国有企业并购风险预警及其影响因素研究
——基于数据挖掘和XGBoost算法的分析
2021-07-15王言,周绍妮,石凯
王 言, 周 绍 妮, 石 凯
(1.北京交通大学 经济管理学院 中国企业兼并重组研究中心,北京 100044;2.北京邮电大学 计算机学院,北京 100876)
一、引 言
党的十八届三中全会以来,随着顶层设计方案的出台,国有企业(以下简称“国企”)改革逐步驶入快车道。通过国有资本和社会资本的交叉融合[1],进一步推动我国国企解决结构不平衡、不协调等问题,全面提高国企发展的质量效益,不断增强国企可持续发展能力,提高国企治理效率。并购重组成为国企改革、实现国企资源优化配置的重要手段,推进国企并购重组是国企改革的重要一环[2]。近年来,在国企改革的政策引导下出现了大量国企并购行为,尤其是国有控股上市公司(以下简称“国有上市公司”)表现最为明显。根据上交所数据显示,2017年沪市国企通过混合所有制改革、专业化重组以及资产证券化等方式,大力推动企业资源整合,重组价值超过5 400亿元,重大重组价值接近2 000亿元;深交所数据显示,2017年深市主板完成的重大资产重组公司有46%重组前为国有控股,重组价值达2 281.57亿元[3]。然而经过近几年的实践发现,国企在如此大规模并购交易背景下,很多企业超出自身能力范围盲目进行并购而导致并购效果不佳,未能充分发挥并购协同作用[4]。如鞍钢2010年兼并攀钢后,2015年陷入数十亿元的巨亏。由此看来,研究国有上市公司并购风险预警可以对风险早防范、早发现、早干预,对提高国企并购成功率具有十分重要的理论和现实意义。
二、文献综述
明确影响国有上市公司并购风险的关键因素是进行并购风险预警的重要前提。现有文献对并购风险主要从并购业绩角度衡量,对于并购绩效的影响因素分别从理论和实证两方面进行研究。在理论方面,国内外学者研究较早,Jensen和Meckling从代理理论出发认为,管理者为了追求自身利益而发动并购,这主要是由于管理者和所有者的利益冲突所致,管理者为了分散个人风险往往会通过多元化并购的方式实现,但基于此目的并购绩效仍需商榷[5]305。邱金辉和王红昕按照并购动机、并购行为、并购绩效的逻辑顺序,探索并购理论在我国的发展和研究方向,对于非国有企业,并购是一种逐利行为,而对于国有或国有控股企业来讲,还反映了政府意志,政府制定了许多财政、税收优惠政策鼓励并购[6]7。在实证方面,国外学者Bruton等发现,在财务困境时候并购,并购经验对绩效的感知测量是正效应[7]972;Shahwan发现,并购商誉与上市公司市场价值之间显著正相关[8]63;Wangerin发现,随着并购尽职调查的减少不利于并购绩效的提升[9];Thompson和Kim发现,并购花费时间较长与并购绩效呈显著负相关[10]。国内学者李善民等发现,支付对价是影响并购绩效的主要因素[11]60;陈芳和景世民研究了资产结构包括应收账款、资产周转率、流动比率与并购绩效的关系[12]117;翟进步等发现,债务融资降低了收购公司的市场绩效[13]100;郭妍和张立光通过实证得出,成长性、盈利能力是银行并购绩效的重要影响因素[14]42;黄旭和李卫民研究认为,员工薪酬越高,企业并购绩效越好[15]113;余鹏翼和王满四发现,第一大股东持股比例越高,越有利于提高企业跨国并购绩效[16]64;周绍妮等证明了交易型机构投资者股东可以提高国企并购绩效[17]73;王艳和李善民发现,主并方社会信任度越高,越有利于提高并购价值创造能力[18]125;宋贺和段军山研究认为,并购财务顾问会降低并购绩效[19]155。
