基于深度学习的Stack Overflow问题帖分类方法
2021-07-15贾焱鑫许舒源
杨 光, 贾焱鑫, 陈 翔,2, 许舒源
(1. 南通大学 信息科学技术学院, 江苏 南通 226019; 2. 南京大学 计算机软件新技术国家重点实验室, 南京 210023)
科研开发人员经常在其问答网站(例如Stack Overflow, 简称SO)上讨论并解决技术开发过程中遇到的问题. 目前, SO中已积累了16 500 000个可以解决开发人员技术问题的问题帖及对应的答案帖, 而用户在如此海量的帖子中找到正确的解决方案有一定的困难. 因此, 对Stack Overflow网站的挖掘与分析已成为软件仓库挖掘领域的一个研究热点. 例如: Shah等[1]通过建立逻辑回归分类器为用户提出的问题找出最优答案并分析出答案的质量; Mamykina等[2]分析了成功问答网站的设计特点; Openja等[3]从主题分析的角度对Stack Overflow网站上与软件工程相关问题的帖子进行了大规模实证研究.
为简要描述SO的帖子内容, 每个问题帖都标有1~5个标签, 标签主要基于技术内容对帖子进行分类, 例如帖子是否与Android,Java或Hadoop等相关. 目前, 网站使用用户定义的标签对每个问题进行分类, 但标签一般是在用户发布问题时手工提供的, 这可能导致用户提供了错误和不一致的标签, 例如一个用户可能使用标签“iphone api”, 而另一个用户可能使用“iphone sdk”, 虽然意图相同(即帖子是相关的), 但由于帖子使用了不同标签, 所以不会被分在一组. 该问题导致了“标签爆炸”. 一般使用4%的标签即可完成90%的问题贴分类. 标签可能无法反映出问题的目的, 例如含有“Java”标签的问题只能确定该问题与Java语言有关, 但无法确定该问题是与GUI开发相关还是与网络问题相关. 为解决上述问题, Barua等[4]提出了一种半自动方法, 该方法基于LDA(latent dirichlet allocation)[5], 其尝试分析出主要的讨论主题. 但研究表明, 不能仅分析开发人员所讨论的主题, 在检索开发人员的问题时, 也应该考虑开发人员提问的原因. 了解帖子的提问目的可帮助开发人员在SO中找到相关的帖子, 并集成到IDE(integrated development environment)中[6]. Beyer等[7]提供了一个通用的分类方法, 给出了7种问题的目的类别: API_CHANGE,API_USAGE,CONCEPTUAL,DISCREPANCY,LEARNING,ERROES和REVIEW, 之后使用基于正则表达式和机器学习的方法对帖子进行分类, 但基于正则表达式需要人工识别问题帖子中的短语模式, 因此存在模式手工提取困难的问题, 而传统机器学习方法在预测性能方面则存在一定的瓶颈.
以提问目的对帖子进行分类, 可以为分析SO上的帖子讨论主题增加新的维度. 因此, 本文基于开发人员提问目的, 使用TextCNN和融合注意力机制的TextRNN方法对SO的帖子问题目的进行分类, 并与4种传统机器学习算法(朴素Bayes、K近邻、 随机森林和逻辑回归)和文献[7]提出的正则表达式方法为基准方法进行对比实验. 实验结果表明, 本文基于TextCNN和 融合注意力机制的TextRNN的深度学习模型对SO贴子问题目的上的分类性能在多数情况下都优于对比方法.
1 基于深度学习的问题帖分类方法
随着深度学习技术的迅速发展, 不同的深度神经网络模型逐渐被应用到文本分类任务中, 其中最经典的是TextCNN[8]和TextRNN[9]. 本文考察上述两种深度文本分析算法在SO帖子问题目的分类上的预测性能. 本文方法的整体框架如图1所示, 共分为3个阶段: 数据预处理、 模型训练和模型验证.

