煤层底板突水预测的PCA-OPF模型*
2021-07-15江泽华袁志刚谢东海邵耀华
江泽华,袁志刚,2,3*,谢东海,2,3,邵耀华
(1.湖南科技大学 资源环境与安全工程学院,湖南 湘潭 411201;2.湖南科技大学 煤矿安全开采技术湖南省重点实验室,湖南 湘潭 411201;3.湖南科技大学 南方煤矿瓦斯与顶板灾害预防控制安全生产重点实验室,湖南 湘潭 411201)
我国水文地质复杂,特别在华北型矿区,煤层底板多含奥灰含水层,矿井突水事故时有发生[1].矿井突水严重威胁矿工的生命安全,也影响了矿井的安全生产.为确保煤炭资源的安全开采,如何快速且准确地对煤层底板突水进行预测成为亟待解决的问题.针对煤矿底板突水问题我国学者做了大量研究并取得了很多成果[2-7].
煤层开采底板的“下三带”与“四带”的划分对防治矿井底板突水起到了重要作用[2-3].李春元等分析了深部开采砌体梁结构失稳扰动底板破坏的动载源特征,揭示了深部开采底板突水机理[4];白峰青等开展了现场注水模拟试验,揭示了底板岩体破裂变化特征[5];王妍等用弹性力学方法求取隔水关键层的应力以及位移,为采场底板突水的预测预报提供理论支撑[6];王向前等通过在数值模拟软件模拟与突水系数法结合,实现了工作面带压开采的可行性分析[7].
但由于岩体介质的非线性、复杂性、不确定性等特点[8],传统通过理论分析、经验数值计算、相似模拟以及数值模拟满足不了对底板突水预测的需要.近年来,人工智能的发展为解决该问题提供了一种新的途径[9],即利用机器学习对煤层底板突水进行科学预测[10-15].
赵斐提出了模糊-支持向量机模型[10];施龙青等提出了Fuzzy_PCA_PSO_SVC以及基于灰狼算法优化的Elman神经网络模型[11,12];张风达提出了基于PSO算法优化的SVM模型[13];温廷新等提出了PSO_SVM_AdaBoost预测模型[14].以上研究为煤层底板突水预测提供了新方法,但这些算法选取的因子较多,且需要对参数进行优化,尚不能满足对煤层底板突水进行快速且准确预测的需要.为此,本文提出了基于主成分分析的最优路径森林模型(PCA-OPF),该模型通过主成分分析(PCA)将多因子减少为少数几个主成分,简化了最优路径森林算法(OPF)的数据结构,同时利用了OPF算法本身具有与参数无关且不需要参数优化的特点[15],能对煤层底板突水进行快速且准确地预测.
1 PCA-OPF模型基本原理
1.1 PCA
煤层底板突水是由多个非线性因子导致的一种复杂动力现象[1].目前,煤层底板突水预测选择的因子较多,且这些因子之间存在一定的相关性,导致在数据集的分析、处理过程中往往因计算步骤过多而把问题变得更加复杂.
PCA是一种利用降维来简化数据集的数据处理方法,其通过把高维数据投影到低维层面,使原始样本数据中的多个因子减为少数几个能包含原始样本数据大部分信息的综合性指标[16].限于篇幅原因,PCA的具体原理、步骤不再赘述,详见文献[17].
1.2 OPF模型
OPF是由Papa等人提出的一种新的基于图的分类器[18-21].基于数据样本标签的不同,OPF算法可分为3种类型:数据集有标签的监督式OPF算法(SupervisedOPF)[18]、数据集没有标签的无监督式OPF算法[19]和2种情况都有的半监督式OPF算法[20].由此可知,OPF算法的选择主要根据数据集的标签来确定.对于煤层底板突水预测,由于数据样本较少且每个样本均能被正确标记,因此选择SupervisedOPF算法对数据进行处理,并对SupervisedOPF算法的原理进行介绍.
