融合时间因素的协同过滤图书推荐算法
2021-07-17张小雷孙刚彭余辉
张小雷 孙刚 彭余辉

摘 要:随着互联网的遍及以及图书资源的高速更新换代,用户对图书的需求变得越来越大,传统的推荐算法已经无法满足用户及时准确寻找所喜欢的图书的需求。读者的阅读习惯会随时间变化而变化。在协同过滤图书推荐算法中融入时间因素,在计算用户和物品相似度中增加时间衰减函数可以解决读者找书难的问题。实验证明,在协同过滤图书推荐算法中融入时间因素,可以提升推荐的精准率。
关键字:协同过滤;图书推荐;时间因素;精准率
中图分类号:G250.7 文献标识码:A 文章编号:1672-4437(2021)02-0051-04
如今,随着线上和线下大量图书的出现,人们越来越难以寻找自己想要的图书。当读者想要读一本书的时候,传统的做法是去图书馆、书店等线下通过管理员查找或自己寻找,或者是去图书网站线上搜索,有时候读者花费了时间还不一定找得到。图书推荐的出现可以解决读者这方面的问题,可以为不同的读者进行专属推荐,满足其快速且有针对性的查找需求,增加图书阅读率和销量。
协同过滤图书推荐算法通过挖掘读者或图书的历史信息进行推荐,能为读者提供有效的推荐。随着时间的推移,读者的兴趣度、图书的流行度、社会群体的兴趣度等都会发生变化,这个时候如果还按之前进行推荐的话,必然会影响推荐的准确率。在基于协同过滤的推荐算法中融合时间因素,能够有效地反映最近读者或图书的变化情况,为读者提供更加实时的推荐,提高推荐效率。
1基于协同过滤的推荐算法
1.1协同过滤算法思想
关于协同过滤,一个经典的例子是:我们想看一本书但不知道看哪一本,这个时候我们通常会咨询周围的人,当我们发现某个人和我们兴趣相似的时候,我们通常会接受他的推荐,这就是其核心思想。协同过滤算法主要包括基于用户的协同过滤(UserCF)算法和基于物品的协同过滤(ItemCF)算法两种[1]。
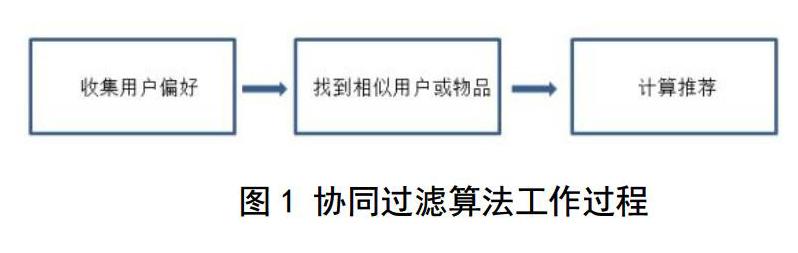
1.2协同过滤算法工作流程
算法流程如图1所示:
1.3基于协同过滤的推荐算法研究现状
1.3.1面临的问题
面临的主要问题有:(1)冷启动问题。由于之前无行为,新用户或新物品进入,不能很好推荐。(2)稀疏性问题。用户一般主动给予的评价较少,在用户评分矩阵中出现很多0值,不能很好地计算相似度,影响推荐精度。(3)扩展性问题。商业网站用户和物品数量庞大,推荐算法计算时间和空间都很庞大,在巨量数据面前,很难做到实时推荐。
1.3.2研究现状
国内外很多学者对传统协同过滤算法出现的问题进行了多种改良。对于用户或物品冷启动问题,可以引导用户表达属性或注册信息,通过给物品打标签分析其属性来解决,也可以直接通过排行榜推荐热门产品来解决。如付文静提出的RC-DFM模型,把评论和内容进行加权融合,缓解了数据的稀疏性,与此同时推荐的准确度也提高了[2],但是当数据集比较大的时候,这种模型的推荐效率会因为时间的增加而降低。王辉等人针对冷启动问题进行研究,把项目的属性和用户的评分结合起来来预测评分[3],给用户进行推荐,但是当新用户来的时候很难进行推荐。杨武等人将基于内容的推荐算法和基于协同过滤的推荐算法相融合[4],提高了推荐的准确率。以上推荐算法可以提高推荐的精确度,但对于需求量宽泛的用户来说,远远无法满足。在“长尾理论”的支持下,大量的不流行的商品的销售量几乎与流行商品的销售量相同,在袁煦聪的研究中,提出了算法item-CF-IIF,通过惩罚热门商品并且优化排序待推荐的物品,能够提高推荐的准确度,同时用户的体验也较好[5]。
