深度学习在遥感影像云检测中的应用
2021-07-15徐少壮钟来星
徐少壮,钟来星
(1.山东科技大学 测绘与空间信息学院,山东 青岛 266590;2.山东科技大学 能源学院,山东 泰安 271000)
0 引言
遥感技术的快速发展带来了海量的数据,但是ISCCP(international satellite cloud climatology project)的研究表明[1],地表的年平均云覆盖率超过66%,云层遮盖了光学遥感影像的部分、甚至全部的地表信息,这不仅严重影像数据质量,甚至制约了进一步挖掘数据的潜力,对遥感影像后续处理也同样是一个挑战[2-3]。因此,对云的高精度定量化评估是一项很重要的工作。
云与地物在光谱、纹理特征方面存在较为明显的区别,基于此许多学者实现了光学遥感影像云检测。李微等[4]通过云与下垫面其他地物在可见光、近红外谱段的差异,提取云覆盖区域,但是该方法对于波长范围受限的影像具有一定局限性。李超炜等[5]将分形维数、灰度共生矩阵等多个影像特征作为分类标准,通过输入SVM实现云检测,但是实验结果与云覆盖区域轮廓匹配程度较低。除此之外,图像分割领域的传统算法同样适用于云检测,比如最大类间分类法[6]、超像素分割法[7]、区域生长法[8-9]等。传统算法对噪声、目标像元的差异十分敏感,而高分辨率遥感影像往往伴随一定的白噪声[10],所以对高分辨率遥感影像进行云检测具有一定的局限性。遥感影像语义分割是从计算机视觉中延伸出来并结合深度学习实现遥感影像分类、地物提取的技术,相比于传统算法,深度学习具备更好的云检测精度和可移植性。2015年,Olaf等[11]首次提出U-Net网络结构,实现了显微镜细胞影像的高精度、高效率识别,在此基础上,学者们将改进后的网络结构应用于三维医学影像分割[12]、多类别影像识别[13-15]等方面,为遥感影像云检测提供了新的思路。陈洋等[16]通过卷积神经网络实现了云检测,在传统池化模型的基础上,针对云的特性提出了一种自适应模型,提高了训练效率、检测精度,但是云检测结果轮廓识别精度较低,不能很好地保留碎云、薄云细节特征。裴亮等[17]基于改进的全卷积神经网络实现了遥感影像云检测,相比于全卷积神经网络,该方法提高了训练速度、云检测精度和收敛效果,但是存在将雪误判为云的情况。么嘉棋等[18]利用神经网络SegNet实现ZY-3影像云检测,改善了传统算法对噪声敏感的缺点,但是对于薄云、碎云存在一定程度的漏检,需要进一步改善。张永宏等[19]结合U-Net以及残差模块实现了FY-4A影像云检测,提高了对薄云、碎云的识别精度,但识别精度仍有进一步提升的空间。
