面向动态数据块的非平衡数据流分类算法
2021-07-14王俊红郭亚慧
王俊红,郭亚慧
1.山西大学 计算机与信息技术学院,太原030006
2.计算智能与中文信息处理教育部重点实验室,太原030006
在计算机网络中,控制监控系统的故障诊断和入侵检测等数据流往往呈现不均衡的类分布。在这些情况下,某些类别的数据比其他类别的数据更困难或更有意义,在文献中称为类别不平衡。在不平衡数据中,一般只含有两类,其中样本少的类称为少数类,而样本多的类则称为多数类。目前传统的针对平衡数据集的分类算法对于多数类和少数类的分类精度相差甚远,导致整体上的分类准确率比较好,但是少数类的分类效果比较差[1]。这可能会导致性能的大幅下降,因为大量的多数类示例会超过模型的增量更新,而少数类示例很可能被忽略[2]。所以,非平衡数据分类算法任务的重点就在于如何提高少数类的精度,还要维持较高的整体分类精度。从这种不平衡的数据流中学习被称为在线类不均衡(OCI)学习[3],这对现有的研究提出了挑战。数据流中的概念漂移就是其中之一,即底层数据的分布随时间发生不可预测的变化现象。这一点在数据流分类中是很重要,因为在现实世界中,数据往往是非平稳的。例如,在故障检测过程中可能会出现新的故障类型。虽然存在检测和处理概念漂移的方法,但是类不平衡加剧了需要解决的问题。
近年来,不平衡数据分类问题已经引起了国内外众多学者的广泛关注,主要是从数据预处理层和分类算法层两方面进行[4]。数据处理的主要思想就是在分类之前对原数据进行平衡调整,使不平衡数据达到一定程度的平衡状态。常用的调整非平衡数据的方法为采样技术、数据重组和单类学习方法;算法层面就是通过调整分类算法来适应数据的不平衡,大致可以分为两类方法:代价敏感学习和集成学习。在不平衡数据分类算法中,通常将数据处理和算法改进结合起来,例如将结合采样方法、代价敏感和集成学习等,以提高分类效果。
数据流中存在的概念漂移现象使得上述传统的分类算法难以满足其需求,固定的分类模型不再适用于动态数据流的变化。所以,数据流分类方法成为很多国内外学者的研究重点。文献[5]提出了一类适用于在线代价敏感学习的算法方法,利用现有的在线集成算法方法与批处理模式方法相结合,用于代价敏感bagging和boosting 算法。文献[6]改进了Online Bagging 内部重采样策略,增加了类不平衡检测机制,提出OOB和UOB算法。并且针对非平衡数据流中的概念漂移问题,提出了概念漂移检测的一种改进[7],通过监控少数类的Recall值的下降来判断产生漂移。为了解决重复出现的概念漂移对分类速度的影响,文献[8]提出了存放分类模型的池机制,通过KL-distance判断概念漂移,若重复出现,则从池中直接获取与之相对应的分类模型,避免重复更新分类器,加快分类速度。文献[9]提出了一种从增量数据中学习贝叶斯网络的新方法,设计了一种新的增量评分函数,即采用logP(D|B)/N和logP(D′|B′)/N′作为评分函数,自适应地调整增量学习过程中新旧数据匹配的趋势。文献[10]提出一种基于加权机制概念漂移策略,使用基于信息表的高斯朴素贝叶斯分类器,利用“Kappa 统计”方法建立基于加权机制的概念漂移检测方法,根据输入数据波动性,分别采取线性函数和贝叶斯函数进行检测,利用专家点删除和信息表来处理经常性的概念漂移,实现漂移检测精度和效率的提升。为解决数据流分类过程中样本标注和概念漂移问题,文献[11]提出了一种基于实例迁移的数据流分类挖掘模型。使用支持向量机作学习器,借助互近邻思想在源域中挑选目标域中样本的真邻居进行实例迁移,避免发生负迁移,通过合并目标域和迁移样本形成训练集,提高标注样本数量,增强模型的泛化能力。文献[12]基于OS-ELM,提出了一种动态阈值的概念漂移检测方法,通过新收集的数据量化更新模型的修改量,当两个OS-ELM模型的差异测量D(M∗(t1),M∗(t1+Δt))>Th时,检测到概念漂移。
与以往仅仅解决数据流中的概念漂移不同,本文主要针对概念漂移和数据不平衡两种问题,解决数据流分类算法在检测概念漂移的同时对非平衡数据进行处理,提出了一种面向动态数据块的非平衡数据流分类算法(Imbalanced data Stream classification algorithm based on dynamic Data Chunk,ISDC)。该算法在数据流分类过程中,通过设置Kappa系数检测漂移的概念漂移检测机制[13]来监测数据块的概念变化。当检测到概念漂移时,预示着可能出现了数据的不平衡,系统依据已有的知识,及时将所有不符合要求的分类器淘汰。然后,需要对数据中的不平衡进行检测,采用经典的过采样SMOTE 方法平衡数据。保留当前数据块的少数类样本,对其进行SMOTE过采样增加少数类数量,得到相对平衡的数据集,利用采样后的数据训练新的分类器加入到分类器集成中。
1 相关概念
1.1 Kappa系数
Kappa系数用于一致性检验,也是一种衡量分类精度的指标,其值的方法如下[14]:

其中,p0表示观测精确性或一致性单元的比例,pe表示偶然性一致或期望的偶然一致的单元的比例。
在对数据流进行分类时,如果数据流中的概念在一定阈值内没有发生改变,即使有快速的不断到来的数据,分类器也会适应当前数据流的分布,使得分类效果慢变好,到达一定值后趋于稳定。若分类器前后的分类效果呈现不一致性,则表示当前数据块发生了概念漂移。为了有效地利用Kappa系数检测概念漂移,利用重新定义的Kappa系数公式和阈值:

其中,pi为分类模型对最新数据块Bi分类结果的准确率,对应相同的下标;为当前与上次概念漂移之间的每个数据块被所有子分类器进行分类的结果准确率的平均值。因此根据公式推导,当Kappa 系数不满足下式(3)时,可判断概念漂移的发生。
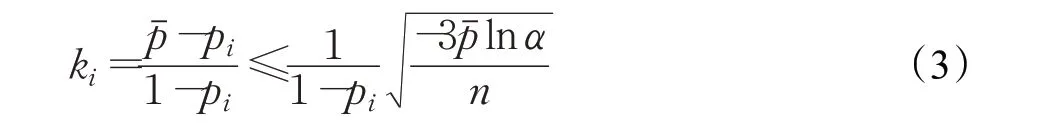
其中,ki为根据式(2)和数据块Bi计算出的Kappa 系数,α为显著性水平,n为实验观测的次数。
由式(2)可以看出,Kappa 系数指的是上次概念稳定时的分类模型与目前分类模型分类性能的差异性,它可以用来度量当前分类器的性能。概念越有可能处于稳定状态,当前分类器的分类性能越好,差异性也越小;反之,差异性越大。在公式计算中,分类器在之前概念稳定时的性能用来评价,是由于对相邻两个数据块的分类性能的对比存在一定得偶然性误差,因此要对两次概念漂移出现时的分类器的一致性进行比较。
1.2 不平衡问题
数据中的类不平衡一直是分类问题中的重点和难点,针对这一问题,学者们对于传统的分类器(例如,贝叶斯、K近邻、决策树等)已经进行了深入的研究,得出了很多适应类不均衡的分类算法。数据流中的类不均衡指的是:在数据流中,一个类别的样本数远远少于其他类别。给定一个数据流{…,dt-1,dt,dt+1…},其中dt(xt,yt),xt表示t时刻到达的数据样本的属性变量,yt表示该数据样本的类标签。设当前训练数据集为S,其中,多数类样本记为集合N,少数类样本记为集合P,且S=P⋃N。因此,不平衡分类也可以看作是二类问题,样本数少的为少数类或者正类,样本数多的为多数类或者负类,在不平衡数据中,样本数少的少数类往往具有更高的价值。在数据流分类过程中,如果少数类样本数非常少且出现的频率低,少数类与多数类的比例甚至为1∶999,这会导致分类模型预测不到少数类,但是分类准确率却高达99.9%,这对于具有重要价值的少数类来说是没有意义的。例如,在疾病诊断中,患癌症的人远远少于没有患病的人,可以正确地检测到癌症对病人是非常重要的。
在数据流中,通过少数类样本在整个样本中的所占数量,就可以得知整个数据集的不平衡率。当P/S=0.5时,数据是平衡的,当的值小于一定阈值时,当前数据被看作是不平衡的。本文算法以数据块的方式处理快速到达的数据流,因此需要对当前处理的数据块进行非平衡检测,若数据块不平衡,这时就要对非平衡数据流进行处理。
通过对数据处理来解决非平衡问题的常用方法就是对数据进行抽样,包括对多数类的欠采样和对少数类的过采样。本文采用过采样中的经典方法——SMOTE采样方法,当检测到当前数据块不平衡时,对数据块中的少数类用SMOTE方法,使少数类样本增加,达到一定程度的平衡,然后用采样后的数据训练分类器。
1.3 评价指标
整体分类准确率指标对于少数类而言是不科学的,因此针对二分类问题有其特有的评价指标,一般使用混淆矩阵来表示分类结果,TP(True Positive)表示预测标签与真实标签都为正类;FN(False Negative)表示预测标签为负类,真实标签为正类;FP(False Positive)表示预测标签为正类,真实标签为负类;TN(True Negative)表示真实标签和预测标签都为负类,如表1所示。

