基于知识图谱和BERT的食品案例检索方法
2021-07-16张贤坤李子璇
张贤坤 李子璇 孙 月
(天津科技大学人工智能学院 天津 300457)
0 引 言
当今世界处在一个信息爆炸的时代,在无数信息中高效准确地检索出自己需要的内容成为了人们的普遍需求。例如:当人们遇到一个新的问题时会凭借自己的经验进行推理得到解决办法,而案例推理(CBR)就是让机器模拟人类这种思维的推理方法。案例推理被成功地应用在许多领域,例如:民航突发事件领域[1]、公共危机事件领域[2]、心理咨询领域[3]和地铁运营领域[4]等,但案例推理应用在食品安全领域的研究较少。近年来越来越多食品安全事件的曝光引发了社会大众对于食品安全问题的重视,然而目前利用典型的食品安全案例来指导解决新的食品安全问题的研究处于起步阶段。案例推理方法是将推理与机器学习结合起来,根据过去的经验或案例来解决新问题[5],故而将案例推理应用在食品安全领域会有很好的前景。
案例检索是案例推理过程中的重要一环,已有的案例检索方法有很多,如基于文本特征提取和语义相似度计算的方法[1-2]、基于本体的方法[3,6]和基于聚类建立索引的方法[7-8]等,但是传统的检索方法不能反映案例之间的内在联系。而仅基于知识图谱结构化信息的检索[9],忽略了非结构化的语义,也会导致检索结果不够准确和全面。
为解决上述问题,本文搜集了大量的食品安全相关案例并进行了分析,提出了基于知识图谱和属性特征向量化的食品安全案例检索方法,也是一个新的食品安全案例检索模型。运用知识图谱技术构建了食品安全案例库,利用三元组的形式来表示食品安全案例,进而更直观地展现案例特征及其之间的关系,根据网络结构计算关系相似度。从案例库中获取食品安全案例具有代表性的属性特征,使用BERT语言表示模型将其向量化,利用欧氏距离相似度度量方法计算属性相似度;最后对关系和属性相似度加权求和,得到案例总相似度。所提方法可以高效、准确地处理食品安全案例检索任务。
1 食品案例检索方法
本文主要研究的内容是食品安全案例的检索,传统的案例表示方法直接用文字描述缺乏特征的凸显,故根据案例特点采用知识图谱表示具有直观的效果。虽然知识图谱技术走在人工智能研究领域的最前沿,应用范围也越来越广泛,但在食品安全相关领域缺乏成熟的食品安全案例知识图谱。因此,本文针对食品安全案例的特点进行知识图谱的构建。
利用食品安全案例知识图谱进行案例检索时,不仅要考虑知识图谱的关系结构,还应更多关注案例的语义信息。而一般的知识图谱表示学习方法多偏重于结构的利用,如经典的TransE模型[10]利用三元组的结构信息进行表示学习,将知识图谱中的关系看作实体间的某种平移向量,采用最大间隔法增强知识表示区分能力,处理简单的大规模知识图谱有一定效果,但处理复杂关系效果不好,缺少对实体语义信息的理解,存在局限性。因此,选择用语言表示模型来将文字语义信息向量化,能够有效表示实体属性特征的文字含义,通过对特征向量的计算,可以准确计算出特征之间的差别大小,且计算效率较高,在食品安全案例检索的应用效果较为明显。
1.1 食品案例知识图谱表示
