一种基于改进CenterNet的胸环靶弹孔检测方法
2021-07-20王小康陶青川
王小康,陶青川
(四川大学电子信息学院,成都610065)
0 引言
射击训练作为军队里士兵不可或缺的重要实训项目,可以让官兵在实战化训练中发现短板,提升士兵的专业水准,对于促进军队现代化具有重要意义。传统的成绩计算方式是由人工实时报靶,但该方式存在人为误报、工作量巨大并且还存在一定的风险等问题,近些年随着视频图像处理领域技术的不断积累,基于计算机视觉的自动报靶系统因其精准实时、稳定性强、安全低成本等优点被广泛研究[1]。由此又出现了一系列基于数字图像处理的自动报靶系统。在基于图像处理的自动报靶系统设计中,由于弹孔面积过小,且在多次射击同一张靶面后可能会存在不同程度的重合问题,如何正确区分弹孔和非弹孔,准确判断孤立弹孔还是重合弹孔,一直是弹孔检测中研究的重难点。目前针对弹孔检测方法主要是一些传统方法[2]:①差影法:原理是在快速射击过程中,连续两次射击得到的两帧画面近似没有变化,故可以对两帧靶面图进行减法运算,由此认为得到的弹孔是新增的弹孔。该方法简单直观,但抗干扰性较差,如果前后两帧靶面由于外部因素造成抖动出现明显位移,则剪影结果会出现较大误差。②颜色特征:把弹孔的RGB色彩信息作为判别标准,通过设定先验弹孔的RGB范围,过滤不在颜色范围内的区域,只把符合条件的区域判定为弹孔。但该方法的缺点是RGB色彩空间具有局限性,无法应对靶面亮度等外部环境变化带来的干扰,鲁棒性较低。③几何特点:在实际射击场景中,情景比较固定单一,多次射击后的弹孔形状规则且相似,故可以在筛选阶段通过弹孔的这些几何特性对弹孔进行分类和筛选,但这种方法过于依赖弹孔圆率、大小等先验值的设定,在极端情况下依旧会和靶面上的划痕以及其他非弹孔混淆,造成误检。
卷积神经网络最初于二十世纪80至90年代被提出,到了二十一世纪后,随着深度学习理论的提出和计算机等硬件设备的计算能力的大幅提升,卷积神经网络得到了快速发展,其研究成果逐渐被应用于工业界。R-CNN[3]框架于2013年由Girshick等人提出后,开启了新时代以深度学习为基础的目标检测热潮。当前基于深度学习的目标检测模型主要分为两类:twostage检测模型和one-stage检测模型,二者都是基于锚框(anchor)的目标检测算法。Two-stage检测模型典型代表有R-CNN、Faster R-CNN[4]。基于二阶段的检测模型优点是检测精确度较高,缺点是是耗时过长,实时性较差。one-stage检测模型主要包括:YOLO[5]、SSD[6]、YOLOv2[7]、YOLOv3[8]等。one-stage检测模型因其检测一步完成,故能实现端到端的检测,相较于two-stage检测模型有着更快的检测速度,但是随之带来的问题是检测精度会有所降低。但使用锚框的问题是,由于检测器被训练用以分类每个锚框是否能最大程度匹配真实框,所以需要在检测阶段预设大量的预选框以待匹配,然而实际上最终只有一小部分框能精准匹配到目标,就会导致正负样本的极度不平衡,减慢训练速度。
随着近些年基于anchor-free的目标检测算法的兴起,这些问题逐渐得到解决。所谓基于关键点的anchor-free的目标检测,其实质仍是one-stage网络,但是不再预设锚框,相较anchor-based算法速度上有不小的提高。本文提出一种基于改进CenterNet模型的快速弹孔检测方法,改进特征提取网络的卷积层,精简网络层数,在保持原有网络的精度的前提下,降低网络参数量,提高模型的检测速度,在弹孔检测阶段代替传统的阈值分割等算法完成检测。实验证明,本文所提出的检测算法相较改进之前,检测速度有明显提升,可以更好地满足实时性要求,同时比传统算法有更高的准确性和鲁棒性,可以应用于大部分弹孔检测识别的场景。
1 基于CenterNet的弹孔检测算法
1.1 图像预处理
基于视频图像处理的自动报靶系统在算法流程上,目前主要处理方法如下,对视频中获取的原始帧图片进行一系列形态学预处理,包括靶面提取、靶面倾斜校正、靶面图像增强等等操作,具体算法流程如下图1所示,目的是为后续提供一个干扰尽可能小的检测环境,然后在此基础上,再做弹孔检测和环值判定工作。环值判定一般有几种普遍的做法,一种是基于环区的判定方法,其思想是将每一个环区先检测出来,然后分别打上标签和该环区的环值相对应,判定时直接读出弹孔所在环区的环值即可。由于靶面的环间距是相等的,所以还有一种方法是预先检测到靶面图像的中心点,然后只需要计算所检测弹孔和中心点之间的欧式距离和环间距就能计算出具体环数。相比较于第一种方法,第二种方法简单直观,并且射击结果可以精确到小数点后数位,调控方便。考虑到在实训环境中,靶面一般放置在距离地面一人高的位置上,为了避免在射击过程中子弹击坏摄像头,摄像头一般放置在靶面正前方靠近地面的位置,所以在实际采集到的图像帧中,靶面会存在一定角度上的倾斜,对于第二种方法,这种三维畸变会导致距离测量产生误差继而影响后续的环值判定,故在进行弹孔检测之前,需要先把靶面图像进行几何校准等一系列预处理操作,如图2所示。