2融合时间因素的协同过滤图书推荐算法
2.1推荐算法中的时间效应
日常生活中随处可见时间效应,时间效应对推荐的影响比较大[6]。在图书推荐领域,读者的阅读习惯随着时间推移会发生变化,主要有以下三个方面:一是个人兴趣度随时间变化而变化。比如读者在小时候喜欢读儿童读物,长大之后则对儿童读物不感兴趣。二是图书的流行度会随时间变化而变化。有的图书刚开始出版的时候很热门,读者也很多,但随着热度的下降就会变得不再很流行。三是社會群体兴趣度随时间变化而变化。比如随着推荐技术的发展,读者更容易找到自己想要的图书,从而整体上读者对图书的评分呈上升趋势。
在图书推荐算法中融合时间因素更能反映读者的近期偏好,为读者提供更有针对性的推荐。
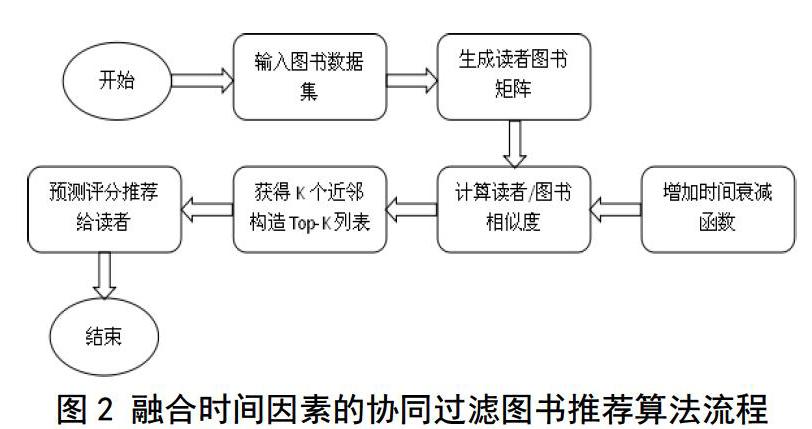
2.2融合时间因素的协同过滤图书推荐算法流程
算法流程如图2所示:
2.3增加时间衰减函数的相似度计算方法
在协同过滤算法中融合时间因素包括在基于用户的协同过滤(UserCF)算法中融合时间因素构造的协同过滤(TF-UserCF)算法和基于物品的协同过滤(ItemCF)算法中融合时间因素构造的协同过滤(TF- ItemCF)算法[7]两种。这两种算法在相似度计算中增加衰减函数的计算方法分别如下。
2.3.1 TF-UserCF算法相似度计算方法
UserCF算法先找“相似用户”再找“相似用户所喜欢的物品”,相似度计算采用余弦相似度计算方法[8],公式为:
和表示用户和用户产生过行为的物品集合。
在冷门物品上有交互更能表示用户相似,所以在公式中加入对热门物品的惩罚项[8],用户相似度公式修改为:
表示产生过行为的所有用户个数。
越是最近的行为越能表示用户当前兴趣,所以在计算用户相似度时加入时间衰减函数,公式如下:
公式中为时间衰减函数,形式为:
式中,为时间衰减因子,表示用户与物品产生交互的时间,表示用户与物品产生交互的时间。
影响大的是当前评分,加上时间衰减函数,最终用户对物品的偏好程度如下:
其中表达式为:
式中,表示当前时间,表示用户与物品产生交互的时间。
2.3.2 TF-ItemCF算法相似度计算方法
ItemCF算法的主要思想是:先找到“相似物品”,再把相似物品推荐给用户。相似度计算公式为:
式中和表示与物品和物品产生过行为的用户集合。
行为较多用户贡献较少,降低其权重,改进为:
)表示用户 的评分物品集合。
在式中增加时间衰减因子函数,改进为:
式中为时间衰减函数。
加上函数,最终公式为:
式中,的表达式为:
式中,表示当前时间。
3实验结果与分析
3.1 实验数据分析
实验使用python语言编程对算法进行实现,使用Book-Crossing数据集,它包含了278858个用户对271379本图书的1149780个评分数据[9]。通过python代码查看用户评分统计可以看出评分范围是0-10分。其中评分前三的人数统计中评分为0分的用户最多,达716109人,其次是评分为8分的人数,达103736人,第三位评分为10分的人数,达78610人。评分统计中评分为1分的人数最少,只有1770人。
