面向粮食安全应用的智能分析和决策支持系统设计
2021-07-20李月恒通讯作者张钰亮李妍欧张雯卓
李月恒 (通讯作者),张钰亮,李妍欧,张雯卓
(北方工业大学电气与控制工程学院,北京,100043)
0 引言
对于粮食的分析和决策系统,国内外主要农业发达地区如欧盟、美国、澳大利亚等都相继建立了农产品及产地追溯的系统,并且建立了自身评判粮食水平的指标。Liopa-Tsakalidi A等开发了一个包括决策支持能力的移动信息系统,该系统提供移动服务来支撑整个决策网络的实现[1]。Swarte C等人针对食品安全目标Food Safety Objective(FSO)的设置进行了较为深入的探讨,该研究引入了FSOs概念并将其作为食品风险管理的有力工具,该研究就FSOs这一理论的产生原理和过程进行阐述分析,为政策制定者提供理论依据,但不足的是作者并没有对这一理论在食品安全政策的有效应用进行阐述[1]。余腊生和李强基于贝叶斯网络的数据挖掘模型来挖掘不同属性的关联度,用Microsoft时序模型和决策树算法,对产品质量水平进行分类[3]。本文采用了支持向量机(SVM)和决策树(decision tree)作为粮食产地判别的模型,经过比较同等情况下准确率更高的模型,同时根据检测得到的矿物元素含量进行风险分析。除此之外,将判别模型嵌入到Web系统中,采用B/S的3层架构、MYSQL数据库和Java语言开发设计了整个系统。
1 系统总体功能图
本系统根据项目的实际需要,系统实现的功能主要有:用户注册、用户登录、待测信息录入、产地预测、数据导出、风险分析共6个模块。系统总体功能图如图1所示。
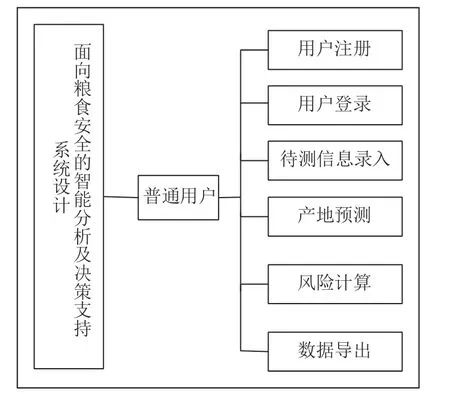
图1 系统总体功能图
2 判别算法比较
■2.1 数据来源
从河北省、陕西省、山东省、河南省采集2018-2019年度小麦样品。从这些地区采集的都是主产区,用ICP-MS(电感耦合等离子体质谱仪)测定4个产区大米的Be、Na、Mg、Al、K、Ca、V、Mn、Fe、Co、Ni、Cu、Zn、Se、Mo、Ag、Cr、Sb、Ba、Tl、Pb、Th 和 U共23种元素的含量。为了提高准确率,每个样品重复测定三次,选三次的平均值作为最后的测定值。
■2.2 数据预处理
首先发现源数据800条只缺失12条,缺失条数相对总数据来说比较少,采用简单的直接删除缺失值来处理,其次对数据进行训练集和测试集划分,训练集:测试集=7:3,将标签变成分散的0,1,2,3便于后续的处理,故对标签进行编码,最后对各项属性进行标准化处理,Z-Score标准化公式如下:

其中,yi表示各个属性标准化之后的值,表示每项属性的平均值,s表示该属性的方差,新序列均值为0,方差为1。
■2.3 方差分析
用python对23种矿物元素含量进行进行方差分析,结 果 表 明,Na、Mg、Al、Ca、V、Cr、Mn、Fe、Co、Ni、Cu、Zn、Mo、Ag、Sb、Ba、Pb 和U共18 种元素的含量在不同省份之间有显著差异.结果表明河北样品的Ca含量最低,V含量最高;陕西样品的 Na、Mn、Fe含量显著高于其它地区;山东样品的Ba和Ni含量最高;河南样品的Cr含量最高。
■2.4 判别结果分析
2.4.1 支持向量机
在对原始数据进行数据预处理后调用支持向量机算法模型,在未调参之前,由于采用的是SVM的多分类模型,数据集呈非线性分布,故使用rbf高斯径向基核函数。支持向量机在处理多分类问题的时候,是把多分类问题转换成了二分类问题来解决。在一类对另一类(OVO)模式下,标签中的所有类别会被两两组合,每两个类别之间建一个SVC模型,每个模型生成一个决策边界,分别进行二分类。这种模式下,对于四分类问题,生成C24也就是6个超平面。在一类对其他类(OVR)模式下,标签中的所有类别会分别和其他类型进行组合,分别进行二分类,无论如何分类,一类对其他类对于四分类问题始终需要4个模型。考虑到无论是当类别更多时,二者需要的决策边界越来越多,模型也会越来越复杂,不过OVO模式下的模型计算会更加复杂,决策边界数量增加更多更快,好处就是准确率随之提高了,所以如果硬件条件满足,人们一般选择OVO模式。
在选定了kernel核函数和OVO模式的情况下,默认松弛系数的惩罚项系数C=1.0,其他系数默认,对数据进行初步的计算,结果发现其正确率非常低,只有24.1%。为了提高正确率,将考虑调整必要的参数来达到要求。
准确率太低,调整C或者gamma的值,发现其正确率并无太大变化,一直只有24.1%左右。后考虑是否可以更换kernel核函数,更换kernel核函数为liner线性核函数发现,其正确率显著上升,达到98.5%,如图2所示。

图2 准确率随C的值变化
2.4.2 决策树
利用决策树模型进行判别,在不调参的情况下,对数据进行初步判别,其正确率有94.6%,正确率是否还能继续调,因此考虑调参看是否能达到更高的正确率,图3是未调参时得到的树图。

图3 未调参时得到的树图
上面的决策树只是sklearn只是调整entroy系数是gini绘制出来的,但是如果重复上述绘制树的过程,发现每次的树都不一样。sklearn通过设置random_state和splitter,每次进行分枝时都只选取部分特征不选择全部特征,这样一来也就建立不同的树,从中选取一颗最好的树作为采用的树。至今为止,我们已经找到了最好的节点和最优的分枝数,接下来要解决怎么让树停止增长,防止过拟合问题。采用合适的剪枝策略正好能完美的解决这个问题,一般来说有以下几个剪枝策略:限制树的最大深度,超过设定深度的树枝全部剪除,这个参数对应是max_depth。图4是max_depth调参折线图。
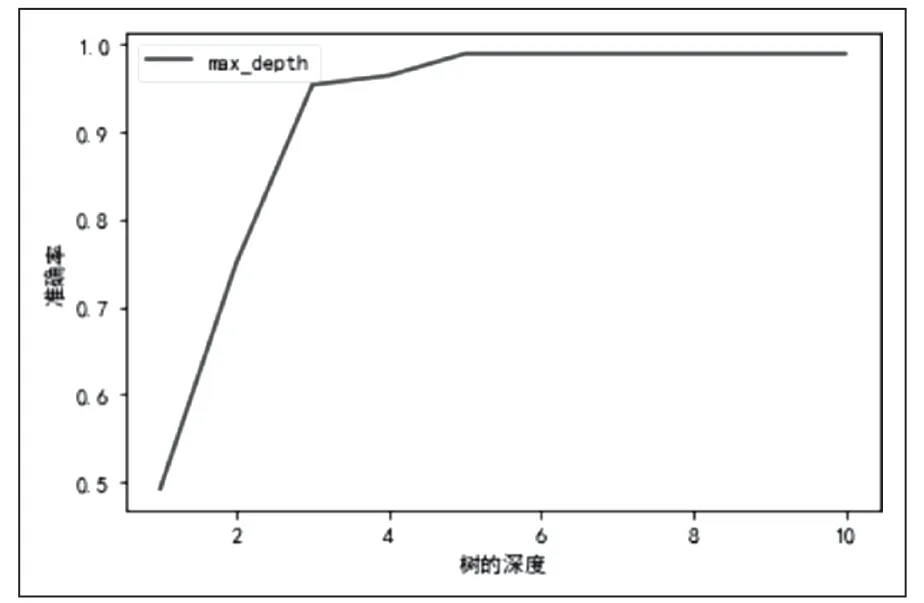
图4 max_depth调参后的折线图
可以明显看出当限制树的深度为5的时候达到最高分数98.9%,准确率可以说是非常高,满足项目的需求。
综上,从正确率考虑,二者其实差不多,但从效率考虑,随着后续数据的增多,SVM也更适合处理小样本的数据,SVM的效率明显快于决策树模型,因此选择SVM作为最终的判别模型。
传统的干法回收处理LFP动力电池成本高、利润低,学者们开发出了新的干法回收技术。本课题组在空气中高温处理正极片后,将 LiFePO4氧化为 Li3Fe2(PO4)3及 Fe2O3并作为再生反应原料,加入适量还原剂,650 ~ 750℃高温碳热还原再生LiFePO4,获得纯相的再生LiFePO4/C材料,如图5。
3 风险指标分析
■3.1 评价标准选取
重金属是非常常见的污染物,散布于土壤中被农作物吸收后会积累在农作物体内。人们食用被污染的肉、蔬菜、粮食等都会通过食物链最后沉淀在人体中,从而引发人的各种疾病,甚至造成死亡。鉴于此,世界主要国家和地区都对粮食中重金属污染物的含量做了比较明确的规定。表1列出了世界主要国家和地区对小麦重金属污染物的含量标准。