运用知识图谱技术描述案例,构建食品安全知识图谱案例库,可以将多源的、异构的数据连接在一起,直观体现了节点之间复杂的联系。构建食品安全案例知识图谱就是描述案例的属性以及案例之间的关系,利用三元组的形式来表示食品安全案例,三元组的基本形式主要包括(实体-属性-属性值)和(实体1-关系-实体2)。
食品安全案例本身可以当作实体,一些重要特征就可以作为案例的属性,本文中设置每个案例的属性包括案例编号、案例名称、发生时间、食品名、毒物名、案例来源和链接,案例实体总体表示为Case=(id,name,date,foodname,poison,source,link)。食品安全案例以(实体-属性-属性值)三元组的形式表示,以某个食品安全案例为例:(案例-id-10001),(案例-name-商贩使用化工原料桶烤出有毒地瓜),(案例-date-2007/1/1),(案例-foodname-烤地瓜),(案例-poison-化工桶),(案例-source-大连晚报),(案例-link-http://www.39kf.com/focus/spaq/01.shtml)。
食品安全事件大致可以分为6种类型:食品添加剂、非食用物质、禁用农药兽药、微生物、掺假掺杂和品质指标。出现食品安全问题的环节大致可以分为7类:种植养殖、加工、包装、储藏、运输、销售和消费[11]。致病程度可以分为:急性、亚急性、慢性和其他。而发生食品安全事件的地点分为34个省级行政区和多地区,共35类。上述内容以(实体1-关系-实体2)三元组形式表示为4种关系:案例与食品安全事件类型(Cases-CATEGORY_IS-Category);案例与发生地区(Cases-HAPPENED_IN-Place);案例与问题环节(Cases-PROBLEM_IS-Problem);案例与致病程度(Cases-DEGREE_IS-Degree)。还以上文提到的案例举例,关系表示为:(案例-CATEGORY_IS-非食用物质),(案例-PROBLEM_IS-加工),(案例-DEGREE_IS-亚急性),(案例-HAPPENED_IN-辽宁)。
本文共筛选出300个较为有价值的食品安全案例进行知识图谱表示,所有案例特征以三元组的形式存储在Neo4j图数据库当中,构成食品安全案例知识图谱,图1为示例图。图中最小的节点表示案例实体,其他节点展示了部分案例类型实体、问题环节实体、致病程度实体以及地点实体,而有向边标注了关系类型,属性信息未展示。
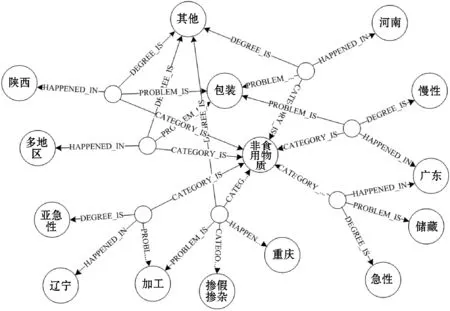
图1 食品安全案例知识图谱示例图
1.2 BERT语言表示模型
语言表示模型是通过文本语料库训练的“语言理解”模型,目的是应用于下游的智能问答、情感分析和文本聚类等自然语言处理(NLP)任务。预训练的优势是在特定任务中使用时,不需要用大量的语料来训练,只需要简单的修改,用特定任务的数据进行一个增量训练,并微调权重,就可以得到有效的向量表示,提高了工作效率。
