基于混合数据聚类算法的异质顾客群体识别
2021-07-15谢卫星王晓琳王旭阳张静娜李玉鹏
谢卫星,王晓琳,王旭阳,张静娜,李玉鹏
中国矿业大学 矿业工程学院工业工程系,江苏 徐州221116
顾客需求是产品/服务研发的根本动力,完善的产品/服务方案应满足和超出顾客期望,甚至创造新的顾客需求[1]。在新产品/服务投放市场至演化成熟的过程中,企业需要对顾客满意度进行测度。有关顾客满意度的研究在产品/服务工程领域由来已久,测度方法主要分为两类:结构化模型(如结构方程模型)[2]和评价决策模型[3]。结构化模型的研究重点在于探索顾客满意度的影响因素及其关联关系,建模过程复杂,结果可靠性难以保证,因此,越来越多的研究者开始转而关注基于评价决策模型的顾客满意度测度[4]。
顾客是评价决策过程的主体,顾客评价是一种顾客主动表达信息的途径,其中蕴含了产品的优势与不足,以及潜在的期望,充分分析顾客评价有助于准确地预测顾客需求。目前,顾客评价的研究主要为评价信息挖掘,如李实等[5]通过数据挖掘技术对顾客评价和态度进行了分析,实现了针对中文评论的产品特征信息挖掘;Greco 和Polli[6]介绍了情感文本挖掘在品牌管理领域的应用,展示了此过程的潜力,给出了顾客在产品偏好、表示和情感方面的特点;Liu[7]提出了一种新的文本分类模型对文本数据进行最大影响、中等影响和最小影响三个特征的分类,进而对顾客进行了准确的分类;Balbi 等[8]提出了一种新的社交媒体用户满意度的评价策略,通过评论排序实现了考虑用户体验的产品/服务方案评价。关于顾客评价信息挖掘的研究相对丰富,但对于异质评价群体本身的研究仍不完善。顾客作为一类特殊的决策者,其评价信息的搜集与处理要借助满意度量表(在线评论/调查问卷),用以对其模糊的感知评价进行量化。但受其年龄、职业、心理状态及成长经历等主、客观原因的影响,决策者往往具备不同的风险态度[9]和边际效用,进而使得其评价观点表现出不同特征,最终对顾客满意度产生影响。部分学者对顾客评价的特征进行了研究,例如,Wang等[10]提出了一种启发式深度学习方法从客户产品评论中提取情感意见,实现了顾客评价的多重情感分类,获得了七对情感属性;李玉鹏等[3]在顾客满意度测定中引入了一种不均衡语义量表,目的在于更加准确的捕捉顾客在评价过程中偏好分布的非均匀特性。可见,从决策者的角度对顾客进行分类,进而捕捉其相应的评价特征具有重要意义。
顾客评价特征表现为评价信息的多元性、冲突性等,其根本原因是顾客作为决策者的异质性[11]。顾客的异质性来源于顾客本身的特质,例如,年龄、受教育程度、职业等。当顾客具备相似特质时,则会形成一类具有显著特质的决策群体。当顾客决策群体的特质具有显著性差异时,其评价也会形成不同的评价类别[12],所以,企业亦可通过识别异质顾客群体来更加准确地预测顾客需求,在此基础上进行产品再设计[13]。对异质顾客群体进行识别对于准确捕捉其评价特征,设计相应的评价模型及量表,从而获得更为准确的顾客满意度信息具有重要工程意义。
本文将顾客定义为决策群体,考虑影响其异质性形成的关键因素,基于混合属性聚类方法实现异质顾客群体的分类识别。首先将顾客定义为数值-分类属性共存条件下混合属性描述的空间向量,进而设计初始聚类中心的确定方法,构建统一相似度度量指标,最后引入惩罚竞争机制,结合混合属性聚类算法实现异质顾客群体的识别。
1 异质顾客群体识别方法框架
如前所述,影响顾客异质性的因素有很多,在对顾客进行分类时,要综合考虑这些因素,并将其定义为聚类分析过程中的聚类属性。显然,上述属性既包含数值型属性(年龄、月收入等),又包含分类型属性(学历、职业阶层等),此时,基于经典欧氏距离的相似度测度不再适用。现有研究通常将分类属性转换为数值属性,但存在信息丢失。在进行异质顾客群体识别时,本文引入基于聚类对象与聚类中心间相似性度量的聚类算法,并为相应的混合型属性数据建立一种统一的相似性度量标准,从而保证数值型属性数据和分类型属性数据在聚类过程中都能够得到有效利用,降低信息丢失。方法框架如图1所示。

