基于成对标签的深度哈希图像检索方法
2021-07-21李梓杨陈嘉颖蒲勇霖
李 雪,于 炯,李梓杨,陈嘉颖,蒲勇霖
(1.新疆大学 软件学院,新疆 乌鲁木齐 830008;2.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;3.新疆大学 软件工程技术重点实验室,新疆 乌鲁木齐 830008)
0 引 言
随着基于内容的图像检索技术逐步替代早期基于文本的图像检索技术,有限的时间和计算资源将挑战也转向优化存储消耗和检索速度这两方面[1,2]。近似最近邻检索作为数据检索中使用最为广泛的技术,其中最受欢迎的一类方法是哈希方法,该方法将高维图像映射成固定长度的散列值并保持原始空间中的相似性,在内存消耗和检索速度方面有着明显优势,因此被广泛应用于公安系统、数字图书馆、搜索引擎等相关工业中[3]。目前的哈希检索方法存在标签语义利用不充分、哈希码离散优化松弛、卷积神经网络模型照搬套用等缺点,这些制约因素限制了大规模图像检索的发展的脚步。为了解决上述问题,本文提出基于成对标签的深度哈希图像检索方法(deep pairwise hashing with binary restricted,DPHB),与之前单纯采用相似或不相似的标签的方法相比,能够深度挖掘丰富的图像间的内在联系,生成具有强判别力的哈希码,有效解决了二值码离散优化问题,使得标签所表达的语义更丰富,特征学习过程中语义损失更明显。
1 相关工作
由于早期的媒体图像数量有限,哈希方法的发展受到图像数量的制约,如局部敏感哈希[4](locality sensitive hashing,LSH),采用随机投影对特征空间进行划分,增大原始空间中相邻的点被划分到相同桶内的概率,实验结果表明这类不依赖数据的方法的有效性与哈希码的长度正相关。学者们提出了一系列依赖数据的哈希算法来生成更加紧凑的哈希码,按照训练数据是否带有人工标签分为有监督方法和无监督方法两大类。
谱哈希[5](spectral hashing,SH)和迭代量化哈希[6](iterative quantization,ITQ)是两种较为经典的无监督方法,前者通过学习原始空间中样本对之间的相似度得到哈希函数,后者采用主成分分析方法,将投影后的二进制码进行正交变换,以最终得到的主成分作为哈希函数。
监督离散哈希[7](supervised discrete hashing,SDH)和核监督哈希[8](kernel supervised hashing,KSH)是有监督方法中较为经典的两种方法,前者使用最小二乘回归和传统的类标签信息固定回归目标,后者提出在核空间处理数据线性不可分问题,学习非线性的哈希函数。
尽管上述方法在图像检索精度上有一定提升,但是文本标注无法描述图像的深层语义信息且存在主观性,为了突破这个困境,研究者们提出使用深度卷积神经网络,同时学习图像特征表示和哈希函数。2012年文献[9]提出的AlexNet模型,2014年提出的NIN(network in network)模型和深层VGG模型都成功地验证了基于深度卷积神经网络的方法在学习图像特征表示上的非凡能力。最早的有监督的深度哈希方法是卷积神经网络哈希[9](convolutional neural network hashing,CNNH),成功结合了卷积神经网络和数据相似矩阵实现图像检索,但是这个方法不是端到端的方法,且矩阵分解消耗大量存储内存,该方法并不适用于大规模图像数据集。针对该问题,学者们提出网络哈希[10](network in network hashing,NINH)方法,该方法以端到端的方式将输入的图像从像素映射到标签,实现了用深度神经网络同时进行特征学习和哈希编码学习。
