基于AWGR的动态光网络及拓扑映射
2021-07-21范修宏臧大伟
范修宏,臧大伟,程 东
(1.中国科学院 西安光学精密机械研究所,陕西 西安 710119;2.中国科学院 计算技术研究所,北京 100190)
0 引 言
现在的数据中心广泛使用虚拟化技术,为了高效利用数据中心的物理资源,需要将尽可能多的虚拟拓扑映射到数据中心物理服务器和网络链路上运行。然而,由于资源量及映射算法的不足,经常会发生虚拟拓扑映射失败的问题,据统计有99%的不成功映射是由于虚拟链路无法映射引起[1]。当前数据中心网络缺乏弹性,是导致虚拟链路无法有效映射的主要原因,造成了数据中心硬件资源的极大浪费。光交换技术具有很强的灵活性和极低的能耗[2],非常适合用来增强数据中心网络的弹性。
基于网络结构与映射算法协同设计的思路,本文提出了一种基于AWGR器件的光电混合网络结构和面向此弹性网络的虚拟拓扑映射算法。主要创新点在于,利用灵活可变的光域网络,通过改变波长调整网络之间的连接关系,重新分配链路的资源,从而提高数据中心的资源利用率和能效。模拟评测结果显示,该方法可以极大提高数据中心的资源利用率和收益。
1 相关研究
在光电混合数据中心网络结构研究方面,当前大量的研究试图结合高带宽的光域交换技术和高灵活性的电域交换技术,如c-Through,Helios,DOS,Proteus[3-5],Petabit Optical Switch[6]等经典的光电混合网络结构。c-Through是一种基于慢速MEMS交换机的光电混合网络结构,它在电域树形网络的基础上增加一个光域交换机,每一个机柜中的柜顶交换机同时连接到电域网络和光域网络,大流量的网络流在两个机柜之间的光链路上传输。在运行过程中,流量监控系统根据任意两个机柜之间的带宽需求,形成一个带宽需求矩阵;为了提高光链路的带宽利用率,光线路的配置转变成一个最大权值的完美匹配问题,使用Edmonds算法来求解匹配结果,并配置MEMS光交换机,重构光网络的连接关系,然后使用基于VLAN的路由方法将ToR中的流量分配给电域网络和光域网络。但是,该结构使用的MEMS交换机,配置延迟达到秒级,只适合处理持续时间达到数秒钟的网络流,而不能加速持续时间较短的网络流。
如何利用光电混合网络的灵活性,高效、动态地将用户需求映射到物理拓扑是另外一个核心问题,可以分为在线映射算法和离线映射算法两种。在线映射算法[7]为随机到达的虚拟网络请求给予资源分配,当虚拟网络拓扑运行结束后,其自动将资源回收。离线映射算法已知虚拟拓扑映射请求的一些详细时间,对一段时间内收集到的虚拟拓扑请求进行集中的处理,由于虚拟拓扑一般需要长时间运行,本文所提出的方法为离线映射算法。按照虚拟拓扑映射计算方式的不同,映射算法分成集中式映射[8]与分布式映射[9]。集中式算法会在一个或几个中心点上计算映射方式,由中心点负责资源的分配;而分布式算法将计算任务分配到若干的节点,由若干的节点共同来完成资源分配和拓扑映射。按照虚拟节点与链路处理的处理顺序不同,将映射算法分为一阶段映射[10]和二阶段映射[11]。一阶段算法同时映射虚拟节点和虚拟链路;而二阶段映射算法通常先进行节点的映射、后进行链路的映射,本文提出的算法是一种二阶段的映射算法。当前的研究主要在电域网络上来进行拓扑的映射,例如文献[12]提出了一种二阶段的虚拟拓扑映射方法,在虚拟节点映射阶段,采用贪婪算法将资源约束高的虚拟节点优先映射到资源量大的物理节点,同时使用路径分割的算法VNE-Splitting,将同一条网络流分散到多条路径上运行。这种方法提高了映射的成功率但需要特殊的硬件支持,并会产生网络包乱序的问题。文献[10]提出了一种一阶段的虚拟拓扑映射算法,它将问题归约为一个SID(subgraph isomorphism detection)问题[13],并提出了一个启发式的算法来寻找Isomorphism图,该方法可以取得很好的收益,但是仍然是针对纯电域网络。