图1 异质顾客群体识别方法框架
首先确定顾客群体特征属性,再通过问卷调查得到顾客群体属性值矩阵;然后利用本文所提的混合数据聚类算法对顾客群体进行识别,得到顾客群体的分类结果;最后对分类结果统计分析,总结各类顾客群体的属性特征。
2 基于惩罚竞争机制的混合数据聚类算法
传统的聚类算法无法有效处理混合属性数据集,且需要给出初始聚类数,聚类结果稳定性不足。为了更好地处理异质顾客群体聚类问题,本文引入一种基于惩罚竞争机制的混合数据聚类算法,能够通过聚类项之间的相互竞争自动确定聚类数目,使聚类结果更为可靠。算法流程如图2 所示,包括混合数据聚类算法、初始聚类中心确定、惩罚竞争学习机制三个部分。
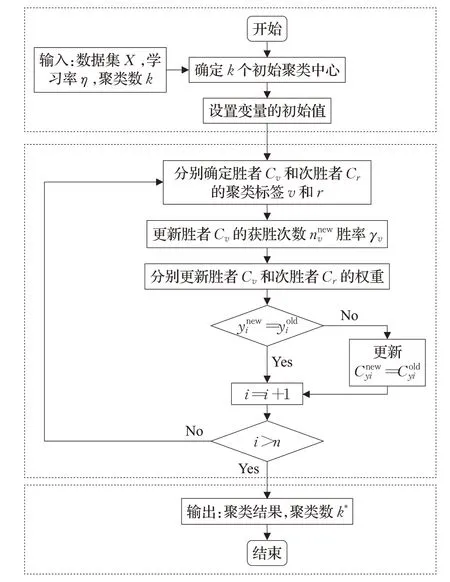
图2 混合属性数据集聚类算法流程图
2.1 基于统一相似性度量的混合数据迭代聚类算法
设顾客群体可表示为X={x1,x2,…,xn} ,其中xi为第i位顾客。将n个顾客聚成k类,表示为聚类项集C={C1,C2,…,Ck},xi与Cj之间的相似度为s(xi,Cj);且xi与Cj之间的数值型属性相似度和分类型属性相似度分别表示为
假设第i位顾客xi具有t个不同的聚类属性,其中数值型属性数量为tu,分类型属性数量为tc,则xi可表示为数值型属性分类型属性其中中包含tc个属性{Ar}(r=1,2,…,tc),属性Ar又包含m个取值{arg}(g=1,2,…,m),则聚类目标函数如公式(1)所示:

其中,Q为0-1矩阵,qij∈{0,1}满足条件:
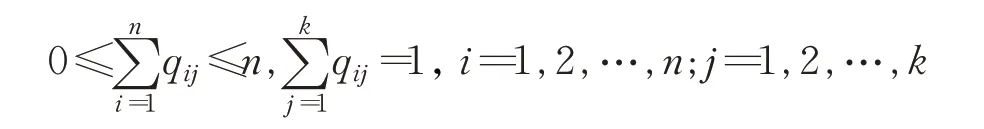
此外,数值型属性和分类型属性在聚类分析中对相似度的影响不同。每个分类属性通常可以表示给定对象的一个重要特征,因此需要独立建模;而对于数值型属性,研究通常更加关注其整体效应,因此在聚类分析时,将其描述为一个向量,作为整体对待[14]。则混合属性数据的聚类相似度可表示为:

其中,tf=tc+1 为权重分项的数量,则数值型属性相似度和分类型属性相似度所占权重分别为1/tf和tc/tf。
本文采用可以反映属性间相关性的马氏距离计算数值型属性相似度:

其中:

其中,cj表示Cj中数值属性的中心,Dis(·)表示马氏距离求解函数,为Cj中数值属性的协方差矩阵。
分类型属性的相似度可表示为:

因此分类型数据的相似度为:

在得到分类属性和数值属性的相似度后,由公式(2)可计算s(xi,Cj),在此基础上可得到

其中,i=1,2,…,n;j=1,2,…,k。
然后,每个xi都会分配给与其相似度最高的聚类项,不断更新各聚类项中分类属性各元素的频率和数值属性的中心,直至不再变化,得到聚类结果。
2.2 混合数据初始聚类中心的确定
初始聚类中心的选择影响聚类的迭代次数和最终结果。目前大多数聚类方法在选取聚类中心时都采取随机初始化的方法,几乎没有一种方法能够普遍适用于混合属性数据初始聚类中心的选取。根据实际情况来看,现有的聚类对象不能完全代表聚类项,因此选取的大多数聚类中心并不应该是聚类对象中真实存在的数据,而是由属性数据重组而来的虚拟对象[16]。
对于数值型属性数据,为了避免聚类中心选取的随机性,将聚类对象的向量中心作为第一个初始聚类中心,进而利用公式(8)计算每个对象与向量中心的距离选取其中距离最大的聚类对象作为第二个初始聚类中心。

其中,i=1,2,…,n,e=1,2,3,…,tu,此时可确定前两个初始聚类中心。为了保证每个初始聚类中心都是距离彼此最远的点,从第三个初始聚类中心选取时,要考虑累加影响。通过公式(9)计算每个聚类对象数据点与已经选取的初始聚类中心距离之和选取累加距离最大的聚类对象点作为下一个初始聚类中心,依次选取,直至结束。
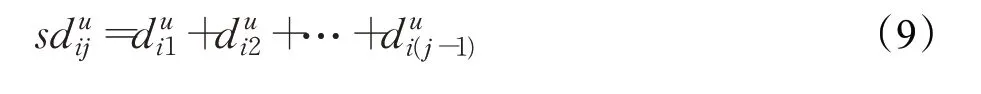
对于分类型属性数据,如果仅采用密度度量方法确定初始聚类中心,会出现聚类中心集中度过高的问题;如果仅采用距离度量方法确定初始聚类中心,则会出现聚类中心离群度过高的问题。为了改善上述问题,同时避免聚类中心选取的随机性,引入一种结合密度度量和距离度量确定初始聚类中心的方法。
首先,确定分类型属性所有元素的数目,进而找到在分类型属性数据部分中含有的所有聚类对象数据点,放入集合中,该过程可用下式表示:


分类型属性数据的初始聚类中心候选集合确定后,便可以通过密度度量的方式来选取第一个初始聚类中心。从初始聚类中心候选集合O中依次选取与每一个相比较,找到与相同次数最多的,记为将其作为分类型属性数据的第一个初始聚类中心。接着通过公式(12)计算每一个初始聚类中心候选点的可能度选择可能度最大的点作为下一个初始聚类中心,直至选取结束。


其中,i=1,2,…,n;r=1,2,…,tc。
将数值型属性和分类型属性的初始聚类中心按选取次序组合,即可得到混合数据的初始聚类中心。
2.3 惩罚竞争学习机制
Cho[17]提出的竞争学习机制源于神经网络的方法研究,如今已经成为自组织网络中一种常用的学习策略。竞争学习是通过个体的相互竞争,使竞争失败者受到一定的惩罚,最终得到最优解的过程。将这一思想引入到聚类算法中,可以实现聚类项的相互竞争,去除冗余的聚类项,得到最优的聚类数目。
将k个不同的聚类类别Cj(j=1,2,…,k)分别看成是一个神经元,设其在竞争中获胜的次数为nj,所占权重为λj,则获胜频率γj可表示为:

基于混合数据聚类算法对相似度进行求解,对于同一对象,相似度高的聚类项获胜。由于相似度的值域为[0,1],可以对公式(1)做以下变换:
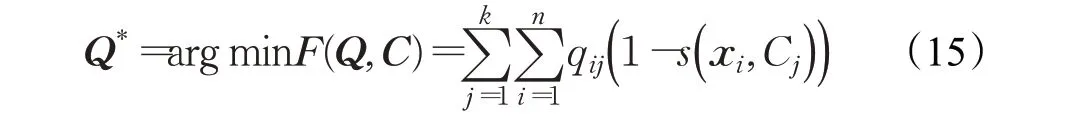
为了防止神经元在竞争中“死亡”,通过获胜频率来削弱获胜项在后续竞争中的能力,因此获胜者Cv可由下式确定:
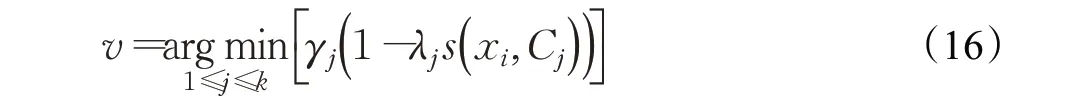
对于获胜者Cv,其获胜次数nv和权重λv可通过公式(17)和(18)计算:

其中η为学习率。
在竞争学习的基础上,Cheung等[14]提出对次胜者进行惩罚,以此来实现聚类数量的自动选择。次胜者Cr可以通过公式(19)得到:
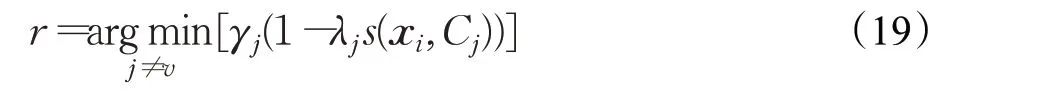
其权重λr可以通过公式(20)确定:

其中max(⋅)的作用是防止λr<0。
通过加入惩罚竞争机制,可以实现混合数据的自动聚类。首先,给k个聚类项分别选择1个初始对象,将nj和λj的初始值设置为1,选择合适的学习率η;继而求出Cv和Cr以及满足

的最小Q*;不断更新各聚类项中分类属性各元素的频率和数值属性的中心以及获胜频率γj和权重λv,直至Q*不再变化,得到最优的聚类结果。
3 案例分析
当前手机产品更新迅速,企业需要及时预测顾客需求,进行改型设计。本章以某型号手机产品为研究对象,通过调研确定顾客群体属性数据,利用所提方法对实现异质顾客群体的分类。
3.1 数据的定义与准备
异质顾客群体识别是通过对混合属性数据进行聚类分析,得到分类结果。因此,需要首先确定用来识别顾客群体的属性和各属性取值范围。经过调研与分析,排除非主要属性,共确定3 个数值型属性:年龄、月收入、风险偏好水平,3个分类型属性:受教育程度、居住地区划、职业。
不同的顾客对风险的态度存在差异,风险偏好水平表示顾客主动追求风险、喜欢收益的波动性胜于稳定性的态度。在调研时,采用了李克特量表来收集不同顾客者的风险偏好水平数据,定义风险偏好水平的取值范围是(10,50)。
职业属性共包含11 种元素,分别是国家与社会管理者、经理人员、私营企业主专业技术人员、办事人员、个体工商户、商业服务人员、产业工人、农业劳动者、城乡无业/失业/半失业和全日制学生。各分类型属性的值域如表1所示。

表1 分类型属性值域
采用调查问卷收集顾客群体数据。共发出调查问卷600份,收回562份。初步筛选,去除掉填写时间过短以及有明显逻辑错误的问卷。根据各答案比例缩小样本容量,选取出100 组具有代表性的数据采用SPSS 进行信效度分析,可得α信度系数大于0.9,KMO 系数大于0.8,数据的信效度良好。
3.2 异质顾客群体识别
利用本文所提方法对上述顾客群体进行聚类分析。算法采用Visual Studio 2013 编程实现,计算机配置为参数设置如下:学习率η设置为0.01,可能度β权重设置为0.5。改变初始聚类数k的取值,得到相应的聚类结果,如表2所示。各类别对象数量及聚类效果如图3~8表示。

表2 案例聚类结果

图3 聚类效果(k=3)

图4 聚类效果(k=4)

图5 聚类效果(k=5)

图6 聚类效果(k=6)
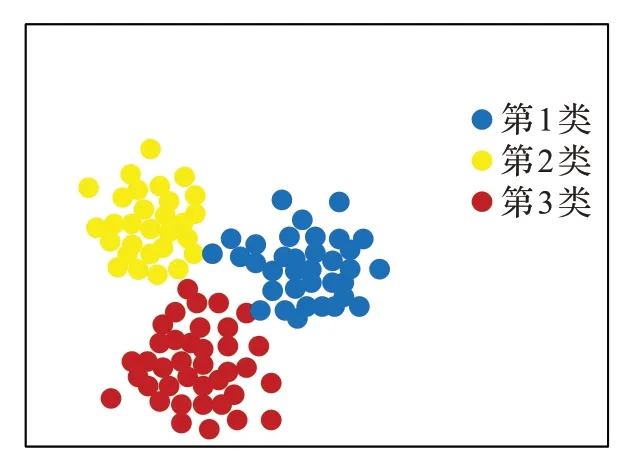
图7 聚类效果(k=7)