为了进一步提升图像检索精度,研究者们提出了多种基于深度卷积神经网络的优化方案,深度快速二进制哈希[11](deep binary fast hash,FastH)通过使用一个隐藏层来表示类标签的潜在概念来学习特征,深度语义排序哈希[12](deep semantic ranking hashing,DSRH)通过保留多标签图像间的相似语义信息来学习哈希函数,监督语义保留深度散列[13](supervised semantics-preserving hashing via deep neural networks,SSHD)实现了基于排序的深度哈希算法,深度哈希网络[14](deep hashing network,DHN)通过构造成对标签来学习样本之间的联系。文献[15,16]是神经网络和PCA算法、多尺度平衡算法的结合,解决了低效耗时的问题,深度监督哈希[17](deep supervised hashing,DSH)使用两层循环不重复的生成图像对来学习深层特征。为了更好减小量化损失的负面影响,深度样本对哈希[18](deep pairwise-supervised hashing,DPSH),哈希网络[19](HashNet:Deep learning to hash by continuation,HashNet)通过不同策略表示样本对在汉明空间上的原始关系,通过正则化项显式地惩罚松弛后的量化损失。
上述哈希方法目前存在两个问题:①无法打破松弛-量化所带来的局限性,无法保证松弛后的实数值再量化的结果仍是最佳的;②使用的损失函数大多是把离散优化过程的损失直接转化为正则化向,使得损失被迫接近区间的边界值,导致网络下降梯度小、结果收敛慢。为了解决上述问题,本文提出基于成对标签的深度哈希图像检索方法(deep pairwise hashing with binary restricted,DPHB),该方法直接在汉明空间中设置一些锚点,并约束与锚点越相似的图片到锚点的距离越近,与锚点越不相似的图片距离锚点越远。通过训练神经网络模型来拟合最优哈希码,避免松弛-量化的固有缺点。
实验在两个公开的数据集CIFOR-10和ImageNet-100上与7种具有代表性的方法进行对比,结果表明较当今先进方法检索精度分别提高了2.37%和3.94%,验证了该方法能有效提高图像检索精度。
2 基于成对标签的深度哈希方法
为了有效克服松弛-量化模式的缺点,提出了一种基于成对标签的深度哈希方法,引入锚点的概念,在汉明空间优化哈希码,并设计了一个深度卷积神经网络,同时学习样本特征和哈希函数,通过不断迭代拟合提升哈希码的质量。整个检索工作流程如图1所示,首先通过贪心算法,得到代表锚点的哈希码。然后,通过训练深度神经网络将表示图片的二值码拟合至各锚点附近。网络采用AlexNet框架,并引入哈希层,通过利用图像标签信息学习图像特征,网络在拟合过程中,以汉明空间中的锚点作为监督信息,使用成对损失和均方误差损失计算分类误差和锚点误差,对网络模型进行参数微调。最后,训练好的网络即是本方法中的哈希函数。以小批量图像集作为DPHB模型的输入,对模型的输出采用上述方法量化就得到了表示图像的哈希码,然后采用常见的汉明距离排序或哈希表查询等方法进行快速检索。提出的网络结构如图2所示,基本组件使用AlexNet八层网络结构,AlexNet网络第八层是SoftMax分类层,根据sgn函数分为零一两种结果,现将第八层改为哈希层,用于输出神经网络预测的哈希码。AlexNet中使用ReLU作为CNN的激活函数,验证效果远远好于sigmoid,解决了网络较深时的梯度弥散问题,并且加快了训练速度。网络详细配置见表1。它包含了5个卷积层(Conv1-5)、3个池化层(Maxpool1-3)、2个全连接层(Full6-7),最后一层是哈希层(Hash layer)。本节将详细介绍DPHB方法的3个关键步骤,分别是生成锚点哈希码、损失函数优化、哈希函数学习。