1.2.1 SupervisedOPF原理
数据集Z是被正确用i标记的样本集合(i=1,2,…,c),它被分为训练数据集(Z1)、测试数据集(Z2).而OPF算法对数据的分类是通过构建完全图实现的.具体步骤如下:
1) 训练阶段
OPF算法将Z1中的每1个样本看做为1个节点,并且各节点之间两两相连,并用弧代表他们的连接关系,从而构成了一个完全图G1=(V1,A1)[18].其中,V1代表着Z1各样本间的弧,A1代表了Z1各样本的特征向量.
完全图通过生成最小生成树(MST)[21]获得原型[18]样本s,s∈Z1,即来自不同分类的所有相邻样本.一旦原型样本被找到,它们通过路径代价函数fmax相互竞争并征服来自训练集的其他样本,进而形成一个以原型样本为根节点的最优路径树(OPT)[18],所有的最优路径树就组成了最优路径森林(OPF)[18].OPF算法对最优路径有如下定义:
路径πs是各个以样本s为终点的节点序列.可以通过式(1)为每条路径赋予一个代价f(π).
(1)
式中:fmax()为当路径只有一个样本s时的代价,若s为原型样本则代价为零,若为s他则代价为无穷大.fmax(πs·
如果路径πs的代价f(π)比其他同样以样本s为终点的路径τs代价要小,则路径πs为最优路径.因此最优路径的最小化代价C(t)为
(2)
2)测试阶段
在测试阶段中,每一个属于测试集的样本t被单独分类,它连接了在训练阶段产生的各个最优路径树的所有节点,并计算连接到各最优路径树的代价,若找到路径代价最小的最优路径树,则该最优路径树根节点的标签(原型样本标签)即为测试集样本t的标签.
