基于改进遗传算法的异构网络资源块分配方法
2021-07-16胡志英
胡志英
(安徽文达信息工程学院, 安徽 合肥 340111)
当前社会对高数据传输速率、低延迟和高能效的需求不断增长,促进了第五代(5G)移动网络的开发和标准化[1],无线通信进入了新的时代.在2.4 GHz和5 GHz未授权频段中已启用了长期演进(LTE)技术,作为下行链路(或上、下行链路)的辅助载波[2].基于LTE和基于Wi-Fi的小区将必须在共享的频谱和空间中共存,这样的网络被称为异构网络(HetNet)[3].
无线资源的分配是HetNet中的重要研究课题.目前,研究人员已经提出了一些无线资源分配机制,例如最优信道质量指标(CQI)、轮询机制、以及比例公平(PF)[4-5].但大部分研究或者没有实现总吞吐量和公平性度量的平衡、或者性能较差,例如在最优CQI方法中,用户设备(UE)始终与高功率基站(BS)相关联[5],由此,用户设备会从高功率基站BS接收到较高的信号噪声干扰,这会造成宏基站过载,并使一些微微基站处于空闲状态;为此,一些研究人员将无线资源分配问题转换为整数线性规划(ILP)问题,如文献[6]提出的ILP方法中,仅对HetNet中的用户关联进行优化,其解决方案提供了最优用户关联组合,但未考虑资源块(RB)分配机制;文献[7]提出同时对用户关联和RB分配进行优化的ILP方法,但由于组合的复杂性,即使对于中等规模网络,其计算复杂度依然非常高,因此,难以高效求得问题的准确解;文献[8]分析了异构超密集网络中用户关联和RB分配的难点;文献[9]提出了基于遗传算法(GA)的LTE下行链路调度程序,以提高视频流的服务质量.GA为基于种群的启发式算法,该算法基于最优者生存原则,用于探索复杂优化问题中的搜索空间[10].但这些研究仅着眼于单个性能度量(吞吐量或延迟)的优化,没有考虑用户关联.
本文提出一种基于改进GA的资源分配方法,同时优化用户关联和RB分配,以最大化网络吞吐量并实现合理公平性的多个优化目标.为将GA用于无线资源分配,将解编码为基因序列,在GA程序的四个主要阶段(初始化、交叉、变异和选择)之外,提供一个额外算子,以管理GA处理过程中产生的非法子代.
1 系统模型
考虑下行链路HetNet环境,其中包括K个单天线UE和B个单天线BS.BS包括1个宏基站(BS1)及其覆盖的B-1个微微基站(pico BS),pico BS有着相同的传输功率和天线增益.设BJ={1,…,B}为所有BS的集合,KJ={1,…,K}为所有UE的集合.将带宽划分为F个大小相等的RB,设FJ={1,…,F}为所有RB的索引集.在使用共信道部署(CCD)的情况下,每个BS使用全部可用带宽.指标αk和βk分别表示用户关联和RB分配.设αk=b表示第k个UE与第b个BS相关联,设βk=f表示将第f个RB分配至第k个UE,其中αk∈{1,…,B},βk∈{1,…,F},∀k∈KJ.将RB考虑为子信道,因此BS将其每个RB最多分配给1个UE.换言之,1个BS仅可服务f个UE.此外,由于采用单天线设计,每个UE最多可与1个BS相关联.该约束表示为:
(1)
式中,thresholding(.,.)为包含两个参数的函数,当两个给定参数相同时,thresholding(.,.)的值为1,否则,该函数的值为0.
2 基于改进GA的资源分配
将无线资源分配的解编码为基因序列,称为染色体或个体.一个基因保存用户关联和RB分配两类信息.遗传算法中的四个主要阶段为初始化、交叉、变异和选择[11].在交叉和变异之后,可能会产生无效基因.对应的用户关联和RB分配无效,对于实际问题的求解无益.为了满足GA算法的完整性和实际问题的求解,有必要对这些无效基因进行修复,使之顺利进入GA算法的下一阶段.因此,增加一个额外阶段,即恢复阶段,以解决无效基因问题.方法流程图如图1所示.