同时也有研究试图在光域中映射虚拟拓扑,例如文献[14]。但是它们通过波长的分配来动态变化链路的带宽,而不会通过桥接光链路来降低网络直径,并不能有效增加数据中心的收益。
综上所述,当前的研究中并未将光域桥接网络用于虚拟拓扑映射的研究中,本文具有前瞻性和创新性。
2 数据中心资源形式化
在数据中心运行过程中,每个虚拟拓扑请求不仅包含如计算能力、放置位置等节点资源约束,还包含带宽、延迟等链路资源约束。所映射到数据中心中的虚拟拓扑,可以共享相同的底层节点的计算资源和链路资源,而不能采用独占模式。本节中给出虚拟网络映射问题的形式化描述,并给出该问题一些评价指标。
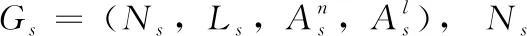
假设每一个虚拟拓扑映射请求中只包含一个虚拟拓扑,因此可以用三元组V(i)(Gv,ta,td) 表示第i个虚拟网络请求,其中Gv表示此请求包含的虚拟拓扑。当ta时刻,虚拟拓扑请求到达时,数据中心需要为此虚拟网络分配满足节点和链路资源约束的物理资源,在虚拟网络运行持续td时间后,虚拟网络运行完成,其占用的相应资源被释放。如果请求到来时,没有足够的资源分配,则将该请求放在等待队列中,或直接拒绝映射。
3 基于AWGR的光电混合网络结构
光电混合网络充分利用灵活可变的光域网络,从物理链路层改变数据中心网络的拓扑架构,从而可以实现网络资源的灵活调度和分配。本文所基于的数据中心物理网络包括两部分,分别为固定拓扑的电域网络和动态可变的光域网络。固定拓扑的电域网络可以采用任意的拓扑结构如Fat-tree,Torus,Mesh等,同时电域网络根据自己的拓扑结构均匀的分成若干的区块,例如在树形拓扑结构中,每一个机柜就是一个区块,区块的数量与所采用的光交换机的端口数相等。在每一个区块中选择一个具有最大通信能力的物理位置作为光域网络的连接点,例如在树形拓扑中的连接点就是ToR(top of rack)交换机的上行端口,而在Torus拓扑中,可以是区块中任意得到一个点,如图1所示。

图1 动态光电混合网络实例
在该结构中使用了多种光器件:首先是TWC(tunable wavelength converters)可调波长光调制器,它将输入的光信号变换成给定波长输出;目前的160 Gbps的波长转换带宽[15]的TWC已经商用,其重构时间只有十几个纳秒。其次是AWGR(arrayed-waveguide grating router)光波长路由器,它根据光的波长进行路由,允许不同输入端口的光线路由至同一输出端口;由端口i输入的波长为w的信号将被路由 [(i+w-2)modN]+1 端口,其中N是端口数;基于这种特性,同一输出端口可以接收不同波长的多个光信号,并复用在一条光纤上输出,而不发生网络竞争,当前高维度的512端口的AWGR器件技术已经成熟。最后是用于接收端光电转换的OCA(optical channel adapter)器件,在接收端它会将光信号变成电信号;OCA器件有一个1:N的多路解复用器,可以将光纤中混合光信号分离成多束单波长的光信号,并由后端的接收阵列将这N个光信号转换为电信号。
在光电混合网络结构中,采用一个单层的光网络作为电域网络的辅助网络。如图1所示,每一个ToR交换机分别通过电域接口和光域接口连接到上层的电域交换机和光域交换机,光域端口的发送链路通过TWC光器件连接到OCA器件的输入端(Tx),接收链路连接到OCA器件的接收端(Rx)。
在控制层面,系统有一个集中的控制器,负责带宽需求测量、链路仲裁控制和链路重构控制。在运行时,控制器收集系统中的拓扑映射请求信息,同时控制每个TWC波长变换器件和电域交换机的路由器件,根据链路匹配算法在两个机柜间建立一条持续的光链路。
