基于DPU的低功耗嵌入式手势识别系统设计
2021-07-19黎海涛
黎海涛,刘 鸣,张 帅
(1.北京工业大学 信息学部,北京 100124;2.北京工业大学 樊恭烋荣誉学院,北京 100124)
0 引言
随着科学技术的不断发展,电子设备和人们生活的关系越发紧密,人与机器间交流的信息更加丰富,急需研究开发方便、可靠的人机交互系统。作为一种新型人机交互方式,手势识别允许用户在不接触设备的情况下通过简单的手势来控制设备,在操作方式上更加直观和自然,交互方式更加人性化[1],具有广泛的应用前景。
手势识别是模式识别的一个分支,其实现需要通过算法来检测人类的手势动作。传统的手势识别方法有模板匹配法[2]和Hu不变矩法[3]。模板匹配法是先准备好手势的模板,当有图像输入时,使用模板来逐行扫描整个图像,每次扫描就计算一次相关度,当相关度超过设定阈值时就判定检测到模板中的手势。该方法的优点是算法简单、计算量较低,缺点是若手势发生旋转或者缩放则无法正确检测,故实用性低。Hu不变矩法通过计算图像的不变矩进行识别,具有平移、旋转、放缩不变的性质,即使图像中的手势发生变化也能进行检测,因而实用性更高,但是当目标纹理复杂时准确率较低,不适用于复杂环境。
随着深度学习技术的不断发展,神经网络被成功应用于手势识别系统,其识别准确率高于模板匹配法、Hu不变矩法,且在复杂背景下的鲁棒性更强。因此,越来越多的手势识别系统采用神经网络进行识别,成为当前的主流技术。虽然神经网络法具有很高的准确率,但其运行需要进行大量运算,这对系统的性能和功耗提出了很高要求,所以目前神经网络大都部署在桌面级平台,而难以应用于嵌入式设备中。
为了把手势识别系统部署于嵌入式平台,研究人员开展了很多工作,其中基于现场可编程门阵列(field programmable gate array,FPGA)平台搭建神经网络成为一种新的尝试。利用FPGA高速并行数据处理的特性,达到加快处理速度同时降低功耗的效果[4]。文献[5]把径向基函数网络部署在FPGA平台上,实现了对24种手语的识别,在保持高识别率的同时压缩了系统体积。文献[6]利用FPGA设计了一个神经网络加速器,在功耗只有GPU的26.7%的情况下,运行速度提高了5倍。然而上述研究仅采用结构简单的网络,而实际应用中由于识别环境的复杂性和多样性,简单结构的神经网络存在无法准确识别的问题。因此,需要研究如何利用FPGA实现基于深度神经网络的手势识别。
由于利用FPGA器件设计深层神经网络需要耗费较大成本,导致实现复杂神经网络存在困难,因此采用集成的处理单元来实现深层网络就成为新的合理选择。赛灵思公司于2019年发布了深度学习处理单元(deep-learning processor,DPU),为FPGA部署深度神经网络提供了新的解决方案。基于此,本文利用DPU把ResNet-50网络部署于FPGA器件,设计了一个低功耗的手势识别系统,以解决基于深度神经网络的嵌入式FPGA手势识别问题。
