基于jupyter的大数据分析工具在网络优化领域的应用研究
2021-07-20蔡林
蔡林
【摘要】 目的:介绍Jupyter Notebook在网络优化领域的应用情况。方法:集成Hadoop、Spark、Jupyter Notebook 等开源工具,搭建网络优化分析平台,基于真实案例验证其在网络优化领域应用的可行性。结果:通过搭建大数据计算环境,成功实现多数据接入、分布式运算、分布式存储、交互式应用及结果展示等功能,并基于该平台完成网络整体问题分析、问题原因定位分析、问题处理方案分析、问题处理效果分析等大数据分析任务。结论:结合网络优化的大数据分析需求,搭建便于使用的大数据分析环境,提升基于大数据的网络优化分析能力。
【关键词】 大数据 Jupyter Notebook Hadoop Spark 分布式计算 网络优化
引言:
随着无线通信网络的快速发展,网络优化信息化、智能化建设进入了突飞猛进的发展阶段,积累了大量的MR(测量报告)、PM(性能数据)、NRM(网络资源管理)、工参等基础数据。这些数据资源的价值还未能充分的挖掘,如何从各维度大量数据中发现可用的信息,加速网络优化信息化、智能化进程是迫在眉睫的任务。通过对网优大数据特性及网优工作协作方式与Jupyter Notebook进行结合性研究,实现有效的且适用于网优的大数据分析,以满足网络优化分析需求。
一、 jupyter与网络优化分析处理的结合
1.1 Jupyter Notebook[1] 技术与网络优化分析应用结合
Jupyter是一个可交互的记事本,支持了Python[2]、Julia、JavaScript、R等等编程语言达40 多种。它是一个开源的Web 应用程序,在其环境中可以运行代码和记录代码,可以对数据进行清洗,可以通过可视化视图查看数据结果,可以进行大数据相关的数模转换、模型构建、机器学习训练等。
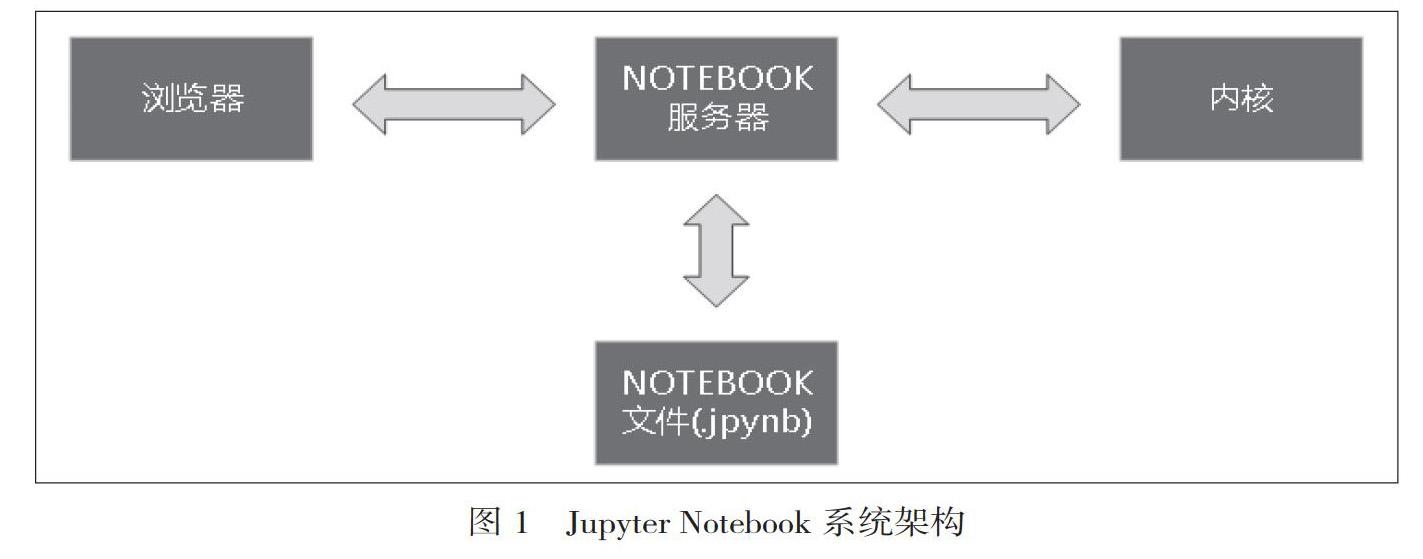
如图1所视,Jupyter Notebook的系统架构包括人机交互、浏览器、服务器、核心、文件等,其中服务器为核心构件。网优分析人员通过浏览器连接到服务器,在Web中编写代码并将代码发送到内核,由内核执行,于将结果反馈到Web页面。个人编写的代码保存在服务器中,可共享给其他人员使用。
1.2 JupyterHub[3]技术与网优工作流程结合
JupyterHub支持多个用户(包括管理人员、网优人员和维护人员等)同时构建自己的工作空间和计算环境,共享或使用其他人的资源,以达到联机协作的目的。
1.3 HDFS[4]与jupyter结合作大数据存储
Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System),用于存储网络优化分析所需的各类型各维度数据。
1.4 Spark[5]与jupyther结合作大数据计算
Spark 提供了80多个高级运算符。一方面,Spark提供了支持多种语言的API,使得用户开发Spark程序十分方便。另一方面,Spark是基于Scala语言开发的,使得Spark应用程序代码非常简洁。同时由于spark基于内存,在网优大数据处理领域,性能比hadoop快。
二、基于jupyter的网络优化分析平台架构
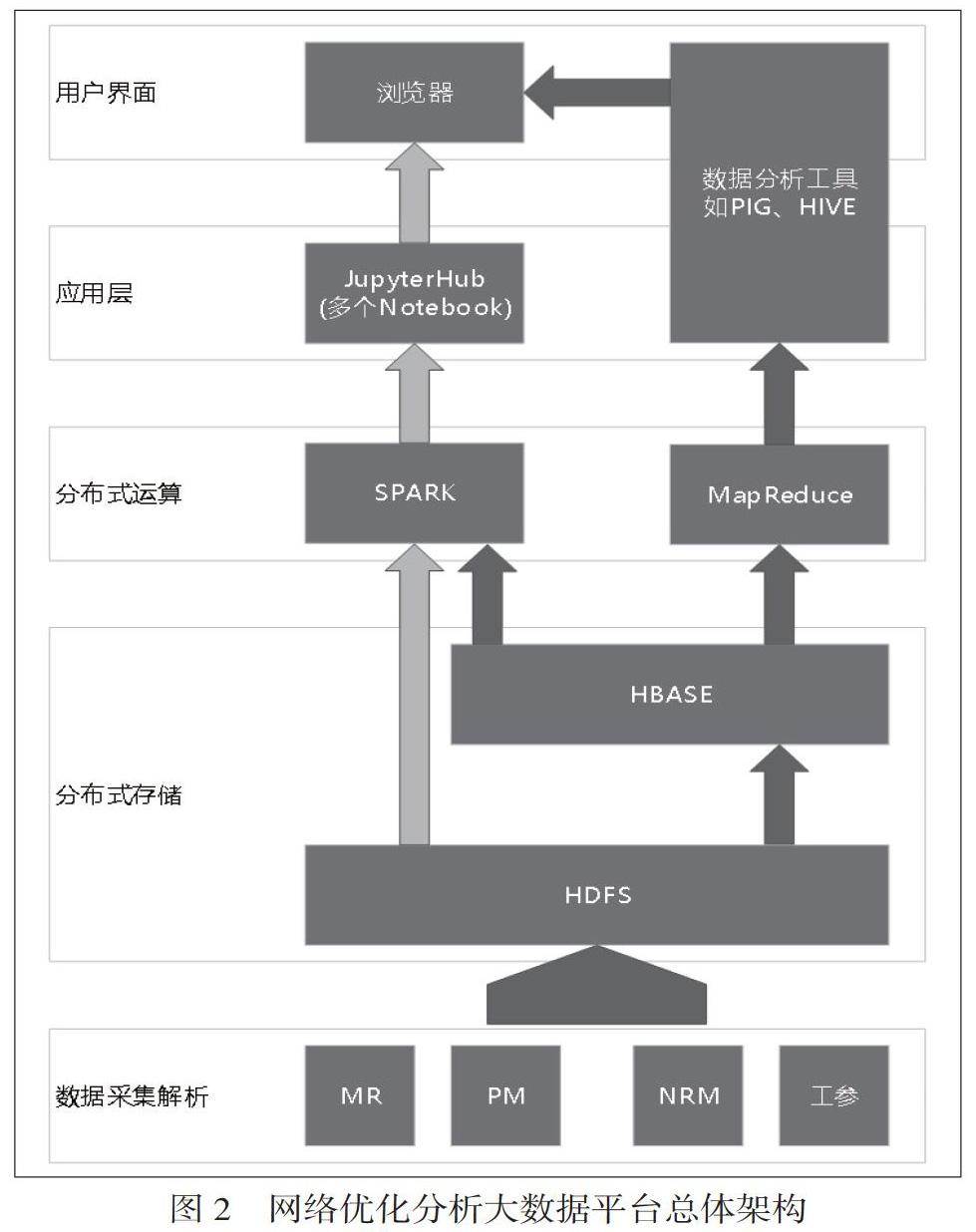
网络优化分析平台的建设面向基于大数据的网络分析优化需求,以网优问題分析定位为主要目的,结合MR、PM、NRM、CM等数据特点,主要以满足网络优化问题定位为主。网络优化分析平台的总体架构图见图2,包括网优数据的采集解析、基于不同数据类型的分布式存储、各类型数据不同维度的分布式运算、各类型数据的组合应用层以及用户界面应用。
2.1 用户界面
界面提供给网优工作人员进行网优工作信息交互,实现网络信息的内部组合形式与网优人员可以接受的按照既定业务逻辑形式之间的转换。
2.2 应用层
应用层为网优人员提供了自行代码编写、程序调试及结果展示的功能,利用JupyterHub实现多个网优人员的Notebook管理,同时也提供了HIVE、PIG等传统的大数据统计分析工具供网优人员选择。
2.3 分布式运算
基于Spark框架,利用Spark Streaming、Spark SQL、GraphX、MLlib等核心组件,实现网络优化各类型各维度数据统计。
2.4 分布式存储
网络优化分析大数据平台采用HDFS作为分布式存储的文件系统,HDFS有着高容错性(fault-tolerant)的特点,而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。从而支持网优人员在HBase[6]或HDFS上对数据进行查询、编辑等操作。
三、应用案例
3.1 4G MR竞对深度分析
本案例对超过300亿条MR测量记录进行按天各运营商覆盖优劣分析。首先将数据(.xml格式)采集解析清洗并转换为parquet [7] 格式存储到HDFS中,然后根据查重条件对数据进行聚合统计,得到按天的各行政区划各场景的运营商覆盖率、优于竞争对手的小区数、劣于竞争对手的小区数,得到覆盖率优于或劣于竞争对手的行政区划数、场景数,计算任务利用Spark分布式计算框架来完成,通过jupyter连接数据库,可以对数据进行开发,数据建模,最后利用Python包matpoltlib图形化展示各运营商各行政区划、各场景的覆盖率、优于或劣于竞争对手小区数的对比分析结果,支持快速定位覆盖率差的行政区或场景,支持快速定位优于或劣于竞争对手的行政区或场景,作为支撑后续基于覆盖优化的天馈调整、参数调整及网络规划工作的依据。