图1 算法流程图

图2 预处理效果图
1.2 CenterNet算法
CenterNet算法是于2019年4月提出的一种anchor-free类型的算法,该算法大致思想是将待检测目标看作一个单点模型,不同于一阶段检测算法或是二阶段检测算法需要预先设定很多不同尺寸的锚框,只需要通过关键点估计算法找到目标中心,而后再回归目标的尺寸、姿态估计、3D坐标信息等其他属性[9]。由于每个目标中心点只有一个,一旦确定中心点就可以唯一确定一个目标,因此也不需要非极大值抑制后处理,这将大大减少了网络的计算量和模型的训练时间。加之损失函数中不仅有目标中心点的位置损失和该位置偏置损失,还加入了目标大小损失,这也能提高算法的准确度。
原文分别使用了三种主干网络,分别是RseNet-18[10]、DLA-34[11]、Hourglass-104[12]。根据作者实验网络在经典数据集上的表现,Hourglass-104虽然速度略有不及其他主干网络但是在精度上表现更好。所以本文实验网络选用Hourglass-104作为主干,CenterNet的网络结构如图3所示。
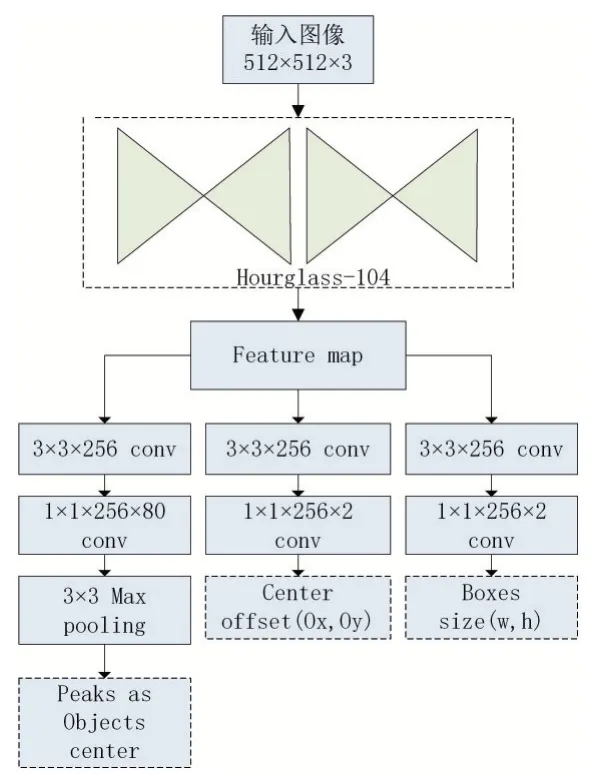
图3 CenterNet算法流程图
CenterNet算法大致流程为,输入尺寸为I∈RW×H×3的图像,经过卷积特征提取网络Hourglass后会生成一张关键点的热点图(keypoint heatmap):