1 系统结构
嵌入式FPGA手势识别系统的结构如图1所示,采用软件和硬件相结合的方法在ZYNQ平台上进行设计。由于ZYNQ内部包含可编程逻辑(programmable logic,PL)和处理系统(processing system,PS),所以设计分为硬件和软件两部分进行。硬件设计包括DPU部署、神经网络,软件设计包括Linux系统、应用程序。

图1 系统结构
在嵌入式FPGA手势识别系统中,DPU部署单元对DPU相关参数进行配置,将其部署在ZYNQ的PL端,为运行神经网络搭建硬件平台。神经网络单元构建并训练深度神经网络,并对网络进行量化和编译操作,得到可以被DPU读取和运行的神经网络文件。PS端的Linux系统单元在系统中添加DPU驱动和相关运行库,并对设备树进行修改来确保DPU能正确运行,为应用程序搭建好软件平台。应用程序单元对DPU进行初始化并创建DPU任务,调用神经网络模型对手势图像进行识别。
整个嵌入式手势识别系统的工作流程为:PS端运行嵌入式Linux系统,通过程序对手势图片进行预处理,同时对DPU进行初始化操作,然后将处理后的图像传递给PL端的DPU;DPU调用神经网络模型对接收到的图像进行识别,然后将识别结果返回PS,最后通过串口或以太网将结果输出到主机。
2 系统功能单元设计
下面针对所提基于DPU的手势识别系统,给出各个功能单元的设计方法。
2.1 DPU部署
DPU是一个针对卷积神经网络优化过的计算单元,它采用流水线结构,内部集成了大量加法器、乘法器、非线性器等神经网络所需要的运算单元,可以支持和运行各种卷积神经网络,适用于深层网络的部署。DPU被部署在ZYNQ设备的PL中,并通过AXI总线与PS进行通信和数据交互。
为了适应不同项目的需求,DPU可以对一些参数进行设置,包括DPU核心数、DPU架构、RAM利用率、通道扩展、深度卷积、平均池化等,通过修改这些参数可以根据硬件资源的不同优化资源配置,达到提高PL利用率的效果。DPU的配置信息如表1所示。
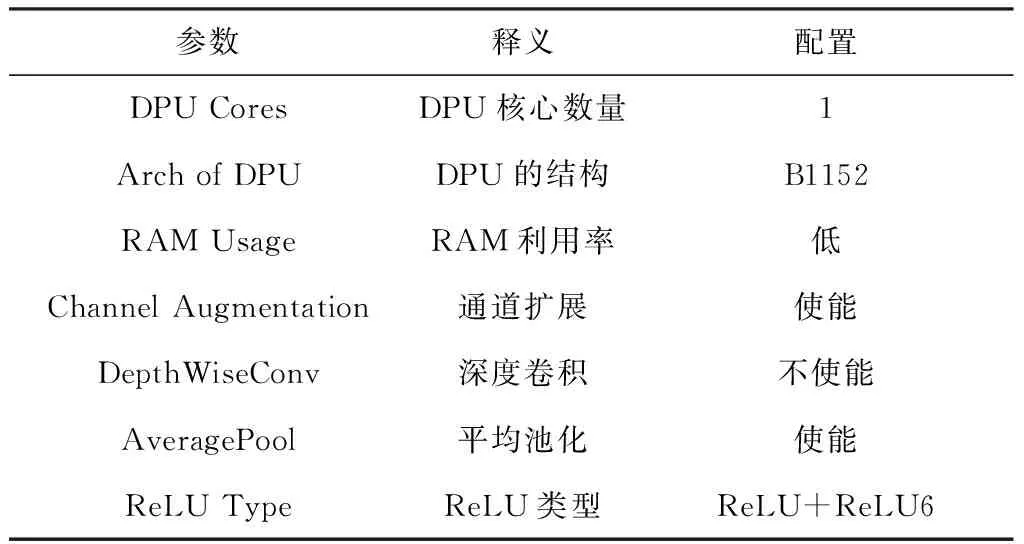
表1 DPU配置
DPU最多可以设置3个核心,由于其为流水线结构,多个核心可以带来更快的处理速度,但同时也会消耗更多的硬件资源。由于实验平台硬件资源限制,本设计只使用1个DPU核心。DPU可以设置不同的卷积结构,如B512、B800、B1024、B1152、B1600、B2304、B3136、B4096等。并行度高的卷积结构的处理速度更快,本文选用B1152结构。在DPU运行时片上RAM会缓存网络的权重、参数等信息,高RAM利用率可以为DPU带来更大的片上存储,也可以一定程度提高系统性能,由于片上RAM不足,本文设置为低利用率。
