基于图自编码器模型的学生成绩预测
2021-07-14鲁鸣鸣郑一基李海峰
张 阳,鲁鸣鸣,郑一基,李海峰
1.中南大学 计算机学院,长沙410083
2.中南大学 地球科学与信息物理学院,长沙410083
“数据驱动学校,分析变革教育”的大数据时代已经来临,如何利用大数据的优势,挖掘出教育中的模式从而针对性改进教学成为亟需解决的问题。经济合作与发展组织在2018 年发布的《2018 教育概览》[1]调查数据发现,学生期末成绩不合格之后再让学生留级并不能达到让学生跟上进度的目的,想要学生跟上学业进度,最好的方式是尽早干预。能够根据学生的表现较早准确预测学生成绩,并分析影响学生成绩的因素,可以便于学校尽早干预学生学习中出现的问题,使得学生能够跟上学习进度,也能为改进培养方案、教学大纲,以及为学生选课提供指导意见。
现有的成绩预测方法主要可分为贝叶斯网络模型[2-4]、决策树模型[5-7]和推荐算法[8-11]等。这些工作往往需要手动提取特征、先验知识、专家知识,或者只能预测指定的某一门课程的成绩,并且预测的效果往往也不太好。深度学习是一种新兴的能自动提取特征的算法,其中的卷积神经网络和循环神经网络在处理图像数据及序列化数据领域甚至超过了人类的水平。但是,卷积神经网络和循环神经网络无法直接对图结构的数据进行预测。为此,文献[12-13]提出图卷积神经网络(Graph Convolutional Networks,GCN)。将卷积神经网络拓展到图结构形式的数据输入。GCN因为可以很好地融合图结构数据的结构特征和属性特征并且有较好的组合泛化能力,而被广泛使用[14-16]。
由于学生选课的数据可以分为学生节点、课程节点和选课成绩,比较适合建模成二分图形式的图结构数据,因此本文提出基于GCN的成绩预测模型,利用GCN对反映学生课程成绩的二分图进行编码,实现了特征的自动提取并且不需要先验知识或专家知识。成绩预测问题本质上是一个矩阵填充问题,其与推荐系统中使用矩阵填充模型预测推荐类似。考虑到不同的课程都有各自的特点,不同学生之间也存在差异性,以及课程和学生之间存在着某种潜在的相关性,提出使用自编码器中的高斯混合模型刻画其分布,其中GCN[12]作为AE 的编码部分。该模型将学生节点和课程节点特征信息以及节点间的成绩关系矩阵输入GCN 进行编码,从而获得学生成绩数据的内在特征,得到节点的嵌入表达再输入解码器,最终获得预测的学生成绩矩阵。
为了验证本文所提出Graph-AE 模型在学生成绩预测上的有效性,通过实验与3 种经典的推荐算法:基于分类/聚类的推荐算法、基于矩阵分解的推荐算法、基于协同过滤的推荐算法,进行了对比。实验结果表明,该模型在3 组数据集中RMSE 均低于经典推荐算法0.097~2.563。
综上所述,本文主要贡献如下:(1)提出并实现一种基于无监督学习模型Graph-AE 并运用于学生成绩预测;(2)通过大规模实验与目前比较好的4 种类型的推荐算法进行了对比,验证了Graph-AE 模型在成绩预测方面的有效性。
1 相关工作
当前已有大量研究工作对学生成绩进行预测。比如,参考文献[2]提出了基于贝叶斯网模型的成绩预测模型对一门课程的成绩进行预测,但该模型需要手动筛选特征。文献[5]提出基于决策树模型的成绩预测,但需要大量先验知识作为输入。文献[6]提出利用电子签到系统数据预测成绩,但该工作需要从大量的考勤、作业和课堂位置信息数据中推理出学生心理状态,从而预测学生成绩。
本文提出的成绩预测模型本质上是一个矩阵填充问题,这一问题与推荐系统中使用矩阵填充模型预测推荐类似,因此可以借鉴推荐系统的算法。经典的推荐算法可划分以下几大类:(1)协同过滤推荐算法[8],包括基于邻域的协同过滤[17](基于用户和基于项)和基于模型的协同过滤(受限玻尔兹曼机[18]、矩阵因子分解[19](如奇异值分解,奇异值分解++)、贝叶斯网络、聚类、分类、回归等),这些方法面临冷启动问题,并且难以解释模型预测的依据;(2)基于内容的推荐算法[10],包括机器学习方法(朴素贝叶斯、支持向量机、决策树等)和信息检索(Term Frequency-Inverse Document Frequency,TF-IDF)算法、BM25(Best Match25)算法,这类方法的项内容必须是机器可读和有意义的,很难联合多个项的特征;(3)混合推荐算法[11],该类算法综合利用协同过滤推荐算法和基于内容的推荐算法各自的优点同时抵消各自的缺点,算法输入通常使用用户和待推荐物品的内容特性与历史数据,同时从两种输入类型中获益,该类算法没有冷启动问题,没有流行度偏见,可推荐有罕见性质的物品,可以实现多向性,但是需要同时考虑协同过滤推荐算法和基于内容推荐算法,才能得到优缺点的恰当平衡。
相比之下,本文提出成绩预测模型主要从学生和课程的相关性进行研究,利用自编码器模型刻画学生和课程之间的相关性以及差异性,不用手动筛选特征,不需要大量先验知识和专家知识并且可以精确的预测成绩区间。
2 Graph-AE模型介绍
自编码器是一种无监督学习算法,主要用于数据降维或特征提取[20]。它可以自适应地学习到数据中的结构,并使用学习到的特征来高效的表示数据,这种特性不仅可以适应大数据环境中巨大的数据量和数据种类,而且可以克服经验特征较大的设计代价和泛化性能差的问题,同时在深度学习中使用自编码器来实现多层次的特征提取可以取得更好的分类精度[21]。自编码器分为输入层、隐藏层和输出层,其目的是将输入层的数据x通过转换得到其隐含层的表示h(x),然后由隐含层重构,还原出接近原始数据的抽象的表示。因此,自编码器也存在鲁棒性较差和深度学习应用中出现过拟合现象等问题[22]。
获取图数据中合适的节点嵌入表达非常不易,而如果能找到合适的嵌入表达,就能将它们用在其他任务中。本文提出的Graph-AE模型主要是基于自编码器模型自适应学习特点的改进。将学生成绩数据之间的关联性刻画成二分图,使用GCN 代替自编码器中的编码操作进行节点间的消息传递,提取特征。这样可以将自编码器应用到图数据上,并且将成绩数据进行等级划分,使得数据更加稀疏,能更好地学习图数据的特征并减少过拟合。
本章主要从成绩数据的二分图建模、模型的整体架构、编码器和解码器的实现等四方面介绍本文的成绩预测模型Graph-AE。
2.1 二分图建模
本文将学生成绩数据建模成二分图结构,如图1(a)所示。每个学生/课程都当成一个节点,学生如果选了课程则用无向边连接两个节点,无向边的权重为学生的课程成绩。这样一个无向二分图可以表示为G=(U,V,R),U为学生节点集合,V为课程节点集合,R为图G的边集。ui∈U(i∈{1,2,…,m})表示第i个学生节点,vj∈V(j∈{1,2,…,n})表示第j个课程节点,m为学生总数,n为课程总数,图的总节点数N=m+n。二分图转化成邻接矩阵,M∈ℝN×N形式存储,如图1(b)所示,矩阵A大小为m×n,AT是A的转置矩阵(无向图的邻接矩阵为对称矩阵)。
不同成绩等级存在的潜在模式不同,处于不同等级的学生之间有较大差别,不同的成绩等级的课程间亦然,因此,将成绩划分成1~10共10个等级。并且分等级计算可以大大减少计算量。学生的成绩数据是边的权重r,将边的权重划分为10 个等级,r=└课程成绩/10┘+1,r∈{1,2,…,10},Aui,vj=r,表示学生ui在课程vj上的成绩区间为r,且按照权值r将邻接矩阵M分解成10个等级的0-1矩阵M1,M2,…,M10如图1(c)所示。第r等级的矩阵其中Ar 为大小为m×n的0-1矩阵,r∈{1,2,…,10}。若学生i所选课程j的成绩区间为r,则Ar第i行第j列的值为1。而对于其他等级r′≠r,Ar′对应的第i行第j列的值为0。
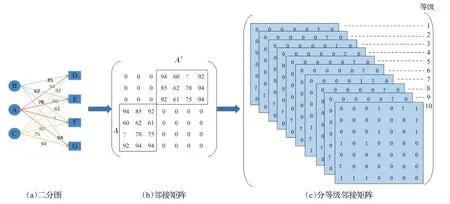
图1 数据预处理
2.2 整体架构
本文提出的学生成绩预测模型Graph-AE整体架构如图2所示。将现有的课程信息、学生信息和成绩数据整合成二分图的形式,并将二分图G的邻接矩阵M和顶点的初始化表示X作为AE 编码器(即GCN)的输入。经过GCN编码之后的向量将通过解码器输出成绩预测矩阵,完成矩阵填充的过程。Graph-AE模型主要包括编码器Encoder 部分和解码器Decoder 部分。输入数据X经过2 层GCN(ReLu 作为激活函数)之后输出编码的均值Z_mean 和标准差的对数Z_log_std,得到输出Z,作为解码器Decoder 的输入部分,数据经过解码器Decoder 得到成绩预测矩阵。其中,在卷积前节点只携带自身信息;第一层卷积时,节点将其携带信息传递到其相邻节点,经过卷积之后节点学习到其邻居节点的信息;第二层卷积时,节点及其携带的邻居节点的信息传递到其下一跳节点,经过卷积之后节点学习到其两跳邻居节点的信息[23]。
2.2.1 GCN层简介
本小节主要介绍图2 中的编码器Encoder 部分,如图2所示,使用GCN作为编码器,且它是序贯式堆叠(前一个编码器的输出作为下一个编码器的输入)以达到逐层抽取数据特征的目的。
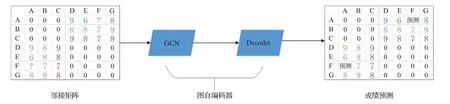
图2 模型整体架构
GCN的整体结构如图3所示,其中圆形表示学生节点,矩形表示课程节点,节点右上角表示节点的特征X(分别用红、橙、黄、绿、青、蓝、紫颜色的矩形表示节点A、B、C、D、E、F、G自身所携带信息)。在GCN中网络结构是嵌套的,如图3所示。外层网络根据图的邻接矩阵等信息实现相邻节点之间的特征传播和融合,如图3(a)所示。内层网络通过浅层全连接前馈神经网络实现节点内部各维度特征的融合和降维,其中每个神经元对应单个特征维度的信息,如图3(b)所示。内层网络是所有节点共享的,作为整体嵌入到外层网络。以节点A 为例,在图卷积操作前,节点只携带自身信息,即特征向量A,它是五维。经过外层网络的计算之后,节点A 融合了其邻居节点D、E、F 和G 的特征,得到五维特征向量。再经过内层网络计算之后,融合并压缩了各维度特征,得到三维特征向量