图1 本文方法整体框架Fig.1 Overall framework of proposed method
1.1 TextCNN
卷积神经网络(convolutional neural network, CNN)的核心点在于可以捕捉局部相关性. 在文本分类任务中, 可利用CNN提取句子中类似N-gram的关键信息. 本文使用的卷积神经网络模型结构如图2所示, 该模型由输入层、 卷积层、 池化层和全连接层构成. TextCNN模型的输入层需要输入一个定长的文本序列, 本文输入文本序列中各词汇对应的分布式表示(即词向量). 由图2可见, 输入层(即最左边矩阵)的每一行表示一个词汇的词向量, 维度为dim, 行数表示输入训练的文本长度. 在卷积层中, 一般使用多个不同规模的滤波器, 在自然语言处理领域, 卷积核一般只进行一维滑动, 即卷积核的宽度W与词向量的维度dim等宽. 卷积核的高度H, 即窗口值, 可理解为N-gram模型中的N. 每个卷积核类似于一个可训练的滤波器, 提取输入的部分特征, 然后将卷积结果经过激活函数(即ReLU)处理后, 输入到池化层. 池化层的输入一般来源于上一个卷积层, 主要有如下作用: 1) 保留主要特征, 同时减少下一层的参数和计算量, 以防止过拟合问题; 2) 保持某种不变性. 在TextCNN模型的池化层中使用Max-pool, 既减少了模型的参数, 又保证了在不定长的卷基层输出上获得一个定长的全连接层输入. 全连接层的作用是分类器, TextCNN模型使用只有一层隐藏层的全连接网络, 相当于将卷积与池化层提取的特征输入到一个逻辑分类器中进行分类.

图2 TextCNN的网络模型结构Fig.2 Network model structure of TextCNN
1.2 TextRNN
尽管TextCNN在很多任务中性能较好, 但CNN中kernel_size视野的固定, 使其无法建模更长的序列信息, 且kernel_size的超参数调节也较繁琐. CNN本质是做文本的特征表达, 而自然语言处理中更常用的是递归神经网络(RNN), 能更好地表达上下文信息. 在文本分类任务中, 本文使用基于双向长短期记忆人工神经网络(LSTM)的TextRNN, 从某种意义上可理解为可捕获变长且双向的“N-gram”信息. TextRNN的结构如图3所示.

图3 TextRNN的网络模型结构Fig.3 Network model structure of TextRNN
LSTM是一种特殊的RNN网络, 其设计目的是为了解决长依赖问题, 通过在RNN上加入门控实现, 由3个门控制细胞状态, 分别为遗忘门、 输入门和输出门. 遗忘门通过查看ht-1和xt信息输出一个[0,1]内的向量, 该向量中的0,1值表示细胞状态Ct-1中的哪些信息保留或丢弃, 0表示不保留, 1表示都保留, 用公式表示为
ft=σ(Wf·[ht-1,xt]+bf).
(1)
在输入门处理前, 需决定给细胞状态添加哪些新的信息.首先, 通过输入门的操作决定更新哪些信息, 然后, 通过tanh层得到新的候选细胞信息, 这些信息可能会被更新到细胞信息中, 用公式表示为
it=σ(Wi·[ht-1,xt]+bi),
(2)
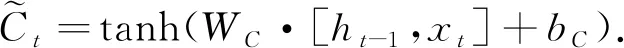
(3)

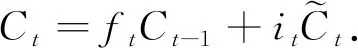
(4)
更新完细胞状态后需要根据输入的ht-1和xt判断输出细胞的哪些状态特征, 输出门将细胞状态经过tanh层得到一个[-1,1]内的向量, 该向量与输出门得到的判断条件相乘即为最终该RNN单元的输出, 用公式表示为
ot=σ(Wo[ht-1,xt]+bo),
(5)
ht=ot×tanh(Ct).
(6)
1.3 注意力机制
本文采用注意力机制[10]对TextRNN进行优化. 在对SO问题帖子进行分类时主要依赖开发人员提供问题帖子的标题和描述, 文本特征较稀疏, 注意力机制源于对人类视觉的研究, 使训练重点集中在输入数据的相关部分而忽略无关部分.
2 实 验
下面对基于深度学习的SO帖子问题目的分类的有效性进行实验验证.
2.1 数据集
考虑1 100个与Android相关的SO帖子, 该数据集由Beyer等[7]搜集并手动将这些帖子分类为7个问题类别. SO数据集中的特征简称及对应的描述列于表1.

