冷启动下用户特征模型的构建与个性化推荐
2021-07-21王丽清徐永跃姚寒冰
王丽清,徐永跃,姚寒冰
(云南大学 信息学院,云南 昆明 650091)
0 引 言
互联网推荐系统或推荐方法用于帮助人们在海量信息中快速、准确地检索出所需要的信息。其中,被广泛采用的协同过滤推荐算法可以根据用户的偏好,挖掘用户与对象或对象与内容之间的相关性,继而完成关联性推荐。但协同过滤的稀疏矩阵计算、“冷启动”以及可扩展性问题,造成了它的局限性[1]。
解决“冷启动”问题的关键是解决新用户的初始用户特征模型的建模问题。用户特征模型通过对用户偏好或者特征信息的显示或隐式的采集完成用户模型建模。对于新用户,需要对其明确一个初始特征的定义和采集规则。为此,有的采用平均值、众数、信息熵等数值填充的方法[2],可以对新用户完成推荐,但会导致个性化特征缺失;采用聚类分析[3]、社区发现[4,5]基于内容的推理和协同[6,7]等方法是通过获得最近邻作为新用户初始值完成推荐,可以提高推荐的可扩展性,并一定程度解决初始用户特征提取的问题,但在提高新用户特征的准确描述方面一直是研究的热点;采用用户偏好问卷调查,再结合相似性计算的方式,可以取得更能反应个体主观偏好的推荐结果[8,9]。但受到问卷调查的项目数的影响,操作太多会降低用户体验。
为在冷启动情况下,尽可能完整描述用户偏好,取得满意的推荐结果,本文引入层次分析法(analytic hierarchy process,AHP),通过改进成对比较矩阵的生成,简化用户的在线比较操作,取得新用户的初始主观偏好数据,建立了初始特征模型,并据此完成了基于用户当前位置的周边美食推荐。
1 用户初始特征模型优化构建
对新用户建立初始的美食偏好个性化特征模型,需要对归属于同一大类的待推荐餐饮对象,明确权重因素,并对用户建立权重因素比较矩阵,然后通过计算,得到矩阵的特征向量,这就是该新用户的初始特征值。
1.1 权重因素比较矩阵
在周边美食的个性化推荐中,设待推荐的餐饮目标对象O, 其大类分为“滇味、川味、湘菜、鲁菜、清真、西餐……”,并定义距离w1、 味道w2、 价格w3和卫生w4这4个用户偏好权重因素。
根据层次分析法原理,为建立反应用户偏好的量化特征模型,由用户两两比较4个因素的重要性。将比较结果按式(1)记入,构成该用户的成对比较矩阵X。 式(1)如下

(1)
X为一个正互反方阵,矩阵元素的值按表1通过用户主观比较进行取值。

表1 两两因素比较取值
如果w1与wn重要性比较,wn反过来比w1重要,则为倒数。例如:用户P1的主观调查结果见表2。用户P1认为距离w1与味道w2比较,味道w2比距离w1稍重要一点,取值为1/3;距离w1与价格w3比较,距离w1比价格w3重要,取值为5,以此类推。
由表2得到P1的成对比较矩阵为