其中W和H分别代表图像的宽和高,R代表下采样的步长,原文中将R设置为4,C为检测目标的类别,原文中取C为80,即待检测目标的类别。热力图输出范围表示成功检测到关键点,表示检测到背景。最终预测目标位置时候,总的损失函数分为三个部分,分别为目标中心点预测损失函数、目标中心点位置的偏置损失函数和目标尺寸大小的损失函数。中心点预测损失函数采用Focal Loss进行逻辑回归,如下式(2)所示:

α和β为Focal Loss的超参数,作为经验值设置为2和4,可以更好地提高算法检测精度。目标中心位置偏置损失函数如式(3):

总的损失函数为三个损失函数加权总和,如式(5)所示:

在进行目标的检测时,首先提取每个类的热值图的峰值,具体做法是在预测阶段,在热力图中选取所有满足自身值大于或等于其8个邻接值的点作为峰值,并保持前100个这样的峰值,最终可以通过下式(6)得到预测框的坐标,完成由关键点到位置框的回归。

1.3 本文改进的CenterNet网络
弹孔检测算是小目标检测的一种,由于小目标自身包含像素较少,占原始输入图像比例非常小,自身携带的信息也很少,一般经过特征提取网络的几次下采样之后特征信息已经所剩无几,这样就会导致小目标在图像中的高层语义不够明显,在复杂环境中不利于检测,尽管特征图越接近底层的特征对应到原图的感受野越小更适合于小目标的检测,但是仅仅使用底层特征带来的问题是卷积层数不够,会缺乏上下文信息和一些必要的高层语义信息,这对于一些需要更高层更抽象的语义特征才能分类辨别的任务不够友好。Hourglass-104网络由两个连续Hourglass模块组成,并且模块之间引入中间监督进行端到端的训练。组成Hourglass模块的基本单元是残差模块(Residual Module),如图4所示。图5为1阶Hourglass图,一阶模块由上下两个半路组成,都包含若干残差模块,逐步提取更深层次特征。不同的是上半路在原尺度进行,下半路经历了先下采样再上采样的过程。每个Hourglass模块根据阶数的不同,所采用的下采样次数和上采样次数均不一样,随着阶数升高,可以在图中的虚线框部分嵌套加入同样的一阶Hourglass模块图,如此递归便可逐渐生成对应的多阶Hourglass模块。网络整体形状类似沙漏,故又称沙漏网络。

图4 残差模块

图5 一阶Hourglass模块
Hourglass模块阶数越高,下采样和上采样的次数越多,对应的高层语义越丰富,特征融合也更多样,检测精度就越高,但是更深的网络层次会使残差模块的卷积操作愈加的频繁,导致计算量更大模型检测更耗时。考虑到实际检测环境中,检测背景比较单一,最终弹孔尺寸比较固定。为了减少参数量,加快计算速度,本文在尽量不损失精度的情况下在网络深度和卷积模块上做出如下改进:
(1)原文中输入到网络中的为原始图像大小4倍下采样之后的图,而后会依次经过5次下采样,最高下采样层数可以到128倍,但是实际中输入图像为512×512,弹孔所占比例在图中较为固定,一般小于15,如果采用原文中的下采样结构到高层特征已经无法有效提取,因此本文改为输入图像为原始图像的2倍下采样,依次经过4倍、8倍,最多16倍的下采样,这样在原网络基础上裁剪掉32、64、128倍数的下采样和上采样过程,相比原文网络,相当于降低Hourglass模块阶数、大大节省计算量。
(2)原文算法应用在经典数据集上,一般用来做多目标多尺度检测,默认为80类别,所以原特征提取网络对于弹孔检测这种单类目标检测而言,特征提取器过于复杂冗余,其中卷积核个数较多,导致卷积计算过多,计算量太大。针对此种情况,本文旨在减少计算量,深度可分离卷积(Depthwise Separable Convolution)可以解决这个问题,在一些流行的轻量级的网络如MobileNet[13]就有使用,其高效的原因是将常规一步卷积方式拆分为逐通道卷积和逐点卷积两个部分,将原本3×3卷积的计算量转移到逐点卷积,大大减少总的计算量,举例说明,假设输入特征图大小为W_in×H_in×M,输出特征图大小为W_out×H_out×N,卷积核大小为K×K,那么对应标准卷积参数量为:K×K×M×N,对应深度可分离卷积参数量为:K×K×M+M×N,相比之下,参数量为原来的,本文中将基本残差单元中的3×3卷积替换为深度可分离卷积,在精度基本保持不变的情况下,参数量和计算量变为原来的改进之后残差单元如图6所示。