针对传统算法对高分辨率遥感影像噪声敏感、深度学习算法检测结果与人主观感受不一致,碎云、薄云识别精度差等缺点,本文结合U-Net和 TTA(test time augmentation)算法进行云覆盖区域提取,与现有算法相比,提高云检测精度的同时,极大限度地保留了碎云、薄云的细节特征。首先,对影像进行预处理,包含数据标注、制作样本集等步骤;其次,基于U-Net神经网络结构提取云的典型特征、训练检测模型;最后,利用TTA算法处理待检测影像,并送入U-Net检测模型中实现云检测。
1 理论与方法
1.1 深度学习原理
1)神经网络结构U-Net。U-Net作为一种用于图像分割的网络结构,相比于其他结构,它的优点在于简单高效、模型参数少,仅使用少量影像训练,就可以得到较高的检测精度。整体上看,U-Net是收缩-扩展结构,收缩过程采用FCN的网络结构[20],由卷积层、池化层组成,主要用于提取影像的典型特征;而扩展过程由卷积层、反卷积层(上采样层)组成。U-Net在图像分割领域首次使用反卷积层恢复特征图和复制、剪切原始特征图拼接的特征融合方式(图1中间横线连接步骤),其结构图如图1所示。
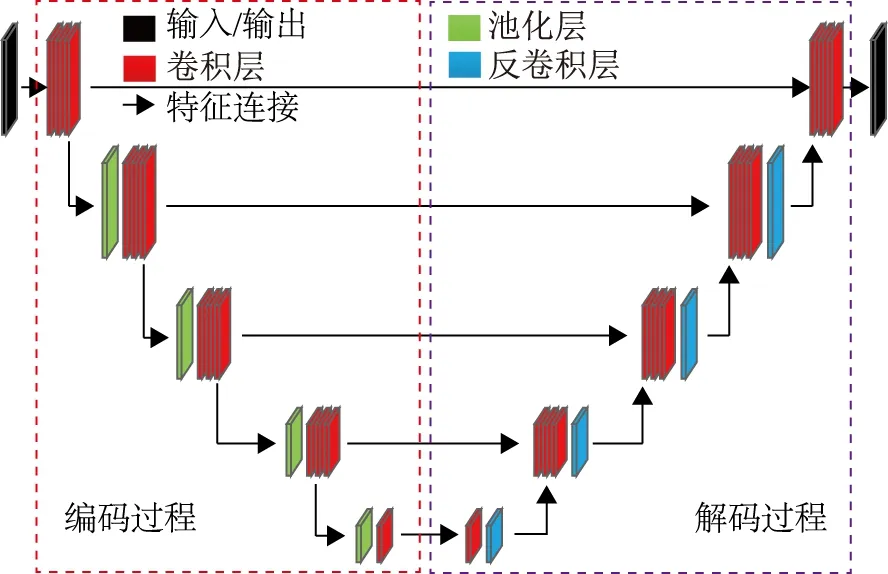
图1 U-Net结构示意图
(1)卷积层(convolotion layer)。由多个卷积单元组成,卷积单元在窗口影像上移动,通过点积,累加获取影像深层次特征,并以特征矩阵的形式传递。单一卷积层仅能获取影像浅层特征,多层结构可以通过浅层特征迭代获取云的深层次、典型特征,并通过共享卷积核权值传递特征。
(2)池化层(pooling layer)。主要目的是减小卷积层所获取的特征维度,减少训练参数以提高模型训练效率,进而防止过拟合现象出现。常用的池化模型分为平均池化、最大池化模型两种。
(3)上采样层(upsampling layer)。卷积层会提取影像的典型特征,同时将输入影像转换为更小的尺寸。上采样层会将输入转换为更大的尺寸,将典型特征放大到原影像大小,使提取后的特征图更能代表云标签的特征。
(4)特征图(characteristic map)。影像上每个像素判断为云、背景的概率称为特征图。U-Net的创新之处在于:不仅通过先收缩、再扩张特征图的方式获取影像的典型特征,还在每个部分直接获取U型结构对称部分的特征图(U型图中间横线部分),这种融合多张特征图的方式最大限度保存了云的类别特征。
(5)Softmax层。主要目的是实现分类、归一化处理,并评价神经网络训练是否收敛,达到最优训练效果。本文采用Softmax分类指标、交叉熵作为损失函数。Softmax回归模型是logistic回归模型在多分类问题上的推广,在多个案例中均取得了较好的效果。式(1)是Softmax值计算方法,Si为对应的Softmax值,当αi代表的值远大αk时,Softmax值逼近1;当αi代表的值远小于αk时,Softmax值逼近0,实现了输入特征分类归一化。
