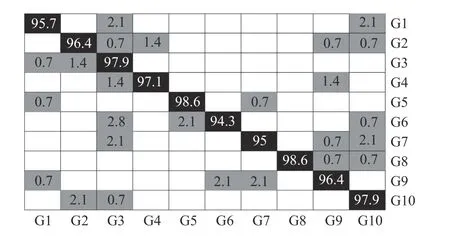
Fig. 12. Confusion matrix of the recognition results on the Kinect Leap dataset. Each row of the matrix represents the distribution of the samples in the corresponding class of hand gestures recognized as respective gesture class. The numbers in the black grids represent the proportions of correct recognitions, while the numbers in the gray grids represent the proportions of error recognitions.
The hand gestures are captured from 14 different subjects,which increases the complexity and recognition difficulty of the dataset. We use the same setup as that in the NTU Hand Digit dataset. Experimental results show that our method achieves a high recognition rate which is superior to other methods listed in Table III. The confusion matrix of the recognition results on the Kinect Leap dataset is shown in Fig. 12. The recognition accuracies of all the classes are high.
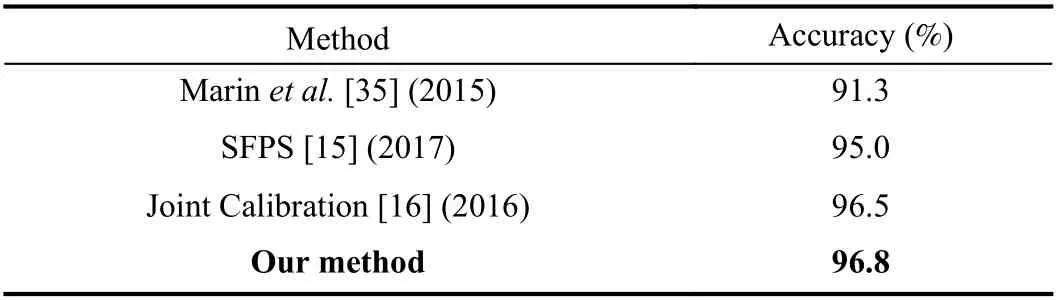
TABLE III RECOGNITION ACCURACY COMPARISON ON THE KINECT LEAP DATASET
3) Senz3d Dataset:The Senz3d dataset [36] consists of 11 classes of hand gestures, each of which has 120 gestures performed by 4 subjects. Each subject performs one class of hand gesture 30 times. The backgrounds are cluttered and there is a lot of noise in the depth maps. Therefore, we process the depth maps using a corrosion operation to achieve a clean hand shape. As shown in Fig. 13, the first row includes samples of ten classes, the second shows the corresponding depth maps, and the third shows hand shapes.
We make a 70%/30% split between training and testing sets.The experiment is repeated over 100 times while changing the training and testing data. The recognition accuracy of our method outperforms the state-of-the-art method listed in Table IV. The confusion matrix of the recognition results on the Senz3d dataset is shown in Fig. 14. We can see that the recognition accuracies of six classes of gestures reach 100%.
