基于互信息的缺陷定位方法
2021-07-21李倩倩牟永敏崔展齐
李倩倩,牟永敏,崔展齐
(北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101)
0 引 言
软件缺陷定位[1](software fault location)是指当软件发生失效时,程序人员通过分析源码找到引发该失效的缺陷代码的行为。传统的缺陷定位技术采用手动设置断点的方式进行调试,但这类方法借助于手工的方法,定位缺陷语句的代价高,同时未能充分利用测试用例的执行行为和执行结果的信息。
目前,缺陷定位方法根据是否需要执行测试用例可以分为:静态定位方法和动态定位方法[2,3];静态定位方法主要采用代码审查的方式,通过对被测程序的内部结构(控制流与数据流等)进行分析从而定位出缺陷的具体位置,动态定位方法则依赖于执行信息进行检测。动态错误定位方法主要包括:基于谓词[4,5]、基于程序切片[6,7]、基于模型[8]、基于数据挖掘[9-12]以及基于频谱的方法等。然而前4种方法由于对测试用例需求量大、时间或空间复杂度高、模型构建复杂等缺点在实际应用中不及基于频谱的缺陷定位方法(spectrum-based fault localization,SFL)。SFL对于测试用例的规模与测试用例覆盖程度十分敏感,同时易受可疑度公式的影响,由此充分挖掘程序频谱和执行结果之间存在的潜在关系,构造合适的可疑度计算公式十分重要。基于此提出了一种基于互信息的缺陷定位方法——MIStar,同时使用西门子数据集进行验证,探究缺陷定位效率,与已有的经典可疑度公式进行对比,实验结果表明,该方法具有良好的定位效果。
1 相关工作
程序频谱是程序在执行测试用例时对于语句的覆盖信息,SFL方法常采用插桩的方法获取程序中语句的覆盖信息,通过分析成功测试用例和失败测试用例在语句或语句块上的覆盖信息,获取语句的可疑度信息或者可疑度的集合。Jones等认为被失败测试用例覆盖的实体较被成功测试用例覆盖的实体有更大存在缺陷的可能性,由此提出了Tarantula怀疑度计算公式,Chen受聚类分析的影响提出了Jaccard怀疑度计算公式,基于分子生物学的研究,Ochiai公式被提出,而后Wong等通过修改Kulczynski系数提出了一种基于相似系数的DStar怀疑率计算公式[2];Yoo等则将遗传规划应用其中,推导出了30个不同的怀疑度计算公式,黄晴雁等[13]通过分析执行信息与执行结果之间的关系,提出了基于条件概率的缺陷定位方法CPStar,取得了良好的定位效果;在使用SFL中,大部分研究员通常使用成功测试用例和失败测试用例二者执行信息,冯潞潞等[14]考虑到SFL算法中偶然性正确测试用例对实验结果的影响,由此提出了一种没有误判率的缺陷定位方法,由此提高了缺陷定位的准确度;王赞等[15]将启发式搜索应用到缺陷定位中,提出了一种基于遗传算法的多缺陷定位方法,并扩展Ochiai系数来计算个体的适应度值从而搜索出具有最高适应度值缺陷分布情况;舒挺等[16]则借助于统计学的条件概率思想,构建了用以量化分析程序频谱和执行结果之间的关系的P模型,由此定位缺陷位置;叶俊民等[17]考虑到语句块的筛序机制会对定位准确度造成影响,提出了一种分层程序频谱的缺陷定位方法,先定位到函数再定位到语句。Chen等[18]特设计了一套理论来评价可疑度公式的优劣;Le等[19]提出了一种多模式技术,同时考虑到错误报告和程序频谱,提出了一种基于信息搜索与程序频谱的缺陷定位方法。
综上所述,已有的方法或是引用其它领域的计算方法进行实验验证可疑度公式,或者挖掘程序本身涵盖的规律,对于可疑度公式的优化中,大多数研究者将重点着眼于执行结果与覆盖信息的关联分析,而忽略不同语句之间存在缺陷可能性的差异,为继续量化程序缺陷可能性,采用分层的思维方式,为每条语句增加权重值,同时引入互信息量优化缺陷定位模型。
2 基于互信息的缺陷定位方法
为了挖掘出程序频谱与执行结果之间的关系,本文将程序实体s的统计信息由一个4元组表示:N(s)=(n10(s),n11(s),n00(s),n01(s)), 其中n10(s),n11(s) 分别表示覆盖程序实体的成功测试用例和失败测试用例,n00(s),n01(s) 表示未覆盖程序实体的成功测试用例和失败测试用例,通过分析各参数的含义,研究人员证明n11(s),n01(s) 越大,语句可疑度越高,n10(s),n00(s) 越大,语句的可疑度越低[2]。
2.1 互信息模型