现有文献已经应用大量预警模型来对风险进行预警,分布于自然、日常生活以及经济等各个领域,尤其是财务金融方面尤为突出。在自然领域,Yuceer等通过采集土耳其耶斯里尔马克河(Yesilirmak)流域实地观测数据,利用RSDS水质模型对流域水质污染问题进行了预测[20];李杨帆等基于风险受体敏感性、城市不透水面变化率等指标构建了景观生态风险空间预警模型,提出了改进措施[21]。在日常生活及应用方面,李祥飞和阎耀军利用支持向量机模型实现了对公共危机事件危害范围的预警[22];冯文刚和黄静基于民航、公安数据库和三层深度神经网络构建出旅客安检和航班预警模型对机场安全检查进行分级分类安检,极大地提升了工作效率和用户体验[23];Zhong等基于机场道路表面纹理的分形特征和胎面胶的粘弹性,建立了以摩擦系数为评价标准的机场路面防滑风险动态评价预警模型[24]。在财务金融方面,Li和Wang将Logistic财务预警模型应用到DEA效率评价中[25];王玉冬结合PSO-BP和FOA-BP神经网络模型原理,选取高新技术企业财务数据,对高新企业财务危机进行了有效预警[26];Louzis和Vouldis通过构建金融系统性压力指数(FSSI)对金融危机进行预警[27];谷慎和汪淑娟构建了支持向量机的碳金融风险预警模型[28];Mancino和Sanfelici基于给定市场冲击的传播衰减率计算金融不稳定性预警指标,利用CEV模型并使用S&P500指数期货逐笔数据对指标的属性进行研究[29]。
综上所述,现有文献利用人工智能算法进行了诸多分类与预测研究。但是,还没有针对并购重组问题引入人工智能预测模型,并购重组研究依然停留在传统的实证计量方法,并且传统的实证方法只能研究关系型问题,而对预测问题却不适用。人工智能算法功能十分强大,这将为传统计量方法不能解决的预测问题提供基础。人工智能算法包含机器学习和深度学习,深度学习适合拥有海量数据的研究,本文研究内容为并购问题,数据量较少,遂选用机器学习算法更为适宜。基于上述内容,建立了国有上市公司并购风险指标评价体系,基于XGBoost算法构建国有上市公司并购风险预警模型,将预警结果与经典机器学习模型GBDT(梯度提升决策树)、RF(随机森林)和传统Logistic(逻辑回归)模型作对比实验,显示出其精度上的优越性,并运用多元线性回归模型对影响因素实证检验。
三、XGBoost算法和设计
1.CART回归树
XGBoost算法是基于CART回归树模型实现的。CART的回归树是二叉树模型,其会根据特征不断分裂左子树和右子树,式(1)中R代表样本,j代表样本特征,s代表特征值,即第j个特征中小于s特征值的样本为左子树,大于s特征值的样本为右子树。
(1)
所以CART回归树就是基于样本特征划分样本空间,那么如何使空间的划分最为合理是必须要解决的问题,既是难点也是重点,这直接决定了模型的精度。CART回归树产生的目标函数如式(2)所示:
(2)
如果想得到最优的切分特征j和切分点s,可以将式(2)转化为求解式(3)这种目标函数:
(3)
这时只要求解所有特征的所有切分点,就可以找到最优切分特征和切分点,得到一棵整体回归树。
2.XGBoost算法思想和原理
(1)XGBoost算法思想