表2 P1主观调查-重要性比较结果
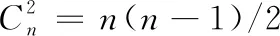
用户主观比较次数多,一方面会导致用户体验差,完成的可行性降低;另一方面还增加了由于成对比较矩阵的一致性不满足而导致失效的概率。而一旦一致性不满足,要不重新让用户比较修改,要不通过计算偏差进行重构[10,11],或采用迭代、极大似然估计或建立扰动偏差矩阵进行修正[12,13]。但这些方法都属于事后弥补,将造成执行效率和用户体验的严重下降。
为降低用户的比较次数,获得满足一致性的比较矩阵,对比较矩阵的生成进行了优化。
1.2 比较矩阵的优化构建
根据成对比较矩阵的构成原理,重要性权重比值为1-9逐渐增强,结合式(1)中的正互反矩阵X, 分析矩阵元素之间的关系,通过推导可以得出:对于两两比较,只需完成第一行a1,1a1,2…a1,n的比较,即可根据式(2)计算得出剩余元素的值,从而得到完整的成对比较矩阵X。
比较矩阵的优化构建式(2)表述如下
(2)
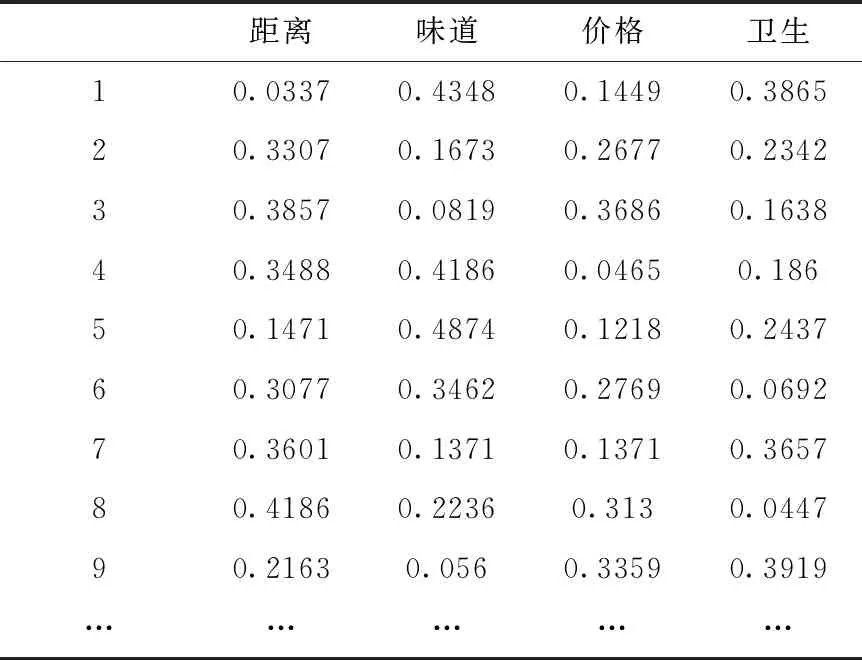
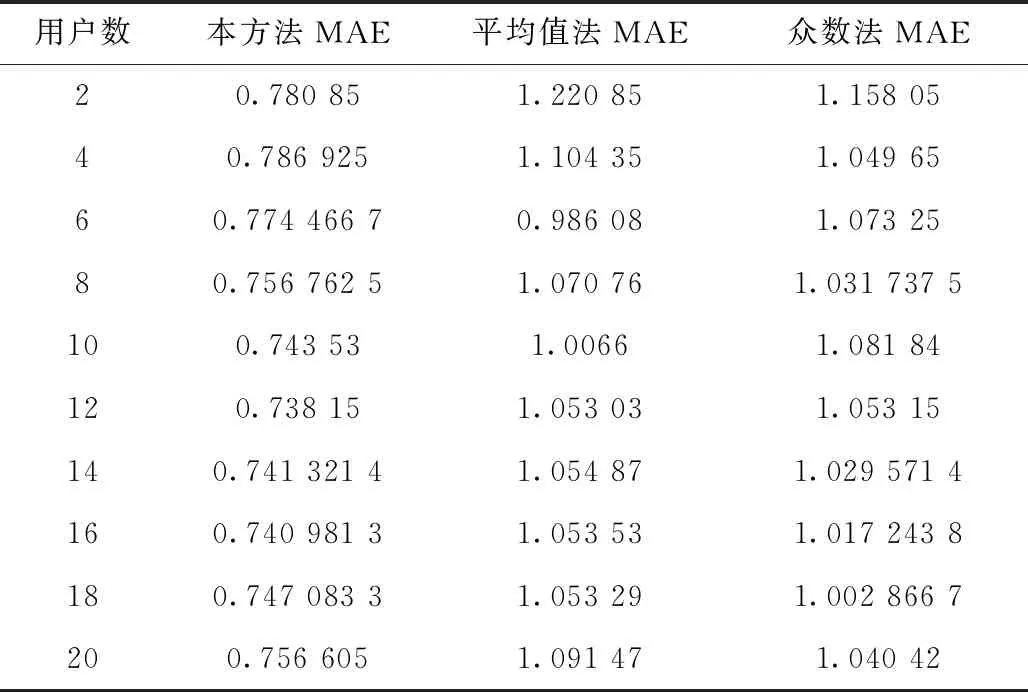
其中, 1 其中,ki,j反应了两个元素之间通过中间元素推导出的大小关系,按式(3)完成计算 ki,j=a′1,j-a′1,i (3) 计算得到的ki,j值,需要进行归一化并映射到权重区间1-9。归一化计算公式如下 ki,j=(|ki,j|-min|ki,j|)/(max|ki,j|-min|ki,j|) 映射公式如下 ki,j=round(1+ki,j*(9-1),0) 这样,即可在已知a1,n的情况下,求出矩阵X的全部元素值。 为验证该矩阵优化构建方法的有效性,需要验证所构成的成对比较矩阵X的一致性。 1.3.1 验证指标 根据层次分析法提出者Thomas L. Satty的定义,矩阵一致性的验证通过式(4)计算矩阵的一致性比率CR完成。当CR小于0.1,则矩阵满足一致性,CR越接近于0,一致性程度越高 CR=CI/RI (4) 其中,CI=(λ-n)/(n-1)。 λ为矩阵最大特征根,n为矩阵阶数,RI按表3取值。 表3 RI取值 1.3.2 验证结果 验证方法是通过对用户P1的主观判断表2,分别采用AHP方法和本文的矩阵优化构建方法构造成对比较矩阵,计算矩阵的一致性比率CR,进行比较。 (1)采用AHP方法,通过如表2的6次比较得到的矩阵为1.1小节中的XP1, 计算XP1最大特征值为 λ=4.1707 对应特征向量 WP1=(0.1980,0.4179,0.0623,0.8845)T 根据式(4)计算得到CR=0.059<0.1。 满足一致性要求。 (2)采用本文所述比较矩阵优化构建方法,通过用户对距离与味道、距离与价格、距离与卫生的3次比较,按式(2)得出矩阵为X′P1 计算得到其最大特征值λ=4.1237 对应最大特征向量为 W′P1=(0.2245,0.6124,0.0692,0.7548)T 计算得到CR=0.04<0.1, 满足一致性要求。 两种方法的比较结果见表4。 表4 两种方法效果比较 从表4看出,采用优化方法构建的矩阵X′P1不仅满足一致性,而且其CR值比原层次分析法确定矩阵的CR值更接近于0,代表其一致性程度更高。 得到特征矩阵后,将矩阵特征向量作为该个体用户P1的特征偏好模型,即可完成个性化推荐。 