图8 聚类效果(k=8)
从聚类效果图及表2 可知,k=3,4 的聚类结果相同,k=6,7,8 的聚类结果相同,且k=6,7,8 的聚类结果各聚类项的分布较为均匀,类簇的直径较小。综合考虑后可得,k=6,7,8的聚类结果出现频次最高,各类数量分布最为均匀,因此将其作为最终聚类结果,如图9所示。

图9 最终聚类结果
4 方法对比与聚类结果分析
本章将通过方法对比说明本文所提方法的特点,验证其优越性;并对3.2节得到的分类结果进行分析,总结各类顾客群体的异质特征,为产品再设计提供参考。
4.1 方法对比
为了验证所提出的混合数据聚类算法的有效性,从算法特点、聚类数与每类个案数、聚类精度三方面,将混合数据聚类算法与K-means、K-prototypes 算法进行对比。3种算法的特点如表3所示。

表3 3种算法特点
K-means 算法无法区分数值型变量和分类型变量[18],对于所有数据均采用距离来度量相似度,针对混合属性数据聚类有较大缺陷。
K-prototypes 算法需要预先分配聚类数目,人为选择带来的负面影响较大。同时,由于初始聚类中心随机确定,导致聚类结果的差异率很高。3种算法的聚类数与每类个体数如表4所示。
由表4可知,K-means算法和K-prototypes算法的聚类数完全取决于k的预定值,同时,每个类别的个体数分布很不均匀;而本文所提方法得到的聚类数相对稳定,且无需预先确定聚类数。

表4 3种算法的聚类数与每类个体数对比
此外,从UCI 机器学习数据库(URL:http://archive.ics.uci.edu/ml/)中获得“Heart Disease”数据集,以聚类误差为指标对比3种算法的性能。聚类误差为:

其中,AC为聚类精度,n为数据集中实例总数,ai为数据库提供的标签,map(bi)为映射函数,将所获得的聚类标签bi映射到数据库中的等效标签,当且仅当ai=map(bi)时δ(ai,map(bi))=1,否则δ(ai,map(bi))=0。
3 种算法的聚类误差对比数据如表5 所示。“Heart Disease”数据集包括270个实例,具有7个分类型属性、6个数值型属性,理论上分为2 个类别。由于3 种算法的最终聚类数均小于或等于初始聚类数,故将k值设置为2、3和4。
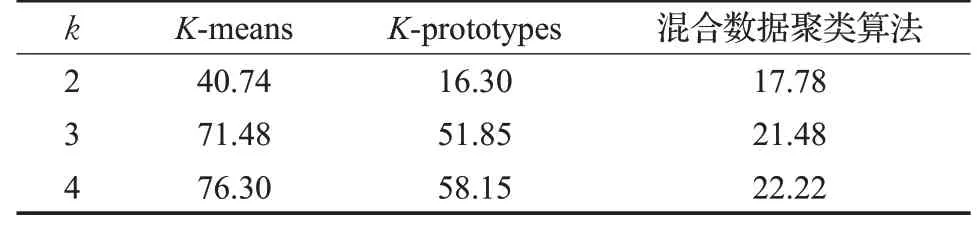
表5 3种算法“Heart Disease数据集”的聚类误差%
由表5 中可知,在聚类精度方面,本文所提方法优于K-means算法和K-prototypes算法。
同时,由于惩罚竞争机制的引入,混合数据聚类算法可以更直接地获得相对可靠的聚类结果而不会产生波动。
综上所述,利用本文所提混合数据聚类算法对顾客群体分类的理论与实际优势如下:理论方面,顾客群体具有混合型属性,其分类问题难以预先确定聚类数但要求稳定可靠的结果。为了解决这一问题,本文针对顾客提出了一种混合型属性聚类方法,采用惩罚竞争机制消除冗余聚类项,通过非随机化方法确定初始聚类中心。所提出的算法在聚类结果的每类个体数和聚类精度方面均优于K-means 算法和K-prototypes 算法。现实方面,顾客数量庞大、特征多样,难以逐一识别,分类后再处理是解决该实际问题的一种可取的方法,但其需要一个明确的分类结果,这一结果可以通过混合数据聚类算法获得。此外,针对混合数据聚类算法的分类结果,进一步分析同质顾客群体中决策者之间以及异质顾客群体之间的交互关系,提出针对相应顾客群体的产品再设计方案,进而形成标准化的产品再设计流程。
4.2 聚类结果分析
假设每个样本个体代表一位顾客,则由上述聚类结果可知,100名顾客被分为三类:第一类共有34人,第二类共有28 人,第三类共有38 人。接下来将对每一类顾客群体做出分析。
第一类顾客群体与其他两类比较,整体特征表现为群体年龄偏大、平均月收入高、不太愿意接受风险、学历较高、人员涉及各职业阶层,具体数据见表6和表7。