该光电混合网络结构与c-Through、DOS等有相似之处,但是有着本质的区别:与经典光电混合网络c-Through相比,同样在机柜之间建立起一条较持续的光线路,属于光线路交换(OCS)的范畴;但由于系统中使用了TWC变换器件纳秒级的波长变换特性,可以快速切换光线路,使用网络能够按照网络流量特征实时、快速重构。
4 虚拟拓扑映射算法
在虚拟拓扑映射过程中,分为节点映射、网络分割、链路映射3个步骤,本文依次对3个步骤所采用的算法进行介绍。
4.1 虚拟节点映射算法
本文使用两阶段映射算法来完成虚拟拓扑的映射,即:首先根据虚拟节点的资源需求将虚拟节点映射到物理节点,然后再完成虚拟链路的映射。我们采用贪心策略完成虚拟节点的映射。在算法运行之前,会收集较长时间窗口内的虚拟拓扑映射请求,并将其放在等待队列中,如果请求队列中的某个请求较长的时间没有得到响应,则删除这个请求。
在算法运行时,首先会按照虚拟拓扑的收益将虚拟拓扑请求按照从高到低排序,优先映射具有高收益的虚拟拓扑。然后,对于每一个虚拟拓扑中的虚拟节点按照对计算能力的需求程度排序,优先对计算能力需求高的虚拟节点进行映射。定义3个公式
(1)
(2)
Tpb=αRp+(1-α)Rb
(3)
其中,Rp表示物理节点所拥有的计算能力与虚拟节点需要的计算能力的差值,Rb表示物理节点所拥有的网络带宽总和与虚拟节点需要的网络带宽的总和的差值,在选择物理节点的时候,必须要满足这两个值大于0。而Tpb是计算能力差值和带宽差值的一个和,根据计算资源和带宽资源的昂贵程度来调整此值,并选取值最小的节点作为映射节点以保证尽可能的将虚拟节点映射到与其需求资源量相当的物理节点上。
算法1:虚拟节点映射算法
输入:虚拟映射请求
输出:虚拟节点位置
(1)按照收益高低排列虚拟拓扑请求;
(2)从队列中选择一个具有最高收益的虚拟拓扑映射请求VR;
(3)将此虚拟拓扑请求中虚拟节点按照计算资源需求排序;
(5)在物理拓扑中寻找物理节点ns满足如下条件
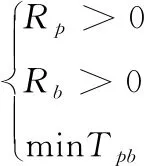
如果有节点无法满足此限制,则从队列中删除虚拟拓扑请求,并放在等待队列中,GOTO步骤(2);
(6)GOTO步骤(4),直到所有的节点映射完成;
(7)GOTO步骤(2),直到所有的请求被映射完成;
(8)算法结束。
如果有任何一个虚拟节点不满足上述条件,则映射失败并将已经映射的节点恢复至原状态,同时将此虚拟拓扑映射请求放到等待队列中。
4.2 光域拓扑重构
将虚拟节点映射到物理节点上之后,需要根据一定的规则对数据中心的光域网络拓扑进行重构,在不同的区块间建立快速的光链路,以便之后将虚拟链路高效的映射到物理拓扑上。
算法2:光域网络重构算法
输入:带宽需求
输出:光交换机的连接关系
(1)虚拟节点映射完成后,统计物理节点两两之间的带宽需求量,形成矩阵M;
(2)对于数据中心中任意两个区域,根据M计算两个区域之间的加权带宽消耗并形成加权带宽消耗矩阵M′;
(3)在加权带宽消耗矩阵M′上使用Edmonds’算法,根据不同区块之间的带宽消耗值计算出一个完美匹配;
(4)根据计算所得的完美匹配结果,控制光交换机在不同的区域间构建光域网络拓扑。
定义物理拓扑中两个区块之间的加权带宽消耗如式(4)所示
(4)
在算法中,统计任意两个区域之间的物理节点的通信总量,形成加权带宽消耗矩阵M′。为了构建光域拓扑,使尽可能多的流量在光域网络上传输,光线路的配置可以归约为一个匹配问题,在本文中使用Edmonds’算法在若干的区域中计算出一个完美匹配。计算出完美匹配后,控制TWC改变波长,实现光域网络的构建;在重构过程中,对应链路中所承载的网络流需要调度到其它链路中,防止重构过程中的丢包。