表1 SO数据集的特征简称及含义
2.2 评测指标
由帖子的手动分类可知, 一些帖子可能同时属于多个类别, 如图4所示的帖子, 其同时被归为API_USAGE和REVIEW. 因为短语“How can I”是API_USAGE类别的识别模式, 而短语“Is there a simpler way”是REVIEW类别的识别模式. 因此帖子问题目的分类是一个多标签分类问题(multi-label classification).
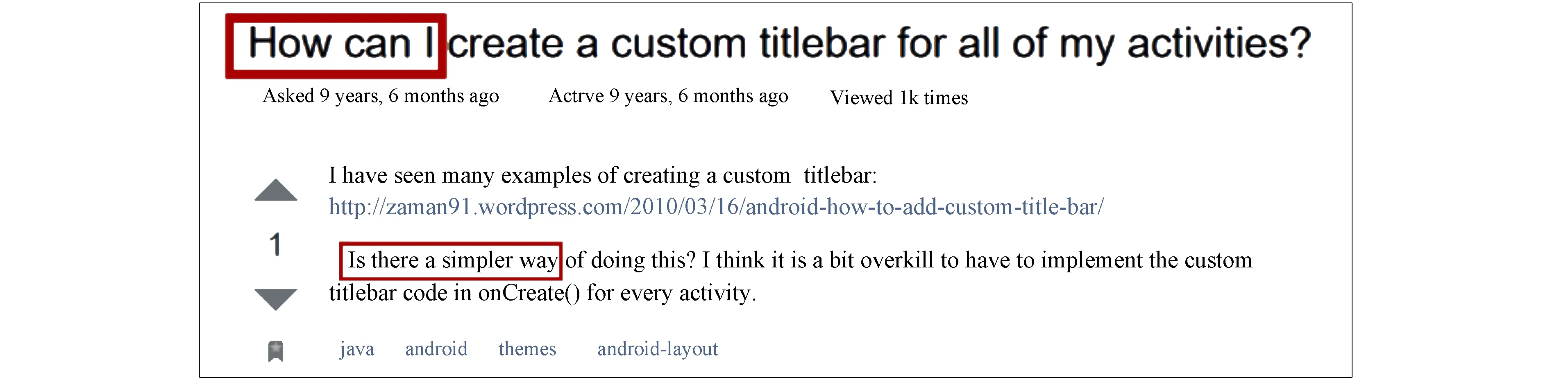
图4 帖子问题目的分类实例Fig.4 Example of a post question purpose classification
本文使用二分类技术, 将多标签分类转换为二元分类问题: 为每个问题类别建立分类器模型, 以确定该帖子是否属于该类别. 若将属于该类别的帖子设为正例, 不属于该类别的帖子设为反例, 则可根据真实类型与模型的预测类型组合, 将帖子划分为真正例(true positive)、 假正例(false positive)、 真反例(true negative)和假反例(false negative), 并令TP,FP,TN和FN分别表示对应的帖子数.
准确率表示在预测结果中, 正确分类的帖子数占所有帖子数的比例, 其计算公式为

(7)
F1指标是查准率和查全率的调和均值, 可对查准率和查全率两个指标进行有效的平衡, 其计算公式为

(8)
2.3 实验设计
本文基于Pytorch框架设计基于TextCNN和基于融合注意力机制的TextRNN的SO帖子问题目的的分类方法. 首先需要对原始数据集进行处理, 对原始数据去除〈code〉〈/code〉间的代码片段, 去除html标签后, 再利用Porter Stemmer算法进行词干还原, 然后进行分词操作生成语料库.
将数据集划分为验证集和测试集, 参考文献[6]中的原始实验设置, 将100个单独用作测试的帖子分离出来, 为防止深度学习在训练时的过拟合问题, 将剩余的1 000个帖子按9∶1的比例进一步划分为训练集和验证集. 对基准方法的实现, 基于正则表达式根据文献[6]中的共享代码进行复现, 基于机器学习的分类方法通过Sklearn进行复现.
本文将正则表达式分类方法用Reg表示, 将随机森林方法用RF表示, 将线性回归方法用LR表示, 将K近邻方法用KNN表示, 将朴素Bayes方法用MNB表示, 将TextCNN方法用TCNN表示, 将TextRNN方法用TRNN表示. 有些类别(如API_CHANGE, LEARNING和REVIEW)存在明显的类不平衡问题, 数据集的正负样本百分数列于表2. 本文采用随机过采样方法对3个类别进行正负样本不均衡问题处理, 将随机重复正样本, 直至正样本数量与负样本数量相同.