NLP领域的建模方法分为基于规则的[12]和基于统计的[13],后者解决了前者建模过程中出现的维数灾难、词相似性等问题的同时提高了性能。基于统计语言模型的研究,如:Google在2013年提出word2vec神经语言模型[14],基于深度学习的想法将文字词语通过训练模型转化为N维固定的向量空间,向量之间的相似度可以表示词语的相似度,但固定的向量表示并不能准确表达所有情况下的语义。ELMo模型[15]使用Bi-LSTM[16]语言模型,根据不同的训练集语境,动态生成不同的词向量表示,解决了一词多义问题。GPT模型[17]利用Transformer[18]网络代替LSTM作为语言模型可以更好地捕获长距离语言结构,GPT也是基于微调的语言模型,以半监督的方式来处理语言理解的任务,解决ELMo每个单独任务的参数量过多的问题,但GPT模型仅关注词语左边的内容,表达不够准确。
BERT模型[19]融合了以上模型的优势,运用海量语料数据训练而成,是一个泛化能力很强的预训练模型。BERT模型结构如图2所示,是一种多层双向Transformer编码器,以一串单词作为输入,这些单词不断地向编码器栈上层流动,每一层都要经过自注意力层和前馈网络,然后再将其交给下一个编码器,通过在所有层中对左右上下文进行联合调节,从未标记的文本中预训练深层双向表示,输出的向量即可更准确地表达词的语义信息。

图2 BERT模型结构
BERT模型采用Transformer而不是Bi-LSTM的主要原因是其有更深的层数,具有更好并行性,能更彻底地捕捉语句中的双向关系;并且应用于特定的任务时,无须对体系结构进行大量修改,只需对预训练好的BERT模型进行微调即可得到很好的效果。综上所示,针对本文食品安全案例的属性特征以及内容,选择BERT语言表示模型进行向量化表示,能够更加准确地体现案例的语义信息。
1.3 案例相似度计算
案例检索就是查询案例库中与目标案例最相关的案例,相似度度量方法可以准确表示案例之间的相关性。用知识图谱构建的食品安全案例库,其本质是一张语义网络,节点是实体、概念,边则由关系构成。其中节点的属性特征含有语义信息,运用语言表示模型做向量化处理,再对向量进行相似度计算。而对于边,需要根据食品安全案例的关系特点选择合适的相似度计算方法。
本文方法综合考虑基于知识图谱关系结构的案例关系相似度和基于案例属性特征的属性相似度,分别给予不同的比重,最后得到综合加权的案例相似度。对于两个案例P和Q,用sim(P,Q)表示它们之间的案例总相似度。sim(P,Q)∈(0,1),相似度值越趋近于1则两个案例越相似,越趋近于0则两个案例越不相同。
sim(P,Q)=αsimatt(P,Q)+(1-α)simrel(P,Q)
(1)
式中:simatt(P,Q)表示案例属性相似度;α表示案例属性相似度所占的比重;simrel(P,Q)表示案例关系相似度;(1-α)表示案例关系相似度所占的比重。
1.3.1案例关系相似度计算