2 煤层底板突水预测的PCA-OPF模型实现
煤层底板突水预测的步骤:首先收集煤层顶板突水预测相关样本数据,并将样本数据导入OPF算法中进行解析以及分组;其次利用PCA进行主成分分析;最后采用OPF算法对降维后的样本数据进行训练和测试并得到预测结果.
2.1 样本数据的收集
通过对文献[10-14]的煤层底板突水预测样本数据调研,最终确定了本文煤层底板突水预测所采用的30个样本数据.根据OPF算法的要求,对获取的样本数据进行解析以及分组,即将30个样本数据分为24个训练集和6个测试集,分组后的原始样本数据如表1所示.表1中,若煤层底板未突水则标签值为1,若突水则标签值为2;X1,X2,X3,X4,X5,X6和X7分别为选取的断层分维值因子、取芯率因子、隔水层厚度因子(m)、单位涌水量因子(L/(s·m))、渗透系数因子(m/d)、底板含水层总厚度因子(m)和承压含水层水压因子(MPa).以上7个因子对煤层底板突水危险性的影响详见文献[12].
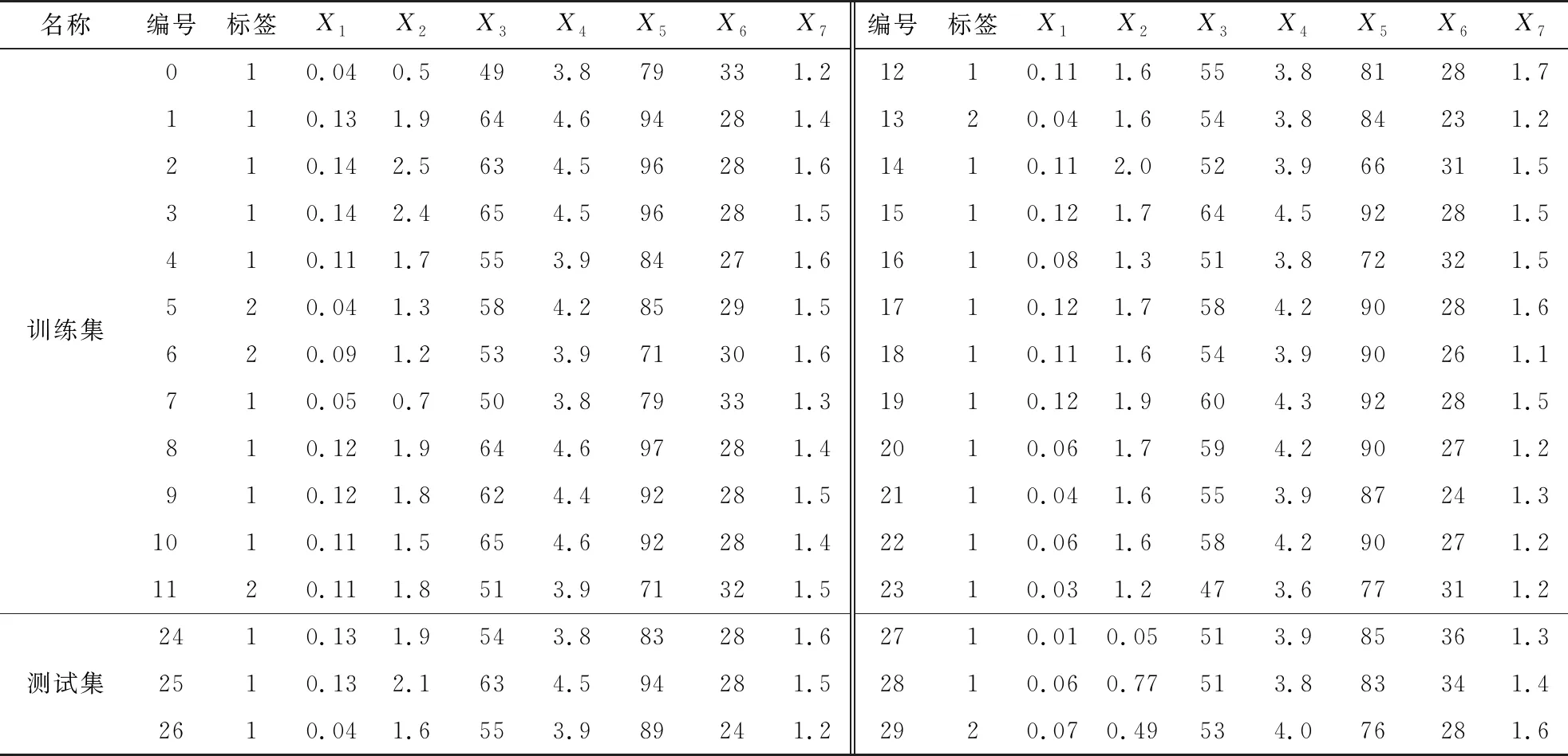
表1 原始样本数据
2.2 PCA主成分分析
为判断PCA主成分分析是否可行,首先须对数据进行相关性分析.由表1可知,原始数据中因子存在量纲,由于量纲影响导致部分因子间的值数量级相差过大(如因子X1和X5),对相关性分析结果产生影响,造成分析不准确[16].因此,为了消除量纲影响,首先对原始数据进行标准化处理,得到处理后的样本数据如表2所示(限于篇幅,表2只给出了部分原本数据).