互信息(mutual information)反映了一个事件的出现对于另外一个事件出现所贡献的信息量,设离散随机变量X=ai,Y=bj,PX(ai),PY(bj), 为其发生的概率,P(ai,bj) 为二者的联合概率,则两个事件之间的互信息量为
(1)
设事件X为语句s是否被执行,X=1表示该条语句被覆盖,X=0,表示语句未被覆盖;事件Y表示执行结果,其中Y=1表示该测试用例为失败测试用例,Y=0,为成功测试用例。互信息的内部函数与外部函数具有相同的单调性,同时对数函数定义域为(0,+∞),所以将新的公式抽象为以下形式:
定义1 在程序运行失败的情况下,语句s被覆盖
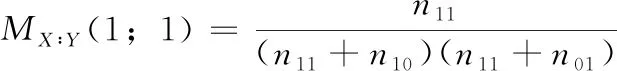
(2)
定义2 在程序运行失败的情况下,语句s未被覆盖
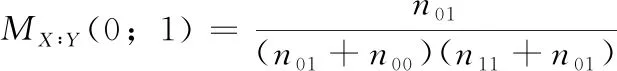
(3)
定义3 程序在运行成功的情况下,语句s被覆盖
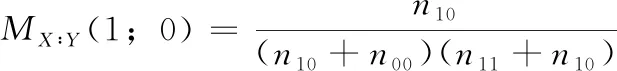
(4)
定义4 程序在运行成功的情况下,语句s未被覆盖
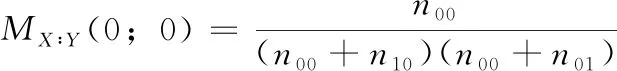
(5)
以上4种模型为程序频谱和执行结果在具体情况下的互信息量的变形公式,由于本文研究建立在既有成功测试用例又有失败测试用例,所以n00+n10≠0,n11+n01≠0; 当n00+n01=0成功测试用例和失败测试用例均未覆盖该语句,n11+n10=0表示所有成功和失败测试用例均覆盖该语句,这两种情况下,该语句的频谱信息均无法帮助缺陷定位,所以不再本文的考虑范围之内。
2.2 示例分析
为直观分析程序频谱与执行结果之间的关系,以一个具体实例进行计算分析见表1,改程序主要功能是求取3个数的最大值,其中代码s2为错误语句,测试用例为t1~t7,表格中1表示该语句被执行,0表示未被执行。通过运行测试用例获得程序的频谱信息,并利用该频谱矩阵统计出四元组信息N(s)=(n10(s),n11(s),n00(s),n01(s)), 统计结果见表2。
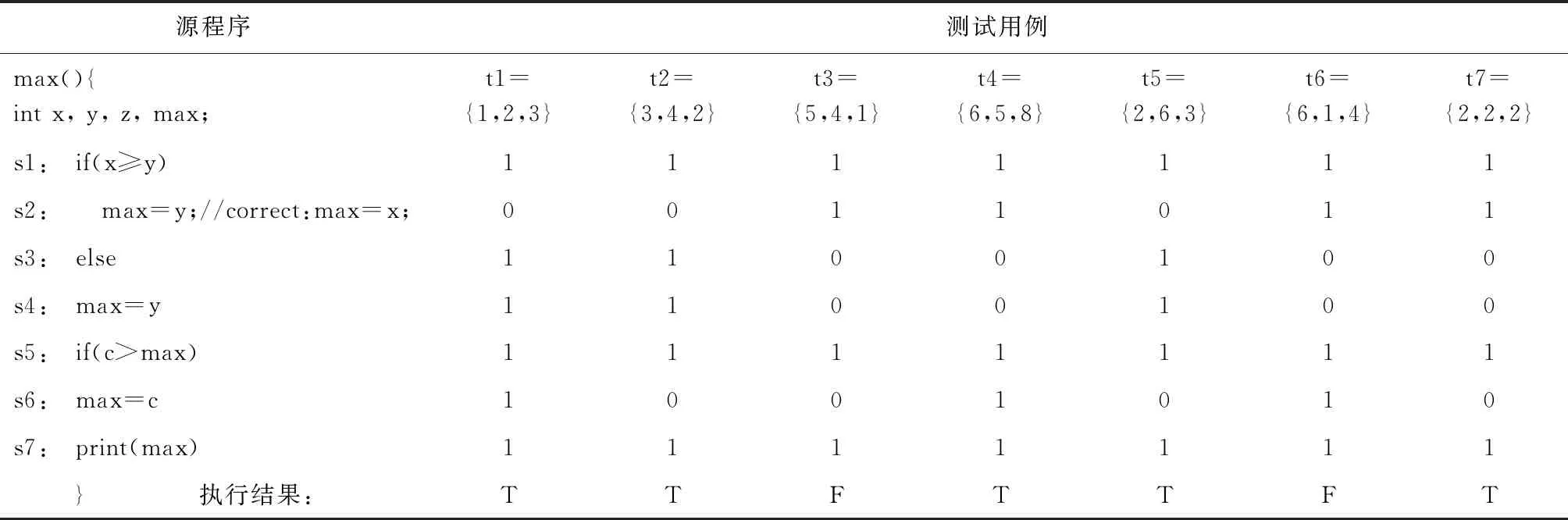
表1 实例程序频谱信息
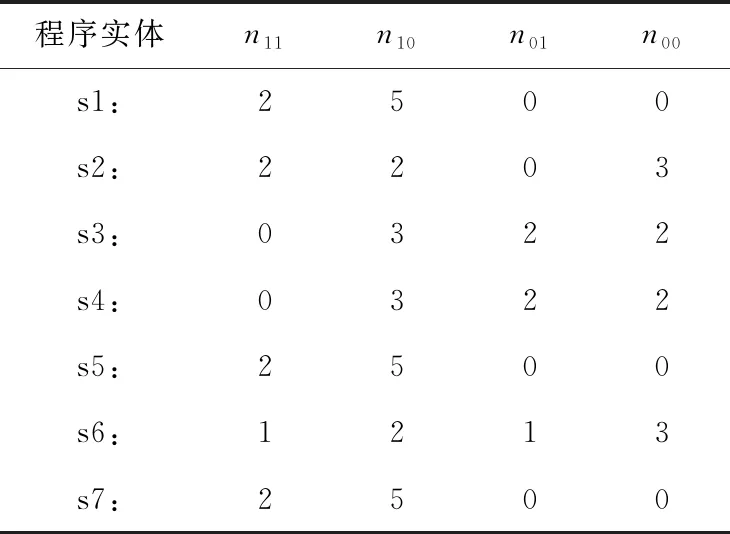
表2 四元组统计结果