图3 GCN模型架构
本文采用两层的GCN 当做编码器,其中第一层的隐层神经元个数为64,第二层的隐层神经元个数为32。即第一层是64维特征的融合,然后降维为32维,第二层是32维特征的融合,然后降维为10维(输出层节点个数)。特征融合可以将神经元学到的局部特征进行融合,降维是为了减少过拟合,降低运算的复杂度。之所以设置两层GCN是因为一层神经网络不能解决非线性问题,而网络层的叠加会造成运算量的几何倍增大,但是精度并不会提高,一般情况下神经网络层数不超过3层,层数过多会造成精度的下降以及运算量的增大。这个特征维度的确定是根据常用的神经网络隐藏层单元数设置公式,然后根据实验结果在一定范围内的微调尝试得出来的。
值得注意的是图3中M表示图的邻接矩阵,X是所有节点的特征向量组成的矩阵,W是内层网络的参数矩阵。但GCN 实际采用的是GCN=σ(LXW)[24],其中L是拉普拉斯矩阵,L=D-M,D为度矩阵。图3采用M矩阵只是为了方便理解。实际上,对于图中每个节点而言,拉普拉斯矩阵在邻接矩阵的基础上引入度矩阵所起到的作用是分别计算该节点与其各个邻居节点特征信息的差异,并对差异值进行加权求和[13]。在本文中,邻接矩阵的值是学生对应的课程成绩。对节点差异值进行加权求和就是将学生之间的成绩差距进行加权求和,以便网络更好的了解学生之间的差异性。具体权重值是神经网络的权重系数,由机器自己学出来的。
图G的邻接矩阵M、度矩阵D和初始化的节点矩阵X输入GCN编码器学习数据之间的潜在相关性,经过激活函数ReLU得到隐藏层表示,最终得到学生节点编码矩阵Zu∈ℝm×K和课程节点编码矩阵Zv∈ℝn×K(m名学生,n门课程,K是超参数,是编码之后的特征维度)。