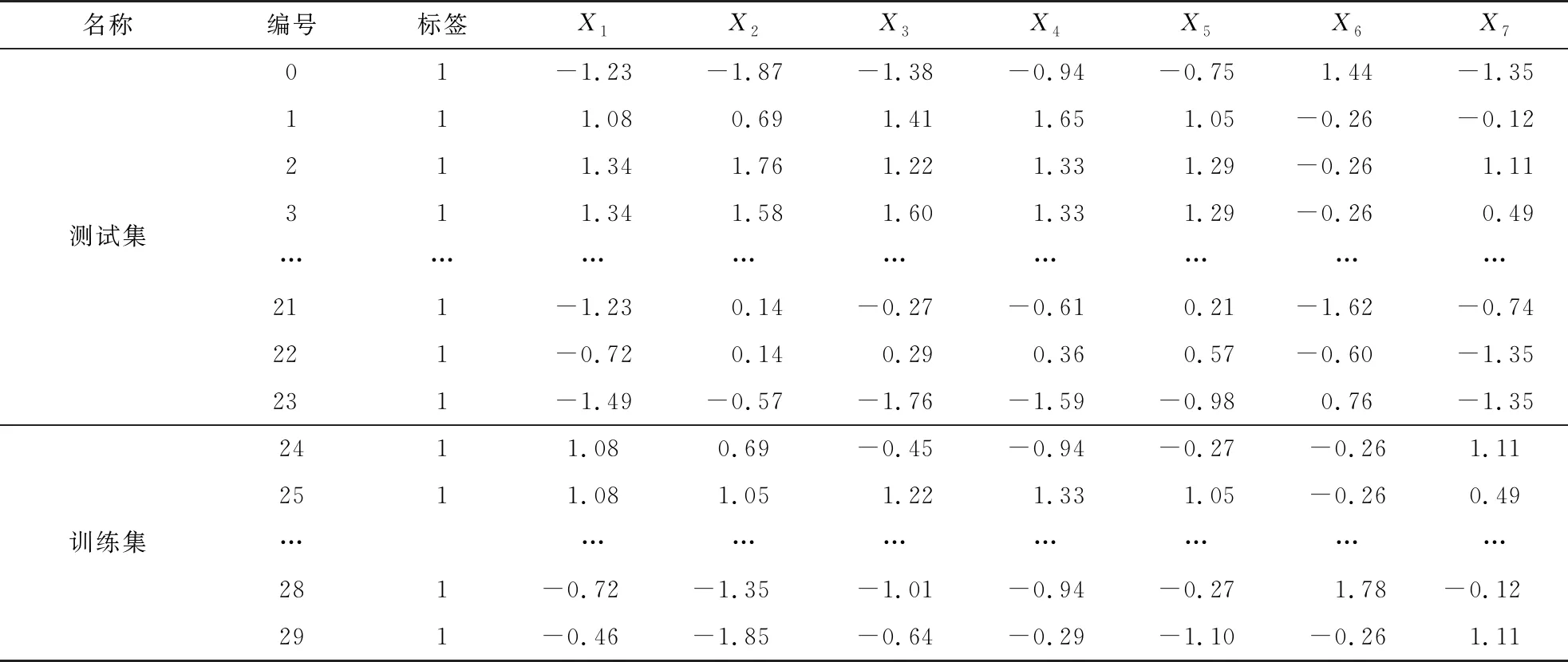
表2 标准化处理后的部分样本数据
通过对已消除量纲影响的样本数据(表2)进行相关性分析[17],得到相关系数矩阵如表3所示.

表3 相关系数矩阵
由表3可知,隔水层厚度X3与单位涌水量X4之间的相关性系数为0.96,而渗透系数X5与隔水层厚度X3、单位涌水量X4与渗透系数X5、取芯率X2与断层分维值X1之间的相关性系数分别为0.82,0.76与0.74.结果表明,选取的7个突水因子之间具有较强的相关性,须对其进行主成分分析.
采用PCA对标准化后的数据(表2)进行处理,得到了主成分分析的碎石图(图1)及其分析结果(表4).