(1)
式中:T代表类别数,在二分类问题中取值为2;αi代表输入向量中第i个元素;αk代表输入权值向量中元素之和。
Softmax模型采用交叉熵作为损失函数,衡量神经网络训练效果,如式(2)所示。
(2)
式中:Pi是Softmax模型的输出值Si中的第i个元素;yi是一个一维向量,以0、1的形式保存像素的标签识别信息。通过观察loss和精度,可以及时掌握神经网络训练效果,并通过调整相关参数提高训练效率。
2)测试增强算法原理。测试增强(test time augmentation,TTA)是一种在机器学习中应用广泛的技术[21],输入经过裁剪、旋转、映射压缩等处理待检测影像,增强其典型特征,以提高识别精度。尽管经过多轮训练、多次迭代后,云检测模型逐渐收敛,准确率趋于饱和,但是仅将待检测影像输入模型中,可能由于典型特征被局部泛化等原因引起云区域漏检,所以对待检测影像进行TTA处理是十分必要的。图2是本文设计的TTA流程:①将待检测影像经过旋转、色彩映射等处理得到8张增强数据,将其与原影像依次输入云检测模型;②将云检测模型输出的特征概率图执行步骤①中几何操作的逆变换,恢复待检测影像平面坐标;③对9张特征概率图进行求和、平均运算,最终输出云像元概率图。
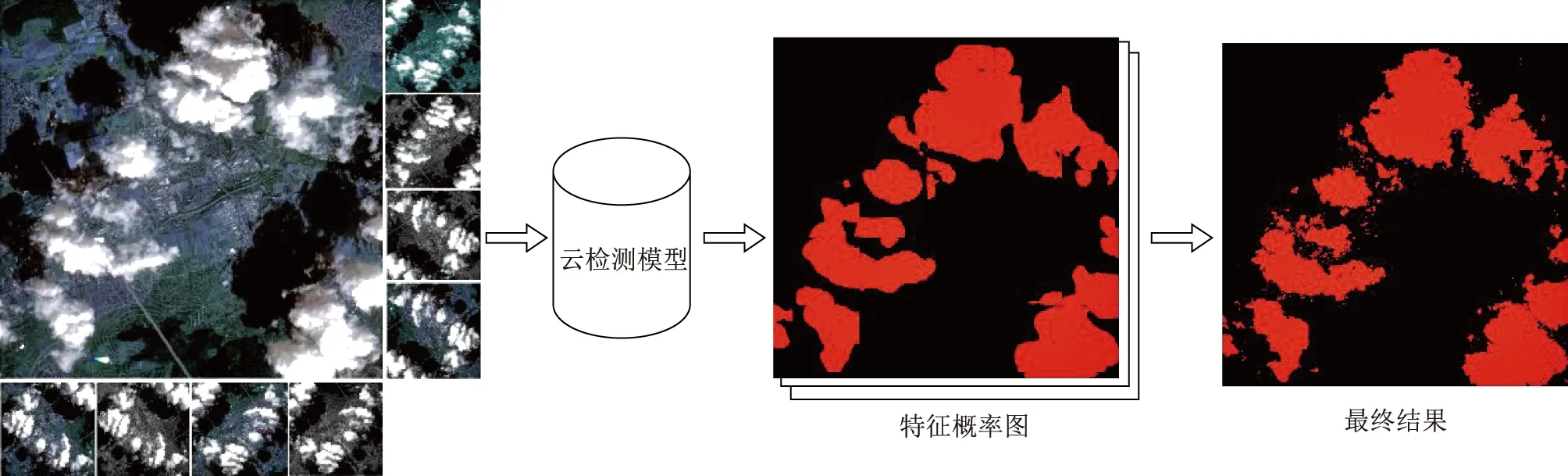
图2 TTA技术流程图
1.2 实验过程
1)数据预处理。本文采用Tensorflow机器学习框架进行实验。该框架是一款深度学习框架,它封装了很多深度学习工具,如Estimator、Keras等,并提供了良好的可视化功能[22]。语义分割是在图像分割领域下为解决多分类分割提出的概念,旨在通过深度学习高精度地提取多地物轮廓。语义分割神经网络通过提取训练集中的典型特征训练模型,当经过多轮训练模型测试达到饱和或较高的精度时停止训练。其中,训练集的大小、数量、是否涵盖不同种类地物典型特征对训练结果均有一定的影响。一般而言,需要对影像进行一定的预处理。预处理主要分为数据标注、影像分割、数据增广三个部分。
(1)数据标注。数据标注的主要目的是为待训练影像上每个像素划分类别。以云检测为例,借助Labelme等数据标注软件[23],将遥感影像上云覆盖区域勾勒矢量边界,在生成的标签文件中云覆盖区域像素被划分为1,其他区域被划分背景像素,赋值为0。选取云量大于50%的高分一号、资源三号卫星全色影像作为实验数据,依次标注影像,用于制作样本库。图3为数据标注示意图。

图3 数据标注示意图