图1 本文方法流程图
本文提出的方法中,基因k为染色体的组件,包含αk和βk两个指标,分别保存用户关联和RB分配信息.将染色体的表示转换到坐标系中.用二维坐标系中坐标为(αk,βk)的点uk表示分配至第k个UE的无线资源,基因k表示为:
genek=uk,k≤KJ
(2)
在坐标系中,x轴表示BS索引,y轴表示RB索引.每个整数点均有一个值,表示特定的UE.由此,将坐标系中的一个整数点视为一个基因.该点表示分配至与特定BS相关联的特定UE的特定RB.此外,假设每个UE最多与一个BS相关联,且BS将每个RB最多分配给一个UE.基于上述假设,确保坐标系中的整数点不会发生重合的约束为:
(ui-uj)2>0,i≠j,且i,j≤KJ
(3)
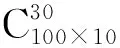
2.1 初始化、交叉、变异和恢复
在初始化阶段中随机生成N个个体.为增加搜索广度,个体数量必须大于UE的数量K.持续对这些个体进行更新,直到满足停止标准.将初始化阶段随机生成的个体转移到二维坐标系中并进行检查,若该基因覆盖了另一个基因,则重新生成该基因.
交叉是GA中的最重要阶段[12].从要配对的每对父代基因内随机选择交叉点,交换父代之间的基因直至到达交叉点,创建出子代,将子代加入种群.通过创建新的个体,可提供搜索多样性.在执行交叉之前,首先需要确定交叉率Rc,即0和1之间的一个浮点数.每次迭代随机选择一对父染色体,同时生成一个随机数,若生成的随机数小于Rc,则执行交叉行为.本文采用的交叉算子是顺序交叉,但交叉运算的对象是二维的,因此,先使用二维坐标系的编码基因(以BS和RB分别为x轴和y轴),然后使用顺序交叉运算.该阶段中可能会产生无效基因,无效基因样例如图2所示.从图2中可以看出,在交叉后,子类1中UE1和UE4的基因有着相同的信息.由于每个UE最多与一个BS相关联(但一个BS可以关联多个UE),且BS将每个RB最多分配给一个UE,因此,UE4的基因是无效的.当生成无效基因时,触发恢复阶段,以修复无效基因.在恢复阶段,打乱重叠的基因,沿逆时针方向将其移动到相邻位置来更改其位置.重复该过程,直至得到有效基因.

图2 在交叉处理后生成的无效基因样例
变异阶段是为了保持种群多样性,防止在成熟前收敛.在某些新子代的形成过程中,新子代的一些基因以较低的随机概率发生变异.与交叉类似,必须先确定变异率Rm,即0和1之间的一个浮点数.每次迭代随机选择一个父染色体进行变异,并生成一个随机数.若生成的随机数小于Rm,则执行变异过程.该阶段中可能会产生无效基因,此时触发恢复阶段,以修复无效基因.图3给出了在变异后生成的无效基因样例.