表6 第一类顾客群体数值型属性统计表
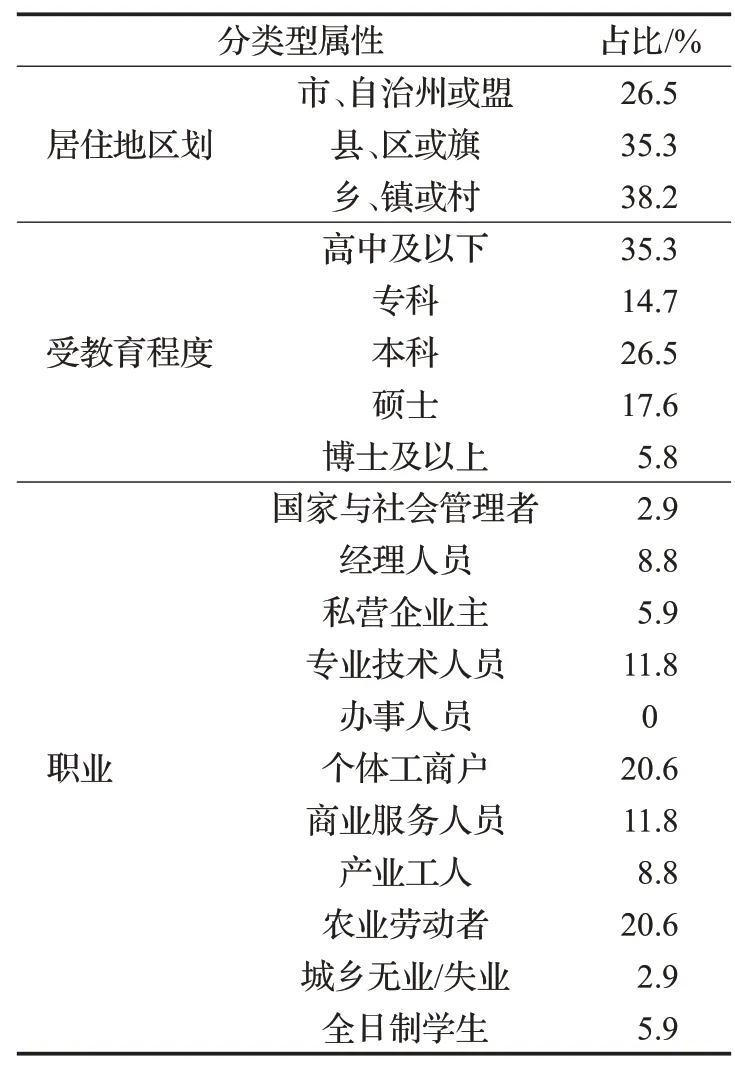
表7 第一类顾客群体分类型属性统计表
第二类顾客群体与其他两类比较,整体特征表现为群体年龄偏大、平均月收入最低、勉强愿意承受风险、大多数来自乡村少部分来自市区、文化水平低、职业主要是农业劳动和产业工人,具体数据见表8和表9。
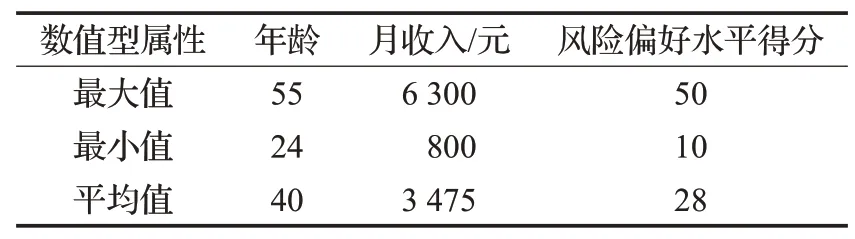
表8 第二类顾客群体数值型属性统计表

