一种ARIMA-LSTM组合模型的人参价格预测方案研究
2021-07-23方涛
方 涛
(河北省地质大学,河北 石家庄 050030)
0 引言
随着国家政策的推广和中药材自身卓越的治疗效果,中药材市场由国内扩展至全球,需求量逐渐扩大,而中药材价格又受到其生长周期、需求周期、政策等多方面、多因素的影响,波动幅度较大,没有显著的线性变化趋势[1]。相比于常见的季节性农产品价格,中药材价格也没有明显的周期变化规律。以常见的名贵中药材人参为例,在2015年1月至2020年11月,价格最高为650元/kg,最低为280元/kg,变化幅度超过了130%,剧变的价格对于人参的种植和销售都会带来不良的影响。
人参的价格数据是一个复杂的包含线性变化、非线性变化的系统,很难将它确定为一种单纯的线性模型或者非线性模型,这一特性增加了预测的难度[2]。在此背景下,为了提高预测精度,提出一种 ARIMA-LSTM神经网络组合模型,分别对人参价格的线性、非线性成分进行预测。价格数据是按照时间的先后顺序收集的,可以将其视为时间序列数据,而中药材或是由于技术改良,导致成本降低,价格下降;或是需求量逐年增加,导致价格上升,这些都是线性变化成分,ARIMA模型广泛应用于确定的、线性的变化系统,使用ARIMA可得到线性变化趋势。原始数据减去ARIMA预测的线性部分,可得到只剩下非线性特征的残差数据,LSTM 神经网络具有映射任意非线性函数的能力,又因为其特殊的记忆单元、遗忘门等结构,擅长处理时间序列数据,对包含非线性特征的残差序列数据可得到一个良好的预测结果。组合模型避免了单一模型的固有缺陷,为价格预测提供一种更有效的预测模型。
国外的研究者,如美国经济学家 Moore[3]通过对每一年温度变化和降雨量做相关性分析,使用回归模型研究棉花价格与温度、降雨量这两个相关因素之间的关系,以此对棉花价格做出预测,并且根据预测结果证明了该回归模型的精度要优于传统的分析方法;Jarrett[4]首次将时间序列模型应用在澳大利亚羊毛价格预测上,得到羊毛价格的大致趋势,验证了该模型在线性预测方面良好的性能表现,为价格预测提供更多的思路,引来更多的学者对时间序列模型展开更深入的研究和广泛的应用。而国内的研究者,如潘水洋[5]等提出一种用神经网络预测股票收益的模型,学习和捕获定价因子之间的非线性关系,获得良好的预测结果;张东青[6]等在使用神经网络的基础上,使用分位数回归分析了不同价格条件的分布特征,提出的是基于神经网络优化后的模型,实验结果表明,分位数回归得到分布特征为神经网络提供的额外的参考依据并提高了预测精度。但是总体来说,这些研究都是使用单一的模型对事物的发展进行预测,尽管使用优化方法对模型进行改进,但是从结果来看,效果并不佳,本文针对药材价格数据的不同特性,使用双模型分别对线性和非线性特征进行分析预测,从结果上来看,预测效果要优于单一的模型。
1 模型理论
1.1 ARIMA模型
ARIMA(Autoregressive Integrated Moving Average,整合自回归移动平均)是在AR和MA模型的基础上改进而来[7]。
AR(Autoregressive Model,自回归)模型是统计上一种处理时间序列的方法,用待研究数据中一段历史时期的数据来预测下一个或多个时期的结果[8]。如使用x1至xt–1时期的数据预测xt时刻的数据。使用该模型的前提是这些数据之间具有线性关系。AR模型的特征是使用自变量预测自变量。该模型定义如下。
给定序列{xt},某一个时刻t和前p个时刻序列值之间的关系为:

假设随机序列{εt}是白噪声,若其与前一时刻序xt(k MA(Moving Average Model,移动平均)模型是一种平滑预测技术,它的基本思想是将待研究的数据逐项推移,依次计算序列平均值,以显示该序列长短期趋势的变化[9]。MA模型可以使原本受各种影响影响导致波动大、较难看出其变化的序列显示出它内在的趋势。该模型的定义如下。 给定序列{xt},xt是若干个白噪声的加权平均和: 式(2)中,{εt}是白噪声序列,这样的模型称为q阶移动平均模型,记为MA(q)[10]。 由于AR、MA模型存在只能适用于平稳时间序列的缺点,提出ARIMA模型,该模型基于AR、MA模型,公式可表示为: 记为ARIMA(p,d,q)[10]。 ARIMA模型综合了AR、MA模型对线性趋势有良好预测能力的优点,由于含有限参数,只要通过一些方法计算、估计这些参数的值,模型即可完全确定。同时 ARIMA模型使用差分法消除时间序列中与线性预测不相干的不平稳因素,预测性能和适用范围都更为优秀,更适合于预测价格序列中的线性趋势。 LSTM(Long-Short Term Memory,长短期记忆)神经网络是RNN(Recurrent Neural Network,循环神经网络)的一种变体,其基本结构与RNN类似[11]。LSTM神经网络在传统神经网络的结构基础上,添加了记忆单元,同一层的神经网络之间使用相同的权重,因此特别适合处理时间序列数据[12]。序列数据可以是价格数据,也可以是文字序列。这些数据有一个共同特点:反应某一个事物、状态等随时间而发生变化,即后面时间段的数据受之前某一时刻或者某一段时间数据的影响。LSTM 神经网络的结构区别于一般的神经网络同层之间不连接,它的所有节点(循环单元)均按链式连接,结构图如图1所示。 图1 LSTM神经网络结构图Fig.1 LSTM neural network structure LSTM 神经网络的网络拓扑结构整体上与传统神经网络类似,由输入层、输出层、隐含层三层组成,因为记忆单元和遗忘门的存在,对于包含非线性特征的时间序列数据具有较好的记忆和预测能力,故适合用在价格预测上。LSTM 神经网络的结构基于RNN的结构,区别在于隐含层的改变,内部详细的模型图如图2所示。 图2 LSTM神经网络模型图Fig.2 LSTM neural network model LSTM神经网络对比RNN最大的改进是它增加了遗忘门、输入门、输出门和一个记忆单元,可以通过控制门控单元对输入数据选择性的进行记忆和遗忘[13]。若输入数据为x1、x2…xt–1、xt、xt+1,遗忘门的计算公式为: 其中,ft是遗忘门的输出,σ是激活函数,W1是权值,ht–1是相邻隐含层神经元传送来的输出值,b1是偏置。 通过遗忘门遗忘了不需要的数据,再通过记忆们选择对哪些值进行更新,结合起来的公式为: 其中,Ct是记忆单元的输出,Ct–1是相邻隐含层神经元中记忆单元传送来的输出,W2是权值,b2是偏置。 隐含层的输出为:数据由隐含层向输出层传播,则输出层的输入为: 最终LSTM神经网络的输出为: 整个组合模型的流程图3如下。 图3 组合模型流程图Fig.3 Combinatorial model flow chart 本文将这两个模型组合起来的基本思路为:首先由 ARIMA模型对价格数据的线性成分进行分析预测,该模型只分析、计算前后自变量的关系,使用历史数据预测当前或者未来时刻的价格数据。通过 ARIMA模型得到线性预测结果,然后用原始数据减去线性预测结果,得到残差值,该值即为剩下的非线性特征数据;然后由 LSTM神经网络对只具备非线性特征的残差值进行分析预测,得到非线性预测结果;最后将两个模型分别预测的线性结果和非线性结果进行组合,即可得到最终组合模型的预测结果。经过实验结果分析可知,组合模型预测精度和预测平稳性都有不小的提高,有效解决了单一模型对包含多因素价格序列预测精度不高的缺点。 本文所使用数据为中药材天地网中亳州市场的人参每kg的市场价格,单位为元,收集的数据自2015年1月至2020年11月,数据如图4所示。 图4 人参价格数据图Fig.4 Ginseng price data graph ARIMA模型的具体实验步骤如下: (1)平稳性检验 由于 ARIMA属于线性预测模型,而人参价格数据属于包含线性、非线性等多重因素的序列数据,首先需要对其进行平稳性检验,检验其是否为只包含线性因素的平稳序列。判断的依据是进行ADF(Augmented Dickey-Fuller test,单位根检验),ADF检验是一种较为严格的检验方法,用以判定序列是否存在单位根。