上述过程可以用公式(1)和(2)来刻画。式(1)中的D-1MrXWr,r∈{1,2,…,10} 相当于综合度矩阵、邻接矩阵、特征矩阵和权重矩阵的信息,其中D-1Mr对应第r等级成绩矩阵经过标准化后的拉普拉斯矩阵。Wr对应第r等级成绩矩阵的内层网络参数矩阵,用来学习第r等级的成绩模式(假设是不同等级成绩的模式也不同)。sum(⋅)加和操作是对各成绩等级学到的模式进行融合,从而得到反映学生节点和课程节点特征的中间隐藏层表达Hu∈ℝm×K和Hv∈ℝn×K。式(2)所起到的作用是将是将式(1)所得到的Hu和Hv通过参数矩阵W∈ℝN×K所对应的全连接前馈神经网络进行特征维度的进一步融合,得到学生节点编码矩阵Zu和课程节点编码矩阵Zv。
2.2.2 解码器
将成绩数据分为10 个等级输入编码器,在GCN 编码之后将10个等级数据通过融合在一起形成编码向量Z,然后通过解码器预测学生成绩属于10 个等级之中的哪一个等级。如图4所示,即通过解码器将编码器输出的节点特征矩阵Z作为输入,得到每个等级成绩对应的中间结果,如公式(3)所示,然后通过归一化函数确定中间结果属于哪一个等级。

