结合超像素的动态单目标追踪方法
2021-07-20程金伟胡大裟蒋玉明
程金伟,胡大裟,蒋玉明
(四川大学计算机学院,成都610065)
0 引言
目标追踪是自动监视、车辆导航、视频标注、人机交互以及动作识别等领域的应用最重要的任务:在已知视频前一帧中任意物体的位置情况下,以尽量高的准确率去估计该物体在后一帧中的位置[1]。
目标追踪要求算法能够以尽量贴近视频帧率的速度快速运算进行物体的追踪。同时,由于光照、镜头缩放等环境或相机状态的变化以及物体产生外边形变等自身状态的变化,使稳定追踪成为目标追踪算法面临的主要挑战。
本文提出了将超像素与孪生网络结构相结合的目标动态追踪新方法。以孪生网络结构为框架,使用目标掩膜和超像素生成目标框提高目标追踪的准确率。在VOT数据集下与其他算法进行对比试验,验证本文算法的准确率和鲁棒性。
1 动态目标追踪技术研究现状
1.1 动态目标追踪技术发展
追踪任意物体的通行方法是从视频前一帧提供的真实信息中在线训练出具有判别目标和背景能力的分类器,从而随着视频对其更新来进行追踪。
随着深度卷积网络的兴起,基于孪生网络(Siamese Network)的追踪方法被引入到目标追踪领域。该方法将追踪视为度量学习问题,通过使用示例图片z和候选图片x获得比较函数进行追踪;比较函数的函数值反映示例图片和候选图片描述同一物体的可能性;通过在新图片中遍历所有可能位置,利用比较函数即可获得目标外表相似程度最高的候选目标并实现追踪。Bertinetto等人提出了基于该方法的全连接孪生网络模型[1],将相同的变换φ作用与示例图片z和候选图片x,使用另一个函数g(z,x)结合变换后的结果得到f(z,x)=g(φ(z),φ(x));当函数g(z,x)是距离度量函数时变换φ可以被认为是嵌入函数(embedding);通过卷积,孪生网络结构输出一个响应图,响应图由当前帧所有候选图片和示例图片的相似函数值组成;再通过插值获得高响应值图片所在的位置,即实现目标追踪。
Li等人利用候选区域(region proposal)优化了孪生网络的效果[2];Zhu et al使用难例挖掘(hard negative mining)[3];He等人利用集成学习进一步优化了追踪结果[4]。
大部分的追踪方法在初始化目标阶段选择使用矩形标定框来确定目标。然而矩形框并不能很好地确定目标。因此依靠矩形框初始化更加细粒度地确定目标是亟待解决的问题。
Wang等人基于Bertinetto等人的算法,在保留离线学习和运算速度的前提下,提出SiamMask算法[5]。由于全连接孪生网络的输出仅包含目标的位置,并不包含其空间范围,该算法在孪生网络结构的基础上增加了候选区域网络(Region Proposal Network)和类别无关的二值分割(Binary Segmentation)。通过RPN和分割出的掩膜计算获得更加精确的目标位置,提升追踪效果。
超像素是指使用聚类算法将完整图像分割出的子区域[6]。每个子区域均包含若干个像素,一个子区域对应聚类中的一个簇,同簇中的对象彼此的特征相似,与其他簇中的对象特征差异较大。由于超像素具有这样的特性,因此具备将目标和背景区分出来,指示自身包含的像素的类别是目标或背景的能力。将超像素运用在视觉计算中可以很好地去除与追踪任务无关的图片信息,减小算法的复杂度。
Yeo等人提出基于超像素分割使用吸收态马尔科夫链(Absorbing Markov Chain)进行追踪[7]。其只使用LAB颜色空间的颜色均值作为目标特征,并没有充分利用目标信息,且运算速度十分缓慢,并不满足实时性要求。
Luo等人采用超像素进行目标特征建模,通过确定关键点位置利用金字塔追踪器预测目标位置进行追踪[8]。由于要提取大量关键点进行计算,因此运算速度约在1FPS左右,并不满足实时性要求。
1.2 动态目标追踪技术对比分析
由表1可以看出,相关滤波类算法MOSSE、SRDCF、KCF等相比于深度学习方法,其精度不如后者,这是由于深度学习方法提取出的特征有更好的表征能力,深度学习方法训练出的模型更加完善。但深度学习类算法追踪速度并比不上相关滤波类算法,这是由于相关滤波类算法使用傅里叶快速变换在频域中进行运算,大大提升了计算速度。

表1 算法指标对比
2 结合超像素的孪生网络追踪方法
目标追踪任务可以被认为是研究后续帧和首帧之间同一目标的相似性问题。通过特征抽取,选定后续帧中与首帧目标的特征相似度最高的物体作为目标进行追踪。利用目标提供的色彩等特征进行追踪时,由于缺少背景信息,经常会导致追踪失败,因此在追踪过程中利用一定的背景信息能够增强追踪效果。本文提出结合超像素的孪生网络追踪方法,通过超像素提取目标信息作为样本进行追踪,提高追踪效果。
2.1 孪生网络结构
孪生网络结构包含两个或多个参数相同,权重共享的子神经网络,其参数可在子网络上同时更新。因此利用一次前向传播并进行互相关运算即可得到输入的相似程度。
函数f对示例图片z和候选图片x进行相似度判定,输出最大值对应目标位置。z通常以第一帧中的目标为中心,x是第n帧中以n-1帧目标位置为中心截取的图像。
使用卷积神经网络φ对图片进行卷积提取特征。使用互相关运算将特征映射融合:
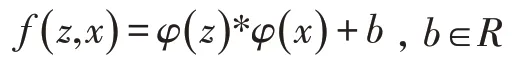
通过互相关运算,f(z,x)计算出示例图片z在候选图片x中不同位置的相似度,响应值最大位置对应候选图片x中目标位置。孪生网络结构输出尺寸为D⊂Z2的相似度图,如图1所示。

