人工智能在智慧铁路体系中的应用趋势研究
2021-07-23温博阁
温博阁
(大连交通大学,辽宁 大连 116028)
0 前言
人工智能神经网络,是一种模仿生物神经网络结构和功能的数学模型,它的构筑理念是受到生物(人或其他动物)神经网络功能的运作启发而产生的。我们通过利用神经网络的非线性变换的能力来处理原本只能依靠人类大脑判断的问题,这种方法比起正式的逻辑学推理演算更具有优势。
借助于人工智能在逻辑推理、识别、控制方面的巨大优势,使用人工智能技术建设智慧铁路正在成为铁路现代化和高质量发展的演进形态和重要标志。我国拥有世界上最庞大的高速铁路网络和服务最广大群体的铁路管理和服务体系,推动智能铁路发展有利于全面提高我国超大规模铁路网运输能力效率效益和建设管理服务水平。
智慧铁路[1]运输系统最为重要的组成部分是控制、感知。这几个方面与人工智能在逻辑判断、图像识别、强化学习等研究方面相符合,使其可以广泛应用于智慧铁路的控制和感知等相关领域,尤其是作为智慧铁路重点建设的目标:智能装备和智能运维方面。这两方面囊括了自动驾驶、智能控制与决策、故障诊断、故障预测与健康管理、先进感知技术大数据分析等各种依赖于人工智能的技术。这些技术的应用将实现重载铁路移动装备及基础设施的自感知、自诊断、自决策、自适应、自修复;实现重载列车自动及协同运行;线路、通信信号、基础设施的最佳使用状态。
1 图像识别在智能驾驶方面的应用前景
人工智能在智能驾驶方面的应用主要集中在两个方向,图像识别和强化学习。其中图像识别主要应用方向是智能驾驶方面的辅助,其特点是根据图像进行司机行为识别、路面情况识别、特殊情况识别等一切无法直接测量,或需要主观判断的识别技术。
为了判断图像信息,人工智能早期使用了多层感知机进行特征判断,其特点是利用了全连接层直接对物体类别进行分类判断。基本上的多层感知机都使用了3层结构:输入层,隐藏层,输出层。结构较为简单,但是识别效率较低,增加隐藏层的层数会带来较为明显的计算开销,判断准确率却不会带来提升。为了提升人工智能性能,在2012年ImageNet的图像分类大赛中,Alex首次在其使用的神经网络 AlexNet引入了卷积神经网络,并在当年取得了最好的成绩,其利用了卷积的权重共享机制,成功将网络深度增加到了 8层,自此奠定了卷积神经网络在图像识别领域的地位。随后多种基于卷积的神经网络方法不断涌现,直到VGG-19的诞生,人们意识到随着神经网络层数的增加,网络的准确率会不升反降,这种情况被称为深度模型的退化。其本质是神经网络的非线性变换导致多层迭代后失去了恒等映射。自此无限增加网络层数进而提高网络表现的方法失效了。
为了解决这个问题,2015年 He-Kaiming提出的 ResNet[2]结构,因为深层的网络已经很难拟合潜在的恒等映射函数(即深层退化)H(x)=x,那么通过将恒等映射作为网络的一部分来把深层网络转化为浅层网络即H(x)=F(x)+x。通过这种方式将问题转化为学习一个残差函数,并且实验证明了拟合残差要比拟合恒等映射要容易的多。
经过了残差网络后神经网络可以有效的提升网络深度,由当时VGG-19的19层一举突破到了ResNet的101层。由于深层神经网络对于特征提取的能力,以往仅仅被用于处理分类的网络终于开始输出更为复杂的结果。由此衍生出了各种应用,包括目标追踪、多目标追踪、物体定位、图像分割、时序行为识别等。对于目标追踪方面,基于 Siam双分支结构可以有效的对目标物体的追踪,可以应用于人物轨迹追踪、货物轨迹追踪、手势轨迹追踪等。时序行为识别则利用了多层可分离卷积感受时序信息,结合卷积网络提取的特征对时序行为进行判断。从图像识别发展路线上来看,网络结构由浅到深,进而由深变宽,未来的网络结构大概率不会继续加深而是增加多个分支网络结构,如超精细图像分支用于提高输出维度等。各网络层数变化表1所示。
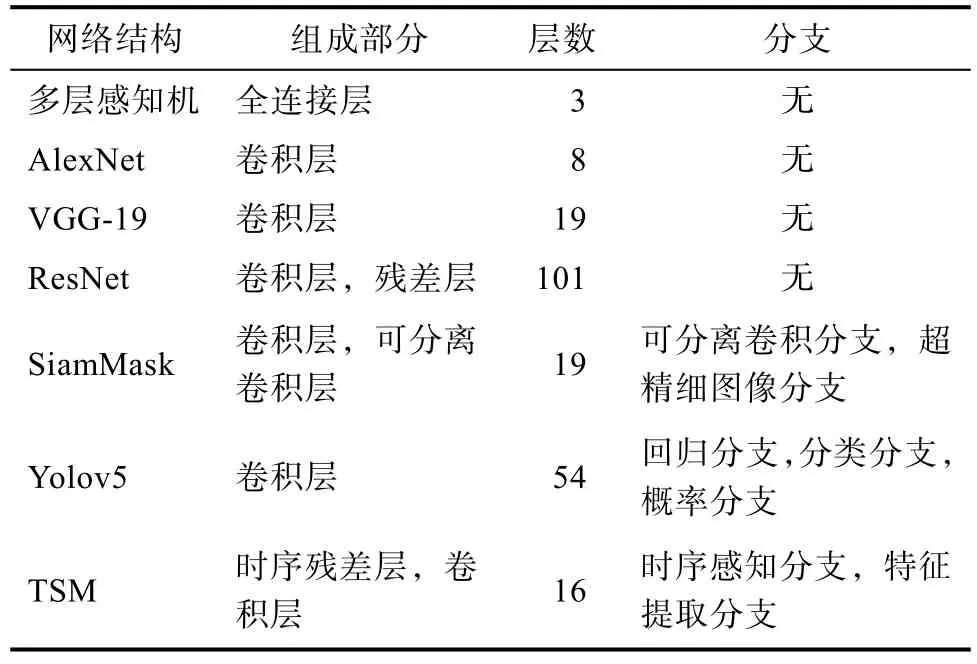