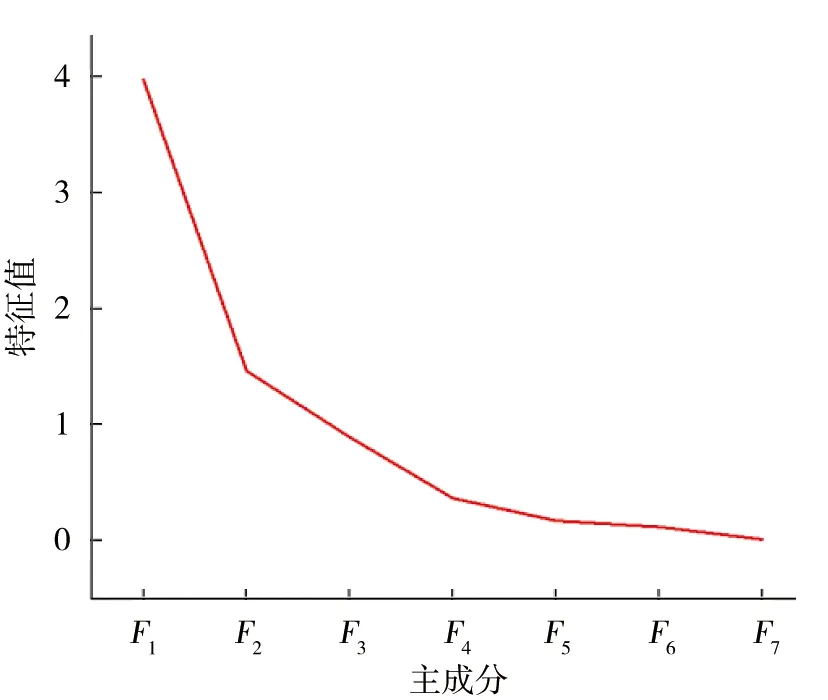
图1 主成分分析碎石

表4 主成分分析结果
由表4可知,前3个主成分F1~F3的累计贡献率为90.4%,表明前3个主成分包含了预测所需要的绝大部分信息,可满足预测需求[11].因此,可将原数据的7个因子降维为3个主成分,3个主成分因子荷载如表5所示.
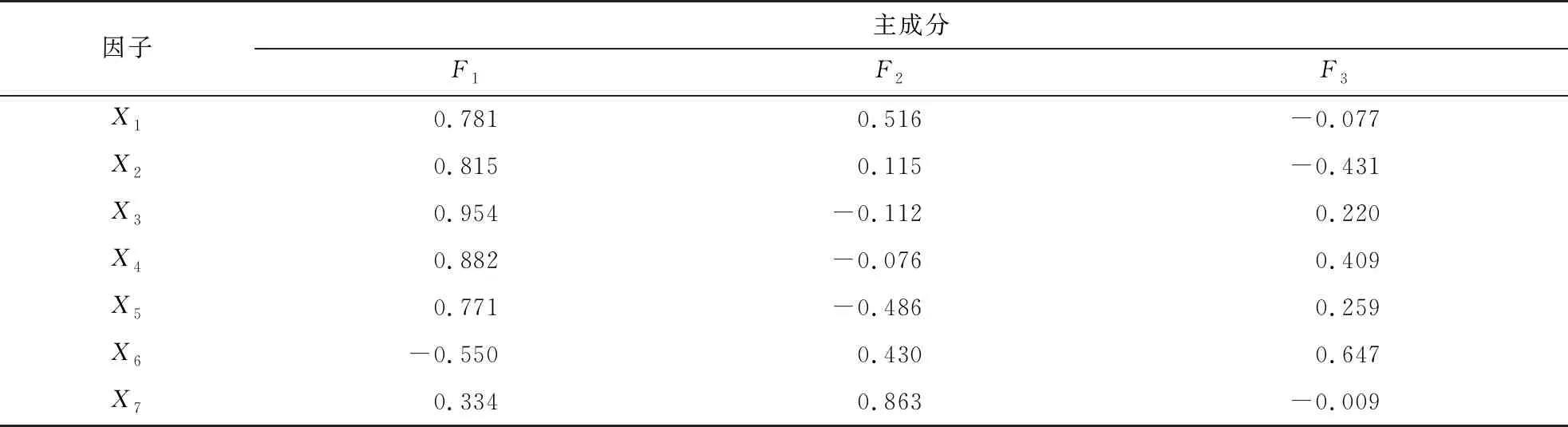
表5 主成分因子荷载
根据表5,得到主成分F1,F2,F3用数据标准化后的7个因子表示为
F1=0.781X1+0.815X2+0.954X3+0.882X4+0.771X5-0.55X6+0.334X7;
(3)
F2=0.516X1+0.115X2-0.112X3-0.076X4-0.486X5+0.430X6+0.863X7;
(4)
F3=-0.077X1-0.431X2+0.220X3+0.409X4+0.259X5+0.647X6-0.009X7.