图6 加入深度可分离卷积的基本残差块
2 实验和结果分析
2.1 训练环境部署
本文在实际训练环境中实验平台配置如下:处理器为Intel Core i5-9700,内存8G,操作系统为Ubuntu 16.04,显卡为NVIDIA GeForce GTX1080Ti,显存11G。在训练部署过程中,参考一些小目标检测解决方案,在弹孔样本数据集上采用数据增强技术,对训练集的样本进行随机翻转,由于弹孔形状都为圆形且比较固定,对样本进行角度变换不会影响到最终的检测结果,故也可以通过旋转来增强样本扩充数据集。最终经过扩充之后共有6480张样本。设置其中5000张作为训练集,剩余1480张作为测试集。训练时,在训练集上以512×512的分辨率作为输入,输出分辨率为256×256,批量大小(Batch size)设置为16。学习率设置为0.001。
2.2 弹孔检测模型的评价标准
本文采用在深度学习中经常被用来衡量模型性能优劣的精确率(Precision)和召回率(Recall)作为评判指标,对本文中改进的网络模型和和原网络模型进行对比。精确率可以代表误检情况,召回率可以代表漏检情况。其中精确率和召回率越高,代表模型更优,对应计算方法如下:

在上式中:TP(True Positive)代表实际为弹孔并被正确判定为弹孔的个数;FP(False Positive)代表实际为非弹孔但是被判定为弹孔的个数;FN(False Negative)代表实际为弹孔但是被判定为非弹孔的个数。
2.3 实验结果分析
最终实验结果图如下图7所示,其中(a)为待检测图,(b)为检测结果图,(c)、(d)、(e)为局部放大的细节图,可以清晰看到,本文改进后网络可以较好地检测出密集射击情景下的弹孔,针对部分重合的弹孔也能获得较好的效果。

图7 检测结果图
在做最终效果检测时,将本文改进网络与原始的CenterNet-Hourglass算法在测试集上进行一个效果对比,主要对比精确率、召回率和单张图片的平均检测速度,结果如表1所示。由于本文结合实际场景对征提取网络的层数做出针对性的剪裁,并且将Hourglass模块中的基本残差块进行改进。实验结果显示,与原CenterNet网络相比,本文提出算法在测试集上总体精度和召回率有微小下降,但是检测速度大大提升,单张平均测速达到36ms,完全能够满足在实际射击场景中的实时计算的要求。

表1 结果对比
3 结语
针对目前传统算法在弹孔检测问题上出现准确率低、自适应性差、速度较慢等问题,本文提出一种基于改进的CenterNet关键点估计的弹孔检测算法,结合实际应用场景,改进特征提取网络,保留网络提取小目标能力的同时精简网络层数,并改变特征提取网络中的基本残差块的卷积方式,减少参数量和计算量,加快计算速度。实验结果表明,和原CenterNet网络相比,本文算法虽在检测精度上略有不及,但检测速度提升十分巨大,极大地增加了其在实际中的应用价值。但是目前对于完全重合的弹孔,还没有很好的解决办法,存在一定的漏检情况,后续还需对网络做进一步的优化并结合其他的办法尝试解决该问题。