3.2 实验评价标准
本次实验中将80%的实验数据作为训练数据,20%作为测试数据。通过精准率(Precision)对实验结果进行评价,Precision表示在预测用户是否喜欢时,正确预测用户喜欢的商品的比例,计算公式如下:
3.3实验结果分析
3.3.1不同K值下的UserCF算法和ItemCF算法的Precision比较
结果如图3所示。从图3可以看出,随着K值的不断增加,UserCF算法的Precision先不断增加后趋于平稳,ItemCF算法的Precision先不断增加再下降。总体而言,随着K值的增加,UserCF算法的Precision高于ItemCF算法的Precision。
3.3.2不同K值下的UserCF算法和TF-UserCF算法的Precision比较
结果如图4所示。从图4可以看出,基于用户的协同过滤算法中融入时间因素构造的TF-UserCF算法和UserCF算法比较,在不同K值下,TF-UserCF算法的Precision要高于UserCF算法的Precision,但优势不明显。所以在基于用户的协同过滤算法中融入时间因素构造的算法的精准率有所提高,但效果不明显。
3.3.3 不同K值下的ItemCF算法和TF-ItemCF算法的Precision比较
结果如图5所示。从图5可以看出,基于物品的协同过滤算法中融入时间因素构造的TF-ItemCF算法和ItemCF算法相比较,在不同K值下,TF-ItemCF算法的Precision明显优于ItemCF算法。所以在基于物品的协同过滤算法中融入时间因素构造的算法精确率明显提高。
以上通过在协同过滤算法中融入时间因素来进行图书推荐,依此来解决随着时间的推移读者的兴趣迁移问题。通过实验证明在协同过滤算法中融入时间因素可以提升图书推荐的精准率,提高图书推荐的质量。但在缓解数据稀疏性方面没有提高,在后续算法中要加以改良,以不断提高图书推荐质量。
参考文献:
[1]趙伟,林楠,韩英,等.一种改进的K-means聚类的协同过滤算法[J]. 安徽大学学报(自然科学版),2016(02):32-36.
[2]付文静.基于评论和内容深度融合的跨域推荐问题研究[D].济南:山东大学,2019.
[3]王辉,姜丹,徐海鸥.基于用户评分和项目属性的稀疏矩阵预测研究[J].电脑知识与技术,2019(02):273-275.
[4]杨武,唐瑞,卢玲.基于内容的推荐与协同过滤融合的新闻推荐方法[J].计算机应用,2016,36(02):414-418.
[5]袁煦聪.基于长尾理论的物品协同过滤推荐算法研究[D].淮南:安徽理工大学,2019.
[6]孙艳.基于协同过滤的图书推荐算法研究[D].镇江:江苏大学,2015.
[7]赵向宇.TopN协同过滤推荐技术研究[D].北京:北京理工大学,2014.
[8]刘恒友.基于时间效应的推荐算法研究[D].哈尔滨:哈尔滨工业大学,2013.
[9]李默,梁永全.基于标签和关联规则挖掘的图书组合推荐系统模型研究[J].计算机应用研究,2014(08):156-159.