以下基于该方法,以周边美食的个性化推荐为例,完成算法的比较和验证。 待推荐对象特征信息库即周边餐饮店特征模型库的建立。 根据所确定的4个用户偏好权重因素距离w1、 味道w2、 价格w3、 卫生w4。 距离是用户实时位置与餐饮店之间的距离,需要实时计算。其它因素设定取值规则为通过与平均值作比较的方式取值,取值范围界定为1~9。值越大,表示比平均水平越好,值越小,表示越差。例如:卫生为9,代表卫生环境条件非常好,而价格为9,表示价格非常便宜,价格竞争优势非常大。 所建立的对象特征信息库Catering的主要表结构见表5。 表5 Cartering表结构设计 对待推荐的周边餐饮采集以上数据信息存入数据表,最终完成待推荐对象特征描述信息库的初始建立。其味道、价格和卫生等评价指标后续可根据用户体验和评价进行动态调整。采集的部分美食餐饮商家信息如图1所示。 图1 部分商家特征信息 在推荐时,通过获取用户定位信息,计算出与待推荐目标的距离,结合建立的用户个性特征模型,对待推荐对象信息库进行检索,完成推荐。 2.2.1 位置定位和距离计算 在推荐时,计算用户实时位置与餐饮位置的距离di, 作为推荐特征因素之一。计算时,根据实时获取的用户位置经纬度和餐饮点经纬度,通过计算得到两点间距离,具体计算实现方法见文献[14]。 位置标注时,借助第三方地图API来完成开发。针对不同的第三方地图,由于其坐标系有所不同,需要对实时获取的定位——国际标准坐标WGS84坐标信息进行转换,以适应不同坐标系的要求。例如:腾讯和高德为火星坐标GCJ02,百度为百度坐标BD09。计算时调用地图服务商提供的转换函数接口,完成坐标转换,取得正确的位置标注。 2.2.2 推荐算法 对于用户的初始个性化特征,按1.2节所述方法完成特征矩阵构建,并计算出矩阵的特征向量WPi, 表述了该用户的偏好观点。通过对WPi与待推荐对象特征信息Catering表中各个对象的综合权重计算,按综合权重由大到小的排序结果即是推荐结果。 具体方法如下: (1)计算距离因素d′i 计算用户实时位置和Catering表各个对象之间的距离di。 距离因素表示为各个点到用户距离的相对远近优势,距离越近值越高,表示在距离因素上有优势。并且同样将值映射到0-9的区间。计算距离因素d′i式(5)如下 (5) (2)建立待推荐对象的特征矩阵X′i 取出Cartering表中STasteV(味道)、SPriceV(价格)、SConditionV(卫生)的值作为Ovi Ovi=(STasteV,SPriceV,SConditionV) 与d′i共同构成Xi, 即 Xi=(d′i,Ovi) 然后,对Xi进行归一化计算后,得到矩阵X′i。 例如:取Sid为1~3的记录,距离分别为8、0.1、0.5,则计算得出X′i (3)计算综合权重Si 根据该用户之前得到的特征向量WPi, 按式(6)计算出各个待推荐对象点的综合权重向量Si (6) (4)结果排序 对Si按从大到小的顺序排序,排序结果代表了各个餐饮点满足该用户主观偏好的程度,也就是该用户的推荐结果。 为验证该用户初始特征建模和推荐算法的效果,提取20个用户按本文所述方法建立初始用户特征模型,然后从待推荐Catering表中提取类别为1的记录,用本方法向用户推荐,取排序最大值作为对该用户的最优推荐结果。同时,将结果与平均值填充法、众数法的推荐结果进行比较和分析。 