案例关系相似度计算是基于食品安全案例知识图谱的关系结构进行的相似度计算。例如,某一案例的关系图如图3所示,此案例的关系有4种:CATEGORY_IS、HAPPENED_IN、PROBLEM_IS和DEGREE_IS。与此案例相连接的关系实体有5个:“品质指标”“微生物”“北京”“加工”和“其他”,其中品质指标和微生物都是此案例的CATEGORY_IS关系实体,由此可以说明案例同种关系的实体节点不唯一。由于发生地点不是计算关系相似度的必要因素,这里不进行地点的关系相似度计算。
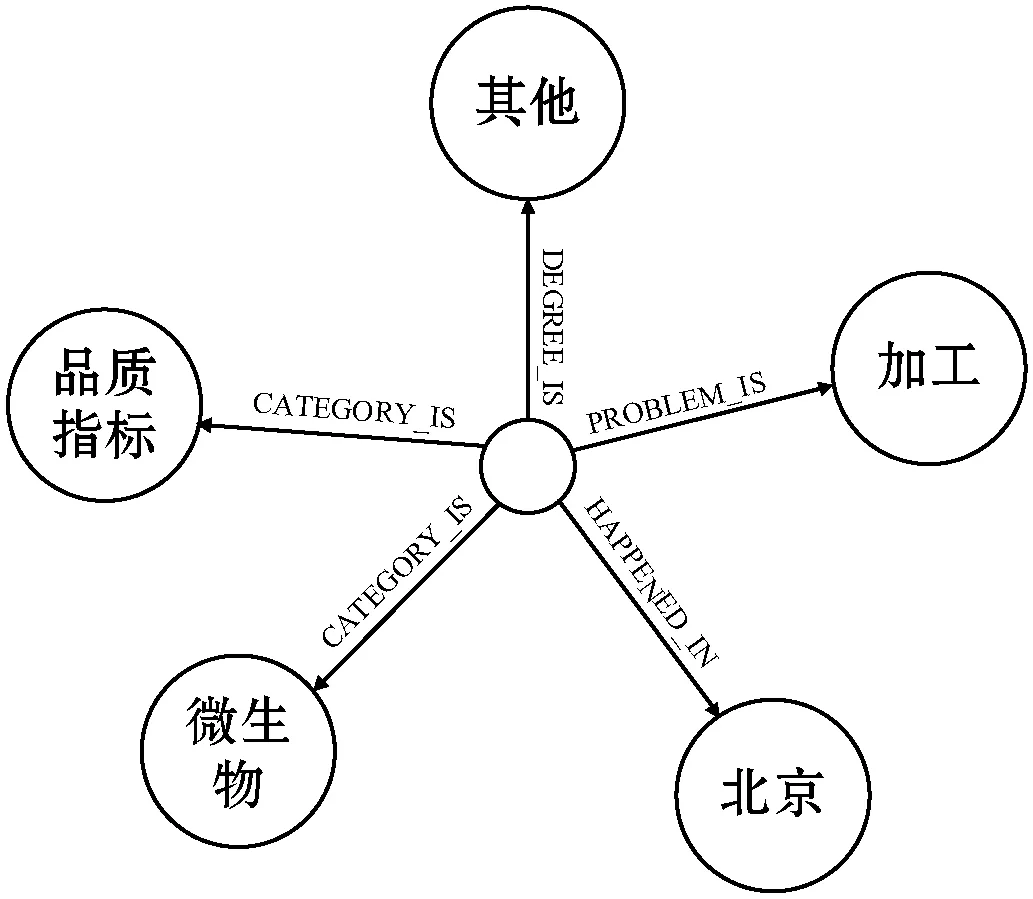
图3 案例关系图示例
Jaccard相似系数[20]适用于有限个数样本集之间的相似性比较。Jaccard系数值越大,样本相似度越高。在食品安全案例知识图谱中,关系的种类有限,关系实体的数量有限,并且对于案例实体与关系实体不一一对应的情况,适合采用Jaccard相似系数来计算食品安全案例关系之间的相似度,用simrel(P,Q)表示,计算式表示为:
(2)
式中:simrel(P,Q)∈[0,1],表示案例P和Q的关系相似度;N(P)表示与案例节点P有关系的实体节点;N(Q)表示与案例节点Q的关系节点。
举个实例,图4为两个相关案例的关系图,可以看出这两个案例有4个共同的关系实体,分别为“其他”“品质指标”“加工”“微生物”,计算关系相似度的过程及结果如下:
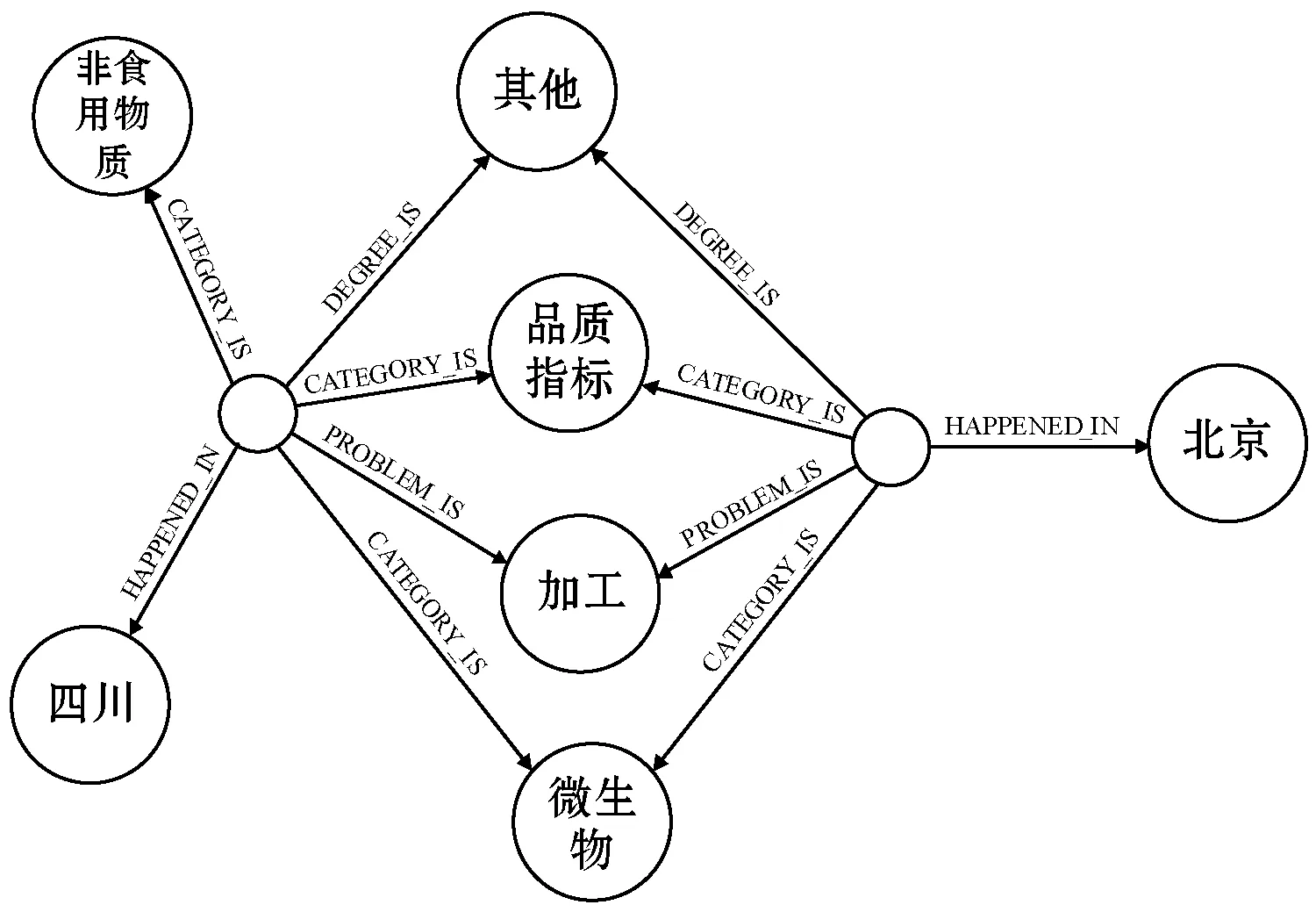
图4 两个相关案例关系图示例
1.3.2案例属性相似度计算
采用知识图谱描述食品安全案例直观表现出来的是实体之间的关系结构,而案例实体的属性值包含更丰富的语义特征,如某案例属性值示例如图5所示。因此在案例检索的任务中不仅要考虑实体之间的关系结构,还要考虑对属性特征的语义信息进行处理计算。

图5 某案例属性值示例
本文从案例中选取有价值的案例属性特征,包括案例名称、食品名、毒物名,可以表示为C=(name,foodname,poison),采用BERT语言表示模型进行文本属性向量化处理,处理结果用于后续计算案例的属性相似度。
在进行文本属性向量化处理后,对于两个案例P和Q,定义VP=(P1,P2,…,Pn),VQ=(Q1,Q2,…,Qn)表示两个案例实体的属性特征向量,分别对每组属性特征向量采用欧氏距离[21]计算属性距离,并根据属性的重要程度分配权重,计算式表示为:
(3)
式中:wi表示分配给第i组属性特征向量的权重,本算法有三组属性特征,故n=3。Distatt(P,Q)∈[0,+∞),表示加权综合的案例属性特征向量距离,当Distatt(P,Q)=0时,表示两个案例属性完全相同。将距离转换为欧氏距离相似度,计算式表示为:
(4)
式中:simatt(P,Q)∈(0,1],表示两个案例的属性相似度,simatt(P,Q)值越大表示案例间属性相似度越高。
1.4 食品安全案例检索算法
本文提出的基于知识图谱和属性特征向量化的食品安全案例检索方法,详细步骤描述如下:
输入:目标案例TargetCase的案例名称nameTar,食品名foodnameTar,毒物名poisonTar,目标案例的关系集合N(Tar);案例库中第k个案例Casek的案例名称namek,食品名foodnamek,毒物名poisonk,案例库中第k个案例的关系集合N(Ck)。