表2 数据集的正负样本百分数
实验对比基准方法采用基于随机森林的机器学习方法、 正则表达式方法、 朴素Bayes方法、 逻辑回归方法和K近邻方法.
在机器学习的分类方法中, 先对文本进行预处理, 然后计算帖子文本的tf-idf矩阵作为特征, 并使用各种机器学习的分类模型进行分类测试. 深度学习模型的超参取值设置如下: Adam对应的学习率设为0.001, SGD对应的学习率设为0.1. 对于TextCNN模型, 卷积核的尺寸设为(2,3,4), 每种卷积核的数量设为256, Dropout设为0.5, 激活函数设为ReLU, 池化选择设为1-max pooling, 词向量维度设为100, batch_size设为128. 对于TextRNN模型, 使用两层的LSTM, 第一层LSTM的hidden size设为256, 第二层的hidden size设为128, Dropout设为0.5, 激活函数设为ReLU, 词向量维度设为300, batch_size设为32.
2.4 结果分析
基于准确率指标和基于F1指标的实验结果分别列于表3和表4. 由表3和表4可见, 针对7个类别, 本文基于深度学习的问题贴分类方法, 在大部分情况下都优于其他对比基准方法. 宏观上, 融合注意力机制的TextRNN方法优于TextCNN方法. 其中在API_USAGE类别上, TextRNN方法的准确率比随机森林方法提高了9.64%, 比正则表达式方法提高了5.81%. 但在少数类别上的分类结果不如对比基准方法, 在REVIEW类别上效果最差. 其性能不佳的原因为: 在100条测试集中REVIEW的正样本数量仅11条, 而API_USAGE的正样本数量有47条, 从而导致深度学习模型的分类性能并不理想.

表3 基于准确率指标的实验结果

表4 基于F1指标的实验结果
针对优化器选择及是否采用预训练词向量, 本文对模型性能的影响进行了对比实验. 在优化器选择上, 本文使用最常用的SGD优化器和Adam优化器; 在预训练词向量上, 本文使用Glove预训练完的词向量.
首先, 分析优化器选择对分类性能的影响, 对比结果列于表5和表6. 由表5和表6可见, 在准确率指标上, 使用Adam优化器比使用SGD优化器分类性能可平均提升1.59%; 在F1指标上, 使用Adam优化器比使用SGD优化器分类性能可平均提升1.33%.