XGBoost算法是Chen和Guestrin提出的一种集成学习模型,借助了CART回归树的思想,又有所改进[30]。算法的核心思想是不断地添加树,新添加的树会根据特征分裂再生长一棵树,添加树的过程就是学习新函数的过程。根据样本特征将每棵树落到对应的叶子节点上,将每个叶子节点上的分数相加就能得到预测值。
(4)
WhereF={f(x)=ωq(x)}(q:Rm→T,ω∈RT)
(5)
注:ωq(x)为叶子节点q的分数,f(x)为其中一棵回归树,T表示叶子结点个数。
(2)XGBoost算法原理
XGBoost目标函数定义为:
(6)
目标函数包括真实预测偏差和正则化项两个部分。其中,由于新树需要拟合上次预测偏差,所以当t棵树生成以后预测分数可以写成:
(7)
因此,目标函数就变为:
(8)
根据式(3)找到使目标函数最小化的ft,XG Boost利用其在ft=0处的泰勒二阶展开近似它,得到:
(9)
其中,gi为一阶导数,hi为二阶导数:
(10)
由于目标函数优化不受y的残差与预测分数影响,故简化目标函数为:
(11)
上式是将每个样本的损失函数值加起来,由于最终每个样本都会落到一个叶子结点,可以将同一个叶子结点的样本重组起来,步骤如式(12)所示:
(12)
其中,T表示叶子结点个数,ω表示叶子节点分数,γ表示可以控制叶子结点个数,λ表示可以控制叶子节点分数,防止过拟合。这样就将目标函数改写成关于叶子结点分数ω的一个一元二次函数,结合顶点公式最优的叶子节点分数ω和目标函数公式为:
(13)
(14)
最后,运用贪婪算法确定树的结构,找出所有特征的分裂点,利用式(14)目标函数值作为评价函数。分裂后目标函数值比叶子节点的目标函数值增益,但为了限制树生长过深而增加了阈值,只有当增益大于该阈值才进行分裂。同时,还可以设置树的最大深度、样本权重等来防止过拟合。
四、国有上市公司并购风险界定和影响因素
1.国有上市公司并购风险的界定
根据上述文献研究成果,并购完成后的绩效是国有上市公司并购成功与否的主要衡量标准,也是并购风险度量最重要的指标。结合本文研究内容采用周绍妮等[17]71衡量并购绩效的方法,即并购完成前后一年净资产收益率的差额。如果并购后企业绩效提高,则为安全并购;如果并购后企业绩效降低,则说明并购风险较大。
2.影响并购风险的关键因素
通过前述文献分析,本文总结包括企业资产结构风险、创利能力风险、价值再造风险、法人治理风险、外部监督风险以及并购特征风险共同作用的19个可能影响国有上市公司并购风险的指标,具体如表1所示。
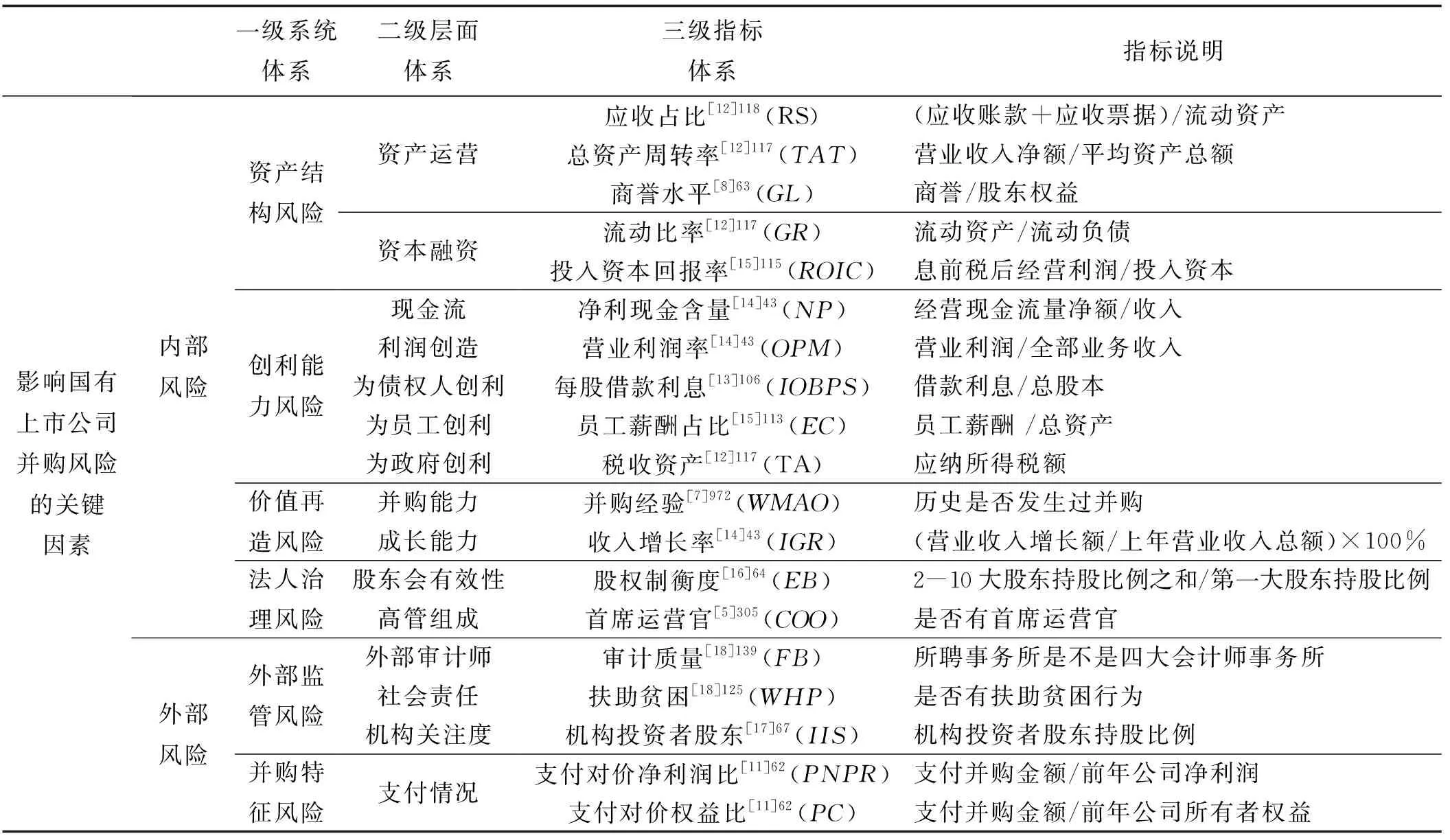
表1 国有上市公司并购风险指标评价体系
五、样本和变量的选取与分析
1.数据选取、处理及分析
(1)并购事件
本文基于同花顺iFinD数据库,选取沪深A股国有上市公司2014~2017年并购事件为研究样本,并购收购标的为股权,剔除资产剥离、资产置换、资产收购、债务重估以及吸收合并等广义并购形式。经过数据筛选和处理最终得到1 806条并购样本。具体筛选和处理步骤为:①首次公告日实际控制人为国务院国资委、地方国资委或其他具有政府机构性质的行政机关、事业单位、国有企业等研究对象,不包括国有股东为第一大股东但无实际控制人的上市公司的并购交易[17]70;②上市公司为收购方的样本;③剔除并购交易未完成或已经终止的样本,以及并购交易正在进行中的样本;④剔除金融类企业;⑤剔除上市年份不足以及被特别处理(ST)的样本;⑥剔除其他关键研究数据不全或缺失的样本。
(2)指标数据搜集