图4 解码过程

其中,Hr表示r通道的权重矩阵,表示第r通道的输出,⊙表示矩阵点乘;Hr大小为N×K。

2.3 优化目标
不同的损失函数,对应p(x|z)的不同概率分布假设,这里每个节点编码向量zi所符合分布的均值μi和方差σi未知,用最大似然估计优化M,使得有一组均值μi和方差σi可以让生成向量的概率取lb 后最大。训练过程,最小化负的lb 似然值,并用交叉熵cost(见公式(5))来度量M和Mˉ的差异,cost越小,M和Mˉ越接近。

Graph-AE 模型从输入到输出所有运算均可导,由此通过SGD[25]优化该网络。该模型训练过程利用学生节点和课程节点的信息X以及学生成绩M作为输入,编码过程生成学生和课程节点的编码Z,最后输出学生成绩,该过程是一个无监督的学习,刚好适合成绩数据。
3 实验评估
3.1 数据集描述
本文所采用的成绩数据集取自中南大学信息科学与工程学院2010 年至2016 年的研究生成绩数据,共有学生顶点数Nu=369,课程顶点数Nv=142。本文将总数据集分割为三部分:2015 年9 月—2016 年7 月(记为data1)、2012年9月—2016年7月(记为data2)以及2010年1月—2016年12月(记为data3)。data1用以观察一年时间的数据情况,data2 用以观察四年时间的数据情况(因为学校的培养方案是四年变动一次),data3 是所有数据。
本文使用RMSE[26](均方根误差)来评估成绩预测模型的预测误差。RMSE是均方误差的算术平方根,是最常用来评估预测数据与真实数据差异的一个指标,其计算如公式(6)所示。该评价指标反映预测值和真实值的差距,值越接近0,差距越小。
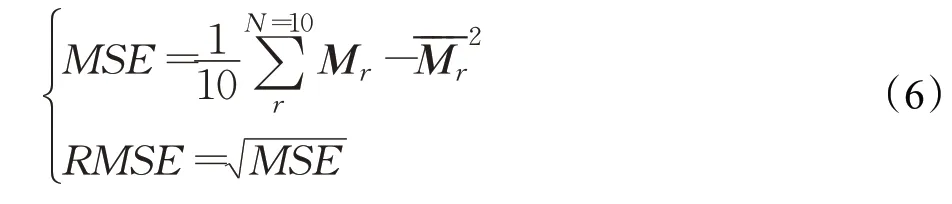
3.2 基础实验
为了确定实验中的参数,做了4 个基础实验。将data1、data2、data3数据集各自划分成85%、10%和5%作为训练集、测试集、验证集。模型学习率为0.1,优化算法为ADAM,Dropout 率为0.1。预设有两个GCN 编码器单元,前者特征维度K为64,后者特征维度K′为32。
为了确定数据分10 个等级的合理性,观察了将数据分为1、2、4、6、8、10、12、15和20各个等级下的实验效果,如图5所示,将学生成绩分为10个等级的时候,效果最好。

图5 各等级数据RMSE的变化
为了确定模型的迭代次数epochs,观察了模型在3组数据集中训练集损失函数(loss)值随迭代次数变化的情况,如图6所示。实验结果表明模型在迭代数epochs达200时稳定收敛,因此选定模型参数epochs为200。