表1 世界主要国家和地区小麦重金属污染物的限量标准[4] mg·kg-1
因此,本文选用中国标准作为本研究的小麦重金属含量的标准,由于检测时只测量了Cr、Cu、Pb、Zn作为研究元素,从1表中可以发现中国粮食卫生标准中只对Cd、Pb、Hg、As做了相关规定,中国农业行业标准对所有的元素进行相关规定,故总结得到小麦颗粒重金属含量限量的标准
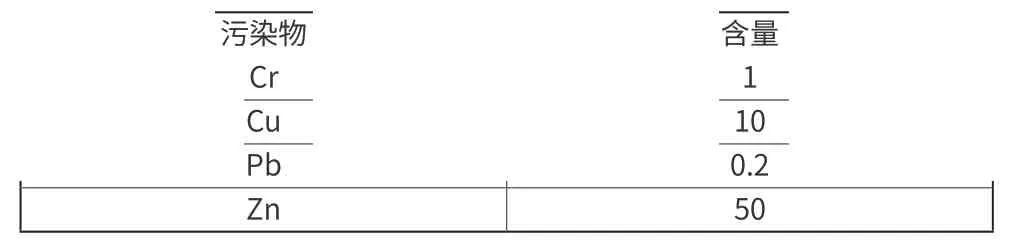
表2 小麦重金属含量限量的标准值 mg·kg-1
■3.2 评价策略
3.2.1 单项污染指数法[5]
采用单项污染指数对小麦重金属污染程度进行评价, 单项污染指数计算公式如下:

其中,iP为所计算出的重金属单项污染指数,Ci重金属含量的实测值,Si为小麦重金属含量限量的标准值。当Pi≤ 0.7时优良,0.7 < Pi≤ 1.0时安全,1.0 < Pi≤ 2.0时轻污染,2.0 < Pi≤ 3.0时中污染, Pi> 3.0时重污染。
3.2.2 综合污染指数法[5]
单项污染指数法只能反映出每个污染物的污染程度,并不能综合地反映出小麦的污染情况。综合污染指数法考虑了单项污染指数的每项的最高值和平均值,从而可以标注出污染严重的污染物。综合污染指数法计算公式如下:

其中,P综是要求的综合污染指数,P平均是单项污染指数的平均值,P最大值为单项污染指数的最大值。当P综≤0.7时等级是安全,0.7 < P综≤1.0时等级是警戒线,1.0 < P综≤2.0时等级是轻污染,2.0 < P综≤3.0时等级是中污染,P综>3.0等级是重污染[5]。
4 功能效果
先启动后台项目,再启动前台项目,启动Nginx,后台项目运行在8001和8002端口,前台项目运行在9100端口,Nginx端口为9010,访问http://192.168.1.118:9100。对于新用户来说,首先要进行的就是用户的注册,注册页面如图5所示。