(5)
由式(3)、式(4)和式(5)得到采用PCA处理后的样本数据如表6所示.限于篇幅,表6只给出了部分样本数据.
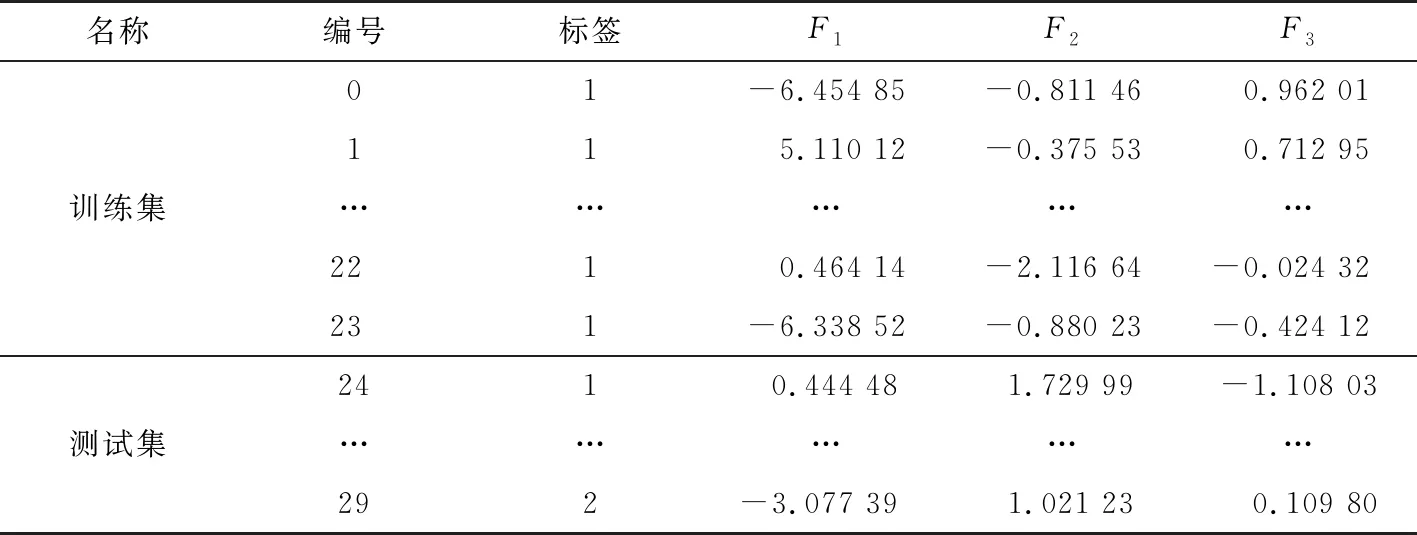
表6 主成分分析后的部分数据
2.3 OPF训练和测试
采用监督式OPF算法对表6的数据进行训练,得到了训练阶段的原型集样本(其包含的样本编号为11,16,14,6,5,4, 13和21这8个原型样本),并基于此原型集样本构建了最优路径森林.
其次,利用训练阶段所构建的最优路径森林对测试集中的每一个样本进行测试,得到的预测结果如表7所示.

表7 OPF预测结果与实际情况对比
由表7可知,采用PCA-OPF模型得到的6个测试集样本的预测结果与实际情况相符.
3 结论
1) 采用PCA主成分分析法可将用于煤层底板突水预测的7个因子降维为3个主成分,3个主成分既保留了原始数据的大部分信息以满足预测需求,同时又简化了OPF算法的数据结构,减少了训练和测试工作量.
2) 构建的PCA-OPF模型利用PCA对原始数据进行简化,并采用OPF算法进行训练和测试,训练和测试阶段与参数无关且不需进行参数寻优,可避免已有方法的局限性.
3)基于PCA-OPF模型的煤层底板突水预测结果表明,采用PCA-OPF模型得到的测试集中6个样本的预测结果与实际情况相符.