表5 优化器选择对TextCNN分类性能的影响
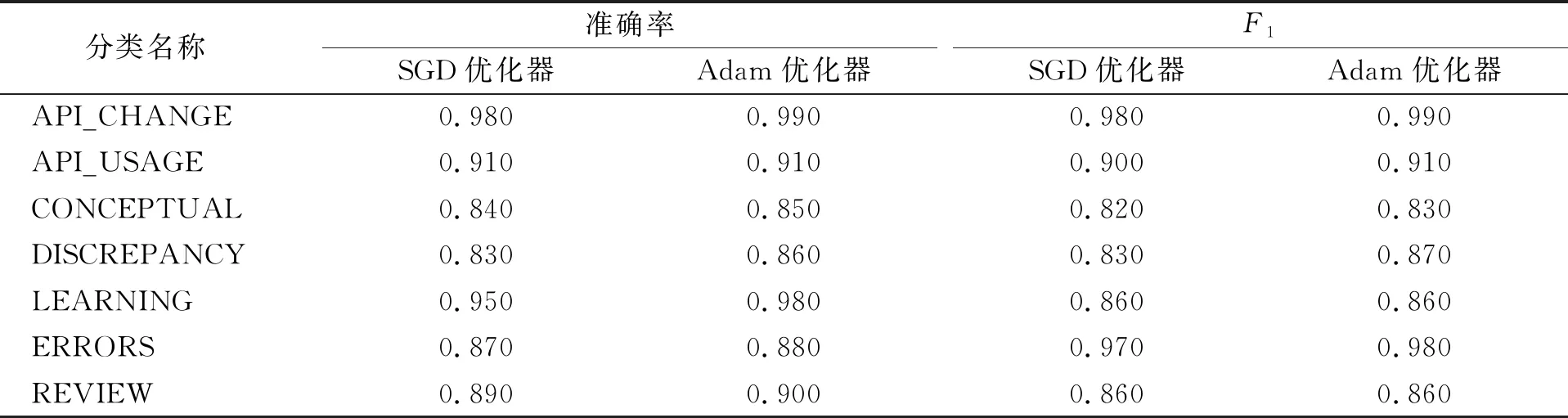
表6 优化器选择对TextRNN分类性能的影响
其次, 分析预训练词向量对分类性能的影响, 对比结果列于表7和表8. 由表7和表8可见, 在准确率指标上, 使用Glove比使用随机词向量生成分类性能可平均提升0.3%; 在F1指标上, 使用Glove比使用随机词向量生成分类性能可平均提升0.7%.
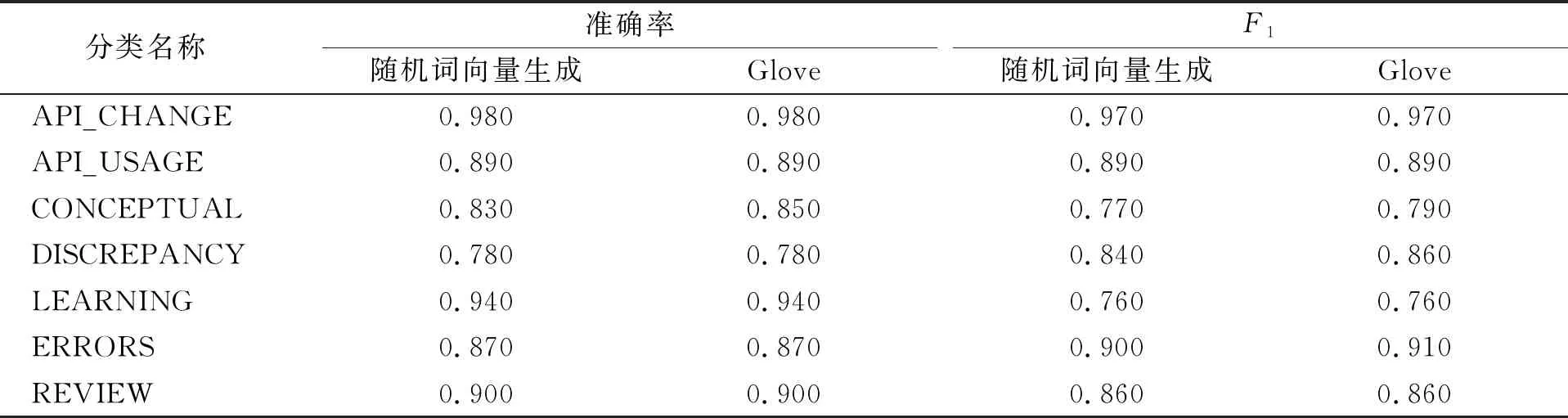
表7 是否采用预训练词向量对TextCNN分类性能的影响
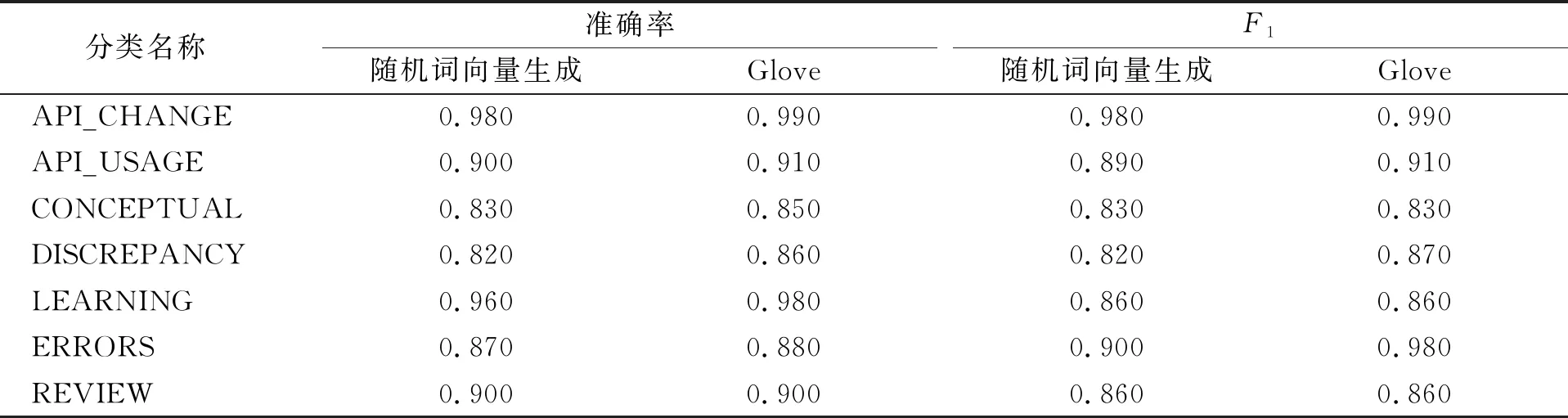
表8 是否采用预训练词向量对TextRNN分类性能的影响
实验结果表明, 采用基于深度学习的问题贴分类方法中, 使用Adam优化器和Glove预训练完的词向量可有效提高训练出模型的分类性能.
综上所述, 本文基于深度学习的TextCNN和融合注意力机制的TextRNN, 提出了一种基于深度学习的SO问题帖分类方法, 并分析了该方法两个设计要素对模型性能的影响. 与经典基准方法的对比结果验证了该方法的有效性.