图3 变异处理后生成的无效基因样例
2.2 选择和停止标准
在交叉和变异阶段后,系统中存在超过N个染色体.在选择阶段,对所有染色体进行解码以得到其信息,再通过适应度函数计算适应度数值V.本文采用吞吐量和公平性度量两种模式的适应度函数,分别使用吞吐量指标TTnorm(标准化总吞吐量)和公平性度量J进行测量.TTnorm可以通过对所有UE的数据速率求和再除以系统理论值获得,理论值由RB的数量决定.J可利用Jain公平性指标[13]计算.TTnorm和J均为数值范围在0和1之间的浮点数.当网络管理员配置了吞吐量(或公平性度量)模式时,适应度函数的目标是通过向高于预定义阈值的吞吐量(或公平性度量)的解提供高优先级,以实现目标吞吐量(或公平性度量).
在适应度函数的操作中,当适应度函数被配置为吞吐量模式时,适应度函数的首要目标是通过向吞吐量指标高于预定义阈值εt的解提供高优先级以实现目标吞吐量,εt为0和1之间的一个浮点数,其数值通常由网络管理员指定.适应度函数的次要目标是对获得了目标吞吐量数值的解最大化其公平性度量.若一个解未取得目标吞吐量数值,则函数将返回吞吐量指标.若一个解达到了目标吞吐量数值,则函数将其数值加1返回公平性度量.由于吞吐量指标为0到1之间的一个浮点数,公平性度量加1将始终大于吞吐量指标.由此将更高的优先级给予满足首要目标的解.因此,该适应度函数确保了在取得目标吞吐量数值的解中选取最优公平性度量,或在没有任何解能够实现目标吞吐量的情况下选取吞吐量最高的解.
使用竞赛方法,选择最合适个体.利用适应度数值对所有个体进行排序,移除数值最低的个体,直至个体数量等于N.通过试验发现,GA总会在迭代次数达到100次之前收敛.因此,迭代次数被设为100.基于GA的资源分配机制总结如下:
Input:N,Rc,Rm,iter;
//N为初始染色体种群大小;iter为停止标准;Rc和Rm分别为交叉率和变异率.
Output:Ch//无线资源分配的解
i=1;
chs.set()=INITIALIZATION(N); //chs为染色体集合
While(i≠iter) do
child.set()=chs.CROSSOVER(Rc); //child集合保存交叉阶段后的子代染色体
if (child.set() is invalid) then child. RECOVER();
chs.add (child); //将child集合加入chs集合
chs.set()=chs.MUTATION(Rm);
if (chs.set() is invalid) then chs. RECOVER();
Ch=chs.SELECTION(); //返回最合适的染色体
i=i+1;
End
ReturnCh;
3 仿真与分析
本文通过进行收敛试验确定交叉率、变异率和初始个体数量,并对公平性度量和总吞吐量之间的权衡进行分析.基于收敛试验得出的数值,对分别使用最优CQI、ILP和本文方法时得出的总吞吐量和公平性度量进行比较.
3.1 试验设置
在仿真环境中,采用LTE下行链路传输方案[14-15],以提供从1.25~20 MHz的可扩展带宽,子载波间隔Δf为15 kHz;传输时间间隔(TTI)时长为1 ms;每个子帧包含2个时隙,每个时隙包含7个符号;RB为BS的资源分配最小元素,其在时域中被定义为1个时隙,在频域中定义为2个连续子载波(180 kHz).LTE下行链路传输方案如图4所示.具体仿真参数如表1所示.

图4 LTE资源分配网格

表1 仿真参数介绍
3.2 收敛试验
在比较不同方法的总吞吐量之前,应确定本文方法的交叉率Rc、变异率Rm和初始个体数N.在适应度函数的吞吐量模式下,通过试验来观察GA的收敛行为.在所有试验中,K、B和F的值分别设为30、9和12.设N=30,Rm=0.6;Rc在0.2到1之间变化,变化增量为0.2,Rc对GA收敛的影响如图5所示.在迭代次数达到20次后,Rc为0.4和1.0情况下的收敛行为相似的.较大的适应度数值意味着GA求得的解能够很好地满足吞吐量模式中的目标函数,即适应度数值越大,利用给定参数获得的GA解的表现越好.从图5可观察到,当Rc为0.8时,GA的解表现较差.因较高的交叉率会造成更大的计算开销,故试验中Rc被设为0.4.设N=30,Rc=0.4;将Rm的值在0.2到1.0之间变化,变化增量为0.2,分析Rm对GA收敛的影响,如图6所示,当Rm为0.6时,适应度数值较优,变异率Rm设为0.6.