表9 第二类顾客群体分类型属性统计表
第三类顾客群体与其他两类比较,整体特征表现为年轻人较为集中、收入水平一般、比较愿意接受风险、主要来自县区和市区、受教育程度中等水平、职业都较为稳定,具体数据见表10和表11。

表10 第三类顾客群体数值型属性统计表
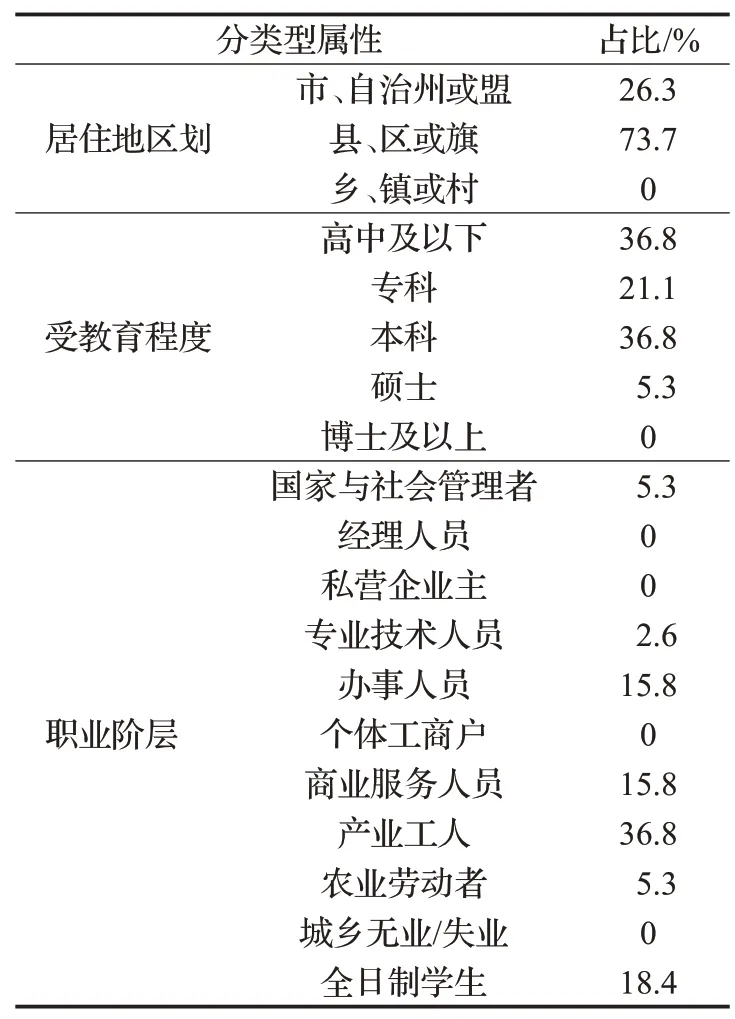
表11 第三类顾客群体分类型属性统计表
通过上述分析,可以看出本文所提的混合属性聚类方法能较为准确地识别异质顾客群体,符合现实情况。
5 总结
本文针对异质顾客群体识别问题,提出了一种混合数据聚类算法对其进行分类。首先通过分析顾客群体主要特征确定识别指标,并收集聚类对象各属性数据;然后确定初始聚类中心并对相似度矩阵进行迭代运算,此外,在该过程中引入惩罚竞争机制,从而实现自动确定聚类项;最终得到异质顾客群体的分类结果。在案例分析部分,以某型号手机产品作为研究对象,对其顾客群体进行分类,最终得到较为可靠准确的分类结果,从而对顾客需求预测及产品满意度测量提供基础。然而,本文仅提出了一种新型异质顾客群体识别的思路,其仍存在一些不足。虽说可为企业提供短期参考,但所得数据容易受到样本影响,其扩展性还需进一步研究完善。
