针对修正余弦相似度改进的协同过滤推荐算法
2021-07-16褚宏林刘其成牟春晓
褚宏林,刘其成,牟春晓
(烟台大学计算机与控制工程学院,山东 烟台 264005)
互联网市场规模的不断扩张,使得信息过载现象愈发凸显。基于用户的协同过滤推荐算法能够对海量数据进行分析,是解决信息过载问题的有效算法[1]。
当前,各类网站以及APP应用等使用基于用户的协同过滤推荐技术为用户提供推荐服务,如何利用协同过滤推荐算法提供高效准确的推荐服务也成为主要研究热点[2]。目前,推荐算法仍然存在着评分预测误差大,导致推荐准确度低的问题[3]。大量的研究者为了解决推荐算法当前面临的问题,继续优化算法,主要从2个方向对基于用户的协同过滤推荐算法进行研究。第一个方向是对协同过滤推荐算法的稀疏评分矩阵处理来进行研究,例如通过对样本数据生成的稀疏评分矩阵,用矩阵分解或矩阵填充等方法,对稀疏评分矩阵进行评分预测[4]。第二个方向是不改变评分矩阵的稀疏程度,寻求在推荐算法中的计算用户相似度部分进行创新或改进。在第一个研究方向上,对推荐算法中的稀疏矩阵处理,有学者提出将SVD奇异值分解的方法用于协同过滤推荐算法[5]。通过奇异值分解,在一定程度上解决了矩阵稀疏带来的推荐不准确问题。 向小东等[6]采用slope-one算法对用户的未评分值进行预测并回填,避免了使用传统填补法造成填补数据单一的问题,同时降低了矩阵的稀疏性。袁卫华等[7]为了解决原始矩阵的稀疏性,首先用填充模型LR-NMF对原始矩阵的未评分项给予填充值,在填充后的原始评分矩阵基础上,进一步实现协同过滤算法。上述学者们提出的算法虽然在一定程度上提高了算法的推荐效果,但是,通过矩阵分解和矩阵填充方式会导致原始矩阵数据损失和难以保证对稀疏矩阵的填充具有一定的合理性等问题,同时仍然采用原有的相似度度量方法,对相似度计算这一关键部分并未改进。在第二个研究方向上,大量的学者主要针对推荐算法中的相似度计算部分进行研究,对目标用户进行合理的推荐,核心问题是如何准确计算用户之间的相似度。通常用Cosine相似度[8]、Pearson相似度[9]以及Tanimoto相似度[10]等传统相似度公式来实现用户之间相似度的计算。文俊浩等[10]在相似度计算中考虑了共同评分项目和所有评分项目之间的关系,对Tanimoto系数进行改进,取得了较好的效果。 陈曦等[11]将用户对共同评分项目时间顺序的影响和用户共同评分项目之间的差异信息熵进行融合,来计算用户的相似度。沈键等[12]提出了二阶段相似度学习的方法,它以既约梯度法迭代寻优的方式,来提高相似度计算精度。李容等[13]考虑共同评分项目数的比例和平均评分2个因素,对协同过滤推荐算法中的Pearson相似度计算方法进行改进。这些研究对协同过滤推荐算法中的用户相似度计算的改进,虽然一定程度上提高了评分预测准确度,但是并没有很好地解决推荐算法相似度计算上对共同评分数量高度依赖的问题,共同评分数量较少时容易产生评分预测误差,导致不能正确推荐。
本文主要在第二个研究方向上做进一步工作,针对基于用户的协同过滤推荐算法中的用户相似度部分进行改进,提出JSD-AC(Jensen-Shannon divergence Adjusted Cosine)相似度计算方法。在传统的修正余弦相似度中引入热门项目惩罚因子,得到改进的修正余弦相似度公式,并将改进的JS散度融合到改进的修正余弦相似度中,形成新的相似度计算方法JSD-AC。在推荐算法的相似度计算部分使用本文提出的方法,得到最终的基于JSD-AC相似度的协同过滤推荐算法。
1 相关工作
1.1 协同过滤推荐算法
当前各类推荐方法在生产生活中得到应用。其中,基于用户的协同过滤算法能够提供较为准确合理的推荐,同时算法稳定,便于实现,得到了大规模的使用。算法主要思想是目标用户利用与其最相近群体对项目的评分数据进行计算,实现目标用户对未评分项目的预测,并根据预测结果产生具体推荐。推荐算法的完整执行流程:
(1)将数据集中用户对项目的所有评分数据构建成一个评分矩阵。其中,m位用户数即为矩阵行数,项目数n表示为矩阵列数,Rua,j为用户ua对项目j的具体评分值。
(2)利用Rmn中每一行的评分信息计算用户间的相似度,任意用户ua和ub之间的相似度Sim(ua,ub)值越大,表示用户关系越相近,得到最终相似度矩阵Sim。
(4)将每个用户的预测值降序后并做推荐。
1.2 修正余弦相似度
修正余弦相似度是一种传统的相似度度量方式,因其本身在计算用户相似度时考虑到评分尺度这一因素,能够避免评分习惯造成的评分偏差,使得度量相似度更加合理,更能准确地挖掘出目标用户的相似用户,被广泛应用。修正余弦相似的计算方法如下:

(2)

1.3 JS散度
JS散度在信息论中,是用来衡量不同概率分布间差异度的指标[14]。在用户项目评分矩阵中,每个用户不同评分等级对应的评分数量构成一个集合,计算出不同评分等级对应的评分数量集合的概率分布,利用JS散度度量不同用户之间的概率分布差异度。
P和Q分别表示任意2个用户评分等级的概率分布,用户的评分等级为I=[1,2,3,…,n],i∈I,S和E分别为任意2个用户在每个评分等级对应的评分数量所组成的集合,Pi表示对评分等级i的评分数量密度:

(3)

给出KL距离公式[15],来度量任意2个概率分布P和Q的差异:
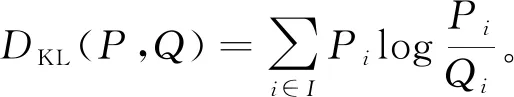
(4)
使用公式(4)中给定的计算方法,计算通过JS散度公式得到的概率分布P和Q之间的差异值,JS散度的计算方法:
(5)
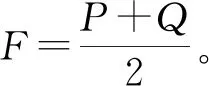
2 基于改进相似度的协同过滤算法
相似度计算是推荐算法的核心部分,能决定推荐的质量。本文对基于用户的协同过滤推荐算法的用户相似度计算部分进行了改进,提出一种计算相似度的新方法JSD-AC。相似度计算部分的改进主要分为3步:
(1)修正余弦相似度公式的改进。考虑到项目热度对相似度计算贡献度的不同,给修正余弦相似度公式添加热门项目惩罚因子。
(2)改进JS散度公式,由于JS散度计算公式本身存在未考虑用户评分总量的不足,改进后得到用户评分等级概率分布的修正因子。
(3)将改进JS散度之后得到的概率分布修正因子和第一步改进之后的修正余弦公式进行融合,形成新的相似度公式JSD-AC。
最终将JSD-AC方法应用到基于用户的协同过滤推荐算法的相似度计算部分中。
2.1 修正余弦相似度的改进
计算用户相似度时,热门项目对用户相似度计算贡献较小,冷门项目对用户相似度计算贡献较大,因此,在修正余弦相似度公式中考虑项目热度对计算用户之间相似度的影响这一因素,能够更加准确地度量用户之间的相似关系。
对于热门项目,多数人都会了解并评分,很难反映是否符合用户兴趣,冷门小众项目更能反映用户兴趣度。因此,在修正余弦相似度中引入热门项目惩罚因子,弱化热门项目在相似度计算中的贡献,强化冷门评分较少项目在相似度计算中的贡献。针对每个不同项目热度,最直观的评价指标是评分数量,评分数量多反映项目热度高,反之则低。
修正余弦相似度公式分子计算的是用户a和b共同的评分项目,给每一个共同评分项目根据项目热度增加一个惩罚因子,项目t评分数量计数表示为countt,给项目评分过的用户总数记为total,惩罚因子punt公式:

(6)
在式(2)的基础上改进后,用户a和b之间的相似度表示为Simco(a,b):
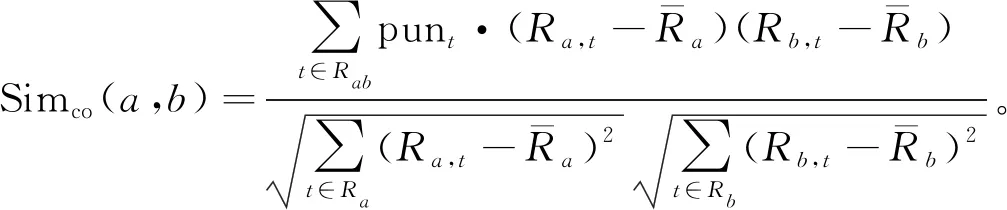
(7)
改进后的修正余弦相似度伪代码如下:
输入:用户a和b的评分向量
输出:Simco(a,b)
(1) for eacht∈[1,2,…,k] do
(2) countt=length(t);

(4) end for
(5) Simco(a,b);
2.2 JS散度的改进
JS散度可以不受共同评分数量的影响,从概率分布的角度衡量用户之间的差异度。为了能将JS散度得到的差异度结果表示为用户之间概率分布的相似度,需要将JS散度公式求得的差异度结果归一化成衡量用户之间概率分布的相似度结果,对公式(5)进行归一化,归一化后用户概率分布相似度Simjs(a,b)表示为
Simjs(a,b)=1-JS(P,Q)。
(8)
其中:JS (P,Q)取值范围是[0,1],P和Q为用户a和b对应的评分等级概率分布。
公式(8)衡量出的概率分布相似度没有考虑用户a和用户b各自总的评分数量之间的差异,当用户a和用户b之间各评分总量差异越大时,会导致公式(8)衡量出的用户a和b之间的概率分布不准确,因此需要考虑用户a和b之间评分总量的差异这一因素。例如,评分等级为1,2,3,4,5任意数值,0表示用户未评分的部分,对于用户a、用户b和用户c,评分集合分别为{1,1,4,4,4,1,1,1,4,4},{4,0,1,0,0,0,0,0,0,0},{1,1,4,4,4,4,1,1,1,4},3位用户评分等级为1和4时的概率密度值都为1/2,概率分布集合都为{0,1/2,0,1/2,0},概率分布相同,因此,通过JS散度公式度量出的用户a和用户b之间的概率分布相似度都为1;但实际上,在概率统计中,大样本数据比小样本数据有更高的参考价值以及可信度,用户b的评分数量的总量少,参考价值低,用户a比用户b更相似于用户c。因此,考虑评分数量的影响,通过评分数量之间的差异度,进一步弱化评分数量差异对概率分布计算的影响。
统计任意用户a和b各自的评分总量为m1和m2,用户a和b之间总的评分数量差异用Dif表示,公式如下:
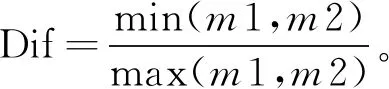
(9)
将公式(9)得到的用户之间评分总数的差异值作为约束条件,对公式(8)改进,用户a和用户b之间的概率分布修正因子为
公式(10)得到G(a,b)作为概率分布修正因子,可以融合到公式(7)中,来解决公式(7)共同评分数量过少导致相似度计算不准确的问题。
改进JS散度伪代码如下:
输入:任意2个评分等级分布集合P和Q
输出:G(a,b)
(1) for eachi∈[1,2,3,…,n] do
(2)Pi,Qi;//normalizing thePandQ
(3)Fi=0.5(Pi+Qi);
(4) end for
(5) for eachj∈[1,2,3,…,n] do