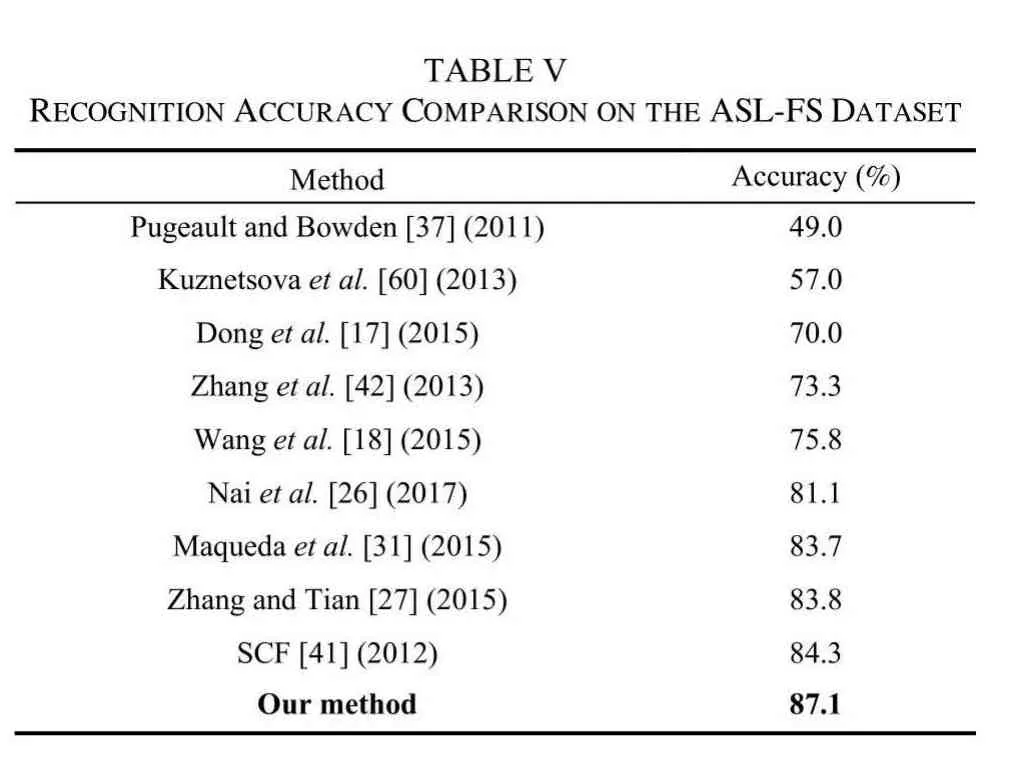
4) ASL-FS Dataset:The ASL-FS dataset [37] contains about 65000 samples of 24 classes of hand gestures performed by 5 subjects. The 24 classes of hand gestures stand for 24 letters in American Sign Language which are selected from all 26 letters excluding the 2 letters with hand motion. The subjects were asked to make the sign facing the Kinect and to move their hand around while keeping the hand shape fixed,in order to collect a variety of backgrounds and viewing angles. An illustration of the variety in size, background and orientation is shown in Fig. 15.
In our experiments, we perform leave-one-subject-out cross validation, which is the same criterion as used in [37]. It is the most relevant accuracy criterion, as it tests on unseen users.The average recognition rate is 87.1%. As shown in Table V,the accuracy is comparable to the state-of-the-art methods and our method shows an impressive performance with the dominating recognition rate.
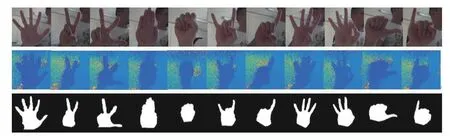
Fig. 13. Hand gesture samples of eleven classes (G1 to G11 from left to right) in the Senz3d dataset.