评价指标为平均绝对误差(mean absolute error,MAE)和平均用户满意度(mean user satisfaction,MUS)。 MAE计算公式为 (7) 其中,n为验证用户数,m为权重因素数,Wr为推荐结果的各个权重因素值,Wu为对应该用户主观偏好设定的各个权重因素值。MAE越小代表误差越小,越符合用户的要求。 用户满意度MUS验证是根据用户对各个因素的主观权重大小,比较首选推荐与其它待推荐之间对应因素的排序位置是否最优,给与分值0~4,0表示很不满意,1不满意,2满意,3很满意,4非常满意。MUS值越大,代表用户满意度越高。 MUS计算公式为 (8) 其中,n为验证用户数,Si为该用户的满意度分值。 实验中用到的部分用户特征数据见表6,部分餐馆对象特征数据见表7。 表6 实验用部分用户特征 表7 实验用部分Catering特征 按照本文方法计算得到的各个餐馆针对各个用户的综合权重见表8,按表8对每个用户排序得到用户的首选推荐结果见表9。与平均值填充法所得推荐结果的MAE和用户满意度MUS比较结果见表10、表11。 表8 餐馆对应不同用户特征要求的综合权重值 表9 推荐结果对应 表10 3种方法的MAE值 表11 3种方法的MUS值 表10、表11转换为折线图如图2、图3所示。 图2 MAE实验结果 图3 用户满意度实验结果 由图2平均绝对误差实验结果可以看出:本方法建立用户初始特征得到的推荐结果,其MAE平均值为0.76,平均值填充推荐方法的MAE平均值为1.07,众数法MAE平均值为1.05,误差分别降低28.97%和27.62%。此外,本方法误差曲线很稳定,近似于直线,说明面对不同用户的差异化需求,本方法的推荐很好地反应了用户的个性化特征,所得结果与用户需求的差距控制在0.8以内,更符合用户的独特主观要求。 从图3用户满意度结果来看,本方法推荐结果的用户满意度平均值为3.76,平均值填充法满意度为2.32,众数法为1.7,本方法满意度明显高于平均值法和众数法,可以取得用户更满意的推荐结果,原因在于其它方法没有针对每个用户提取个性需求。 本文提出的个性化推荐方法是通过将用户的主观意向选择,根据改进的特征矩阵优化构建方法,用最少的用户输入,建立量化特征模型。然后,据此计算待推荐对象特征值的综合权重,按权重从高到低排序,得到满足用户个性需求的推荐结果。 在用户个性化特征矩阵的生成中,采用本文方法,对于有n个权重因素的个性推荐来说,用户主观比较次数从n(n-1)/2次,下降为n-1次,有效地简化了用户的输入操作,提高了效率。 研究结果表明:本文所述方法能够在冷启动情况下,建立出能够准确反应用户主观偏好的用户特征模型,取得满意的推荐结果。对于解决冷启动情况下用户初始特征模型的生成和个性化推荐具有借鉴意义。 在实际应用中,根据用户体验数据、评论分析等获得更精准的动态数据,不断更新待推荐对象特征信息库,可进一步提高推荐的实效性、准确性。 此外,本方法主要用于冷启动下的个性推荐,随着系统使用后用户数据的不断丰富,可引入更多方法实现个性化的混合推荐,以满足用户复杂多变的推荐需求。
1.3 一致性验证


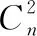
2 周边美食的个性化推荐
2.1 待推荐对象特征信息库建立


2.2 位置相关的个性化推荐

3 推荐结果与分析
3.1 实验数据与评价指标

3.2 实验结果和分析





4 结束语
