基于演化博弈的最优防御策略选取研究
2021-07-14巩俊辉胡晓辉杜永文
巩俊辉,胡晓辉,杜永文
兰州交通大学 电子与信息工程学院,兰州730070
无线传感器网络(Wireless Sensor Network,WSN)是由大量传感器节点通过自组织方式形成的一个多跳无线通信网络,在环境、工业、军事和家居等领域应用广泛,人们可以通过它感知真实物理世界中的各类信息,极大提高了人类认识客观世界的能力[1]。传感器节点有限的资源、开放的无线通信方式以及复杂的工作环境使得无线传感器网络极易面临各种安全威胁,入侵检测系统(Intrusion Detection System,IDS)能够有效发现网络中不安全的行为[2],但它需要较多的资源开销。如何在资源受限的WSN中真正有效地使用IDS是一个非常具有挑战性的任务[3-4]。
博弈论(Game Theory)作为研究竞争现象的数学理论,被许多学者应用于无线传感器网络入侵检测的研究[5-7]。相较于误用检测、异常检测等方法,基于博弈论的检测方法没有训练过程而且不需要额外的数据来建立模型,其复杂度较低,能帮助WSN更加合理有效地应用IDS[8-10]。陈行等人[11]在无线网络入侵检测参数调整问题的研究中引入贝叶斯博弈理论,构建入侵检测博弈模型并设计了入侵检测算法,算法能有效检测发生变化的恶意攻击行为。李奕男等人[12]对Ad Hoc网络的入侵检测问题建立非合作完全信息静态博弈模型,该模型的纳什均衡策略在降低误检率的同时提高了检测率,并且减少了网络能耗。Shen 等人[13]应用信号博弈描述并分析恶意传感器节点和无线传感器网络入侵检测系统之间的交互过程,建立重复的多阶段信号博弈模型,实现了入侵检测最优策略的机制。Huang等人[14]在误用检测和异常检测的基础上提出马尔科夫IDS算法,利用非完全信息静态博弈推断最优防御策略。周伟伟等人[15]利用贝叶斯方法根据外部节点的先验概率推断其在后续时刻为恶意节点的后验概率,并在提出的多阶段动态入侵检测博弈模型上给出最佳策略。Han等人[16]针对无线传感器网络攻击手段多样性问题以及资源受限的困境,利用非合作博弈思想得到混合纳什均衡防御策略,平衡了系统的检测效率和资源开销。
但是传统博弈模型存在不足,它们采用完全理性假设,通过一次博弈就能找到最优策略且较少考虑最优策略的稳定性。这在现实网络对抗中是不合理的,会导致模型与实际出现偏差,降低了研究的指导意义。相比于传统博弈理论,演化博弈的假设与分析更加合理和准确,与无线传感器网络入侵检测实际情况更加契合。因此,本文基于有限理性假设,针对不同的攻击方式,引入演化博弈构建入侵检测攻防博弈模型,利用复制动态方程分析多种攻击方式下攻防双方策略的演化趋势,实现最优防御策略选取算法,解决检测率和能耗均衡问题。
1 演化博弈
演化博弈理论(Evolutionary Game Theory)[17]起源于达尔文的生物进化思想,摒弃了经典博弈理论中完全理性的假设,将参与者视为群体中有限理性的个体,是一种将博弈理论与动态演化过程相结合的理论。
在演化博弈中,有限理性的参与者通过不断试错、学习来修正现有策略,经过一个动态重复的长期博弈过程才能找到合适的策略。演化博弈理论分析的重点是在博弈过程中博弈参与者策略的调整过程、演化趋势和稳定性。
随着时间变化,所有的参与者最终可能会趋向于选择某个稳定策略不再改变,系统达到稳定状态。对此,演化博弈中一个重要的概念是演化稳定策略(Evolutionary Stability Strategy,ESS),它用于分析有限理性下博弈是否存在稳定均衡。关于演化稳定策略的定义如下。
演化稳定策略假设有限理性参与者的策略空间为S,任何策略y≠x∈S,u(x,x)为参与者采取策略x时的收益。如果存在某个,使得不等式u[x,εy+(1-ε)x]>u[y,εy+(1-ε)x] 对于所有都成立,那么策略x是一个演化稳定策略。
从演化稳定策略定义可看出,如果群体一开始采取的演化稳定策略x,则大群体中的参与者的策略收益总是大于突变小群体中参与者的策略收益,也就是说此时群体可以抵挡突变小群体的策略入侵;如果群体一开始采取的策略是y策略,则大群体中的参与者的策略收益总是小于突变小群体中参与者的策略收益,即y策略的收益总是小于演化稳定策略x的收益,因此该群体会被演化稳定策略x成功入侵,使得群体成员最终都采用演化稳定策略。
2 网络模型
假设无线传感器网络采用分簇路由协议将网络划分为多个相互连接的簇状结构,每个簇中都有一个簇头节点(Cluster Header,CH)和若干成员节点,簇头节点定期被选举产生的,它和簇内成员节点没有本质上的差异。假设在无线传感器网络中分布着N个节点,分簇路由协议将网络划分为k个簇,分别记为C1,C2,…,Ck,每个簇中包含的成员节点数目为Mi(i=1,2,…,r),网络中的恶意传感器节点对其所属簇头发起攻击。如图1给出了本文的网络模型。
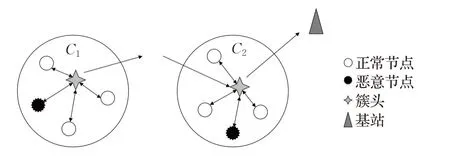
图1 无线传感器网络入侵检测网络模型
无线传感器网络中节点的能量十分有限,每个节点都运行入侵检测系统势必会增大节点的能耗,减少节点的工作时间,因此本文使用分布-集中混合式入侵检测系统来均衡能量消耗和检测性能[18]。分布-集中混合模式是指网络中的每个传感器节点都已安装了入侵检测系统,但并不是所有节点都运行入侵检测系统,为了节省能量消耗,只开启位于簇头上的入侵检测系统以识别簇内恶意传感器节点的攻击行为。当一个传感器节点被选作簇头时,它的入侵检测系统将同时被唤醒,而簇内成员节点上的入侵检测系统将会被停用。因此,本文中簇头节点在周期内额外承担入侵检测的功能,且簇头的IDS根据基站的指令开启指定模块。
3 博弈模型
现实的网络安全形势日益复杂,攻击手段各式各样,可以按照检测方法将其分为常见攻击和新型攻击两类[16]。误用检测方法可以检测出攻击特征已知的常见攻击,却不能有效检测出未知特征的新型攻击,此时需要使用异常检测方法来判断入侵行为是否存在。因此,本文的入侵检测系统主要有误用检测和异常检测两个检测模块,需要制定一种用以指导入侵检测系统的策略,使之在合适的时间启动合适的检测模块。
先前的研究工作通常假设恶意传感器节点和簇头节点是完全理性的,且仅攻击网络一次,这不符合实际情境。因此,假设节点是有限理性的,网络进行多次攻防对抗并且攻击手段多种多样。恶意传感器节点对所在的簇头进行常用攻击或者新型攻击,每次攻击都会选择某一种特定攻击手段,簇头需要决定开启误用检测模块还是异常检测模块。
根据演化博弈理论,构建入侵检测攻防博弈模型ADEGM=(N,S,P,U)(attack and defense evolutionary game model)。
(1)N=(NA,ND)为入侵检测演化博弈的参与者集合,其中,NA为恶意节点(攻击者),ND为簇头节点(防御者)。
(2)S=(AS,DS)是参与者策略空间,其中AS={AS1,AS2}为攻击者的可选策略集,AS1表示进行常用攻击,AS2表示进行新型攻击;DS={DS1,DS2}表示防御者的可选策略集,DS1表示启用误用检测模块,DS2表示启用异常检测模块。
(3)P=(PA,PD)是演化博弈的攻防策略的概率集合,其中,PA={p,1-p},p是选择常用攻击的概率,则1-p是选择新型攻击的概率;PD={q,1-q},q是启用误用检测的概率,则1-q是启用异常检测的概率。
(4)U=(UA,UD)是攻防双方收益函数的集合,UA表示攻击者的收益,UD表示防御者的收益,当攻击者和防御者采取ASi和DSj时,分别表示他们的收益。
利用表1 中定义的符号可以表示攻击者和防御者的收益。