根据表2的统计信息,利用M模型可以计算得出相应的量化结果,见表3,其中对应的横杠表示对应的语句该模型无意义。
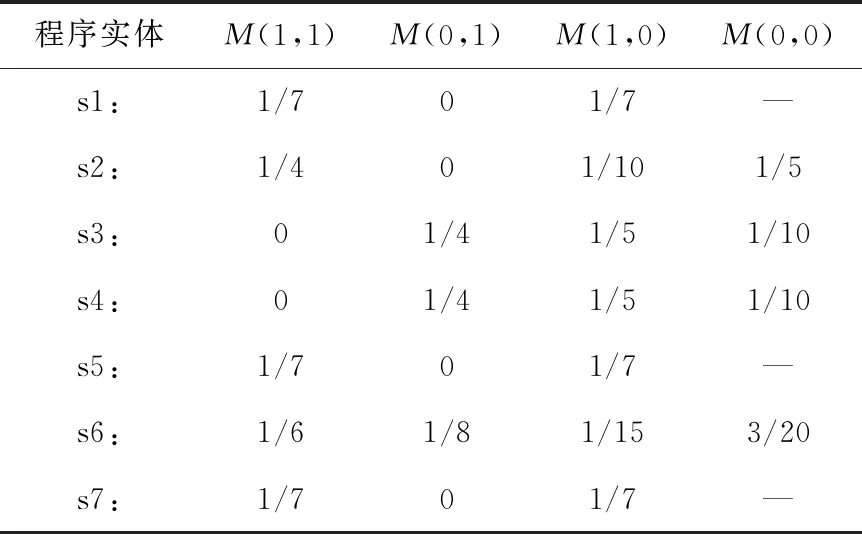
表3 M模型统计结果
互信息反映了一个随机变量由于已知另一个随机变量而减小的不确定性,同时基于频谱方法的假设提出:若语句在失败测试用例中执行较多,则存在缺陷的可能性越大[2],由此提出假设:语句缺陷与M(1,1),M(0,0) 呈现出正相关,与M(1,0),M(0,1) 呈现负相关。具体量化关系通过更权威的数据集进行验证,本文随机选择西门子数据集中部分版本进行实验,计算M模型值,同时以降序对数据进行排序,分析4种M模型值与缺陷语句之间的关系,如图1所示。
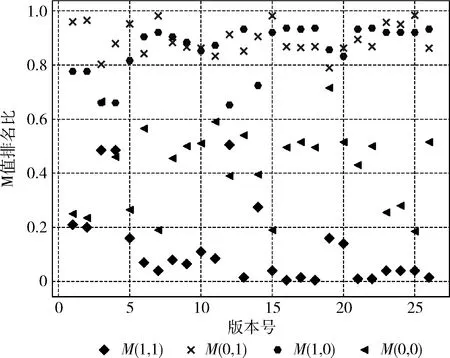
图1 Siemens套件错误语句M模型结果
从图1中可以看出,除去少数离群点外,大多数错误版本中M(1,1) 的统计值错误定位集中在20%左右,M(0,1) 与M(1,0) 则与错误定位值呈现出了负相关,且值大体分布在70%~90%之前,而M(0,0) 的值分布较为分散,分布在20%~60%之间,且分布不是很稳定,原因是:测试用例成功执行,但并非触发了错误语句发生的条件,由此导致结果仍然成功,从而使得M(0,0) 的结果出现波动,未呈现规律性。通过对上述实验的验证,获取了M模型的整体特性,从而为更好挖掘程序频谱与执行结果的关联关系打下基础。
2.3 使用M模型评价经典公式
M模型从更加抽象的角度分析了程序频谱与执行结果的关系,本文选择4个比较经典的怀疑度计算公式进行分析,并将其进行变形,等价于相应的M模型的组合,具体结果如下所示
Ochiai
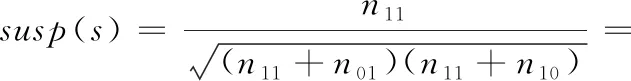
(6)
Tarantula
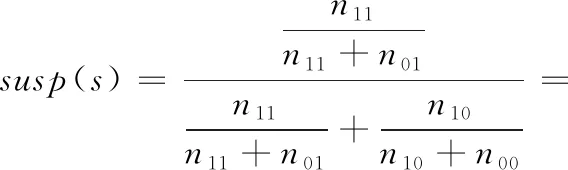
(7)
Kulczynski2
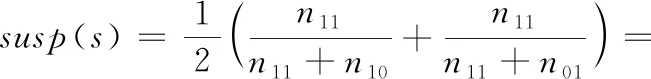
(8)
Ample
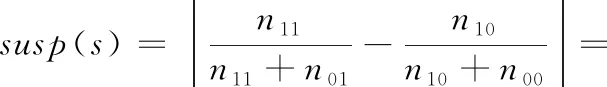
(9)