表1 混淆矩阵
根据表1 中的指标,常用的类不均衡评价指标如下所示。
(1)精度(Pression),也称为查准率:

(2)召回率(Recall),也成为查全率,即正类的分类准确率:

(3)F1测度,可以正确衡量分类器对正负类的分类性能:

(4)几何平均G-mean值,用来衡量非平衡数据集的分类性能:

(5)AUC 值,是值ROC 曲线下方的面积值,直观的反应了分类器的分类能力,其值越高,分类性能越好。
为了更好地衡量本文算法对数据流中少数类以及整体的分类能力,因此分别使用了Recall、F1 以及AUC作为实验的评价指标。
2 面向动态数据块的非平衡数据流分类算法
ISDC 算法通过计算每个数据块分类结果的值,利用式(2)和式(3)来检测数据流的概念是否处于稳定状态。当不满足式(3)时,表示分类模型的性能有所下降,概念漂移出现。当检测到概念漂移后,当前的分类模型已不再适用,必须根据一定的规则更新分类器。因此,本章要一次淘汰掉表现差的所有子分类器,使得算法能够很快适应数据流中的当前概念。此时,要计算数据块在每一个子分类器训练下的Kappa值,需要用子分类器对数据块的分类准确率来代替式(2)中的,计算出代入式(3)来判断当前子分类器是否适应当前数据,若不符合,则把该子分类器删除。然后再进行非平衡检测,根据平衡后的数据训练新的子分类器加入到分类模型中。
2.1 ISDC算法框架
基于上述思想,本文提出了针对存在概念漂移和不平衡的数据流分类算法ISDC。主要框架示意图如图1所示。

图1 ISDC算法框架示意图
2.2 算法执行过程
由以上知识可知,ISDC算法的执行过程如下。

3 实验结果与分析
为了验证文中的算法与同类算法对数据流的分类性能,数据集选用MOA[15]环境产生Hyperplane(Hyp)包含概念漂移的平衡数据集,以及9个选自UCI的真实数据集,分别是Horse、Echocardiogram(Ech)、Germany(Germ)、Breast Card(BC)、Tic、votes、bankfull(bank)、Online shoppers intention(ONSI)和Dcredit card(DC),包含概念漂移的不平衡数据集。数据情况如表2所示,表中包含数据集名称、数据集的大小、属性个数以及非平衡率,其中非平衡率是少数类占数据样本总数的比值。这些数据集的数据为两类样本数据,大多为数值型,针对个别一些为字符的属性,进行人为修正,将字符用数值表示。