现有文献对影响国有上市公司并购风险指标进行了大量规范性研究,但是,很多治理、监督指标数据都不能直接从数据库获得,这些指标获取难度大且可能会对国有上市公司并购风险预警产生很大影响。所以,本文首先选用同花顺iFinD数据库提取部分直接可获得数据,然后基于扎根理论(Grounded Theory)[31]的原理和方法,利用文本挖掘(Textual Mining)[32]和网络爬虫(Web Crawler)[33]技术,通过列出指标关键词,使用python和正则法则进行匹配,抓取了上市公司一手不易获得的数据。详细操作过程如图1所示。其中,运用扎根理论是通过挖掘大量经验资料,总结并升华到理论的过程;文本挖掘是从海量的文本库中抽取隐含的、未知的、有价值数据的技术;网络爬虫是通过模拟人访问网络,从而获取图片、数据等有用信息的过程;正则法则是对字符串操作的一种逻辑公式,用以匹配相应关键词。此外,在进行数据抓取前,还需制作指标抓取具体规则,即需求文档,针对不可直接获得的3项指标数据(COO、FB、WHP)的需求文档如表2所示。

表2 抓取网页和文本数据的需求文档

图1 基于扎根理论的文本挖掘和网络爬虫抓取数据分析框架与流程
(3)指标数据处理
①属性值处理和转化数值类型。属性值处理即非数值属性的数值化,经过分析发现非数值属性可分为两种:属性值之间有趋势的文本属性和属性值之间无趋势的文本属性。国有上市公司并购风险关键因素的三级19项指标体系中非数值属性数据都属于属性值之间有趋势的文本属性,如是否有首席执行官、所聘事务所是否四大会计师事务所以及是否有扶助贫困行为,采用0和1量化的方法进行取值,是则取值为1,反之为0。此外,对于有些特征,本身不是数值类型的,这些数据是不能被算法直接使用的,所以要将所有的非数值型数据转化成数值型。
②正向化和连续数值归一化处理。利用XGBoost算法构建的预警模型对国有上市公司并购风险进行预警之前,若指标方向不全是正向化的,或者存在逆向指标,则不会得到有效结论,故需要将逆向指标进行正向化处理,方法是将逆向指标取倒数变为正向化指标。本文选取的指标除应收占比、商誉水平、支付对价净利润比以及支付对价权益比四个指标外其余均为正向化指标,即指标数值越大越好。此外,由于有些属性的连续数值规模较大,预警模型对指标的量纲要求较高,对收敛速度有很大影响,故为了使各项指标间具有可比性以及模型的预测结果更加精准,需要对各项连续指标进行归一化处理。本文利用python软件按照归一化公式编程进行处理。
2.描述性统计分析
(1)并购发生的地域分布
国有上市公司并购样本中,东部沿海地区发生并购次数最多,东北地区和中部地区发生并购次数居中;西部地区除新疆外,发生并购次数较少。北京、广东、上海发生并购次数位列前3名,分别为245次、222次、201次,占并购样本比例分别为13.57%、12.29%、11.13%,总和占比为36.99%,超过全体并购样本的1/3。由此可见,国有上市公司并购与当地经济发展具有高度相关性。
(2)并购发生的行业分布
国有上市公司并购样本中,制造业、批发和零售业、房地产业是并购的高发区,分别为796次、176次、163次,占并购样本比例分别为44.08%、9.75%、9.03%,总和占比为62.86%,超过全体样本的60%。原因是从整个A股上市公司来看,这些行业的公司样本较多。
(3)并购风险指标整体描述