图1 基于成对标签的监督哈希图像检索的工作流程

图2 DPHB的网络结构

表1 DPBH中特征学习部分的配置
2.1 问题描述

2.2 生成锚点哈希码
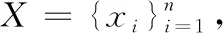
根据最后一步中留下的二进制编码不同,可以得到不同的解,且都是最优解。经算法求证,当k等于10类时,c等于12比特,H等于6时,M集合中共有16个二进制编码,可随机留下其中10个编码组成锚点哈希码;当k等于10类,c等于12比特,H等于7时,M集合中共有4个二进制编码,数量小于k,不能满足解的要求。综上所述,可以很高效地得到锚点哈希码集,给后续神经网络哈希层输出的结果提供参照点,在汉明空间内优化二进制码。
2.3 损失函数优化
在训练深度卷积神经网络时,锚点哈希码的作用是监督网络生成具有强判别力的哈希码,那么如何让神经网络在训练中变得越来越智能,则需要一个优秀的损失函数及时识别出误差,让神经网络各部分在误差反馈下促进工作达到理想状态。于是设计出能够减小相似实例哈希码的汉明距离,增大不相似实例哈希码的汉明距离的损失函数至关重要。

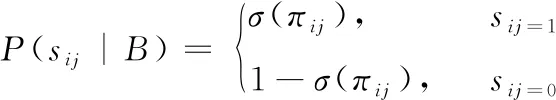
(1)

(2)
其中,λ表示权重。
该损失函数由两部分组成,其中第一项表示成对损失,利用标签信息衡量样本对之间的汉明距离表示误差,第二项表示均方误差损失,衡量神经网络输出的哈希码到锚点间汉明距离表示误差。用成对损失与均方误差损失的加权求和的方式同时考虑两种损失的约束,使得损失尽可能接近最小,神经网络输出的结果尽可能接近锚点哈希码并保持原始空间相似性,最终生成具有高判别能力的哈希码。将函数(2)推导如下

(3)
不难发现,当xi和xj越相似,πij值越大,相似可能性越大,与锚点间损失越小,二者之和越大,反之亦然。由此看来,式(3)能够满足使得相似图片变换得到的哈希码之间依旧保持相似性,相似性在汉明空间中使用汉明距离度量,相似的哈希码在汉明空间中越接近则汉明距离越小。较好地达到成对损失函数的优化目标,对预训练的神经网络调整参数起到了理想的效果。损失函数最终形式整理如下

(4)
其中,λ是权重,这里等于1。
现有工作中,损失函数的优化策略是通过松弛为实值矩阵将二进制代码从离散状态转换成连续状态,严重影响了算法性能。但是式(4)中利用锚点哈希码,很好规避了离散优化问题,可以直接在汉明空间中计算出损失。相比之下,本文提出的损失函数更有利于哈希函数的学习,最终得到的哈希码更具有判别能力。
2.4 哈希函数学习
上述的损失函数仅在样本训练过程中发挥作用,使得神经网络输出令人满意的结果,但是图像检索过程不同于繁琐的训练过程,检索的目的是高效完成以图搜图的用户任务。因此需要让训练后的深度卷积神经网络能够达到哈希函数的作用,能够使得图像经过函数变换成具有高判别能力的哈希码。为了得到用于编码的哈希函数,用θ表示特征学习部分7层的所有参数,xi表示网络的输入,bi表示网络的输出,φ(xi;θ) 表示full 7层输出的图像特征,w∈R4096×c表示权重矩阵,v∈Rc是一个偏执向量,通过一个全连接层将这两部分连接到一个框架中,用包含权重矩阵W和偏执向量V的一个公式实现数据传输
bi=wTφ(xi;θ)+v
(5)
于是,将式(5)代入式(4)可以写成如下形式

(6)


(7)
然后,根据链式法则,利用bi更新参数w、v、θ
(8)
(9)
(10)
最后,该神经网络中各参数可以通过标准的反向传播算法进行优化,神经网络训练结束后,即作为DPHB方法的哈希函数。在图像检索过程中,优化后的哈希函数可以高效的将样本图像生成具有判别力的哈希码,与训练图像哈希码数据库中哈希码进行相似查找操作,最后根据汉明距离排序输出结果。
3 实验与分析
在本小节,利用两个基准数据集CIFAR-10和ImageNet-100,基于平均准确率均值mAP指标验证DPHB方法在图像检索方面优秀的性能。此外,基于其它3项常用评价指标,与7个典型的图像检索方法做了对比实验,所有实验结果均表明了本文提出的DPHB方法优于当前主流方法。
3.1 实验环境与数据集
实验采用预训练模型,使用Pytouch作为模型调参环境,每次初始输入128张训练图像,再以结对的方式两两组合成成对图像作为输入神经网络,采用随机梯度下降(SGD)优化。SGD的学习率为0.05,学习率衰减值为10-7。实验过程使用一块GPU加速,详细的实验机器配置信息见表2。