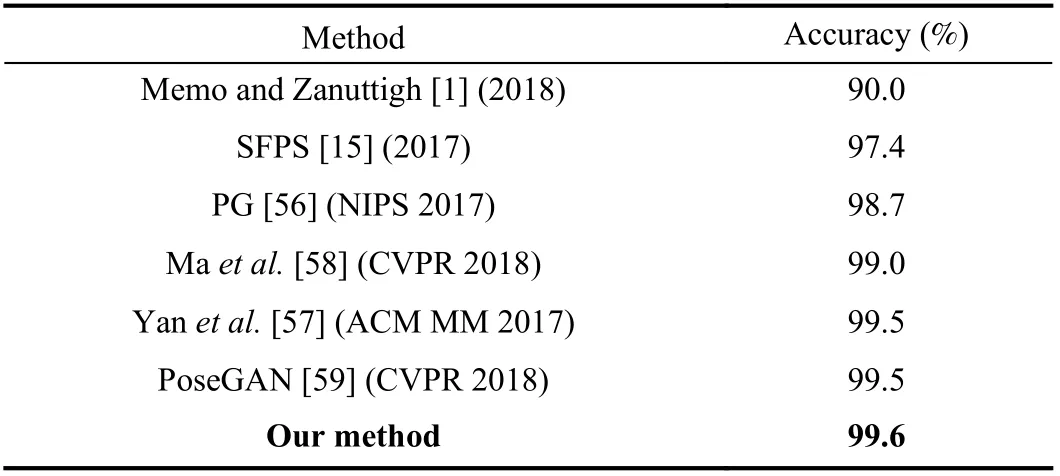
TABLE IV RECOGNITION ACCURACY COMPARISON ON THE SENZ3D DATASET
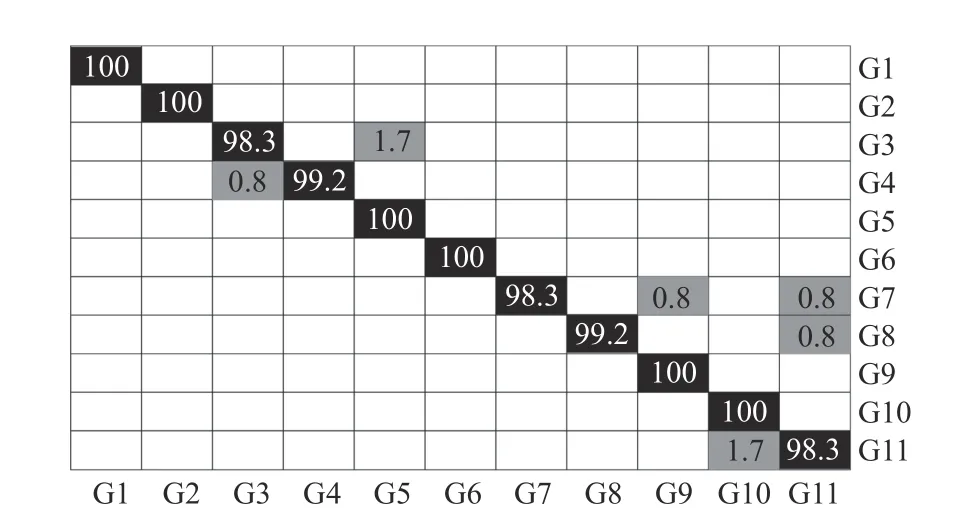
Fig. 14. Confusion matrix of the recognition results on the Senz3d dataset.Each row of the matrix represents the distribution of the samples in the corresponding class of hand gestures recognized as respective gesture class.The numbers in the black grids represent the proportions of correct recognitions, while the numbers in the gray grids represent the proportions of error recognitions.
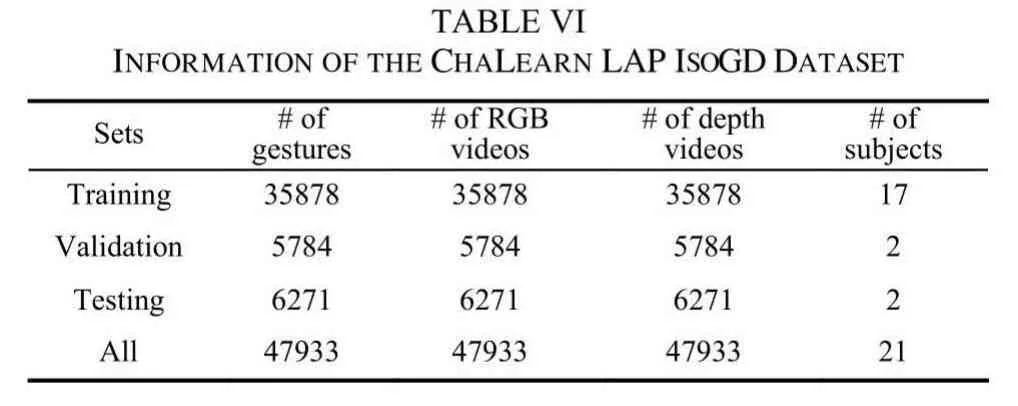
5) ChaLearn LAP IsoGD Dataset:ChaLearn LAP IsoGD[38] is a large-scale dataset derived from the ChaLearn gesture dataset (CGD) [61] which has a total of more than 50000 gestures. The ChaLearn LAP IsoGD dataset includes 47933 RGB+D gesture videos. Each RGB+D video represents one gesture only, and there are 249 classes of hand gestures performed by 21 subjects. This dataset is for the task of user independent recognition, namely recognizing gestures without considering the influence of performers. Details of the dataset are shown in Table VI.