对国有上市公司并购风险全部评价指标进行了描述性统计分析,表3列出了25% 分位数、中位数、75%分位数、均值、标准差、最小值和最大值。在2014~2017年除金融行业之外的沪深A股国有上市公司并购事件中:历史是否发生并购指标的中位数为1,均值为0.62,表明国有上市公司较多发生过并购,具有较强的并购经验;支付对价净利润比均值为2.33,表明较多国有上市公司并购支付价款高于公司当年净利润;流动比率均值为1.71,中位数为1.29,说明过半数国有上市公司流动比率低于平均水平;净利现金含量和收入增长率标准差较大,说明国有上市公司净利现金含量和收入增长率波动大。

表3 并购风险预警样本各变量描述性统计
3.相关性分析
并购风险预警变量间可能存在共线性关系,进而干扰预警精确度。为了使研究结论更具稳健性,本文同时选用Kaiser-Meyer-Olkin(KMO)统计量、Bartlett’s球形、Pearson相关性矩阵以及方差膨胀因子(Variance Inflation Factor,VIF)进行相关性验证:KMO和Bartlett的Sig值为0,小于0.05,但KMO值为0.438,小于0.6,表明变量不太适合因子分析;各变量的VIF值最大值为2.37,均值为1.42;Pearson相关性矩阵变量之间的相关系数都小于0.65。所以,综上4种方法说明变量间不存在多重共线性的干扰并且变量选取合理。本文所有检验均通过SPSS 20.0软件得出。
六、实验结果分析
1.类别聚合
为了加强样本分类方法训练集与测试集的泛化能力,本文验证分类方法的精度使用K折交叉验证法进行估计。Kohavi[34]指出K折交叉验证是将整个数据集分成互斥的K个子集,每次使用(K-1)个子集作为训练集,剩余一个子集作为测试集,这样总共得到K次训练和测试结果,K次测试结果的平均值即为验证分类方法的精度估计值,如式(15)所示。本文采用五折交叉验证方法,按照4:1比例将样本大体分为5份,每份约362个样本。从5份样本中逐次抽取4份即1 444个样本作为训练集,剩下362个样本作为测试集。一部分用来训练分类器,另一部分用来检验分类器的效果,每个样本有19个属性和1个标签,总共训练5次,计算5次结果的均值求得模型精度估计值。
(15)
2.XGBoost算法的主要参数及说明
XGBoost算法主要包括3种类型的参数,即通用类型参数、Booster参数和目标参数,其中对算法性能影响较大的是Booster参数,每类参数又包括多个具体的参数,总共多达几十个。这些参数的主要作用是提高模型性能和预测准确性,所以,参数的配置和调整也是十分必要的。本文利用XGBoost算法构建国有上市公司并购风险预警模型,模型的主要参数及说明如表4所示。
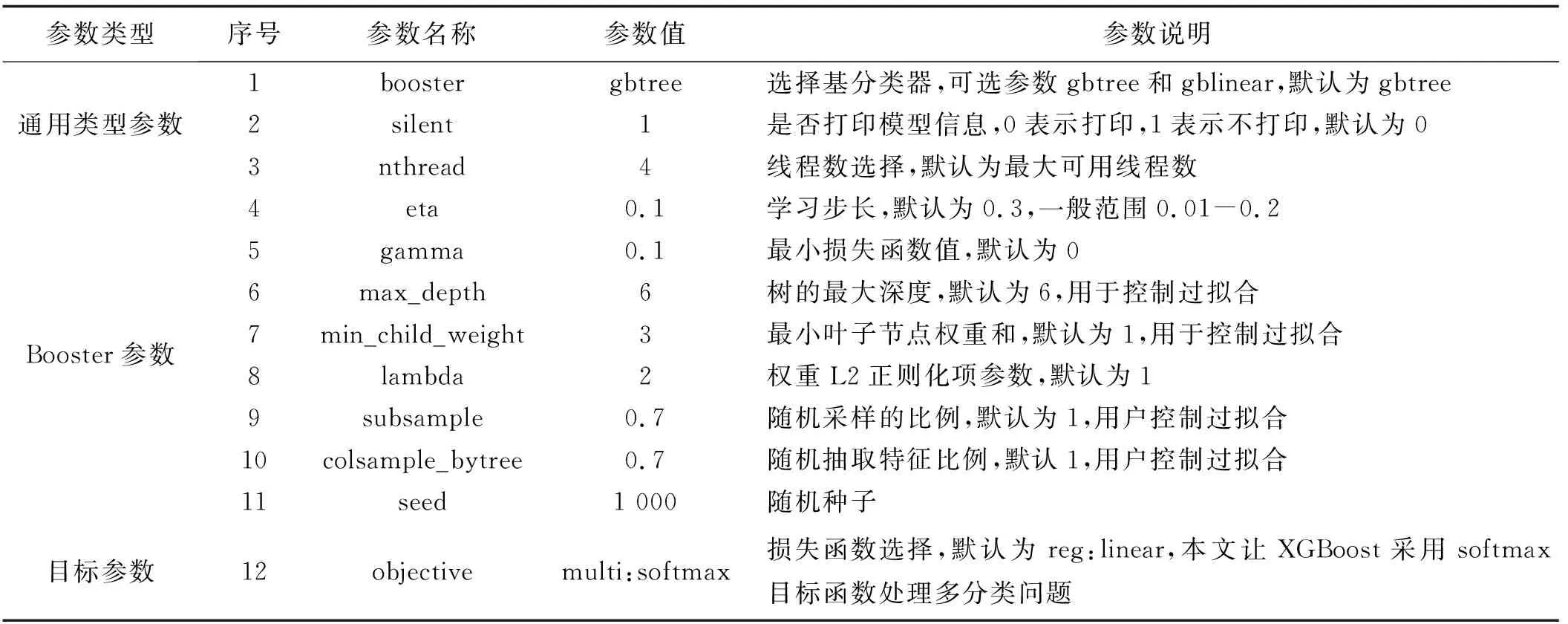
表4 XGBoost算法构建预警模型的主要参数及说明
3.预警模型结果及对比
(1)混淆矩阵、查准率、召回率与准确率
在衡量模型预测结果时,通常采用混淆矩阵对结果进行区分,具体如表5所示。在混淆矩阵中,模型分类结果被分为真正例(TP)、假正例(FP)、真反例(TN)以及假反例(FN),即积极样本被分类正确、积极样本被分类错误、消极样本被分类正确以及消极样本被分类错误,其中FP与FN分别被称为第一类错误与第二类错误。

表5 预警模型的混淆矩阵
通过混淆矩阵可以很快速地计算查准率(precision)与召回率(recall)、准确率(accuracy)等指标,具体定义如下:
(16)
(17)
(18)