通道扩展可以提高DPU的处理效率,当输入通道数低于总通道数时,神经网络无法完全使用所有可用的硬件通道,故本设计采用通道扩展以提高DPU的性能。深度卷积可以降低卷积操作时的参数量和运算成本,考虑到深度卷积操作会降低并行度,本设计中不采用深度卷积。DPU的平均池化可以支持2×2到8×8的池化范围,本文采用平均池化。ReLU类型可以设置DPU执行哪种激活函数,我们采用ReLU和ReLU6作为激活函数。
DPU使用了双数据率技术来提高性能,因此需要输入2个时钟,一个时钟是通用逻辑工作所需,另一个2倍频时钟是DSP工作所需。考虑到开发板的实际供电能力,本文选择150 MHz作为通用逻辑工作时钟,300 MHz作为DSP工作时钟。DPU通过AXI总线与PS进行通信,当参数设置完成后,需要给AXI从机接口分配地址,这些地址在系统被DPU驱动和设备树所调用。DPU的地址分配如表2所示。

表2 DPU的地址分配
2.2 神经网络模型
本文采用文献[7]给出的ResNet-50网络作为运行于DPU端的神经网络模型。ResNet网络能够简化深层网络的训练过程,使深层网络在拥有较少参数的同时保持很高的准确率,适合在嵌入式设备中使用。以ResNet-152网络为例,即使它的网络深度远高于VGG网络,却只有很低的参数数量。
ResNet在网络结构上引入残差的概念,允许原始输入的信息不经过下一层而直接传递到后面的层中,在一定程序上保护了信息的完整性。ResNet的残差单元如图2所示。用x表示输入,F(x)表示原始的映射,则引入残差结构后,原始的映射变化为F(x)+x。如果实际所需要的映射为P(x),则只需让原始映射F(x)=P(x)-x就可以达到和正常网络一样的结果。这说明残差网络结构不影响正常网络的识别准确率,但是可以更容易被训练和优化,简化了深度网络训练的难度。

图2 ResNet的残差单元
不同层数的ResNet网络有不同的结构,但从整体上看ResNet网络结构相对固定,都是由上述的残差模块堆叠在一起实现的。ResNet-50网络结构如表3所示。除了Conv1卷积层外,其他4个卷积层均只使用1×1和3×3卷积核,输入数据经过卷积层后再和自身进行残差处理,使得网络更容易被训练。

表3 ResNet-50网络结构
由于神经网络使用浮点数对网络的权重进行存储,而FPGA因其硬件的特性,只能使用定点数,所以需要将浮点神经网络模型量化为定点神经网络模型。同时,由于定点网络模型运行时的计算复杂度低,所以相比浮点网络模型能带来更快的速度和更高的能量效率,能有效地降低功耗。本文采用深度压缩工具(deep compression tool,DECENT)对网络进行量化操作,得到8位定点网络模型。