图6 3组数据训练loss值的变化
为了观察不同时间段数据的区别,观察了3组数据集随着训练迭代次数的增加,RMSE值的变化情况。如图7 所示,3 组数据集的RMSE 曲线变化的趋势是一致的。从图7可观察到仅有规模较小的数据集data1的训练过程存在一个小幅度的波动。这说明即使在不同时间跨度不同数量级的训练数据上,模型都能很好地学到数据的特征。

图7 3组训练数据RMSE变化
神经网络模型训练中一般采用对模型参数随机初始化的方式初始化参数。由于每次训练随机产生的初始值存在差异,因此模型训练的评价指标以及预测结果会存在变化。为了确定模型的效果,观察使用data1 数据集随机实验10 次得到的测试集评估指标,并且加入常用的MSE 和MAE 来辅助验证。如图8 所示(横轴表示实验次数,纵轴表示评价指标具体数值)。从图8 可以观察到,随机实验10 次后得到的各项评估指标趋于稳定。因此,后续实验中,采用随机实验10次取均值的方式表示模型的训练效果。

图8 模型指标随实验次数的变化趋势
3.3 对比实验
为了验证模型的有效性,将Graph-AE 与3 种经典的推荐算法(分类聚类成绩预测、矩阵分解成绩预测以及协同过滤成绩预测)进行对比。
典型的推荐算法大致分为分类/聚类、矩阵分解以及协同过滤三类。其中,分类/聚类成绩预测主要包含基于学生用户邻域推荐的k近邻算法(userKNN)、基于课程邻域推荐的k近邻算法(itemKNN)、基于学生用户推荐的聚类算法(user cluster)、基于课程推荐的聚类算法(item cluster)等4种方法;矩阵分解方法成绩预测主要包含奇异值分解++(SVDPP)、非负矩阵分解(NMF)、biased 矩阵分解(biasedMF)、局部低秩张量矩阵分解算法(LLORMA)以及贝叶斯概率矩阵分解算法(BPMF)等5种方法;协同过滤成绩预测主要包含基于全局的协同过滤推荐算法(global average)、基于内容的推荐算法(aspect model rating)、基于课程的协同过滤推荐(item average)、基于学生的协同过滤推荐(user average)等4种方法。
实验对比了以上3 大类方法,实验结果如图9 所示。其中,图9(a)展示的是Graph-AE与分类/聚类推荐算法对比,在数据集data1、data2 和data3 上,Graph-AE的RMSE 比分类/聚类推荐算法平均低0.097、0.364 和2.046;图9(b)展示的是Graph-AE 与矩阵分解算法对比,在数据集data1、data2和data3上,Graph-AE的RMSE比矩阵分解算法平均低0.134、0.703 和1.748;图9(c)展示的是Graph-AE 与协同过滤算法对比,在数据集data1、data2和data3上,Graph-AE的RMSE比协同过滤算法平均低0.666、0.253 和1.186。实验表明,Graph-AE的RMSE 均明显小于这13 种推荐算法,且在数据集data3中尤为明显,data3根据培养方案,有些课程可能存在变动,此时其他模型不能很好地适应这种更改,而本文模型可以很好地适应。
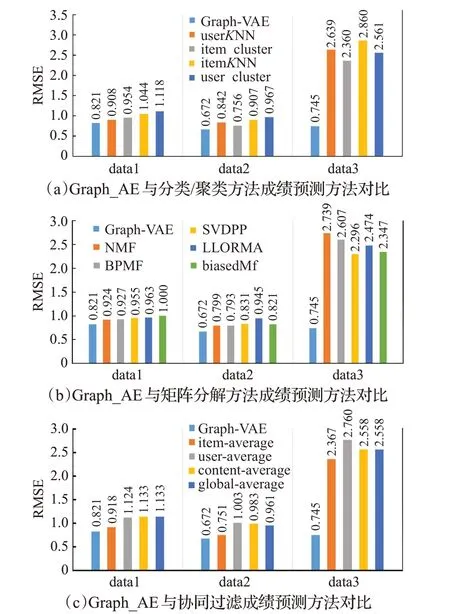
图9 Graph_AE模型与经典推荐算法的RMSE对比
4 总结
成绩预测可以帮助学校和老师尽早发现问题,对学生个体进行建模并针对性改进教学的手段,从而有效促进学生学习。本文针对现有工作的问题,提出了一种Graph-AE 模型,相比以往模型这种模型能自动抽取学生成绩数据的关键特征,从而完成成绩预测任务,促进教育教学质量的提升。本文分析了该模型的工作原理,并通过实验验证了模型的有效性。