4.3 虚拟链路映射算法
在虚拟节点映射到物理节点及光域拓扑建立完成之后,将虚拟链路映射到实际的物理链路上。在虚拟节点固定的情况下,求解将虚拟链路映射到物理链路上的最优解可以归约为不可分割流问题(UFP),这个是NP-hard[16,17]问题。
本文中使用贪心策略,首先映射产生最大收益的拓扑的虚拟链路;映射每一条虚拟链路时,在虚拟节点映射到的两个物理节点之间寻找一条满足资源限制的最短路径。对于同一个虚拟拓扑映射,优先映射带宽需求最大的链路;如果没有找到满足资源限制的k-shortest path,则将该虚拟拓扑映射请求放入等待队列中,并删除已经映射的虚拟链路和顶点。
算法3:虚拟链路映射算法
输入:物理节点带宽需求
输出:链路映射关系
(1)构建物理节点邻接矩阵Mj, 标示节点间的邻接带宽;
(2)将完成节点映射的虚拟拓扑映射请求按照收益由高到低排列;
(3)选择具有最大收益的虚拟拓扑映射请求,如果没有,则算法停止;
(4)将选择到的虚拟拓扑中的虚拟链路按照带宽需求由高到低排序;
(5)选择带宽需求最大虚拟链路开始映射;
(6)对于每一个虚拟链路映射请求,通过递增k,寻找两个物理节点之间的k-shortest path,并且该路径满足B(ps)≥B(pv) 如果找到这样的路径,将虚拟链路映射到此物理链路,并更新临接矩阵Mj。 GOTO步骤(5);
(7)如果没有找到这样的路径,则删除此虚拟拓扑请求,并放入等待队列中,GOTO步骤(3);
5 系统评测
本部分将对提出的结构和算法进行评测,首先介绍评测所采用的拓扑生成、算法模拟等工具,然后通过实验结果对其进行评价。在评测中,关注点在于使用动态光链路对虚拟链路映射性能和收益的提升。
5.1 评测指标
虚拟拓扑映射的主要目标在于提高数据中心物理资源的利用率,为更多的虚拟映射请求提供服务,从而提高数据中心的收益。对虚拟网络映射的评价主要有:①物理拓扑的长期平均运营收益;②物理资源的有效利用率;③虚拟拓扑映射请求的接受率[1]。接受并映射一个虚拟拓扑的收益可以定义为式(5),其中P(nv) 表示虚拟节点nv的计算能力需求值,B(lv) 表示虚拟链路lv的带宽能力需求值,nv用来调节计算资源和带宽资源收益的相对权重。根据式(5),我们可以定义物理拓扑的长期平均运营收益为长时间的运营收益总和与运营收益的比值,如式(6)所示
(5)
(6)

(7)
(8)
虚拟拓扑请求的接受率不仅可以衡量物理拓扑资源的有效利用率,而且也是衡量映射算法是否高效的一个重要指标。虚拟拓扑请求的接收率定义为长时间内被成功映射的虚拟拓扑数量Vs与虚拟拓扑请求总数V的比值,如式(9)所示
(9)
5.2 评测参数设置
为了对本文提出的结构和算法进行评测,设计了一个光电混合网络模拟器对网络结构和映射算法进行仿真。模拟器根据提供的节点和链路关系,自动构建物理拓扑结构;在模拟映射过程中,它根据设置的随机函数,生成若干的虚拟拓扑映射请求,并使用如上所示的算法执行虚拟拓扑的映射;在映射完成后,模拟器会统计接受率、链路资源利用率、节点资源利用率等信息。
由于本系统不针对于任何的特定拓扑结构,因此使用随机拓扑来进行评测,其中使用GT-ITM工具[18]来生成随机物理拓扑结构,所有物理拓扑的规模是变化的,而光域网络的链路节点也随机在物理拓扑中分布。模拟器会随机产生若干的虚拟拓扑映射请求,其中虚拟拓扑中虚拟节点的数目满足2至50间的均匀分布,每一对虚拟节点之间以0.5的概率具有一条虚拟链路相连,因此每一个虚拟拓扑中边数的期望值为n(n-1)/4。 每一个虚拟拓扑中的虚拟节点对计算能力的需求满足10至100间的均匀随机分布,每一条虚拟链路的带宽需求满足0至60的均匀随机分布,同时定义收益公式中的调节参数α=0.8。