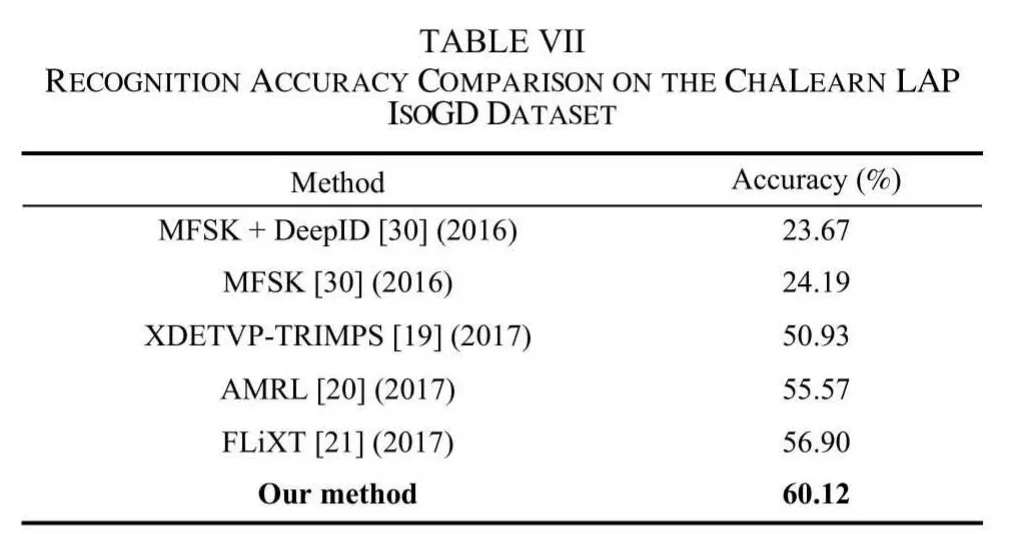
Only the depth videos are used in our experiment, without RGB videos. We combine the 3D-SC descriptor of the hand gesture in each frame to make the whole representation of a hand gesture. The performance of our method is compared with state-of-the-art methods as shown in Table VII. We can see that our method achieves the performance of 60.12%which outperforms the state-of-the-art methods.
C. Robustness of 3D-SC Descriptor
In this experiment, we test the robustness of the proposed 3D-SC descriptor to cluttered backgrounds and noise.
1) Robustness to Cluttered Backgrounds:Given the depth maps with cluttered backgrounds, we need to segment the hand shape from the background. The hand shape segmentation method we used is discussed in Section III-A.As shown in Fig. 16, although the backgrounds are cluttered,the hand shapes are segmented accurately. Thus, the influence of cluttered backgrounds can be avoided.

Fig. 15. An illustration of the variety of the ASL-FS dataset. This array shows one image from each user and from each letter, displayed with relative size preserved. The size, orientation and background can change to a large extent. The full dataset contains approximately 100 images per user per letter.
Our method is superior to skin-color-based methods [62],[63] in hand gesture recognition because we exclude the interference of color and our method is insensitive to changes in lighting conditions. Additionally, redundant information is excluded by hand shape segmentation and the rest is useful with all the 3D information of hand gestures. In summary, the proposed 3D-SC descriptor is robust to cluttered backgrounds.
2) Robustness to Noise:This experiment is carried out to evaluate the robustness of our method against noise. Gaussian noises are added to the original hand shape. The hand shape is perturbed by a Gaussian random function with zero mean and deviation σ in bothxandydirections. The noisy hand shapes with different deviations are shown in Fig. 17. The log-polar histograms and line charts of the original hand shapes(Fig. 17(a)) and the noisy hand shapes with σ=0.4 and σ=0.8(Figs. 17(c) and 17(e)) are shown in Fig. 18. From the figure we can find that the proposed 3D-SC descriptor preserves invariance under noise, and the increasing of σ has very little effect on our method.
To further demonstrate the robustness to noise of the proposed 3D-SC descriptor, we add Gaussian noise to the hand shapes in the NTU Hand Digit dataset with differentσ and conduct hand gesture recognition experiments on these noise-deformed hand shapes. This test is implemented in the same manner as before to calculate the recognition rate. The experimental results are listed in Table VIII which shows that the recognition rates are rarely affected by noise levels from 0.2 to 0.4, and that our method can still maintain high recognition rate even with noise levels of 0.6 to 0.8 with large deformations in the boundary. This verifies the robustness of the proposed 3D-SC descriptor to noise in hand gesture r ecognition.
?
?
?