图5 交叉率对GA收敛的影响

图6 变异率对GA收敛的影响
3.3 阈值权衡
通过改变总吞吐量阈值,分析总吞吐量和公平性度量之间的权衡.仿真运行500次,UE随机分布在1个宏小区和8个微微小区的覆盖下.用J、TT和V分别表示公平性度量、总吞吐量和适应度函数的标准化数值.J和TT的标准化数值在0和1之间,V值在0和2之间.当总吞吐量阈值低于4 800 kb/s时,J总是高于TT,这是因为可轻易实现最优总吞吐量,GA为寻找合适的公平性度量的解耗费大量时间.当总吞吐量阈值在4 800 kb/s和11 000 kb/s之间时,TT高于J,这是因为GA一半的计算时间用于求解.
图7给出公平性度量阈值在0.0到1.0之间总吞吐量和公平性度量之间的权衡.从图7中可看出:当公平性度量阈值约为0.45时,J线和TT线彼此重合,TT和J的行为发生了反转;当公平性度量阈值高于0.8时,GA的大部分时间用于寻找满足公平性度量阈值的解.因此,公平性度量的数值范围应在0.45到0.8之间.
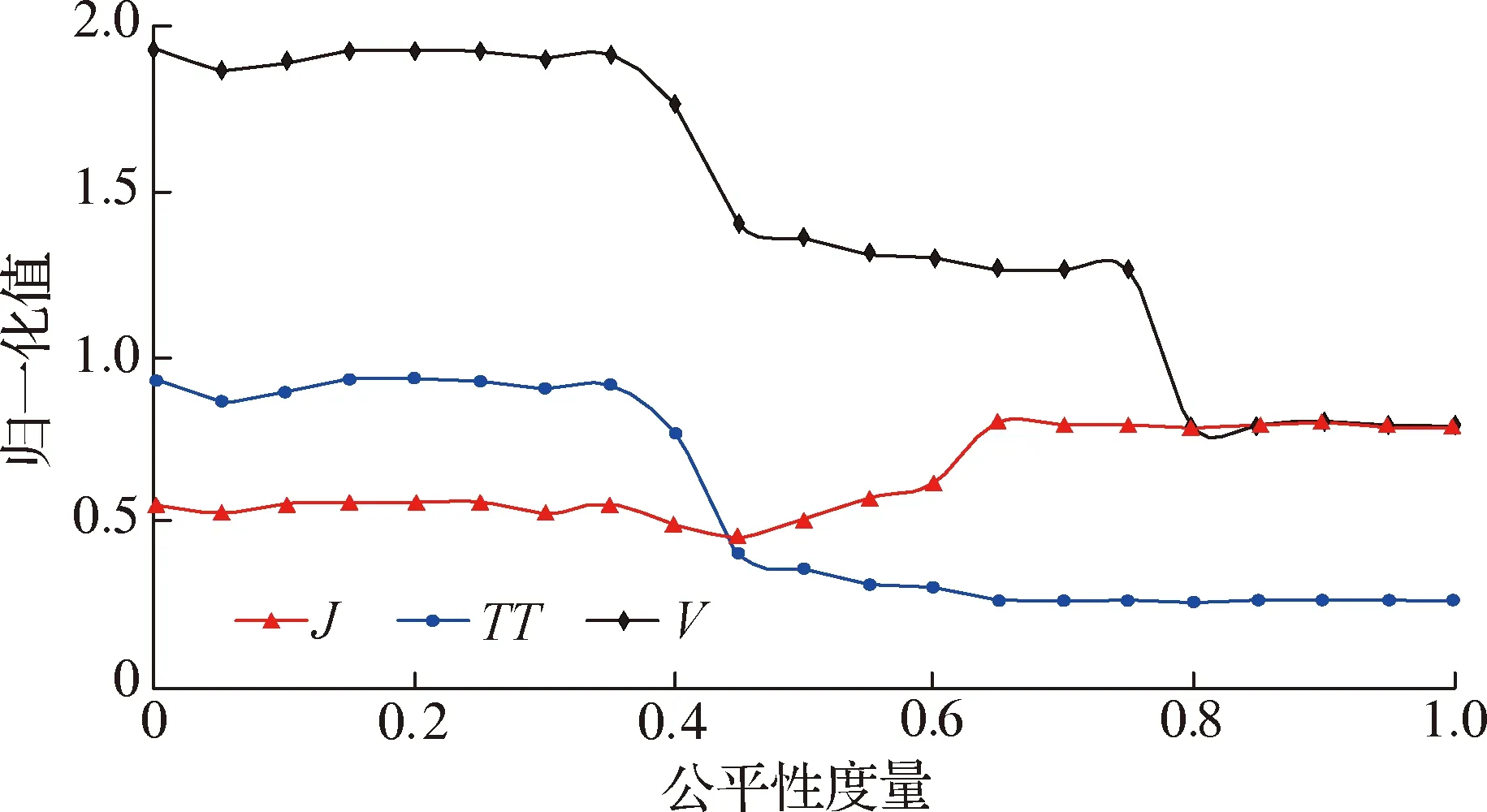
图7 总吞吐量和公平性度量之间的权衡
3.4 比较结果
通过仿真,比较最优CQI方法[5]、基于ILP方法[6]和本文方法在总吞吐量和公平性度量方面的性能.所有GA配置参数如表2所示,仿真时间设为1个TTI,仿真结果如图8所示.从图8中可看出,使用本文方法得到的总吞吐量分别比ILP方法和最优CQI方法所得值高30.1%和35.6%;使用本文方法得到的公平性度量分别比ILP方法和最优CQI方法所得值高31.5%和32.8%.这是因为在最优CQI方法和ILP方法中均未考虑RB分配机制.基于仿真结果可得出结论,通过考虑合适的用户关联和复杂的RB分配,能够改进吞吐量和公平性度量方面的性能.