当序列平稳时,不存在单位;而当序列不平稳时,则存在单位根[14]。ADF检验先假设存在单位根,如果得到的显著性检验统计量分别小于三个置信度(10%,5%,1%),那么就分别有(90%,95%,99%)的把握拒绝原假设,即序列是平稳的。 先假设序列存在单位根,即先假设该价格其是非平稳序列。P值是指在一定的显著性水平下,假设统计量正确,临界值与其相等的概率,所以P越小,拒绝假设的可能性越大,即该序列越有可能是平稳序列。一般认为,P>0.05表示接受该假设,即存在单位根,序列是非平稳的;P<0.05表示拒绝假设,即不存在单位根,代表该序列是平稳的。T检验是通过t的分布来比较差异化,若t大于规定水平的临界值,则接受假设,即序列不平稳;若t小于该临界值,则拒绝原假设,即序列是平稳的。通过计算可得人参价格序列ADF单位根检验结果,具体数值如表1所示。 表1 人参价格序列ADF单位根检验结果Tab.1 Test results of ginseng price series ADF unit root 从表1可知,在ADF检验下,统计量t=–2.4616,均大于在 1%、5%、10%水平临界值的统计量,ADF检验的概率P=0.4341,大于规定的0.05,因此接受原假设,即该价格序列是不平稳的。 (2)差分 由步骤(1)可知,序列是不平稳的,进行差分处理,值得注意的是,尽管差分运算可消除平稳性,但每一次的差分运算都会使原序列丢失一定的信息,差分次数过多会导致模型不可靠,所以应当使用尽可能少的差分运算。差分后的数据如图5所示。 图5 人参一阶差分图Fig.5 Ginseng first order difference map 对差分的金银花价格序列再次使用 ADF进行平稳性检验,结果如表2所示。 表2 人参价格序列ADF单位根检验结果Tab.2 Test results of ginseng price series ADF unit root 从表2可知,ADF检验下的统计量t=–11.4261,均小于在 1%、5%、10%水平临界值的统计量,ADF检验的概率P=0.0001,小于规定的0.05,所以拒绝原假设,证明该序列是平稳的。确定差分的阶数为1。 (1)模型定阶 模型定阶是通过合适的方法确定 ARIMA模型中p、q两个参数的值,可通过 AIC(Akaike Information Criterion,赤池信息量)确定[15]。本文通过计算AIC确定ARIMA(p,d,q)种p、q的值。AIC建立在熵的概念基础上,用来衡量模型复杂度和拟合优良程度。AIC的公式为: AIC数值越小,说明拟合性能越佳。然而模型性能越好,复杂度也会随着提高,同时似然函数也会增大,并且也可能造成过拟合的现象。为了限制模型的规模,避免过拟合,将值限定在[0,8],通过暴力查找到最合适的值,对应的p、q值为5、5,差分次数为1,即确定模型为ARIMA(6,1,6)。 (2)线性预测 参数全部确定完,模型确立,即可对数据进行训练、学习、预测,由于 ARIMA模型是使用历史数据对当前和未来数据进行预测,故2015年1月至2015年6月的价格作为最初的历史数据无法对其进行预测,以2015年7月为第1个月,2020年11月作为第65个月,预测图如图6所示。 图6 ARIMA线性预测图Fig.6 ARIMA linear prediction chart LSTM的具体实验步骤如下: (1)预处理 由于本文是使用LSTM神经网络预测非线性部分,首先计算人参价格序列的残差值,ARIMA模型已经预测出人参价格数据的线性趋势,LSTM 神经网络只需要对非线性成分进行预测即可。使用人参原始价格数据减去 ARIMA模型的线性预测部分,即使用图 2.2的数据减去图 2.4的数据,剩下的残差值即可认为是人参价格数据的非线性成分。 对该残差值进行归一化处理,归一化可将输入数据缩放到一个较小的区间,本文将数据归一化至[–1,1]。由于神经网络给予数据中偏大的值更多的权重,容易影响预测结果的准确性,而归一化将所有数据缩放至一定范围内,可避免这种情况,同时也可以减少计算量、加快收敛。 (2)初始化模型 初始化模型的过程包含数据集的划分以及输入特征、隐藏神经元数目的设置。 将处理后包含非线性特征的残差数据序列划分为训练集、测试集,药材价格数据共有65个,将其中的 40个时间点数据划分为训练集,25个时间点数据划分为测试集,并且对训练集和测试集数据的选取都是随机的,但是要保证每次输入的样本数据依然具备时间序列特性,即该一个样本内的数据依然是按时间前后关系排列。