表2 实验机器配置信息
为了让实验公平进行,选取了两个图像检索领域最常用数据集进行实验。CIFAR-10:CIFAR-10图像数据库共有80 000张小型图像数据集,从10个类中随机挑选6000张图像组成一个60 000张32×32的彩色图像数据集,且每张图像只属于一个类。在实验中,随机在每个类别中选择100张图片(总共1000张图片)作为测试集,每个类别中选择500张图片(总共5000张图片)作为训练集,本文使用一个512维的GIST描述符来表示CIFAR-10数据集的图像;ImageNet-100[20]:ImageNet-100是一个广泛使用的单标签大数据集,它是从ImageNet-1000中提取的100个类别的图像,包含128 503张图像且每张图像只属于一个类别,其中500张作为测试集,128 000张作为训练集。为了减小复现过程中潜在错误导致的不利影响,所有方法仅使用这两个数据集做对比。
本文采用常用的4个指标作为度量标准来评估DPHB的检索性能:平均准确率均值(mean average precision,mAP);查准率-召回率曲线(precision-recall curves,PR);前n个检索结果精度(precision curves with different number of top returned samples,P@N);查询样本和数据集之间的汉明距离小于2的精度(precision curves with hamming radius2,P@H=2)。
根据特征提取方法,以下方法分为两类,分别是传统的手工制作方法和基于神经网络的方法,可以分为4个子类:
(1)传统的无监督哈希方法:ITQ[6];
(2)传统的有监督哈希方法:SDH[7];
(3)提取深度特征的深度哈希方法:FastH[11]、DHN[14]和DSH[17];
(4)成对标签的深度哈希方法:DPSH[18]、HashNet[19]。
实验选取的每种方法都是该类中优秀的方法,沿用所对比得方法使用的网络结构,在同一个网络结构基础上比较方法的性能,实验均在优化的AlexNet网络和两个基准数据集上进行,所有结果均是复现已有研究成果,复现的方法性能略有不同,但性能优次顺序与已有成果的结论是一致的。
3.2 实验结果与分析