输出:与目标案例最相似的前n个案例。
(1) 使用BERT语言表示模型分别对nameTar、foodnameTar、poisonTar和namek、foodnamek、poisonk向量化,分别得到TargetCase和Casek的属性特征向量VTar1、VTar2、VTar3和VCk1、VCk2、VCk3。
(2) 使用式(3)计算加权综合的案例属性特征向量欧氏距离Distatt(Tar,Ck)。
(3) 使用式(4)将Distatt(Tar,Ck)转换为相似度,得到案例属性相似度simatt(Tar,Ck)。
(4) 使用式(2)计算目标案例的关系集合N(Tar)和案例库中第k个案例的关系集合N(Ck)的Jaccard相似度simrel(Tar,Ck)。
(5) 使用式(1)计算目标案例与案例库中第k个案例的综合相似度sim(Tar,Ck),α取值0.9。
(6) 重复步骤(1)至步骤(5),直到目标案例与案例库中所有案例都进行了案例相似度计算。
(7) 将案例库中所有案例,按照sim(Tar,Ck)的值降序排列。
(8) 取前n个案例,即得到案例检索结果。
2 实验与结果分析
提出的基于知识图谱和属性特征向量化的食品安全案例检索方法是针对食品安全领域的案例检索方法,实验过程分为三个部分,最终验证该方法的有效性和检索结果的准确性。
2.1 实验环境
实验的硬件环境为:Intel(R) Core(TM) i7- 4790 CPU @ 3.60 GHz,内存4 GB;操作系统为Windows 7;集成开发环境(IDE)为PyCharm2019,编程语言为Python。
2.2 实验数据
实验数据的样本集共300条食品安全案例,来源是食品安全类网站以及曝光食品安全新闻事件等网站,爬取结构化和半结构化的食品安全案例,再经过部分人工标注整理,并存储在Neo4j图数据库中,得到食品安全知识图谱案例库。
2.3 属性特征权重分配实验
食品安全案例的众多属性特征中案例名称、食品名和毒物名具有代表性。案例的名称一般较长,在15~25字之间,大多数案例名称是食品安全事件的新闻标题,为了吸引人的关注会突出食品安全事件的特点,部分案例名称中也会出现食品名或毒物名,具有一定的代表性。案例的食品名和毒物名是最为关键的案例属性特征,一般通过这两类属性特征能够大致确定案例类型和问题环节等,非常具有代表性。三种属性综合计算能够更加准确地表示案例的语义信息,因此选择案例名称、食品名和毒物名作为案例的属性特征进行计算。
在计算案例属性相似度的过程中,使用bert-as-service[22]对目标案例和案例库中案例的案例名称、食品名和毒物名这三种属性特征分别进行了向量化处理,bert-as-service使用BERT模型作为句子编码器,并通过ZeroMQ将其托管为服务,从而以快速可靠的方式将属性特征映射为特定长度的表示形式。再分别计算每组属性特征向量的欧氏距离,由于三种属性对于案例本身的重要程度不同,因此分配不同的权重计算案例属性相似度。