表1 卷积网络结构Tab.1 Convolution network structure
基于上文所述,在智能驾驶辅助方面,对于异物入侵可以采用Yolo进行多目标识别,这将帮助司机定位出现在其驾驶盲区的突发事件。在司机行为监控方面,可以利用 SiamMask进行肢体动作追踪,同时利用 TSM 对于时序动作进行识别,可以有效检测司机执行动作的准确性。
2 强化学习在智能驾驶方面的应用前景
强化学习[3]可以对环境做出相应的对策,因此其被应用于自动驾驶领域。相比较于汽车的自动驾驶,需要对自己的运行轨迹预测,同时考虑汽车自身周围数米内人,车的预测轨迹,并作出最优的决策避免出现事故。轨道交通领域所需考虑的场景则较为简单,因其所处环境较为独立,周围环境干扰较小,因此是较为合适的应用强化学习的领域,除此之外强化学习所学习到的策略是可以超过人类水平的,这相比于目前的LKJ辅助驾驶[4]或者自动虚拟编组技术这种依靠人工指定的操作顺序来控制的方法来说,其上限更高。强化学习输出的列车控制策略理论上可以有更快的运行速度,更低的能源消耗,对列车运行间车钩力最小化的能力,这将有效的提高整体运行的效率。
强化学习的本质是采用博弈方法来学习策略,当然这种博弈的方式也可以使用自博弈来进行,著名的 AlphaZero就是采用了自博弈的方式来进行的围棋学习,其学习的效果超过了其初代版本AlphaGO(该版本使用了学习人类棋谱的能力来构筑博弈策略)。目前针对强化学习,多采用了多智能体学习方法,并且设计了若干策略池来连续的学习策略和对可能情况的反制策略。其中最著名的是 2019年发表于Nature上并作为封面的AlphaStar,该方法也代表了强化学习的最高水平。
强化学习本身也使用了多种网络结构相互结合。例如在实际驾驶过程中,因环境要素较为复杂,感知环境的部分一般交由图像识别网络进行,例如YOLO可以有效的对出现在图像中的物体进行定位并分类,对于传感器反馈的数据也多采用自然语言处理的方式进行特征提取,强化学习更多的以这些网络提取后的特征作为基础,利用这些信息进行决策。并且强化学习本身可以与现有的自动驾驶规则相融合,可以只用来解决各种不适用于规则范围内的场景或极端问题。对于这些极端问题,多智能体将一个复杂问题分解为多个子问题,通过这种方式将短期奖励分解为长期奖励分配,这更有利于结构化搜索和迁移学习,同时多智能体也降低了每个网络的复杂程度。提升学习速度,降低不收敛的可能。总的来说,强化学习目前还在不断发展过程中,新的概念不断涌现,其对于复杂环境的感知和决策能力在逐步提升。从这几年公布的研究成果来看,科研界越来越重视强化学习与多种网络结合的端到端的解决方案。
3 自然语言处理在智能运维方面的应用前景
自然语言[5]识别字面上看只能够处理语言相关的问题,但其根本的定义是处理时序相关的数据。这种处理方法得名称来源于早期人工智能处理不同数据类型时的分类。图片类的静态数据被称为图像识别,时序相关的简单问题一般涉及到语言,所以被称为自然语言处理。目前自然语言处理的方法已经在涉及到了关于时序信息处理的方方面面,从语言到传感器数据,甚至视频动作识别都有涉及。
自然语言识别基础模型是循环神经网络,其特点是每次输入都结合了上一次输出的结果与这一次输入的结果相结合,这给了循环神经网络感知连续的时序信息的能力,可以有效的将上下文的信息进行处理。当然其面临两个问题,第一个是传输效率问题。第二个就是传递距离问题,即过长的输入会导致循环神经网络快速遗忘之前的输入。对于其改进型长短时记忆网络则利用了关键的遗忘门来控制其对与之前输入的遗忘程度,进而得到了较为不错的长期记忆能力。之后诞生了重要的Attention结构,其核心是构造一个N进N出得网络结构。接收整个时序得连续数据作为输入,然后为每个输入都做出一个输出。但是与循环神经网络不同的是,Attention结构能够同时处理输入中的所有信息,并且任意两个信息之间的操作距离都是 1,这么一来就很好地解决了上面提到的循环神经网络的效率问题和距离问题。