具体来说,首先将所有图像的大小调整为224×224像素,然后使用原始图像像素和目标哈希码作为模型输入。为了降低过拟合的风险,在模型初始化方面,与文献[18]的工作是一致的。采用预训练的AlexNet初始化DPHB框架的前7层进行哈希学习。表3列出了8种图像检索方法在CIFAR-10和ImageNet上的mAP结果。
在CIFAR-10数据集上的结果表明,提出的DPHB方法在本质上优于表3中的所有方法。传统的无监督哈希方法ITQ的性能排在最后。SDH是最具代表性的传统监督方法,但其性能仅略好于ITQ方法。DSH、FastH和DNH等基于深度学习的哈希方法在图像检索性能上与传统方法完全拉开了距离。DPHB与主流的基于深度学习的哈希方法相比,在不同长度哈希码的mAP中,与HashNet相比,绝对提升8.65%、4.09%、4.05%、6.09%,与DPSH相比,绝对提升5.98%、5.64%、4.74%、5.16%,DSH方法码长48位时mAP在7种被比较的方法中达到最高,与之相比,DPHB绝对提升2.37%,检索性能优于DSH。对于大规模图像数据集ImageNet-100,表3中的ImageNet-100数据集的实验结果表明,所提出的DPHB方法优于现有的传统哈希图像检索方法。与基于学习的哈希方法(如FastH、DNH和DPSH)相比,DPHB的性能有了显著的提高。与HashNet相比,DPHB在不同哈希码长度的平均mAP中绝对提升41.01%、21.45%、11.95%、3.94%。结果表明,该方法可以生成信息丰富、判别力强的哈希码,从而提高大规模图像检索性能。
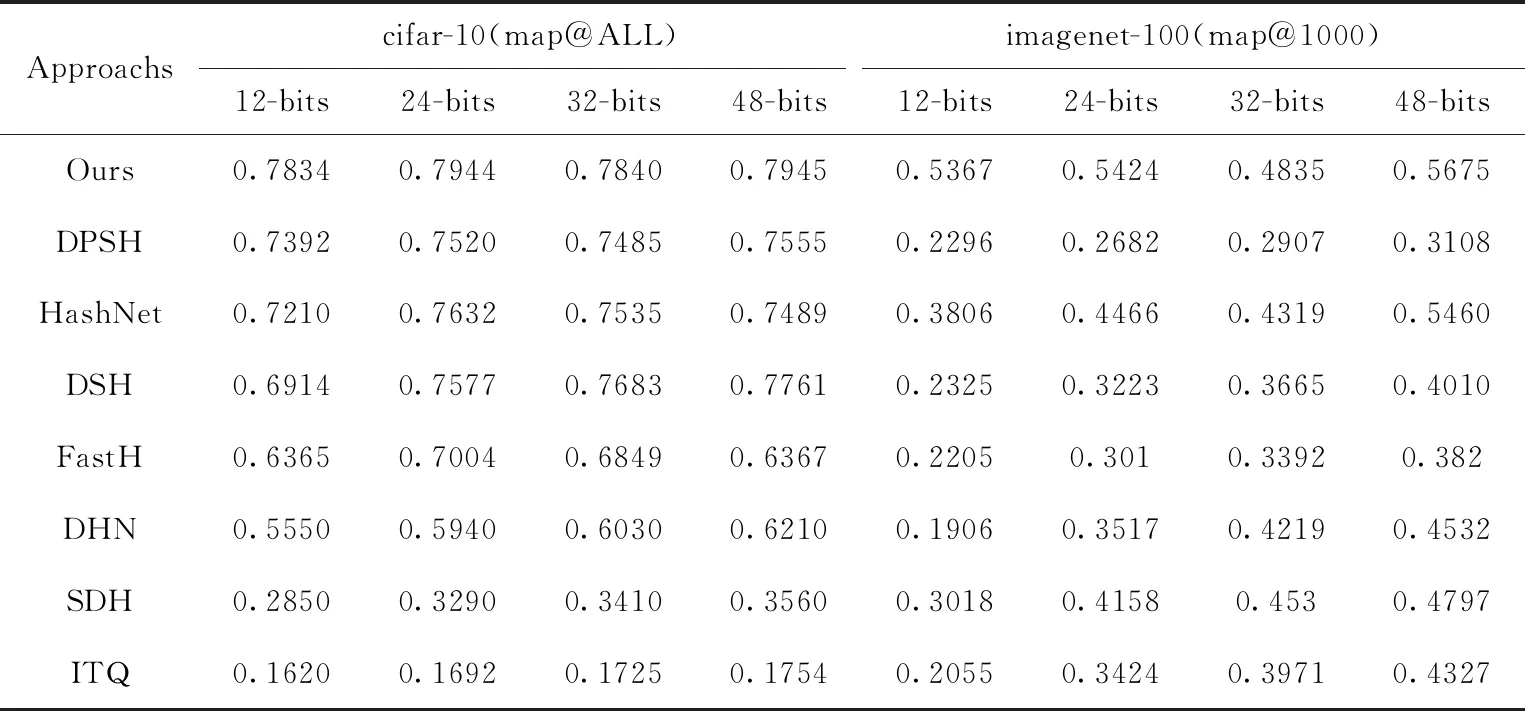
表3 8种图像检索方法在CIFAR-10和ImageNet上的mAP结果
为了进一步验证DPHB的有效性,实验基于其它评价指标做了对比实验。图3表示在CIFAR-10上的结果,图4表示在imagenet-100上的结果,图5表示不同算法模型调参和检索效率。
如图3(a)、图4(a)所示,精度召回曲线(PR)是评价图像检索性能的一个重要指标。DPHB的性能优于与之相比较的模型。图3(b)、图4(b)表示在汉明半径2(P@H=2)范围内的精度,图3(c)和图4(c)分别表示在CIFAR-10上map@ALL的结果和在imagenet-100上前1000个搜索结果的精度曲线(P@N)。DPHB模型在所有被比较的检索方法中取得最佳结果。
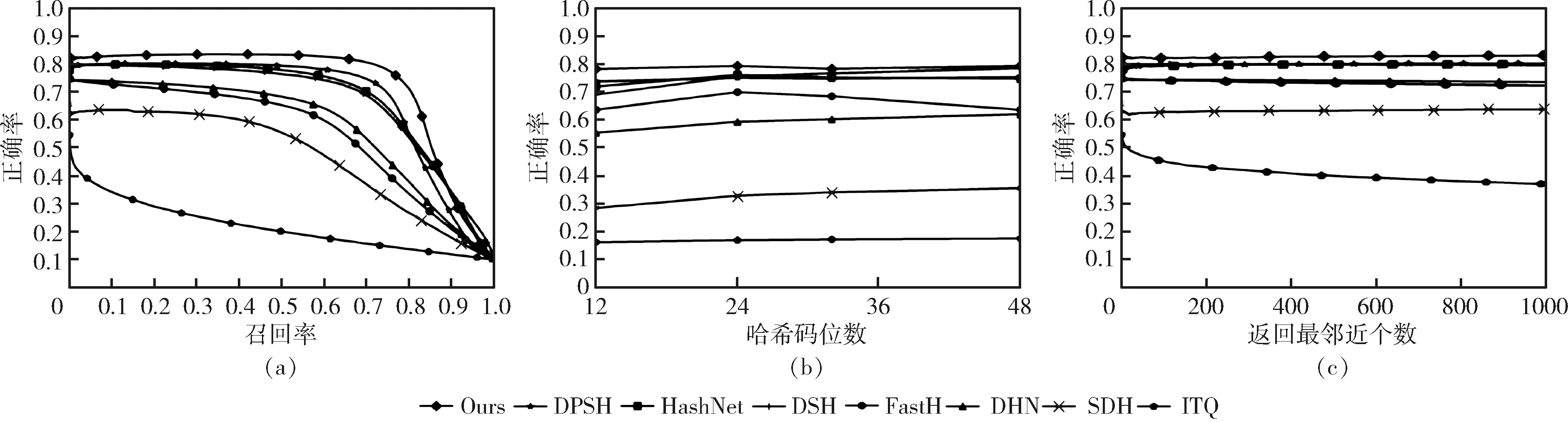
图3 CIFAR-10数据集上的结果