(8) end for
(9) JS(P,Q)=(0.5DKL(P,F)+0.5DKL(Q,F));
(10)G(a,b)=Dif·(1-JS(P,Q));
2.3 基于JSD-AC相似度的协同过滤算法
将改进之后的修正余弦相似度公式,和改进JS散度后得到的概率分布修正因子进行融合,得到新的相似度公式JSD-AC应用到推荐算法的用户相似度计算中。改进的修正余弦相似度公式降低了项目热度对计算用户间相似度的影响,同时融合的JS散度还克服了改进后的修正余弦相似度公式高度依赖共同评分数量的限制,解决了传统计算方法带来的计算误差。
a和b表示任意用户,Simco(a,b)是公式(7)得到的改进修正余弦相似度公式,G(a,b)是公式(10)得到的用户之间概率分布修正因子,将G(a,b)作为Simco(a,b)的权重与之相乘,进一步修正Simco(a,b)的计算结果。最终得到的相似度Simnew(a,b)计算公式:
Simnew(a,b)=Simco(a,b)G(a,b)。
(11)
基于JSD-AC相似度的协同过滤算法实现流程:
(1)对原始的训练集数据集进行处理,将生成的t1行t2列的评分矩阵B作为相似度计算部分的输入数据。
(2)改进传统的修正余弦相似度,考虑热门项目对相似度计算的贡献程度,增加热门项目惩罚因子,将改进后的公式对t1个用户之间的相似度进行计算生成相似度矩阵Simco。
(3)改进JS散度公式,得到的概率分布修正因子G作为权重和Simco进行融合,生成最终的相似度矩阵Simnew。
(4)通过矩阵Simnew,找出与目标用户关系最近的用户,再根据这些近邻的原始评分值,得到目标用户对项目做出预测值。
(5)将用户评分预测值降序排列,取前n个项目作为最终的推荐结果。
算法相关伪代码如下:
输入: 用户项目评分矩阵B
输出:评分预测矩阵E, 推荐列表T
(1) for eacha∈[1,2,3,…,t1] do
(2) for eachb∈[1,2,3,…,t1] do
(3)G(a,b)=Dif·(1-JS(P,Q));
(4) Simco(a,b);
(5) end for
(6) end for
(7) Simnew=Simco·G;
(8) for eachi∈[1,2,3,…,t1] do
(9) us=sort(usneibor,k);
(10) for eachj∈[1,2,3,…,t1] do
(11) ifB(i,j)==0
(12)E(i,j)=pre(i,j,us);
(13) end
(14) end for
(15)T=tui(E(i),n);/*Recommend the topnof the score prediction value to the useri*/
(16) end for
3 基于改进相似度的协同过滤算法
3.1 实验数据
本文将从官网(https://grouplens.org)下载的MovieLens数据集作为实验数据,进行相关实验。MovieLens数据集是明尼苏达大学GroupLens研究组收集的大量真实的用户对不同电影进行的在线评分,并进行整理公布在官网上提供使用。用户对电影的评分为1至5范围内任意一个整数值,用户对电影的喜爱程度越高,评分值越高,反之则低。MovieLens数据集在真实性以及实验数据规模上,都满足实验要求。MovieLens数据集中包含了u1.base到u5.base总共5对训练集,以及u1.test到u5.test共 5对测试集,每对训练集和测试集之间一一对应。5组数据集都分别涵盖了943个用户对1682部电影的评分,每组数据集包含的数据总量都同为100 000条。
3.2 评价指标

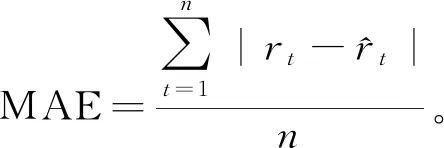
(12)
式中,n表示预测评分集合的样本数量,MAE衡量的是测试集中所有用户已有评分与算法得到的预测值之间的误差大小,通过MAE能够反映评分预测是否准确。
3.3 实验结果分析
(1)推荐算法中使用不同相似度计算方法的MAE比较 为了测试在基于用户的协同过滤推荐算法中的用户相似度计算部分使用JSD-AC相似计算方法的效果,在用户相似度计算部分还分别使用传统的Pearson相似度、Cosine相似度、Tanimoto相似度以及文献[13]中提出的相似度计算方法进行对比实验,比较协同过滤推荐算法在使用不同相似度计算方法下的MAE值。
使用u1.base和u1.test分别进行训练和测试,得到实验结果。推荐算法的最近邻居的取值分别为5,10,20,30,40,50,60,70,80,以MAE值作为评价指标。根据实验结果,对比结果如图1。
根据图1的实验结果,在协同过滤算法的用户相似度计算中,使用本文提出的JSD-AC计算方法与使用图1中的其他的计算方法相比,推荐算法的评分预测误差MAE整体上较小,当邻居数取值大于20时,MAE取值整体趋于稳定,改进后的算法降低了评分预测误差,推荐效果得到提升。