图1 孪生网络结构
在追踪时,以n-1帧中的目标位置为中心选取候选图片,对相似度图进行插值,将最大值所在的位置作为目标位置,得到每一帧的目标位置情况。
2.2 结合超像素的孪生网络追踪方法
本文介绍的结合超像素的孪生网络算法整体网络结构如图2所示,*d表示对基础网络输出进行空间互相关运算。通过卷积神经网络sφ的输出选取卷积神经网络输出中的最大值,得到当前候选图片中目标的位置,对候选图片进行超像素分割,生成目标的优化掩膜,进行追踪。

图2 网络结构
卷积神经网络sφ对基础网络输出的张量进行卷积,输出相似度图,得到目标位置与相似程度。使用双三次插值对相似度图进行上采样,得到更准确的目标位置。为了抑制追踪漂移的情况,使用余弦窗惩罚相似度图中的过大位移情况,同时为了应对尺度变化,对样本的五个尺度进行搜索。
为了得到更加精确的分割掩膜,使用优化模块R对Conv1、Conv2以及Conv3的输出进行元素求和,使用流水线结构对初级掩膜不断进行上采样,并对各卷积层输出结果进行反卷积,使初级掩膜与不同分辨率的掩膜融合。掩膜融合后输出的指示掩膜如图3所示。

图3 初级掩膜
2.3 超像素优化掩膜
在CIELAB色彩空间对当前图片以S为间隔对目标位置进行采样,共有k个聚类中心Ci=[li ai bi xi yi]T,,N为图片大小。将每个聚类中心移动到3×3领域中梯度最低位置以避免超像素中心位于边缘。
计算每个像素在2S×2S范围内与所有聚类中心的距离D,将该像素点归入距离最小的簇中。其中,距离度量:
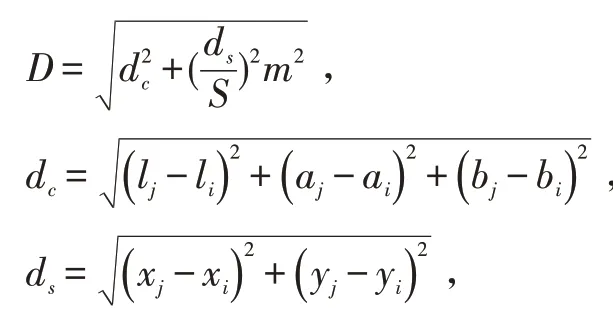
m为权重系数。
当每个像素都被归入相应簇中,更新各簇聚类中心至该簇所有像素的平均向量计算残差是更新前的聚类中心,是更新后的聚类中心。不断更新聚类中心直至残差‖E‖2小于阈值。
通过对卷积神经网络sφ预测的目标位置进行超像素分割,将前景与背景分割开来。结合卷积神经网络输出的掩膜,规定超像素面积Ms与指示掩膜面积Mm之比>0.8为优化掩膜。如图4所示。通过优化掩膜生成最小包围矩形框进行追踪,如图5所示。

图4 优化掩膜

图5 追踪框
2.4 损失函数

3 实验结果
使用VOT数据集的评价方法作为评测标准。VOT数据集使用准确率(accuracy)和鲁棒性(robustness)作为评价标准的基本计算单位。准确率计算公式如下:

VOT数据集包含60种图片序列,包含了光照变化、部分遮挡、镜头缩放、目标外表形变等情况。一个优秀的追踪算法应该具有较高的期望平均重叠率和平均准确率,较低的平均鲁棒性。
表2展示了本文算法与在VOT2018数据集的评价基准下的追踪算法CSRDCF、DaSiamRPN、SiamRPN的指标对比。

表2 算法指标对比
在准确率方面,本文提出的算法准确率为0.575,在四个算法中居于首位,并且对比基于相关滤波算法CSRDCF高出0.104。这说明深度卷积神经网络比相关滤波器提取出的特征更加有效,能更好地表征目标。
图6展示了四种追踪算法在rabbit和fernando图片序列下的追踪效果。Rabbit序列中追踪目标为兔子,它和背景的雪颜色高度相似。因此,四种算法都产生了不同程度的漂移,DasiamRPN和CSRDCF生成的目标框内不包含目标,追踪失败。本文提出的算法相比SiamRPN更好地标识出了目标所在位置。Fernando序列中追踪目标为暹罗猫,其外观会产生剧烈变化,干扰算法进行追踪。得益于通过掩膜生成目标框的特性,本文提出的算法相比较其他算法更加精准地定位出目标的整体情况。

图6 追踪对比
4 结语
基于孪生网络结构的算法具有追踪效果好,网络结构简单,实时性好的优点,本文基于孪生网络结构,提出将超像素与目标掩膜相结合进行追踪的方法。利用卷积神经网络生成的初级掩膜作为指示,使用超像素分割目标和背景进行掩膜优化。使用掩膜的最小包围矩形框代替了传统的边界框,提高了目标追踪的准确率。在VOT数据集上的实验结果表明,与当前主流追踪算法相比,将超像素与孪生网络结构相结合进行目标追踪,具有提升目标追踪效果的能力。