图4 imagenet-100数据集上的结果
如图5所示,分别对6种加入卷积神经网络的哈希模型,统计了调参时间和检索时间,每种方法取5次实验所得结果的均值作为对比结果,避免外部因素影响。图5(a)表示DPHB方法在imagenet-100上不同哈希码位数上的表现,生成24 bit哈希码时,神经网络调参和检索用时最少,效率最佳。图5(b)和图5(c)分别表示采用24 bit在CIFAR-10 数据集和imagenet-100数据集上调参时间和检索时间的表现。通常响应时间小于30 s不会影响用户体验感,由图(5)可知,DPHB算法在CIFAR-10上与其它5种算法效率上无明显差别,但是在大规模图像数据集imagenet-100上,DPHB算法的调参时间明显优于其它方法,检索时间明显优于HashNet、DSH和DHN算法,在实际的图像检索应用中快速响应用户指令,且返回的结果准确率更高。

图5 不同算法模型调参和检索效率
实验结果表明,DPHB相对于以往的哈希算法,在各项评价指标方面都具有理想的检索效果,尤其在高位编码上有明显的优势,在CIFOR_10数据集和ImageNet_100数据集上,DPHB方法48 bit的mAP较其它方法最高结果分别提高了2.37%和3.94%。另一方面,实验验证了DPHB方法所采用的优化策略,有效规避了传统的松弛-量化步骤所带来的负面影响,验证了在汉明空间中以锚点为监督信息的方法能有效减小相似实例哈希码的汉明距离,增大不相似实例哈希码的汉明距离,所提出的损失函数能够使得神经网络的输出更接近锚点哈希码,经过训练的哈希函数能够生成判别力更高的哈希码。通过对DPHB方法检索效率的对比实验分析发现,本文提出的方法较其它主流方法更适用于在十万级数量以上的图片集中进行高精度检索的场景,DPHB在大规模数据集上具有检索结果正确率更高,性能更稳定、检索效率更快等优点,能够高效完成图像数据量日益增长趋势下的图像检索任务。综上所述,DPHB方法能更好地满足当下大规模图像检索的实际需求。
4 结束语
本文提出了一种基于成对标签的端到端的图像检索算法。该算法巧妙的规避了哈希码量化损失的问题,生成的哈希码具有强判别力,使得检索性能有大幅提升。与其它相关方法相比,DPHB的优势主要体现在3个方面:
(1)打破了原有松弛-量化的固定优化模式,引入了锚点信息,直接在汉明空间中度量相似样本间距离,而非松弛到欧氏空间中计算,避免了二次量化造成的语义缺失;
(2)DPHB方法是一个端到端的可以同时进行特征学习和哈希码学习的方法,这个过程极大保留了图像间的语义相似度;
(3)使用成对损失和均方误差损失计算分类误差和锚点误差,同时考虑两种损失,使得图像语义损失更明显,网络输出结果更逼近锚点哈希码,与单纯只考虑一种损失,这样得到的哈希码更具有判别力。
在实际数据集上的实验结果表明,DPHB在图像检索应用方面的性能优于其它方法。此外,下一步工作将DPHB方法用于特定领域的数据集上进行测试,如医学图像,提供机器辅助诊断,来检验DPHB方法的通用性。