图1 同一数据集下的MAE
(2)改进算法有效性验证 为了验证在修正余弦相似度中考虑项目热度和融合改进的JS散度概率分布因子这2个改进方法的有效性,对2个改进点分别进行验证。在推荐算法的修正余弦相似度计算部分只考虑项目热度的验证用AC1表示。在推荐算法的修正余弦相似度计算部分只融合JS散度概率分布修正因子的验证用AC2表示。将2种情况与未改进修正余弦相似度的推荐算法进行对比,未进行任何改进的算法用AC表示。通过AC1和AC2的验证,来证明公式(7)和(10)改进方法的有效性。数据来源为u1到u5共5对数据集,推荐算法近邻取值为5,10,20,30,40,50,60,70,80,对不同近邻得到的MAE值取平均后,得到平均MAE值作为衡量指标。纵坐标轴平均MAE结果越低,表明算法平均绝对误差越小,评分预测效果越好。
推荐算法相似度部分使用改进方法AC1和AC2进行实验,并与原始方法比较,评价指标为平均MAE。根据实验结果绘制柱状图如图2。
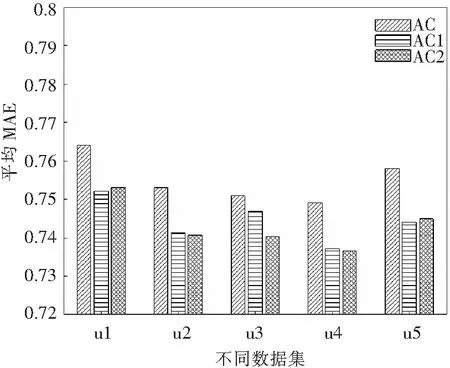
图2 改进方法的有效性验证
根据图2所示的实验结果,协同过滤推荐算法在修正余弦相似度计算中分别只考虑项目热度和只考虑JS散度概率分布因子2种状况时,在5组实验数据集上,算法的平均MAE值均低于未改进相似度状态下的平均MAE结果。表明考虑项目热度和融合JS散度概率分布因子有效,说明2个改进点都对原始算法产生作用。
(3)多组数据集验证 为了验证本文提出方法的稳定性与有效性,推荐算法的相似度部分分别使用本文提出的方法与对比的几组方法进行实验,评价指标为平均MAE。根据实验结果,绘制图3。在基于用户的协同过滤推荐算法的用户相似度计算部分分别使用JSD-AC计算方法和传统相似度计算方法以及文献[13]中提出的方法,比较协同过滤推荐算法在使用不同相似度计算方法下的平均MAE值。

图3 不同数据集下的平均MAE
根据图3中5组数据集的实验对比,使用JSD-AC相似度计算方法的协同过滤推荐算法求得的平均MAE值都低于使用其他相似度计算方法的推荐算法求得的MAE值,多组对比实验结果表明,改进算法效果稳定,能降低评分预测误差,本文提出的方法可行有效。
4 结束语
本文针对基于用户的协同过滤算法核心部分相似度计算提出了一个新的计算方法JSD-AC。首先,在修正余弦相似度计算中考虑到项目热度对相似度计算的影响,增加热门项目惩罚因子,对公式进行改进,得到改进的修正余弦相似度公式。其次,为了进一步解决改进的修正余弦相似度在共同评分数量过少时计算相似度不准确的问题,将改进的JS散度计算出的用户之间的概率分布修正因子作为权重,融合到改进的修正余弦相似度中,得到新的相似度计算方法JSD-AC。最后,在基于用户的协同过滤推荐算法的用户相似度计算部分使用本文提出的JSD-AC相似度计算方法,通过多组实验验证,本文方法较对比方法,能更好地降低评分预测误差,提升推荐效果,具有可行性和有效性。
接下来的工作,将考虑在Hadoop平台上,对本文改进的算法实现并行化。在现有改进算法的基础上继续提高算法的拓展性和运行效率。