查准率表示在模型预测某一预警区间样本中,实际上也处在这一预警区间的样本所占的比例。召回率表示在实际某一预警区间样本中,能够被模型准确地预测为这一预警区间的样本所占的比例。准确率表示所有样本被正确分类的比例。此外,对于分类问题,准确率在作为衡量分类模型性能的指标时具有明显缺陷,所以,本文采用查准率与召回率而非准确率作为衡量模型好坏的标准。
(2)F1 score
在某些情况下,查准率和召回率也会相互矛盾,为了综合评判模型的预测能力,可以使用F1score进行判定,F1score计算如式(19)所示,即为查准率与召回率的乘积除以两者和的二倍。当两者其一值比较小时F1score会急剧下降,是查准率与召回率的加权体现。根据定义,F1score的取值范围在[0,1]区间,取值越大,表明模型的预测能力越强。
(19)
(3)预警模型结果比较
为了验证XGBoost算法预警能力,本文分别采用经典机器学习模型GBDT、RF和传统Logistic模型与XGBoost作对比实验。图2报告的是4个模型的查准率与召回率对比。召回率表达的是模型找到数据集中相关实例的能力,而查准率表达的是模型找到的数据点中实际相关的比例。简而言之,查准率高则对判为正例要求严格,召回率高则对判为反例的要求严格。XGBoost、GBDT、RF、Logistic查准率分别为82%、82%、79%、91%,召回率分别为79%、74%、75%、59%。XGBoost查准率与GBDT一致,比RF高3%,低于Logistic;XGBoost召回率比GBDT高5%,比RF高4%,大幅高于Logistic。由于查准率与召回率不能明显看出差距,需要继续用F1score进行判断。

图2 预测模型的查准率和召回率对比
如图3所示,XGBoost、GBDT、RF、Logistic 4个模型的F1score分别为80%、76%、76%、69%。XGBoost较Logistic高出11%,比RF和GBDT高出4%,表明基于XGBoost算法构建的预警模型预测能力最强,其次是RF和GBDT,最后是Logistic 回归模型,可见XGBoost的优势比较明显,基于XGBoost算法分类器对国有上市公司并购风险预警问题具有非常好的分类效果。

图3 预警模型的F1 Score对比
(4)指标重要性排序
基于XGBoost模型的训练结果,探讨了19个并购风险预警指标对预测模型的相对重要性。根据指标重要性排序的19个并购风险预警指标如图4所示。排名前三位的指标分别为投入资本回报率(权重系数0.100)、营业利润率(权重系数0.082)和支付对价净利润比(权重系数0.075)。与其他影响因素相比,这3项指标对于并购风险预警模型的区分能力明显强于其他指标,它们的共同特点是都和企业利润相关,说明企业自身盈利能力对于国有上市公司并购风险的预测更加重要和有效。

图4 并购风险预警指标的相对重要性排序
4.影响因素分析
(1)多元线性回归模型
为了检验各个指标对国有上市公司并购风险的影响,构建以并购净资产收益率增长额为被解释变量,影响因素为解释变量,且包含其他控制变量的计量模型,具体如模型(20)。
ΔROEi,t=β0+β1*RSi,t-1+β2*TATi,t-1+β3*GLi,t-1+β4*GRi,t-1+β5*ROICi,t-1+β6*NPi,t-1+β7*OMPi,t-1+β8*IOBPSi,t-1+β9*ECi,t-1+β10*TAi,t-1+β11*WMAOi,t-1+β12*IGRi,t-1+β13*EBi,t-1+β14*COOi,t-1+β15*FBi,t-1+β16*WHPi,t-1+β17*IISi,t-1+β18*PNPRi,t-1+β19*PCi,t-1+∑INDUSTRY+εi,t-1