D. Efficiency Comparison
Besides the outstanding recognition accuracies on five benchmark datasets, the proposed method also has excellent efficiency. In this experiment, the efficiency of our method is tested and compared with other important methods. Our experiment is repeated with different training and testing samples over 100 times and the mean performance is reported.The efficiencies of different methods are listed in Table IX.From the comparison we can find that the efficiency of our method outperforms state-of-the-art methods. The average running time of the proposed method is only 6.3 (ms) for each query on a general PC (without GPU), which fully supports real-time applications.
VI. CONCLUSION
In this paper, a new method for 3D hand gesture representation and recognition is proposed. Both local and global 3D shape information in multiple scales are sufficiently utilized in feature extraction and representation. The proposed 3D-SC descriptor is invariant to articulated deformation,rotation, and scale variation. It is also robust to cluttered backgrounds and noise. Experiments on five benchmark datasets, including large-scale hand gesture datasets,demonstrate that the proposed method outperforms state-ofthe-art methods. Also, our method has excellent efficiency and fully supports real-time applications.

Fig. 17. The hand shapes with Gaussian noises in different degrees. (a) σ=0. (b) σ=0.2. (c) σ=0.4. (d) σ=0.6. (e) σ=0.8.
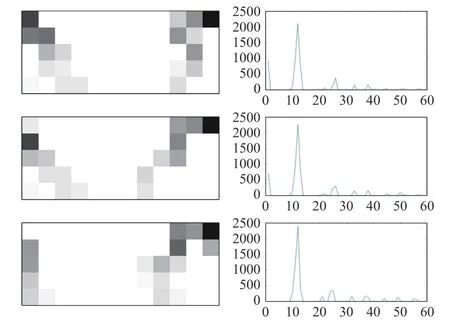
Fig. 18. The log-polar histograms and line charts of the hand shapes with Gaussian noises, where σ=0, 0.4 and 0.8 in the 1–3, rows respectively.

TABLE VIII RECOGNITION ACCURACIES UNDER DIFFERENT NOISE LEVELS ON THE NTU HAND DIGIT DATASET
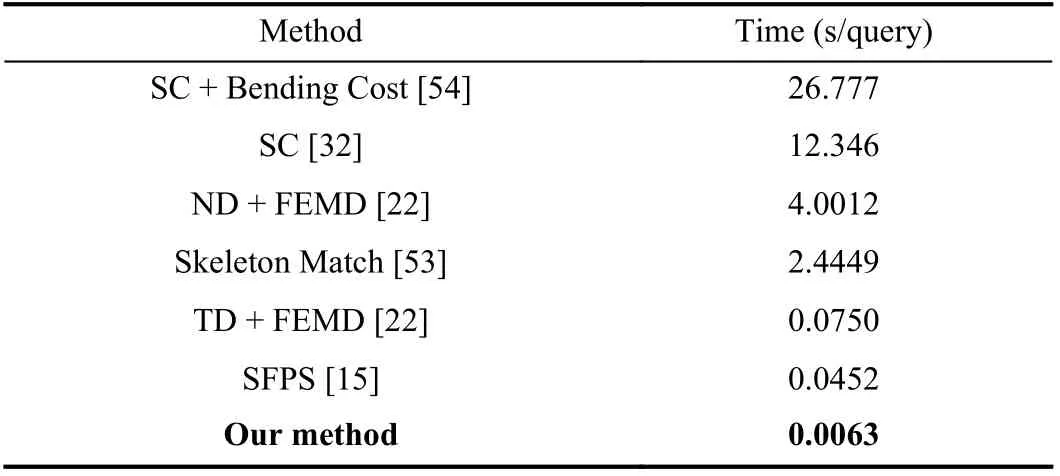
TABLE IX EFFICIENCIES OF DIFFERENT METHODS ON THE NTU HAND DIGIT DATASET
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Distributed Resource Allocation via Accelerated Saddle Point Dynamics
- Fighting COVID-19 and Future Pandemics With the Internet of Things: Security and Privacy Perspectives
- Soft Robotics: Morphology and Morphology-inspired Motion Strategy
- Generating Adversarial Samples on Multivariate Time Series using Variational Autoencoders
- A Unified Optimization-Based Framework to Adjust Consensus Convergence Rate and Optimize the Network Topology in Uncertain Multi-Agent Systems
- MU-GAN: Facial Attribute Editing Based on Multi-Attention Mechanism