由于DPU无法直接读取定点网络模型,故需要对模型进行编译。本文利用深度神经网络编译器(deep neural network compiler,DNNC)来编译量化后的网络,得到DPU的可执行文件。
2.3 Linux系统
由于DPU被部署于PL,若程序需调用DPU,就需要在系统中进行相关配置。Linux系统部分负责添加DPU驱动和运行库,并根据DPU对设备树进行修改,为手势识别定制嵌入式系统。
DPU运行时需要调用系统内的相关驱动。为了让其能够正确运行,需要把DPU驱动添加到系统中。为了方便程序的开发,赛灵思公司提供了一套DPU运行库,其包含了DPU相关的API函数,简化了底层器件的复杂性,可以加速DPU程序开发,故把这套运行库添加到系统中。
为能让系统正确加载DPU驱动,我们在设备树中针对DPU设置进行修改,包括寄存器地址、中断号等,使得这些参数和硬件逻辑设计中的配置完全相同,确保DPU驱动的正常工作。DPU的寄存器地址是指DPU被分配的基本地址,根据硬件逻辑设计,本文分配的DPU寄存器地址为0x40000000。设备树中DPU的中断描述由3部分组成,它们包含了硬件逻辑设计中DPU的中断信息。第1部分表示中断类型,0x0代表共享外围中断(shared peripheral interrupt,SPI),0x1代表处理器到处理器中断(processor to processor interrupt,PPI),本文使用SPI中断。第2部分表示系统中断的状态位,ZYNQ的SPI中断如表4所示。由于DPU部署时使用的中断为IRQ_F2P[0],从表中可以得到这个信号将触发61号中断,对应的状态位为29,故本文的中断状态位为29。第3部分表示中断触发方式,0x1指上升沿触发,0x2指下降沿触发,0x4指高电平触发,0x8指低电平触发,本文使用高电平触发。

表4 ZYNQ的共享外围中断
2.4 应用程序
应用程序负责为DPU创建任务,通过相关API函数调用ResNet-50网络对手势图像进行识别。程序流程如图3所示。首先打开DPU,这一步将初始化DPU内核并加载驱动;其次加载编译后的神经网络模型,为模型分配DPU内核;再次将DPU内核实例化,为神经网络创建DPU任务;然后运行DPU,将图像送入DPU内核中进行处理;最后按照相反的顺序依次销毁DPU任务和DPU内核,关闭DPU并释放资源。由于在实验所用平台的DPU不支持Softmax操作,所以先计算Softmax,从而得到识别结果。
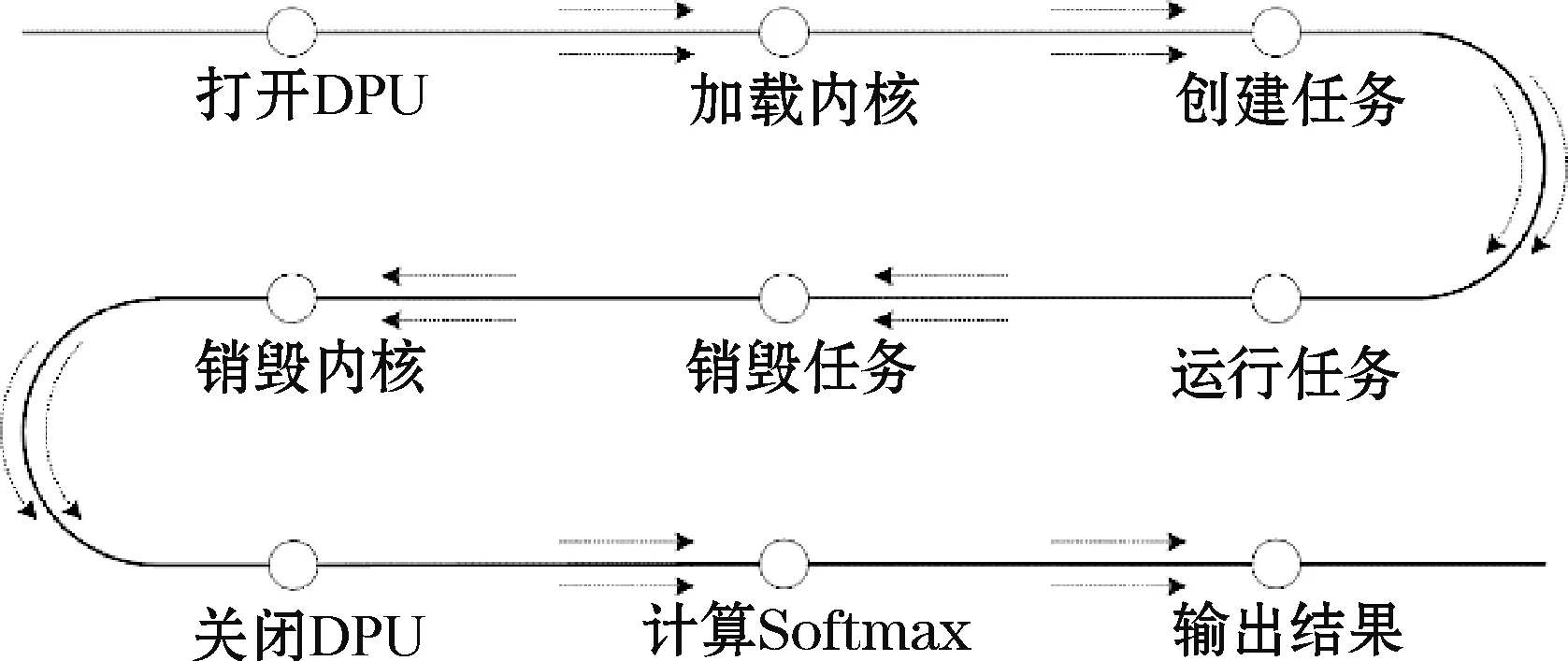
图3 程序流程