表2 实验数据集
实验选用BWE[16]、AE[17]、AWE[18]以及DSCK[13]作为对比算法,在Recall值、AUC值和F1值等评价指标上对算法进行分析。实验环境为:Windows10 操作系统,Intel Core2.94 GB 四核CPU,8 GB 内存,算法程序由Matlab R2016a实现。进行一些相关的实验设置,设定子分类器数目的上限k=4,显著性水平α=0.05,σ=10−7。AE、AWE和BWE 算法的基分类器采用C4.5 算法实现,DSCK和ISDC算法的基本分类器采用CART算法实现。每次训练过程中选取数据集的80%作为训练集,20%作为测试集。
由于每个数据集的数量不同,因此划分的数据块大小不一致,在实验过程中对每个数据集选用的窗口大小也不尽相同,实验结果如表2~4 所示,表中黑色加粗的数值为每一行的最大值,最有一列分别为数据集所采用的数据块大小。
由表3 分析可得,除去hyperplane 数据集,ISDC 算法在其他数据集上的Recall 值都是最好的。尤其与DSCK 进行对比,Recall 值的提高是由于在处理概念漂移的基础上增加了对不平衡数据的处理,SMOTE 方法使少数类的分类能力得到提高。而对于hyperplane 数据集,由于它本身就是平衡数据集,所以并没有用到本章算法中的SMOTE 采样方法,分类结果与DSCK 是一样的,因此,该算法在处理非平衡数据方面具有一定的优势。综合来看,ISDC 算法在处理非平衡数据流优于其他算法。

表3 实验算法在不同数据集上的平均Recall值
从表4和表5来看,ISDC算法比AE、AWE、BWE算法在大多数数据集上的效果好,主要与概念漂移的处理策略有关。在ISDC 算法分类过程中,当检测出概念漂移时,分类性能较差的所有子分类器在算法中都将被删除。对比AWE和BWE算法,采用逐步淘汰的策略对分类器做出调整,若想淘汰多个性能较差的子分类器则需要很长的训练过程。在所有不符合要求的子分类器被完全淘汰之前,一部分性能较差的子分类器仍然会对新数据进行分类,当分类器的淘汰速度匹配不上概念漂移的变化速度时,BWE和AWE算法的分类准确率就会受分类器的影响,性能降低。ISDC 算法比DSCK 算法分类效果好的原因就在于对数据进行了平衡处理。概念漂移和不平衡之间不是必然的,二者都是影响分类结果的因素,都应该进行检测与处理。因此,当出现数据不平衡时,对少数类用SMOTE 算法平衡数据,用平衡数据训练新的子分类器,使得分类器一直保持较好的分类效果。

表4 实验算法在不同数据集上的AUC值

表5 实验算法在不同数据集上的平均F1值
数据集的内部分布也是影响分类性能的因素,因此,为了进一步研究数据块大小对概念漂移检测和非平衡数据处理的影响,选用Horse、Germany、BreastCancer、Tic和votes这5个数据集作为实验数据,ISDC算法选用不同Winsize大小,以Recall做为评价指标,最终获得的实验结果如表6和图2所示。
由表6的数据和图2中曲线的基本变化趋势分析可得,随着数据块大小的增长,ISDC算法在绝大多数数据集下的Recall 值呈现先上升再下降的趋势。当取值较小时,随着窗口的增大,分类器获得更多的训练数据,使得数据块有可能获得较多的少数类,使得不平衡率降低,分类模型受非平衡问题的影响也会相应变小,提升了准确率,分类效果变好。针对不同的数据集结构,所能达到效果最佳的窗口大小并不相同。当数据块大小达到一定值后,再增加其大小会使得数据块内的数据包含不止一个概念,并且数据块太大也会导致算法对数据流中概念变化的敏感性下降,也有过拟合的风险,因此分类模型不再符合测试数据,导致分类性能逐步降低。