随机选取目标案例和对比案例,分别调整属性权重分配情况进行多组反复实验,每组实验以属性相似度计算结果为标准判断权重分配的合理性。举例说明,实验选取某“三聚氰胺”事件作为目标案例,在案例库中随机抽取了10个对比案例(案例1-案例10),案例10为目标案例本身,案例内容如表1所示。
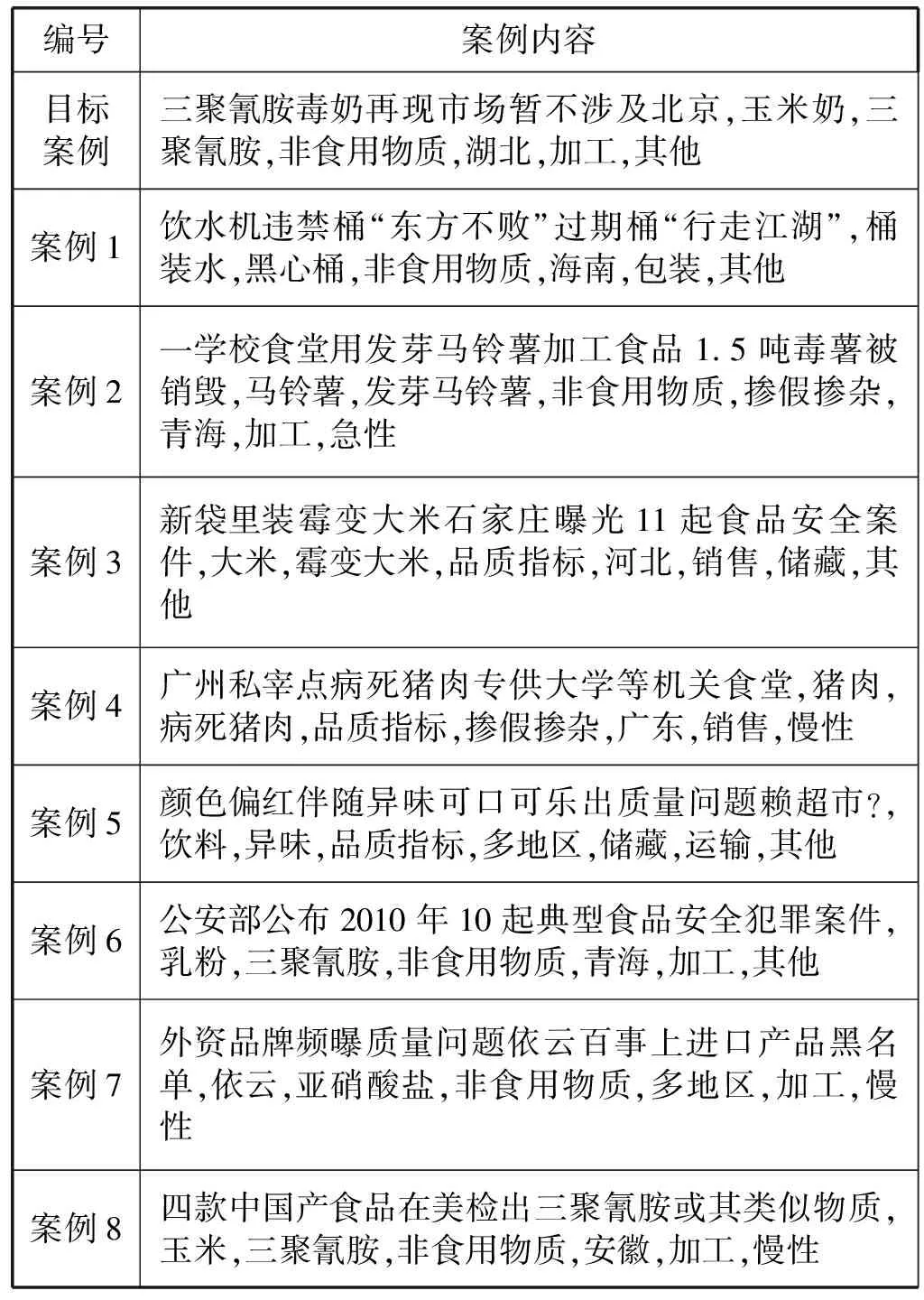
表1 “三聚氰胺”目标案例与对比案例内容

续表1
分别改变三组属性的权重,且保证三个属性特征的权重总和为1,进行对比实验得到不同的属性相似度计算结果。依次计算目标案例与案例1-案例10的属性相似度,结果如图6所示。图6中“权重均分”分配给案例名称、食品名和毒物名三组属性的权重均为1/3;“加权1”的权重分配为0.45、0.45、0.1;“加权2”的权重分配为0.45、0.1、0.45;“加权3”的权重分配为0.1、0.45、0.45。可以看出四种权重的分配下,与目标案例最相似的是案例10、案例6和案例8。由于目标案例与案例10是同一案例,相似度值均为1,验证了该方法的有效性。图中在前三种权重分配下,案例8的相似度值略高于案例6说明案例8与目标案例更相似;而最后一种权重分配下,案例6与目标案例更相似。根据表1的案例内容可以看出目标案例与案例6、案例8均为“三聚氰胺”类事件,而案例6与目标案例的食品名均为乳制品,因此案例6应当较案例8与目标案例更相似。

图6 不同权重的属性相似度
实验结果说明最后一种权重分配更合理,即应该减少案例名称的权重,增加食品名和毒物名的权重。分析原因是实验中比较了食品名和毒物名的重要程度,这二者在不同的角度均反映了食品安全事件的特点,因此设置食品名和毒物名属性特征权重相等。案例名称虽具有一定代表性,但有时为了吸引读者眼球会使用一些修辞手法,具有主观性。食品名和毒物名均相对更加客观,因此食品名称和毒物名称均应该分配较高权重。经过多组实验,案例名称、食品名和毒物名的权重分别为0.1、0.45、0.45时结果最准确。
2.4 计算属性特征向量的方法选取实验
实验随机选取1个目标案例和10个案例库中的对比案例(案例1-案例10),设置案例10为目标案例本身,依次计算目标案例与案例1-案例10的综合案例相似度。改变本文方法中计算案例属性特征向量的方法,即在将案例的属性特征使用BERT模型向量化后,使用欧氏距离相似度与余弦相似度分别计算案例的属性相似度,比较两种方法的效果。改变α的取值,用Jaccard相似度计算的关系相似度分别与两种属性相似度加权求和,得到综合的案例相似度,并对比检索效果。
第一组对比实验与2.3节的实验数据相同,案例内容如表1所示,改变α的取值,用欧氏距离相似度和余弦相似度计算出的综合案例相似度结果如表2和表3所示。
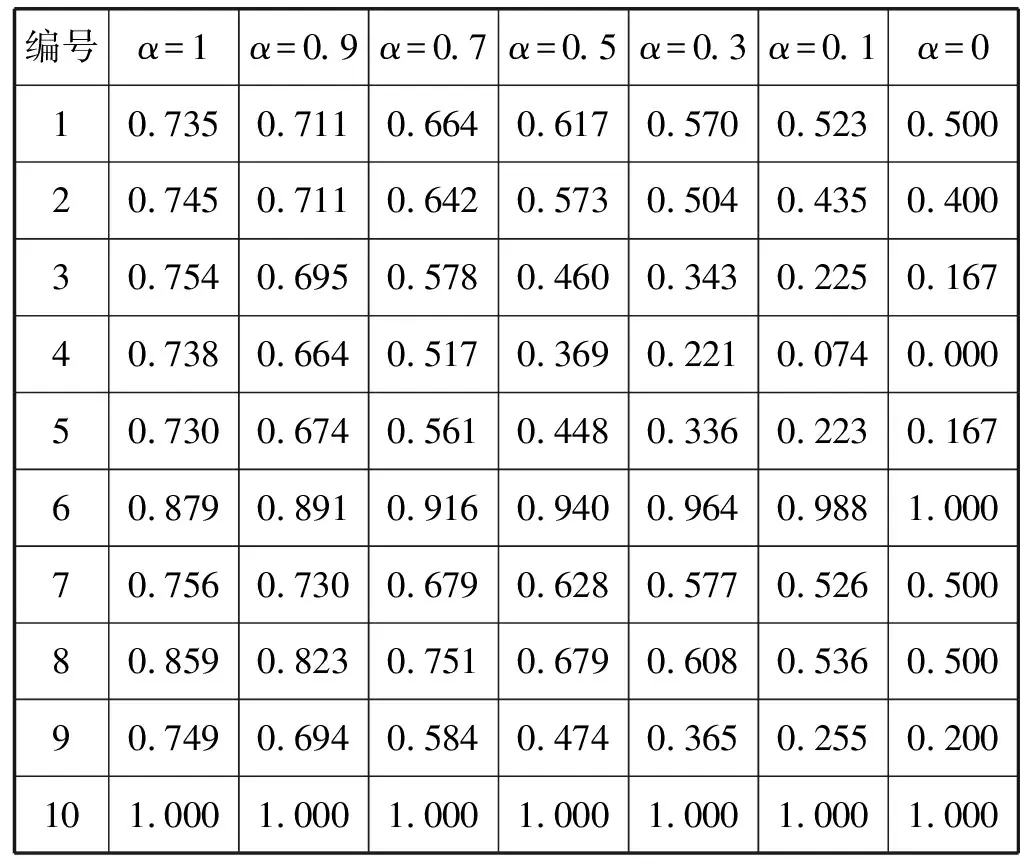
表2 “三聚氰胺”案例使用欧氏距离相似度的结果
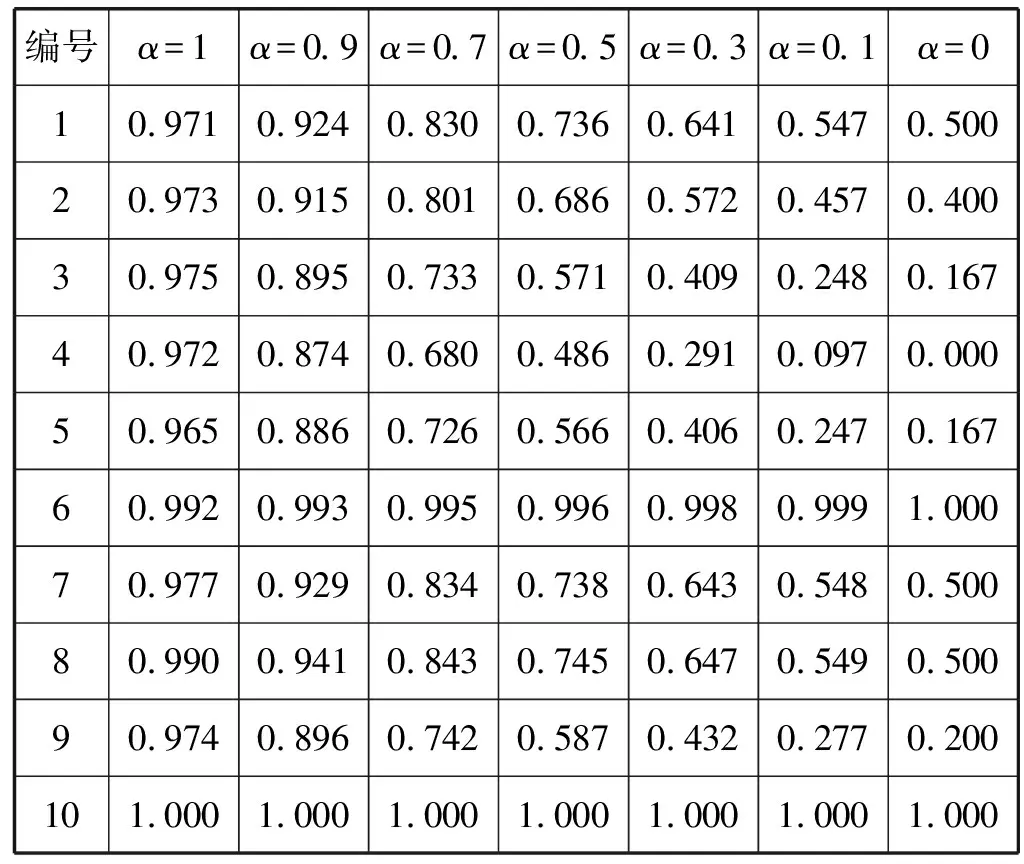
表3 “三聚氰胺”案例使用余弦相似度的结果