(2)影像分割。影像分割的目的是为了选择合适的影像大小,以便于神经网络训练。待分割大小取决于显卡的配置、神经网络的设置等参数,一般在64、128、256、512、1 024像素等数值中取值。本实验选择将影像分割为256像素×256像素的小块,当整景不足以继续分割时,舍弃这一部分影像。
(3)数据增广。数据增广的目的是为了增加训练集的数量,便于神经网络提取样本库主要特征。通过旋转、加椒盐噪声、形态学变换等处理,将训练集的数量级增大到较大的基数。本实验中,通过自定义的数据增广函数(如先随机旋转、添加白噪声等处理),将样本库数量扩大至20 000张影像。
2)训练神经网络。在已经确定神经网络结构基础上,训练神经网络仍需确定一些重要参数,这些参数与实验结果息息相关,有的依据经验、有的需要经过反复测试才能确定最优值。本实验将训练集的0.75用于训练模型,其余0.25用于验证模型精度。batch_size确定为4,epoch为30。batch_size的取值往往为2的次方,取值取决于显卡的性能、为每个训练轮次投入的影像数量。epoch为训练集整体投入神经网络的轮数。随着epoch的增加,准确率逐渐增大,直至其饱和,趋近于变化缓慢时,epoch取值为最佳,一般而言,初始值会偏大一点,当趋近于饱和时可手动取消训练。图4是训练U-Net神经网络过程中训练模型时的损失值(train_loss)、准确率(train_accuracy),验证模型精度时的损失值(val_loss)、准确率(val_accuracy)的变化线性图。由图4可知,训练过程中loss持续下降,从0.25下降到0.095 8;精度持续上升,从0.897上升至0.963。验证模型精度过程中loss持续缓慢下降,从0.219下降到0.177;精度持续上升,从0.912上升至0.937。

图4 训练神经网络过程中loss、精度的变化线性图
如上所述,上述实验实现了U-Net云检测模型训练,且保持了较高的云检测训练精度。在此基础上,如何实现输入影像云检测较好的效果仍然是个难题。应用广泛的方案为:①将整景影像读入,创建一个与原始影像大小相同的空白图像;②从遥感影像左上角开始,依次切割256像素×256像素影像送入模型中,并输出对应的类别概率图。但是该方案有一定概率在分块间存在拼接痕迹,影响云检测效果。因此,本文在步骤②的基础上,每次分块保持与上一次存在50%的重叠度,以减少拼接的影响,得到初步云检测结果。
采用TTA技术提高云检测精度。首先,依次将待检测影像与对应的8张增强图输入U-Net云检测模型;其次,依次获取9张影像对应的云检概率图;最后,对9张特征概率图求取每个像素的平均值,输出最终云检测结果,并进行着色。相比于传统U-Net地物提取方案,本文所采用的设置一定重叠度、TTA技术能提高云检测精度,使云覆盖区域轮廓识别精度更高。