DPU的应用程序是一种异构程序,它包含在PS中ARM上运行的代码和在PL中DPU上运行的代码。由于电脑的处理器为X86架构,而ZYNQ上的PS为ARM架构,所以若直接在电脑上编译应用程序,得到的文件将无法在PS上运行,这是由于处理器结构不同所导致的。为了生成能在PS上运行的文件,需要对代码进行交叉编译。本文利用G++编译器对应用程序进行编译,得到可被ARM执行的文件。同时,利用DNNC编译器对深度学习模型进行编译,得到可被DPU执行的文件。当编译完成后把这两个文件链接在一起,生成一个可以被ZYNQ执行的文件,该文件包含ARM和DPU运行的所有必需信息。
3 实验结果与分析
根据前述设计方案,本文研制出一套基于DPU的嵌入式手势识别原型系统,下面给出该系统实验结果。
3.1 实验环境
本文用黑金AX7020开发板作为硬件平台,其FPGA芯片为Zynq XC7Z020,采用软件和硬件相结合的方法进行DPU的部署。先用Vivado设计套件在PL端搭建硬件平台,再用PetaLinux设计工具在PS端搭建软件平台。然后,利用Caffe框架训练深度学习模型后,用DECENT工具对模型进行量化,最后用DNNC工具编译量化的神经网络模型。
本文采用的数据集如图4所示,共4 800张图片,包含了手势0到手势5这6种手势,其中训练数据集有4 320张图片,测试数据集有480张图片。

图4 数据集图片
训练中使用的参数为:固定学习率为 0.001,批量大小10,迭代次数3 000次,momentum为0.9,weight_decay为0.000 1。由于数据集数量较少,采用Finetune方法进行训练[8],使用在ImageNet数据集上预训练的权重作为网络的初始权重。
3.2 实验流程
实验原型系统由逻辑电路、软件平台、神经网络和应用程序组成。逻辑电路部分负责系统的硬件平台设计,将DPU部署到PL,为运行神经网络做好硬件基础。软件平台部分负责进行嵌入式Linux系统的设计,针对系统的特点和需求定制Linux系统,为运行应用程序做好软件基础。神经网络部分负责设计在DPU上运行的神经网络,通过对训练后的网络进行量化和编译操作,得到能被DPU读取和运行的可执行文件。应用程序部分负责设计在嵌入式Linux系统上运行的程序,该程序将手势图片送入DPU中进行处理,得到手势的识别结果。
系统的实验步骤如图5所示。第一步是创建硬件平台,使用Vivado设计套件进行可编程逻辑电路的设计,生成包含硬件配置信息的HDF文件。第二步是搭建软件平台,使用PetaLinux开发工具导入硬件配置信息,在嵌入式Linux系统内核中添加DPU驱动和运行库,生成系统的启动文件boot.bin、image.ub和根目录sysroot。第三步是量化和编译神经网络模型,使用Caffe框架训练手势识别神经网络模型,然后通过DECENT和DNNC工具对模型进行量化和编译操作,得到量化的神经网络模型。第四步是编写应用程序,调用DPU内核进行图像识别,然后将量化后的网络模型、应用程序、sysroot进行交叉编译,最后得到可以在Linux系统中运行的可执行文件。

图5 实验步骤
3.3 实验结果