通过对公式进行变形可以发现:Ochiai值为M(1,1) 与n11的乘积,由M模型的特性可知M(1,1) 在错误语句的排名呈现正相关,同时n11越大可疑度越高,所以Ochiai可以有效定位缺陷,其次M(1,0) 与缺陷语句呈现负相关,所以Tarantula也得到较好验证;n00越小,存在缺陷的可能越大,所以Kulczynski2表现较好;然而n10越大,存在缺陷的可能性越小,Ample算法进行变形之后,加入负相关元素n10,由此导致整个公式的计算效果表现略逊色于其它3类。
2.4 新可疑度公式
2.4.1 新可疑度公式提出
基于对M模型的分析和实验验证,同时使用该模型对经典可疑度公式进行解释,选择了M(1,1) ——该值与缺陷语句可疑度呈现正相关以及与缺陷语句呈现负相关的M(1,0) 作为新可疑度公式的研究基础。通过对经典可疑度公式进行分析,同时结合Wong等[14]提出的n11在可疑度公式应当赋予更高的权重这一假设,受DStar公式的影响,提出了新的公式MIStar(MI*),其中*表示n11的指数范围,取值范围为0~30,实际缺陷定位过程中,传统的缺陷定位方法将所有的语句存在缺陷的概率看作是相同的,然而根据实际的执行情况,每条语句应赋予不同的权值。
目前不少的研究者提出了在函数级别上的缺陷定位,依据分而治之的思想,可以将程序在函数级别上缺定位效果转化每条语句存在缺陷的权重属性,即相同函数下的语句存在缺陷的可能性相同,用wi表示,其中i取值是该程序中函数的个数,新的怀疑度公式表示为
MIStar
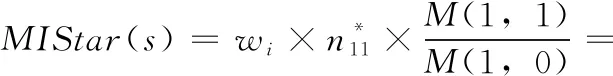
(10)
在实际应用中发现测试用例会影响可疑度公式的准确度,由此选择*系数,增加n11的权重,根据具体问题设定相应参数值,在同一函数中的语句wi的取值相同,即为该函数存在缺陷的概率或者函数的可疑度。
2.4.2 公式边界情况
分母为零情况分析:
若语句n10为0且n11为0,则代表该条语句及没被成功测试用例覆盖又没有被失败测试用例覆盖,该情况不成立,所以二者不可能同时为0,当某一取值为0时,在公式中以1代替,进行计算。
语句s总是被执行:
在该情况下,n00,n01均为0,则公式变形为
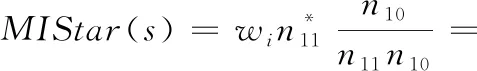
(11)
此时执行信息与否已经无法对定位产生影响,语句的可疑度转化为win11的相应值,每个函数级下的语句无法区分可疑度。