(20)
其中,i代表企业,t为时间;ΔROE为i公司t年并购完成的后一年与前一年净资产收益率的差额;RS至PC表示i公司t-1年末的指标状况,采取滞后一期目的是尽量缓解反向因果可能导致的内生性问题;β1~19为变量对应估计系数;INDUSTRY为按照2012年最新版中国证监会行业划分标准的行业虚拟变量;β0和ε分别表示常数项和随机误差项。
(2)模型估计结果
本文利用Stata 14.1统计软件进行多元线性回归分析,结果如表6所示。Adj-R2指回归直线对观测值的拟合程度,其值为0.235,表明该模型的拟合效果比较好,模型可信度较高,自变量提供的信息能较好地解释因变量。由表6得出影响国有上市公司并购风险预警模型(21)。
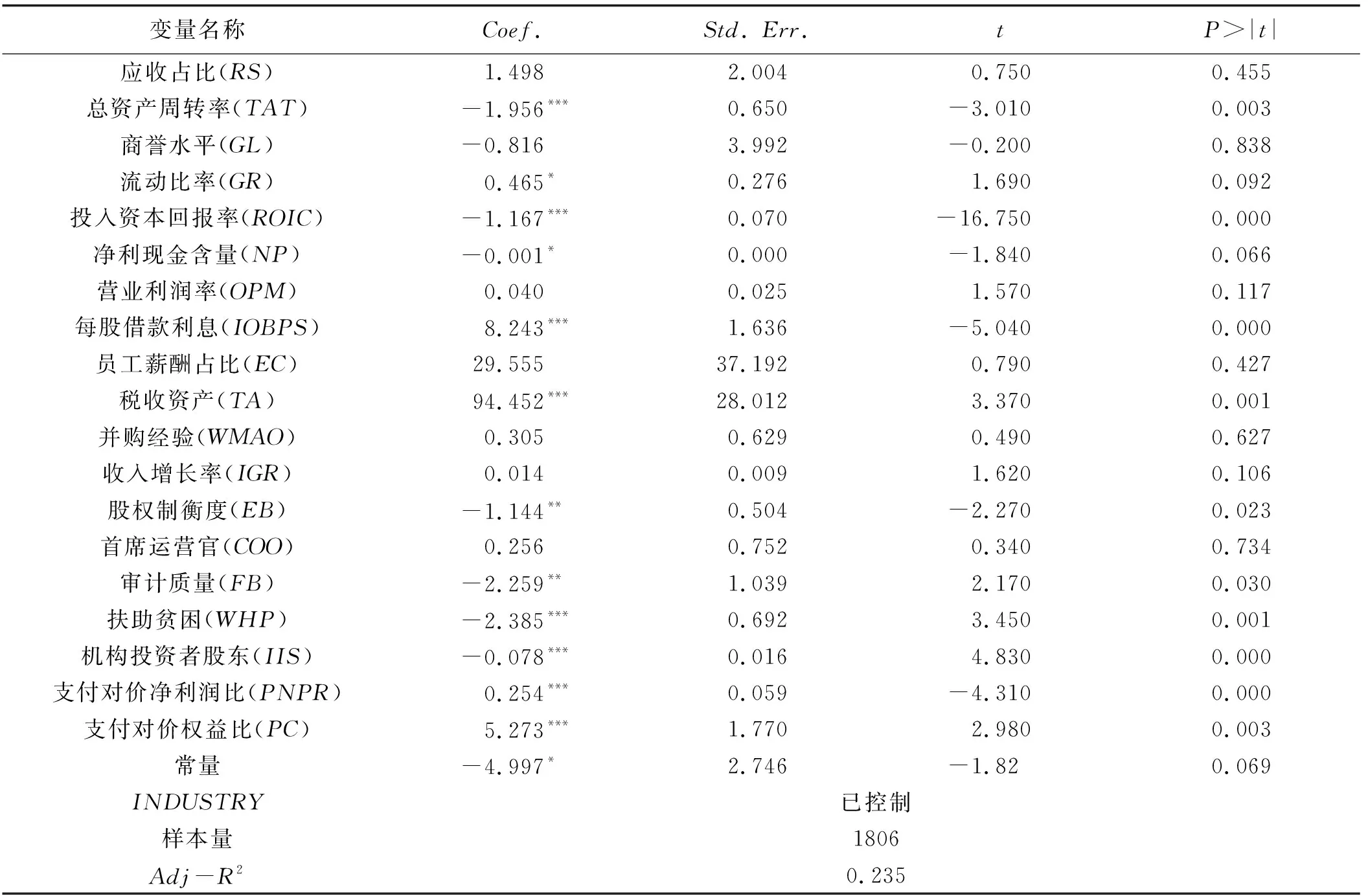
表6 多元线性回归模型估计结果
y=0.465GR+8.243IOBPS+94.452TA+0.254PNPR+5.273PC-1.956TAT-1.167ROIC-0.001NP-1.144EB-2.259FB-2.385WHP-0.078IIS-4.997
(21)
(3)结果分析
通过多元线性回归检验,得到以下结论:
①资产结构风险中总资产周转率(β=-1.956,p<0.01)和投入资本回报率(β=-1.167,p<0.01)对国有上市公司并购风险具有十分显著的抑制作用,即分别每提升一个单位,并购风险相应减少1.956倍和1.167倍。总资产周转率分析评价资产使用效率,越高说明企业销售能力越强,投入资本回报率用于衡量投出资金的使用效果,两项指标都能说明公司资产投资的效益好,有利于带动被并购企业资源,降低并购风险。
②创利能力风险中每股借款利息(β=8.243,p<0.01)和税收资产(β=94.452,p<0.01)增加了国有上市公司并购风险,即分别每提升一个单位,并购风险相应增加8.243倍和94.452倍。公司付给借款人利息和国家的税收越多,导致流动资金越少,财务压力越大,越不利于并购方安全支付并购款以及并购后的资源合理配置。
③法人治理风险中股权制衡度(β=-1.144,p<0.05)对国有上市公司并购风险具有显著的抑制作用,即每提升一个单位,并购风险相应减少1.144倍。股权制衡度较高,既能保留股权相对集中的优势,又能有效抑制大股东对上市公司利益的侵害,减少过度并购行为发生,从而将国有上市公司并购风险消灭在萌芽之中。
④外部监督风险中所聘事务所为四大会计师事务所(β=-2.259,p<0.05)、具有扶贫行为(β=-2.385,p<0.01)以及机构投资者股东持股比例较高(β=-0.078,p<0.01)对国有上市公司并购风险具有显著的抑制作用,即分别每提升一个单位,并购风险相应减少2.259倍、2.385倍、0.078倍。实证检验发现,四大会计师事务所的确具有相对较高的审计质量和健全的并购咨询职能;企业具有扶贫行为,说明企业社会责任较强,社会认可度高,企业文化氛围好,容易被并购双方和其他利益相关者接受;机构投资者股东对国企并购具有治理作用[35]。这3项指标都可以有效提高国有上市公司并购绩效,有力控制和降低并购风险。