表2 本文改进型GA的参数列表

(a) 总吞吐量
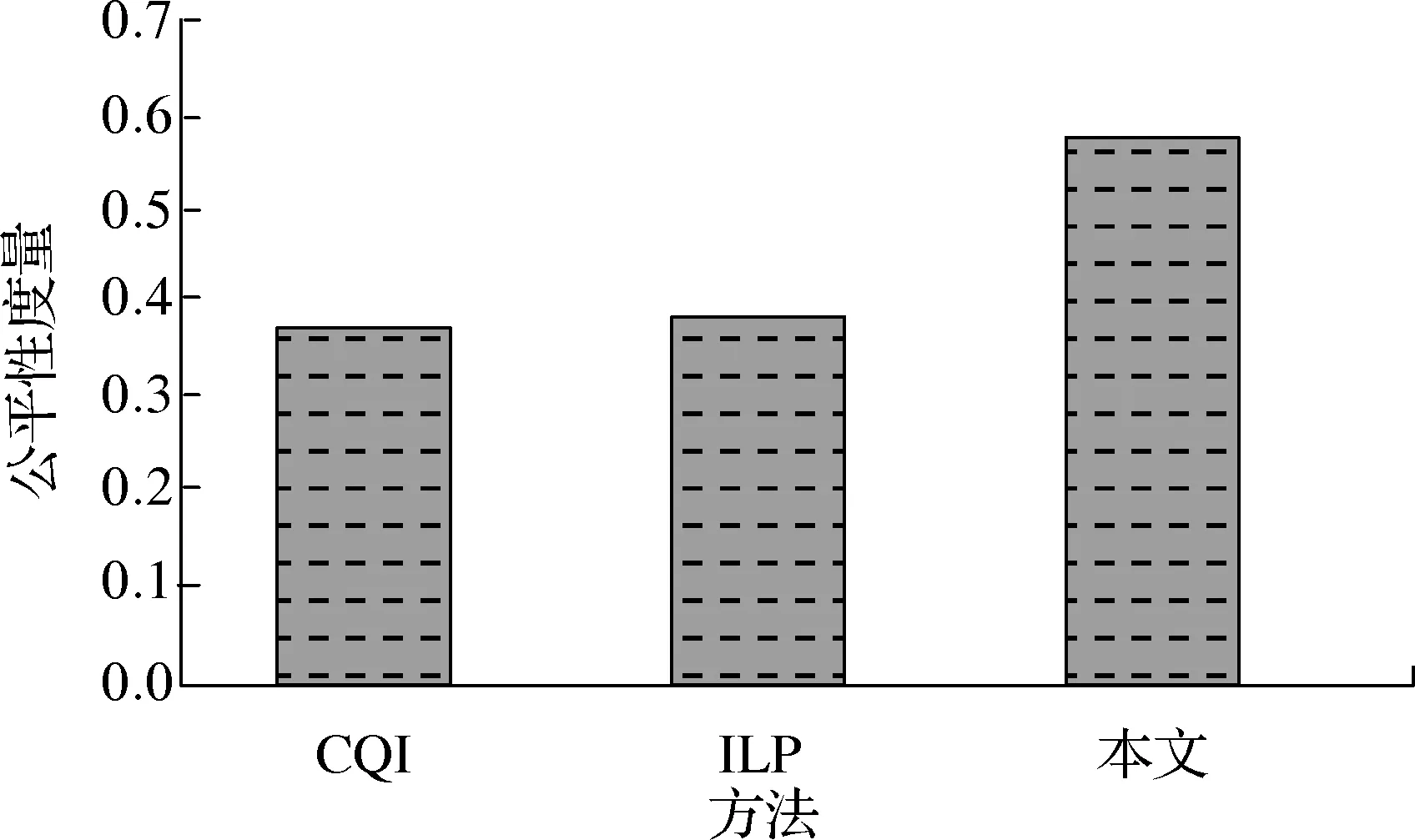
(b) 公平性度量
4 结语
本文提出了基于GA的方法,将无线资源分配至UE.与以往研究不同,本文利用多个目标(包括公平性度量和总吞吐量),同时考虑了HetNet中的用户关联和RB分配,构建资源块分配模型.在使用GA求解时,加入额外的恢复阶段,以调整无效基因.仿真结果表明,本文方法取得的总吞吐量和公平性度量均比ILP方法和最优CQI方法所得值高.