语句s总是不被执行:
在该情况下n11,n10为0,可疑度结果为0,符合常识。
3 实验及结果分析
3.1 实验数据集
本文使用经典的Siemens数据集进行实验,该数据集下载地址为SIR(http://sir.csc.ncsu.edu/portal/index.php),表4中是其信息的具体介绍,包括实验对象名称、功能描述、代码行数、每个对象的错误版本数,以及测试用例的个数。
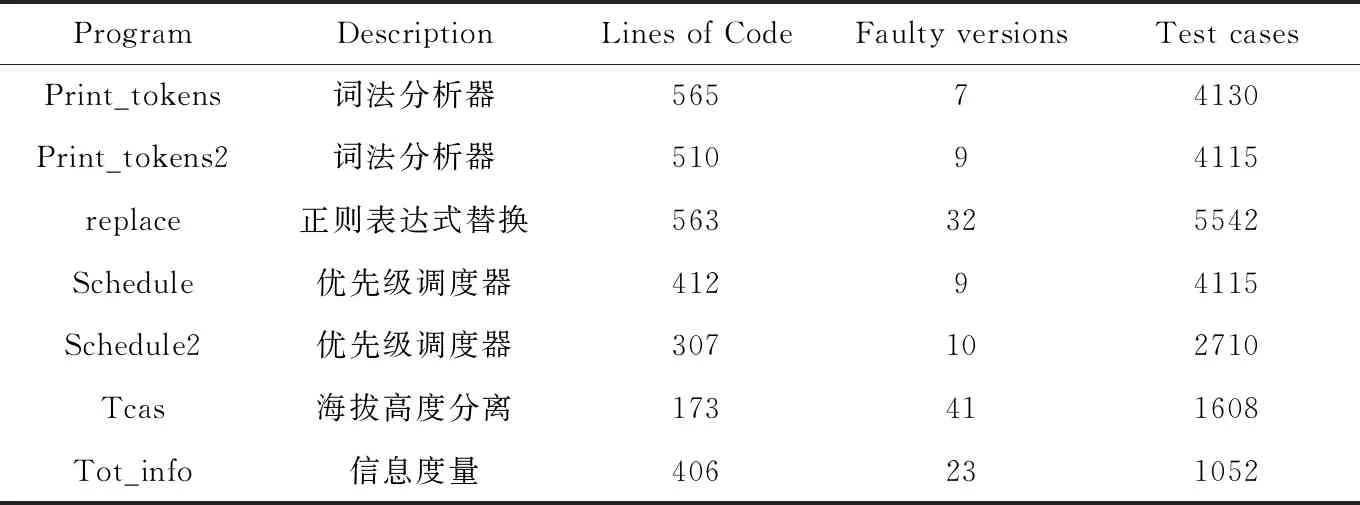
表4 Siemens数据集信息
3.2 实验设计与结果分析
实验设计主要包括两个部分,第一部分是对不确定性参数Star进行选择,确定最优值进行实验;第二部分将MIStar算法与其它经典算法进行对比实验,对定位结果进行分析。评价指标为EXAM,即定位出缺陷语句时需要检查的语句占程序中可执行语句的百分比,根据EXAM指标可知,在相同版本下,EXAM越小,定位的代价越小,效率越高。
3.2.1 Star值对定位效果的影响
本节中,对于Star值的设定范围为0~30,通过采用网格搜索的方式,以0.5为增量进行实验,以每个具体Star值的平均EXAM评价定位效果,实验结果如图2所示。
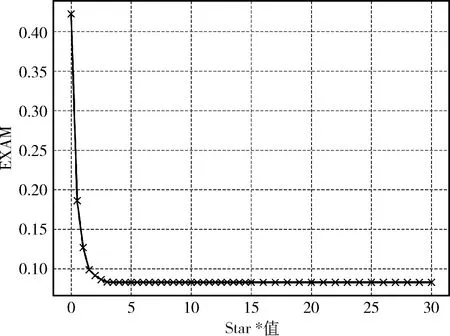
图2 不同Star的定位效果
从图2中可以观察到,检测到错误语句需要检测的代码函数随着Star值增加不断降低,最终趋于稳定。原因在于测试用例的选择会对实验结果产生一定的影响,n11值未能充分反应出缺陷程序的执行信息,由此需要增大n11的比重将错误语句与正确的语句做区分,当*不断增大的过程中,n11的信息与nf(nf表示该测试套件中的全部失败测试用例数目)中的信息逐渐趋于均衡,由此实验效果将不再改变。该次实验中,Star值在3.5时达到平衡,由此选择该值进行实验分析。
3.2.2 MIStar实验验证
为了能够更好分析MIStar的性能,本文选择了6个主流的基于频谱的缺陷定位方法进行实验,其中对于权重值wi的计算依据函数缺陷定位效果中每个函数可疑度排名位置的倒数(排在前面的函数存在缺陷的概率大于后面的函数),本文wi的实验取值参考文献[10]中对于函数级别的缺陷定位实验方法和实验结果,Wong等实验结果表明Dstar算法D3找到第一个故障的效果最好,所以对Dstar算法选择的为D3,实验运行结果如图3所示,其中X轴代表检查的平均代码行数占总代码的百分比,Y轴表示平均发现缺陷的版本数占总版本数的百分比(即错误检出率)。