部署DPU所使用的FPGA资源如表5所示。由于神经网络运行时需要使用DSP对数据进行处理,实验中DSP的使用率达到了88.18%。同时为了提高运算速度,DPU会将中间参数存储在BRAM中,这也导致BRAM的使用率达到83.93%。LUT资源消耗和DPU结构息息相关,受到LUT资源的限制,本文只使用B1152结构而没有选择更高性能的结构。
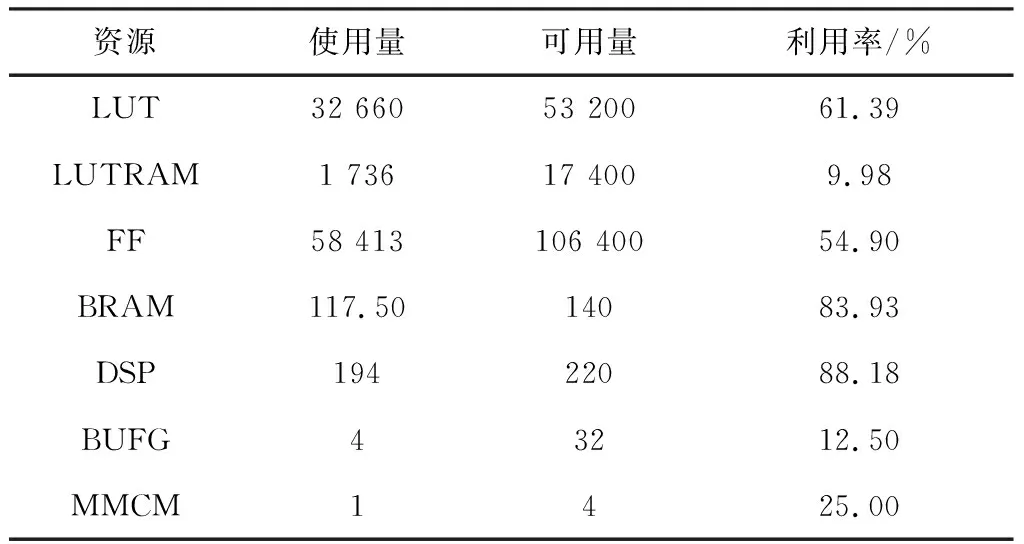
表5 FPGA资源利用率
在数据集上的实验结果如图6所示,图中显示了识别时间、系统性能、置信度、识别结果等主要参数。从图中可以看出该神经网络每次运行需要花费约59.7 ms,识别帧率可达到16帧/s。由于ResNet-50网络运行一次需要进行7.71×109的运算操作,通过计算可以得出本系统的性能为129 GOPS。

图6 手势图片识别结果
DPU对测试集图片的识别结果为:在480张测试图片中,469张图片被正确识别,11张图片被错误识别,识别的准确率为97.7%。与浮点神经网络98.2%准确率相比,量化后神经网络的识别率基本相同。这说明使用DECENT工具进行量化操作对网络的准确率不会造成太大的影响。
表6从网络模型、硬件平台、性能、功耗、能效比等方面与另外3种在FPGA上实现神经网络的方法进行比较。由于高功耗一般会产生高性能,而不同方法间使用的网络结构和硬件平台不尽相同,为了消除不同设备功耗带来的影响,增加能效比这一参数来衡量不同硬件平台间的结果。

表6 与其他在FPGA上的神经网络实现方法的对比
所设计系统在150 MHz的频率下,达到了129 GOPS的性能,通过功率计测得功耗为4.9 W,具有26.3 GOPS/W的能效比,相比于文献[9-11],能效比分别提高了85%、93%、34%。与文献[9]相比,本文在功耗更低的情况下,达到了几乎一致的性能。与文献[10]相比,虽然系统性能存在较大差距,但本文功耗仅不到其20%,在能效比上具有较大优势。与同种芯片的文献[11]相比,本文的频率和性能更高,能耗比更优。与现有3种方法进行比较可以看出,本文设计的嵌入式手势识别系统在能效比上具有很大优势,在同样性能下能达到更低的功耗,这有利于其工程应用。
4 结束语
针对嵌入式手势识别系统难以设计深度网络模型的问题,本文基于DPU提出一种低功耗手势识别系统设计方案。通过将DPU部署在FPGA器件端,调用ResNet-50模型对手势图片进行识别,为嵌入式手势识别系统的实现提供了新的技术路线。实验结果表明,在AX7020开发板上,本文提出的方法在频率为150 MHz时,可以达到129 GOPS的性能和26.3 GOPS/W的能效比,识别准确率为97.7%。相比于现有文献中神经网络的FPGA实现方法,所提方法运行时的功耗仅有4.9 W,在能效比上具有较大优势。