这种基于Attention计算的结构最早是由谷歌与2017年提出,并将这种网络命名为Transformer网络,其过程就是为连续输入得每一个输入本身做一次Attention。算出其他输入对于这个输入的权重,然后将这个输入表示为所有输入的加权和。同样得,为了增加Transformer网络的深度,在自然语言识别中也引入了图像识别中得残差网络结构,将每一层得输入于其标准化后得输入出相加,进而凑成一个残差结构拟合恒等映射。由于Transformer网络中既不存在循环神经网络,也不同于卷积神经网络,一段连续输入里的所有输入都被同等的看待,所以时序输入之间就没有了先后关系。为了解决这个问题,Transformer提出了输入向量方案,就是给每个输入叠加一个固定的向量来表示它的位置然后针对每一列都叠加上一个相位不同或波长逐渐增大的波,以此来唯一区分位置。
很明显得是输入向量会随着处理问题得逐渐复杂化而维度逐渐提高。例如要求其推理能力根据前后时序判断其未来可能得输出结构,或者相似度判断等。基于此,需要一个更为通用化得模型来处理越来越复杂得输入向量空间维度得增长。于是在2018年OpenAI提出了基于Transformer得大型网络结构GPT模型。在增加了网络深度得基础上主要解决了大量无标记数据的训练问题,精简化网络结构,使用了单向得 Transformer网络,使得网络只会关注当前输入之前的信息,这为在线预测打下了基础。同一时期谷歌也提出了基于Transformer的改进模型BERT[6]其与GPT最大不同在于可以利用双向输入去进行预测,这对于准确度有了很大得提高,但是也杜绝了一部分在线实时得应用场景。在2020年5月OpenAI提出了最新的GPT-3模型,其输入已经包括了人机问答,数学推理,画图,制表,玩游戏,写代码等方方面面,可以说是目前为止最为全能的AI,对于任何时序数据上得推理,其能力已经较为接近于人类。但这一切是建立在其网络包含了1750亿参数才可以实现的,可以发现整个自然语言处理得演化进程就是不断增加网络深度,使其可以更加智能得推理和判断。各网络演进如表2所示。

表2 自然语言处理网络结构Tab.2 Natural language processing network architecture
如上文所示,自然语言处理方面的网络结构越来越深,其参数量也水涨船高。更高维度得参数量可以有效得识别更为庞大的输入向量,使得其可以理解输入之间更为深层次的联系,进而得到其推理的结果。从智能运维的角度上来说,自然语言处理网络可应用得场景十分广泛。早期得PHM[7]系统中的专家诊断模块就是简单的利用了专家知识建模得到的,随着列车系统得逐渐复杂化,越来越多得故障没有办法简单建模得到,因为其形成机理中涉及到多个部件或零件间的运转关系,所反映出来得传感器信号与其单一运转时不同,这使得传统的故障模型建立往往难以对真实情况做出反应,只能在实验室级别取得成果,无法真正转化为实际应用。而对于多个部件间复杂的耦合关系又无法准确得通过理论解算,所以该问题一直难以处理。随着高维度超大网络的时序处理神经网络得诞生,这一切问题都可以得到一种新的解决方案,从GPT-3中可以发现对于超大网络,其捕捉信息得能力已经提高了几个量级,脱离了人工标注得范围,可以无监督学习。这将极大的降低在训练时人工标注的时间开销。一个超大网络可以有效的统合各类信息,并给出相应的推理结果。另一方面对于一些关键零部件,可以部署多个小型Transformer型网络,对其健康数据记录,学习,对关键零部件全寿命周期进行预测。
4 结论
本文梳理了人工智能三大领域:图像识别,自然语言处理和强化学习最新的研究进展,并且分析其演化方向,预测未来的发展方向。结合轨道交通领域实际应用情况,对自动驾驶,智能运维等相关领域可以改进的方向进行分析,并提出了可以借鉴使用的领域方向等。