3.2 4G分頻段对比分析
本案例对超过30亿条PM数据、超过300亿条的MR测量记录、超过1千万条NRM数据进行按天分析。首先对数据进行数据采集解析清洗存储到HDFS中,然后根据NRM匹配出有效的工参数据,再按照工参数据中的频段属性进行分频段聚合统计,得到按天的各频段按频段、按行政区划、按场景、按基站的干扰类、接入类、保持类、容量类、移动类、负荷类、语音类、覆盖类指标数据,计算任务利用Spark分布式计算框架来完成,通过jupyter连接数据库,可以对数据进行开发,数据建模,最后利用Python包matpoltlib图形化展示4G分频段的各类指标,支持按指标类的不同行政区域对比、不同场景对比,支持按行政区划、按场景的不同类指标对比,支持按行政区域、按场景的某一类内多个指标对比,作为支撑后续指标差原因分析、指标优化分析、参数调整、负荷均衡、硬件扩减容、LICENSE调整、频段调整、PCI调整、邻区调整的依据。
四、结束语
基于Jupyter Notebook的网络优化大数据分析应用,构建易于使用的网络优化分析大数据平台,能够快速高效为网优人员提供大数据分析计算环境,解决日常网络优化的大量数据分析处理问题。同时由于网络优化分析平台的信息安全级别要求较高,使得基于开源产品建设的平台维护难度较大,需要进行有效的完全管理后才能作进一步的推广。
参 考 文 献
[1] Jupyter.The Jupyter notebook 5.4.0 documentation[EB/OL].https://jupyter-notebook.readthedocs.io/en/5.4.0/.
[2] Python. 3.9.1 documentation[EB/OL].https://docs.python.org/3/.
[3] Jupyter.JupyterHub-JupyterHub documentation [EB/OL]. https://jupyterhub.readthedocs.io/en/stable/.
[4] Hadoop A.Hadoop-Apache hadoop 3.2.2[EB/OL]. http://hadoop.apache.org/docs/r3.2.2/.
[5] S p a r k . O v e r v i e w -Documentation[EB/OL]. http://spark.apache.org/docs/latest/.
[6] Apache.Apache HBase-Apache HBase? Home [EB/OL]. https://hbase.apache.org/.
[7] Parquet.Apache parquet[EB/OL].http://parquet.apache.org/documentation/latest/.