将表2和表3的相似度结果用折线图表示,如图7所示。当α取值为1时,由图7(a)和(b)的折线对比可以看出,采用欧氏距离计算的结果更有区分度,能明显得出与目标案例最相似的案例为案例10、案例6和案例8,而使用余弦相似度计算的结果区分度很小。分析原因是余弦相似度注重两案例间的方向偏差,更适用于区分不同领域的案例;而欧氏距离更注重二者的差异程度,因此欧氏距离相似度计算方法更适用于本文食品安全领域的案例检索。
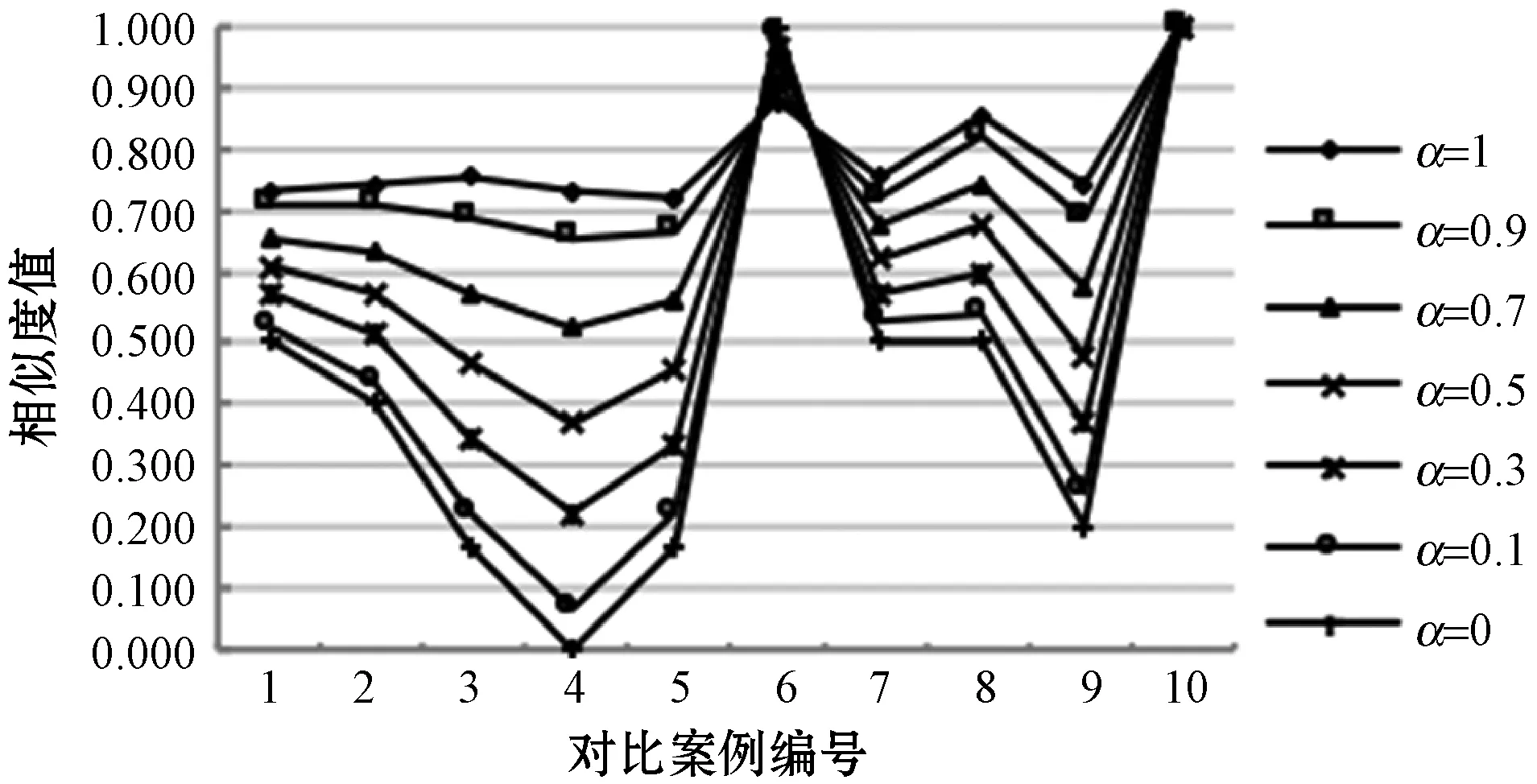
(a) 欧氏距离相似度结果
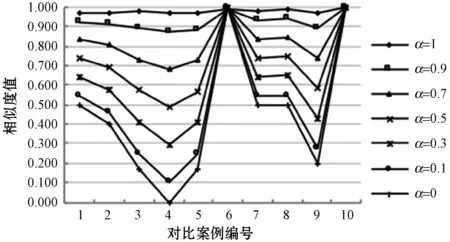
(b) 余弦相似度结果图7 “三聚氰胺”案例结果对比
随着α值减小,(1-α)值增大,由图7可以看出结果的区分度也随之增大,但检索效果并不是越来越准确,例如:目标案例与案例7、案例8的比较,由表1的案例内容明显看出案例8与目标案例更相似,均为“三聚氰胺”事件,而案例7为“亚硝酸盐”事件,但是图7(a)中随着α值的减小,案例7和案例8的相似度值越来越接近,原因是这两个案例对应的关系节点相同导致目标案例与案例7、案例8的关系相似度相同,因此关系相似度的权重越高,越无法区分二者哪个与目标案例更相似。而在图7(b)中无论α值如何变化,目标案例与案例7、案例8的相似度都很接近,检索效果不理想。
当α取值为0时,根据图7的结果得到目标案例与案例6、案例8的相似度值均为1,目标案例与案例1、案例7、案例8的案例相似度均为0.5,查看表1的内容显然是不正确的,分析原因是当α取值为0时,案例相似度仅由关系相似度决定,缺少了属性特征对案例相似度的影响。
为了避免“三聚氰胺”结果的特殊性,进行了多次验证。第二组对比实验选取某“工业盐”事件作为目标案例,在案例库中随机抽取了10个对比案例(案例1-案例10),案例10为目标案例本身,案例内容如表4所示,依次计算目标案例与案例1~10的案例相似度。

表4 “工业盐”目标案例与对比案例内容
改变α的取值,用欧氏距离相似度和余弦相似度计算出的综合案例相似度结果如图8所示。根据表4的案例内容可知与“工业盐”目标案例最相似的是案例10和案例7,次相似的是案例5和案例8。从图8的结果可以看出当α取值为1时,采用欧氏距离相似度的结果比余弦相似度结果更有区分度。随着α值的减小,关系相似度的比重增加,两种计算方法的结果区分度都明显增大,目标案例与案例1的案例相似度也逐渐提高,由表4内容看出案例1不是“工业盐”相关案例,故案例1相似度值不应该高于案例5和案例8的相似度值,图8(a)满足要求。而无论α取值如何变化,图8(b)中的案例1与案例5、案例8的区分度始终不明显,不符合实际情况。
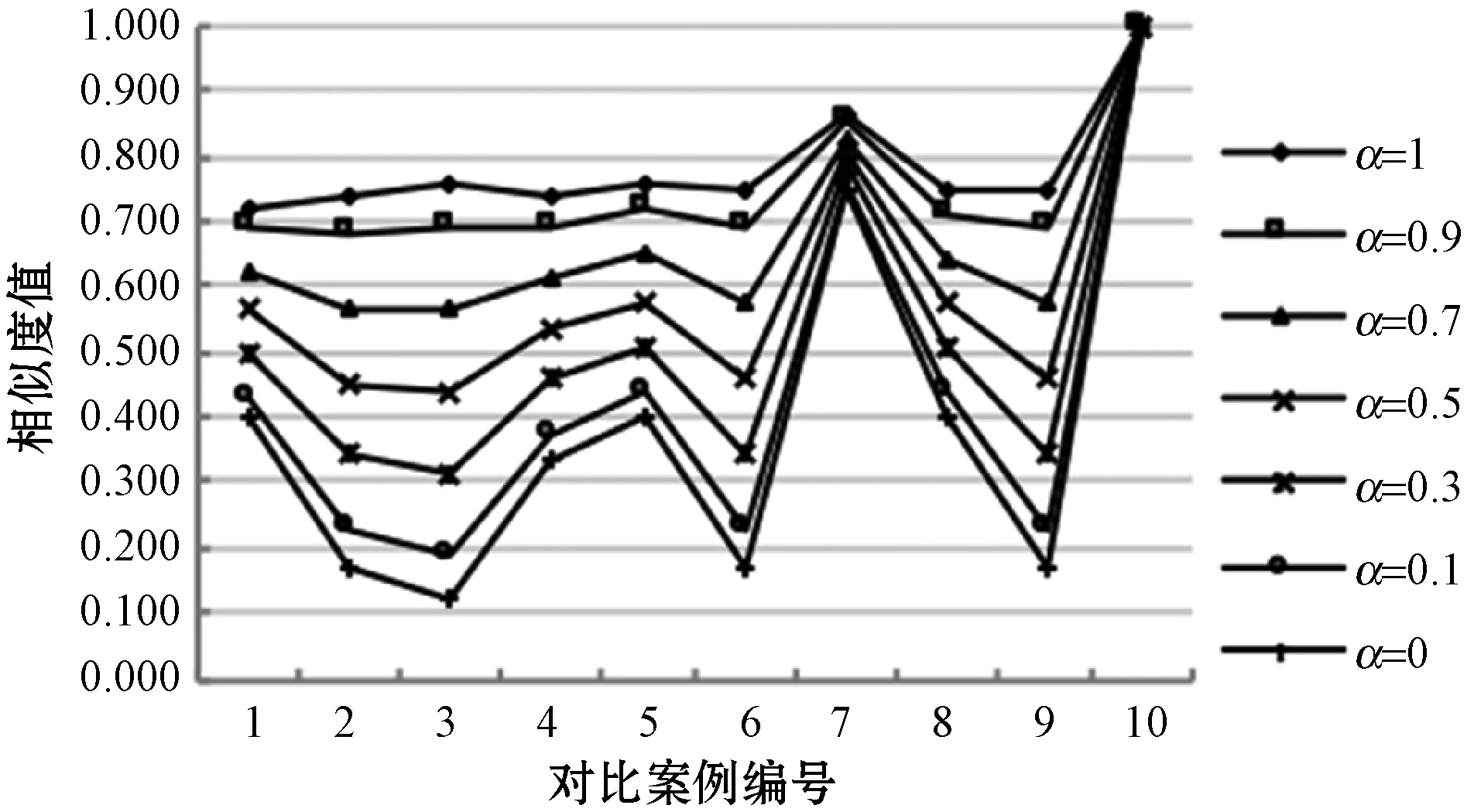
(a) 欧氏距离相似度结果

(b) 余弦相似度结果图8 “工业盐”案例结果对比
第三组对比实验选取某“二氧化硫”事件作为目标案例,在案例库中随机抽取了10个对比案例(案例1-案例10),案例10为目标案例本身,案例内容如表5所示,依次计算目标案例与案例1-案例10的案例相似度。
表5 “二氧化硫”目标案例与对比案例内容