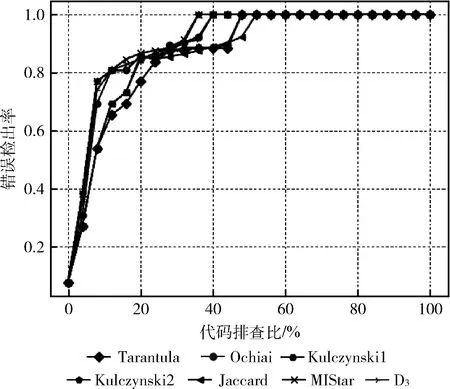
图3 各种方法缺陷定位效果
根据图像可以看出,在初期小于5%的排查量时,MIStar、Kulczynski2的错误检出率最高,其次是D3、Ochiai,而Tarantula和Jaccard表现略次之;在代码排查量在15%左右时,MIStar明显处于领先地位,在代码排查量在30%左右时MIStar、Kulczynski2,D3、Ochiai,Kulczynski1的定位效果都比较接近,同时MIStar在代码排查量35%~40%基本上可定位出全部缺陷,随后其它定位方法随着代码排查量的增加,错误检出率逐渐持平。
为了验证实验的有效性,验证不同方法的平稳性以及平均性能,我们统计了各种方法在实验检测到错误语句时EXAM值的最优值、最劣值、平均值、标准差,见表5。根据统计结果可以发现,Kulczynski2的最劣值达到了最优,MIStar次之,同时MIStar的平均水平仅次于Kulczynski2,然而MIStar的方差较其它缺陷定位方法最小,由此该方法有较好的稳定性。

表5 统计结果对比
4 结束语
基于频谱的缺陷定位方法由于其自身易于实现,时间复杂度低,同时易于开发人员理解等特性,在缺陷定位领域广受研究人员的喜爱。通过探究与量化程序频谱与执行结果之间的关联同时设计出高效的可疑度计算公式,提高定位的准确性是缺陷定位研究的重点。
本文通过引入信息论中互信息量这一概念,挖掘执行信息与执行结果之间的关联关系,同时引入不确定性参数Star来修正n11的权重,考虑到分层策略,引入权重值为每条语句赋值,由此提出了基于互信息的缺陷定位模型——MIStar,在第3章节通过不断修正Star值,同时与经典的缺陷定位方法作对比,展现出来MIStar良好的定位效果和稳定性。
虽然该方法在基准测试程序中展现了良好的表现,但本文中实验对象为中小型程序且为单缺陷环境,实际的开发环境中存在更多多缺陷情形,所以所提方法在实际使用中需要进一步的实验验证和观察。