随机选取的目的增加LSTM神经网络的鲁棒性,打乱数据可以在训练过程中得到不同的梯度,避免每次训练都从同一个梯度方向寻优,造成过拟合现象。药材价格预测是使用其本身的自变量对自变量的预测,所以输入特征为 1。隐含层数目经过多次调试设置为10。 (3)模型训练 本文的神经网络实验基于Keras框架,Keras框架规定LSTM神经网络的输入数据格式为:[送入样本数,循环核时间展开步数,每个时间步输入特征个数]。送入样本数确定为 5,即通过前 5个时间点价格数据预测后 1个时间点的价格数据;循环核时间展开步数取 1;每个时间布输入特征个数因为一个时间点为金银花一个数据,故取1。 LSTM 神经网络中训练学习步骤是整个神经网络处理过程中最重要的一环,根据价格序列数据的特性和规律,LSTM 神经网络使用t–1,t–2,…,这些历史时刻的数据,预测t时刻的数据。确定每一次训练数据数目为5个,且每个神经元接受1个训练数据,则输入层存在5个神经元,实际输出数据数目为 1。首次输入后,隐含层的神经元不但要接受输入层的神经元通过权值计算传输的,还要接受同层之中上一个节点传输过来的值,并对其进行累加。然后隐含层通过激活函数输出数据,与真实的输出数据进行误差计算,并根据误差调整权值,以上过程为单次的训练流程。经过反复的计算,直至误差低于指定值或者达到一定的次数,则完成训练。 (4)预测数据 相关数据已经处理完毕,每次训练以 5个时间点的历史数据预测未来的1个时间点数据,每个时间点代表一个月的价格数据。多次训练后拟合出一个对所有训练数据预测误差最小的函数,即完成了训练过程。与ARIMA相同的是,LSTM神经网络也是使用历史数据预测未来数据,故2015年7月至2015年12月的数据作为最初的历史数据无法对其进行预测,重新设置时间标号,将2016年1月作为第1个月,2020年11月作为第59个月。预测图如图7所示。 图7 LSTM残差预测Fig.7 LSTM residual prediction (5)模型组合 最后一步对模型进行整合,由于两个模型是分别对线性成分和非线性成分进行预测,模型的整合将两个模型的对2016年1月至2020年11月的预测结果进行累加。以2016年1月为第1个月,2020年11月为第59个月,最终的预测图如图8所示。 图8 组合模型预测图Fig.8 Combination model prediction diagram 实验结果的好坏需要使用相对应的指标进行评析,对于模型的预测精度方面,本文使用MRE(Mean Relative Error,平均相对误差)对结果进行评价来进行评价;对于模型预测结果的平稳性,本文使用RMSE(Root Mean Square Error,均方根误差)来进行评价。均方根误差可以体现误差的离散程度,即预测的平稳性。平均相对误差、相对均方根误差公式为: ARIMA、LSTM神经网络、组合模型的评价指数如表3所示。 表3 各模型评价指数表Tab.3 Model evaluation index table MRE是误差与真实值的比例,结果越小越精度越高,RMSE是分析预测结果的离散程度,对异常值高度敏感,即使大多数预测都很准确,一旦有极少数的值与真实值相差较大,那么就会极大的影响RMSE的指标,它的结果越小,预测结果越平稳。从表中可知,LSTM 神经网络在预测精度和平稳性都要优于 ARIMA模型,而两者组合的模型在预测精度和平稳性两个方面都要由于单一的ARIMA模型和LSTM神经网络。 人参的需求量逐渐扩大,分析其价格走势并能够对短期的价格趋势做出一个准确预测,及时将信息反馈给相关从业者和决策者,这对于种植、销售和宏观调控都具有重要意义。应用在人参价格预测上的组合模型的相关研究较少,而药材的价格数据包含线性、非线性成分,单一的预测模型难免会产生预测精度不高、预测结果不平稳的缺点,本文根据药材价格数据包含线性和非线性成分的特点选取ARIMA模型和LSTM神经网络并对其进行组合。 ARIMA模型使用差分法去除原始价格数据中的非线性因素,通过一系列处理从价格序列中提取线性成分,预测出较为准确的线性发展趋势;LSTM 神经网络对非线性函数具有较好的拟合能力,而又由于其特殊的结构优势,对序列数据有更好的预测能力,与 ARIMA模型相结合可以得到更精确、更平稳的预测结果。

1.2 LSTM神经网络







2 实验流程

2.1 ARIMA模型线性预测






2.2 LSTM神经网络非线性预测
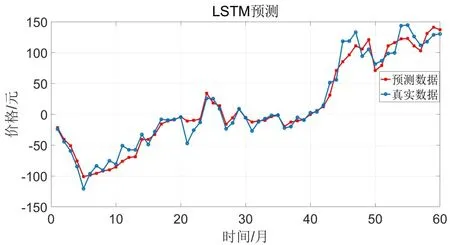

3 实验结果分析


4 结论