表6 ISDC算法在不同Winsize取值下的Recall值

图2 不同Winsize下的ISDC算法的Recall值
图2中针对不同的数据块大小,数据集的分类效果有一定的波动,每个数据集产生波动的数据块大小不尽相同,说明大小不同的数据集的分类结果最优的数据块大小也不相同,内部分布不同的数据集也会产生或提高或降低的波动。因此对于不同的数据集,要使得算法分类效果最佳,就要采用不同的数据块大小。
根据本文算法原理可知,子分类器个数k的值越大,训练次数越多,造成的时间消耗也就越大。为了验证这一想法,在不同的k值下选用几个数据集进行实验,如表7所示。
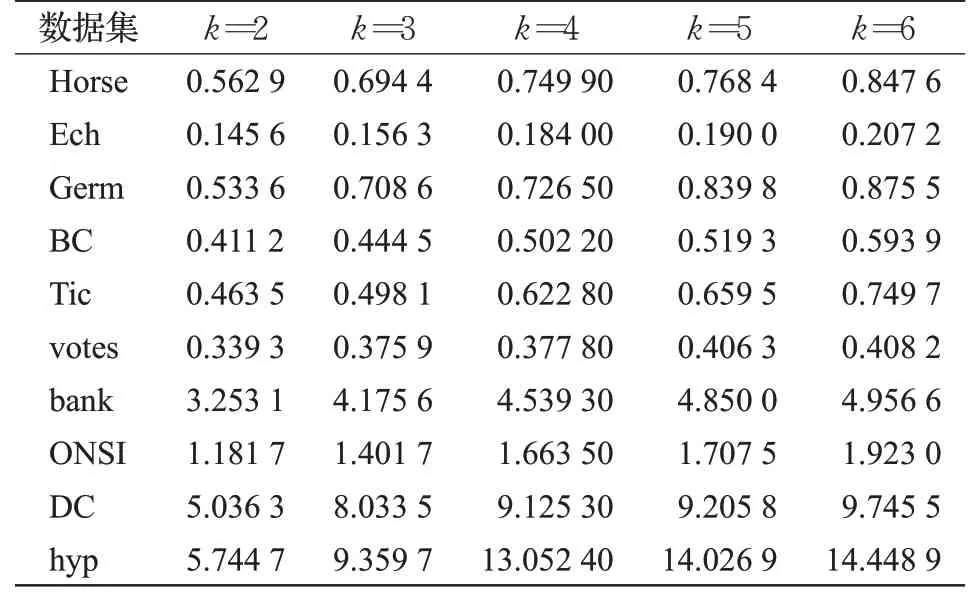
表7 不同k 值下ISDC的时间花销 s
由表7可以很明确的看出,算法的时间复杂度与分类器的个数k有直接的关系,k的取值决定了数据的训练次数,k较大时,分类模型在训练分类器以及处理各个子分类器的结果上花的时间就要更多。
4 结语
本文提出了一种基于Kappa 系数的概念漂移检测和针对类不平衡的SMOTE采样方法相结合的动态数据流分类算法ISDC,在该算法中使用了Kappa 系数检测数据是否发生概念漂移,发生概念漂移后,再检测数据是否平衡,如果数据不平衡,ISDC算法所采用的措施能够保证算法以很快的速度适应概念漂移和不平衡。实验结果表明,该算法在Recall值、AUC值和F1值上取得了较好的效果,说明了ISDC 算法的有效性。然而该算法也存在一定的不足之处,对数据集内部分布对分类结果的研究不是很充分。因此,之后将对边界数据、安全数据、噪声等分布的数据的分类效果做进一步的研究,并且从研究二分类问题转向多分类问题,提高算法的实际可行性。