5.3 评测结果
本文与之前的工作的最大不同之处是将灵活的光域网络与拓扑映射算法协同设计,克服以前固定拓扑不能有效映射网络拓扑的问题。在评测中以系统的收益为评价的标准,首先评测高速桥接链路对收益的影响。
在评测中以文献[19]中提出的完全贪心算法作为基准算法,在评测中固定光域网络的连接点的个数为N/25, 其中N为物理节点的个数,因此光域网络的节点会随着物理节点数的增加而增加。
从图2所示的评测结果可见,与基准算法相比节点映射算法在没有光网络的情况下所获得的总收益是基准算法的1.3倍;而如果增加光域拓扑结构之后,系统所获得的总收益是基准算法的2到3.1倍,并且随着物理节点数目和规模的增加,拥有光域网络的系统可以获得更大的收益,这主要是由于光域网络缩短了网络直径,可以接受更多的虚拟拓扑映射请求。

图2 不同结构下节点数量与收益关系
同时,在此评测了光域网络的规模对收益的影响,在评测中电域网络选择了3种不同的规格,分别为1000、2000、3000节点;在评测中,以节点数为1000的物理拓扑作为基准,在不同的光域拓扑规模下分别评测收益率的变化。评测结果如图3所示,对于同样数量的光域网络接入点,增加电域网络的规模不会使收益有倍数的增长,并且随着物理拓扑规模的增长这种损耗就更加明显,物理拓扑节点数为2000时,总收益能达到节点数为1000时的1.9倍,而物理拓扑节点数为3000时,总收益只能达到节点数为1000时的2.75倍。这主要是由于在光域接入点数量相同的情况下,随着物理节点数的增加使每个分区的规模变大,光域网络对映射的效果的加速作用减弱。

图3 不同规模拓扑收益与光节点关系
我们评测了在不同情况下物理节点的资源利用情况,在与测试1中我们使用了相同的参数,从图4的测试结果可见,在有光域网络的情况下,节点的利用率会有倍数的提升,这一趋势与总收益的增长有类似的趋势。这主要是由于评测中采用的收益因子为0.8,在数据中心中最主要、最昂贵的资源是计算资源,因此随着物理节点资源利用率的提升,其收益也会相应提升。

图4 不同结构下节点数量与利用率关系
在当前数据中心中随着节点数增加和网络半径的增大,节点之间的通信需要经过若干次的电域交换机,期间伴随多次光电转换。在本文所提出的光电混合网络结构中,由于光线路在不同网络区间中采用光构建了一条桥接链路,因此可以减少光电转换的能耗。如图5所示,对网络的能耗情况进行了统计,在此假设数据包每经过一级光电转换消耗一个单位的电能。图5数据显示,随着网络规模的增加,光电混合网络的节能效果快速显现,当节点规模达到3000时,最高能节省22%的光电转换次数。

图5 不同规模拓扑能效统计
最后,评测了虚拟拓扑映射的拒绝率,相对于纯电域网络,光电混合网络中将虚拟拓扑请求拒绝率由23%降低为8%,大概有两倍的性能提高。
综合上述,采用灵活光域辅助网络的光电混合网络结构在数据中心利用率、收益和拒绝率方面都有很大的提升。
6 结束语
随着数据中心规模的增长,同一个虚拟拓扑中虚拟节点所分别映射到的物理节点间的距离越来越远,其链路在映射过程中需要经过若干的跳步,占用了大量的物理网络资源,因此降低了数据中心的收益。以前工作通过优化网络映射算法来提高收益,但受到数据中心固定拓扑的限制,很难取得较好的提升;本文将光电混合动态网络与映射算法协同设计,提出了一种基于AWGR的动态光网络和对应的虚拟拓扑映射方法,该方法在当前数据中心的电域拓扑的基础上,增加一层线路交换的光域网络拓扑,在数据中心全域通过光域网络来减少网络直径;结合与之匹配的虚拟拓扑映射方法,极大提升数据中心的利用率和能效,从而提高数据中心的收益。当前光网络已经在Google、Facebook等互联网巨头的数据中心中尝试使用,其巨大的资源利用率和能效优势具有很大的应用前景。