⑤并购特征风险中支付对价净利润比(β=0.254,p<0.01)和支付对价权益比(β=5.273,p<0.01)增加了国有上市公司并购风险,即分别每提升一个单位,并购风险相应增加0.254倍和5.273倍。企业并购支付金额与并购企业内在价值时差额越大,越会相应增加企业自身的财务压力,然而被并购企业由于短期内无法带来高速增长,导致并购整体效果不佳,并购风险加大。
七、结论与建议
1.研究结论
本文将人工智能算法引入到并购重组领域。选取沪深两市A股国有上市公司2014~2017年并购事件,旨在通过对我国国有上市公司并购风险影响因素做出假设,基于XGBoost算法构建国有上市公司并购风险预警模型进行风险预警,并探究了各影响因素对并购风险预警影响的重要程度,运用多元线性回归模型对影响并购风险的相关因素进行了显著性分析,得到如下结论:
第一,将基于XGBoost算法构建国有上市公司并购风险预警模型的预警结果与经典机器学习模型GBDT、RF和传统 Logistic模型作对比,XGBoost模型对并购风险具有最优的预测效果,其次是RF和GBDT,最后是Logistic 回归模型。
第二,构建的国有上市公司并购风险的指标体系中的19个指标对并购风险预警都具有作用,且发现从一级系统体系整体来看,资产结构、创利能力、外部监督和并购特征风险对并购风险预警较为重要,其中投入资本回报率、营业利润率和支付对价净利润比3项指标对并购风险预警最为重要。
第三,资产结构风险中总资产周转率和投入资本回报率越高、法人治理风险中股权制衡度越大、外部监督风险中所聘事务所为四大会计师事务所、具有扶贫行为以及机构投资者股东持股比例越高,越有利于降低并购风险;创利能力风险中每股借款利息和税收资产越高、并购特征风险中支付对价净利润比和支付对价权益比越大,越会使得并购风险增加。同时,是否为四大会计师事务所、是否扶贫两项指标为利用文本挖掘技术抓取的指标,这说明除财务、并购特征等容易获得数据的指标外,不容易获取治理和监督数据同样会对国有上市公司并购风险预警产生很大影响。
2.启示及建议
针对上述研究结论,国有上市公司可以采取以下具有针对性的措施有效地控制并购风险:
第一,国有上市公司应加强存货、应收账款等资产管理,减少固定资产、存货和应收账款,开发适销对路的新产品,提高资产的周转效率;还应加大控制成本力度,降低各种费用,合理减少投入资本,开拓市场,提高收入,提升投入资本回报率。
第二,国有上市公司应灵活使用财务杠杆,并购前期适当减少有息负债,降低每股借款利息;还应合理避税,聘请会计、税务、法律等相关专业技术人才,进行充分的纳税筹划。
第三,国有上市公司在并购初期尽可能聘请四大会计师事务所进行高质量审计和并购咨询,积极听取并采纳相关建议;应根据自身行业特点,多维度积极参与精准扶贫;应积极引进机构投资者尤其是战略机构投资者,与机构投资者股东加强沟通。
第四,国有上市公司应严格制定并购资金需求量及支出预算,在实施并购前对并购各环节的资金需求量进行认真核算,并据此做好资金预算,从而降低支付对价净利润比和支付对价权益比。
3.未来展望
在未来研究中,将继续寻找影响国有上市公司并购风险的关键因素,对XGBoost算法参数和模型融合进行优化,以进一步提高XGBoost算法的分类准确性和计算效率,完善并购风险预警模型及其应用。总之,随着国有资本和社会资本交叉融合的国企改革不断深入、国企并购重组业务的不断涌现,并购风险也会不可避免地随之产生,人工智能算法对于构建并购风险预警模型并进行风险预警具有重要的应用价值,可以早防范、早发现、早干预,从而使国企更有效地开展并购活动。