2 实验结果与分析
如图5所示,本文方法在实现云检测的同时避免了细小噪声的干扰,并高精度地保留了云轮廓细节特征。高分辨率遥感影像具有丰富的纹理信息,但同时因为分辨率较高会带有白噪声,而Otsu等传统算法对噪声敏感,进行云检测时会不可避免地受到噪声的影响。图5(b)中黄色圆框部分显示Otsu云检测确实受到了这些细小噪声的影响,同时将下垫面与云近似的建筑物误识别为云,本文方法避免了这一缺点,同时保证了较高的云检测精度。

图5 Otsu与U-Net结合TTA对比分析
如图6所示,当输入单景影像时,U-Net保持了较高的云检测精度,且没有将建筑物等与云灰度相近的地物误识别为云,但是碎云、薄云存在一定的漏检,这是因为从待检测影像中提取的特征输入模型时,由于角度、灰度映射关系等原因导致被忽视。在经过TTA处理后,云轮廓识别精度得到提高,与人主观感受更为一致。在单景影像中经过TTA处理后,云检测精度得以提升1%~2%,所提升的精度主要与云在影像中所占的比例有关,但不可否认的是,TTA提升精度的同时增加了计算所需的时间。

图6 TTA处理前后对比
为了评价各算法云检测精度,分别在多张影像上进行了云检测,与人为勾勒的标准云图进行对比分析,并计算出了各个指标的均值。包含以下三个评价指标:①OA为总体精度,以人为判断的标准云图为准,判断各算法准确识别云的概率;②Dice_index为过分割系数,可以评价云检测结果与标准图之间边缘是否相符,数量越大轮廓越吻合;③Jaccard_index为杰卡德系数,是图像分割领域常用的评价分割效果的指标,是与人主观感受比较一致的量化指标。上述指标不仅能准确判断云识别精度,还可以评价云轮廓识别精度。如表1所示,综合各个指标,U-Net结合TTA算法的云检测精度高于传统算法约5%。
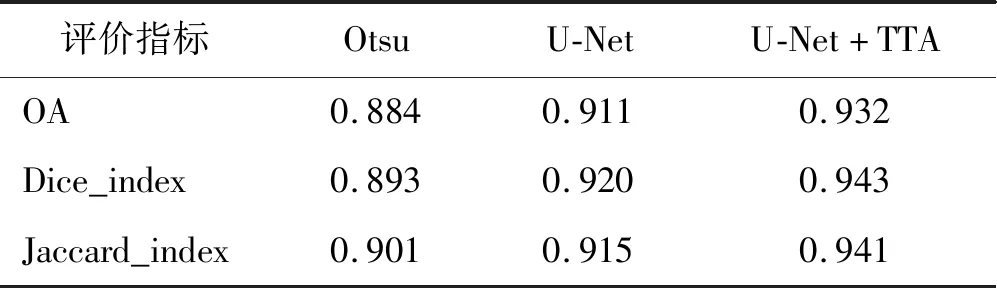
表1 U-Net云检测结果对比
3 结束语
针对传统云检测算法对高分辨率遥感影像噪声敏感这一问题,本文提出一种U-Net结合TTA的方法。实验结果表明,该方法检测精度达到93.2%,高于Otsu等传统算法约5%。相比于传统算法、仅使用U-Net的方法,本文算法对薄云、碎云等不同类型的云均有很好的检测效果,同时保留了云轮廓细节特征,与人的主观感受更一致,具有更高的云检测精度。
深度学习在遥感影像云检测方面虽有较大优势,但仍存在很大的改进空间,表现在以下两个方面。①模型融合。自U-Net结构提出后,影像分割领域出现了各具优势的新型结构,结合这些方法与U-Net模型的识别结构,可以兼具二者的优势,提高模型识别精度。②结合云的更多特征。本文仅使用了云的纹理特征作为识别的标准,而遥感影像还具备丰富的光谱、空间等特征,值得进一步挖掘。