图5 注册页
在注册页面中,用户输入昵称、注册的手机号、一条四位数字验证码和自定义的密码,点击注册后,系统会核实验证码是否正确,如果正确则会向数据库添加一条新用户的注册信息,同时页面跳转到登录页面。如果验证码不正确,系统隔60秒重新请求验证码。
其次是登录页面,如图6所示。
图6 用户登录界面
在登录页面中,用户输入手机号和密码进行登录。点击登录按钮后,系统将输入信息以请求体的方式传递到后台,并判断用户名和密码是否存在与数据库中,验证手机和数据库中的手机号和密码匹配。登录成功后,跳转到系统首页面。

图7 首页
首页面参照了后台系统的模板形式,主要分为三部分:侧边栏、顶部栏和中部主要区域,在侧边栏内,设计了添加元素、元素列表、查看分析后产地的数量以及地图的显示;顶部栏主要对登录后的用户进行头像显示和用户的退出;中部主要区域只是对用户做了一个友好的欢迎。
点击添加元素可进行文件的上传,如图8所示。

图8 文件上传界面
点击选取文件按钮,弹出一个对话框提示用户从本地选取文件,对文件进行解析,显示在元素列表页面上,如图9所示。
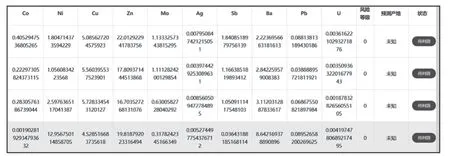
图9 解析文件后界面
点击待判别按钮,系统会调用后台的判别算法对其产地进行判别,同时根据预设定的风险评价体系,给出其最后的风险评价,随着判别情况一同返回到前端进行页面渲染,使得数据发生变化。当点击批量判别时如图10所示。
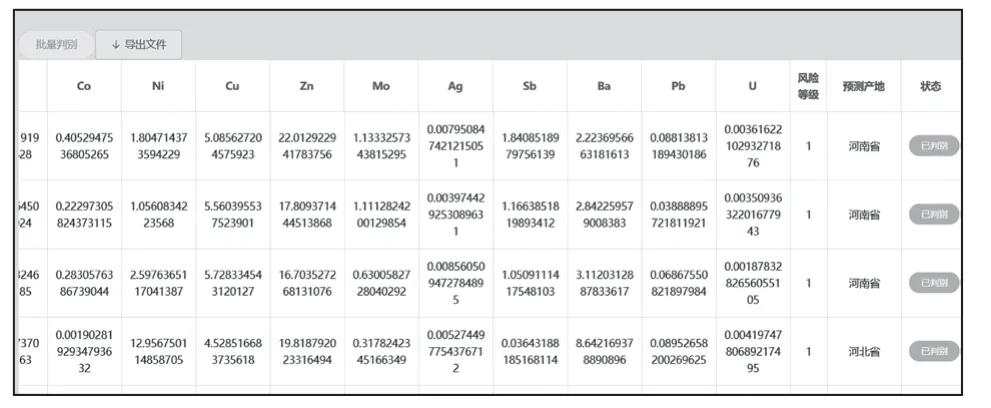
图10 批量判别返回产地和风险评价
在得到了数据的判别产地和风险等级后,系统提供了条件查询的功能:根据数据的产地、风险等级、上传的开始时间和结束时间对数据进行查询,可以找到其满足要求的数据进行显示,条件查询如图11所示。

图11 条件查询
系统还提供了文件下载功能,当点击下载文件按钮时,在本页面中弹出一个对话框,用户选择想要保存文件的位置,确定后即可开始下载,下载后文件部分数据如图12所示。

图12 下载后部分数据图
系统还结合了ECharts提供了更为直观的数据显示,点击查看分析后的产地结果如图13所示,通过该图可以明显看出每个省份小麦对应的数量。

图13 分析后产地数量对应图
最后,系统可以通过地图来查看各项数据产地分布情况,如图14所示。

图14 地图查看小麦分布
5 总结
文要解决的问题是粮食安全的分析和决策评价,采用B/S的三层架构,tomcat服务器,J2EE标准,数据库采用Mysql和Redis设计开发设计了粮食安全的分析和决策系统,为了便于研究,选择小麦作为主要研究对象,从而实现了对小麦产地的判别和小麦安全的评价。