续表5
改变α的取值,用欧氏距离相似度和余弦相似度计算出的综合案例相似度结果如图9所示。根据表5案例内容可以看出与目标案例最相似的是案例10和案例8,而当α取值为1时,图9(a)的结果比图9(b)的结果更准确,但随着α值的减小,关系相似度的比重增加,案例5的相似度值逐渐增大,甚至高于案例8的相似度值,不符合实际情况。
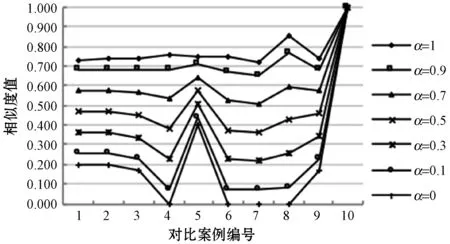
(a) 欧氏距离相似度

(b) 余弦相似度图9 “二氧化硫”案例结果对比
因此,经过多组实验验证,对于本文食品安全案例的检索方法,采用欧氏距离相似度方法更适于计算案例属性相似度;并且当α的值取0.9,(1-α)的值取0.1时,即案例属性相似度的权重为0.9,关系相似度的权重为0.1时,能够得到最准确的案例检索结果。
2.5 案例检索实验结果
本文提出的基于知识图谱和属性特征向量化的食品安全案例检索方法采用BERT语言表示模型将食品安全案例的属性特征向量化,并用欧氏距离相似度方法计算出加权综合的案例属性相似度,同时使用Jaccard相似度方法计算出案例关系相似度,再将属性相似度和关系相似度加权求和得到案例相似度,根据案例相似度值进行降序排列,得到案例检索的结果。
使用本文提出的方法进行案例检索,随机取5个不同的目标案例,分别与案例库中300个案例进行案例检索。由于案例样本数有限,这里取排名前5的案例作为检索的结果,实验结果如表6至表10所示。其中表6目标案例为“湖北‘三聚氰胺玉米奶’事件追踪,玉米奶,三聚氰胺,非食用物质,湖南,加工,其他”;表7目标案例为“路边卖的蜜饯凉果七成不合格,路边蜜饯凉果,二氧化硫,食品添加剂,山东,储藏,慢性”;表8目标案例为“两男子生产假食用盐坪山销售被检察院起诉,食盐,工业盐,非食用物质,掺假掺杂,广东,加工,其他”;表9目标案例为“国内养殖业抗生素滥用触目惊心检测却仅针对出口,养殖业,抗生素,禁用农药、兽药,多地区,种植养殖,其他”;表10目标案例为“北京市场检查发现有毒海丝螺中毒者已治愈,海丝螺,麻痹性贝类毒素,非食用物质,北京,销售,亚急性”。

表6 “三聚氰胺”事件案例检索结果

表7 “二氧化硫”事件案例检索结果

表8 “工业盐”事件案例检索结果
表9 “抗生素”事件案例检索结果

表10 “中毒”事件案例检索结果
由表6至表10的案例检索结果可以看出,与目标案例越相似的案例排名越靠前,验证了所提方法的有效性和准确性。同时对照结果查看了案例库中所有案例,验证了结果的全面性。
3 结 语
本文根据食品安全案例的特点,采用三元组形式表示案例的属性特征和关系结构,从而构建了食品安全知识图谱案例库,并设计了案例检索方法,验证了检索的有效性、准确性和全面性。然而,在此工作的基础上,还需要获得更多案例样本来扩充案例库,构建完善的知识图谱,并且考虑加入“发生地点”等更多的食品安全案例特征,进一步提高案例检索的准确率和效率。同时,在知识图谱的扩展和应用方面本文方法还具有一定的局限性,如何对食品安全案例进行更加详细合理的知识表示与知识的计算、推理还需要进一步研究。