表1 符号定义
误用检测模块检测常见攻击的准确率为α,而它却无法检测出新型攻击;异常检测模块检测新型攻击的准确率为β,同样它也无法检测出常用攻击。基于以上分析,可以计算出不同策略下攻击者和防御者的收益,如表2所示。

表2 收益矩阵
4 模型分析
4.1 演化均衡求解
攻击者和防御者的知识水平不同,各自的策略不同,策略的差异会导致收益不同,在利益差异的驱动下,收益低者会向收益高者学习来改进自己的策略[19],这导致不同策略的比例随时间推移而发生变化。策略变化可以表示为一个与时间相关的函数,其动态变化速率可用复制动态方程表示。
复制动态方程是应用最为广泛的选择机制方程[20],借鉴了自然界生物演变思想,适用于学习速度较慢的群体。它描述了策略的动态变化过程,被普遍用来分析演化博弈的均衡状态。
求解攻防演化博弈模型均衡的算法描述如下:
(1)给定估计概率p、q。
(2)建立攻击者复制动态方程。
根据PA、PD及收益矩阵得到攻击者不同攻击策略的收益以及期望收益:

进而建立攻击者的复制动态方程为:

(3)建立防御者复制动态方程。
根据PA、PD及收益矩阵得到防御者不同防御策略的收益以及期望收益:

进而建立防御者的复制动态方程为:

(4)演化稳定均衡求解。
联立上述步骤(2)和步骤(3)得到的攻防复制动态方程,建立如下演化复制动态方程组:

通过求解方程组可以求出博弈模型的均衡为:

其中Y1=[0,0]T表示攻击者进行常用攻击,防御者使用误用检测;Y2=[0,1]T表示攻击者进行常用攻击,防御者使用异常检测;Y3=[1,0]T表示攻击者进行新型攻击,防御者使用误用检测;Y4=[1,1]T表示攻击者进行新型攻击,防御者使用异常检测。表示攻击者和防守者以混合策略选取常用攻击和误用检测。
4.2 演化稳定分析
针对利用复制动态方程对网络攻防演化博弈模型求解得到的演化均衡,采用系统动力学方法[21]分析其是否为演化稳定策略。由公式(3)可知,攻击者的策略变化有3种情况,如图2~4所示;由公式(6)可知,防御者的策略变化有3种情况,如图5~7所示。

图2 当时,攻击者的复制动态相位图

图3 当时,攻击者的复制动态相位图

图4 当时,攻击者的复制动态相位图

图5 当时,防御者的复制动态相位图
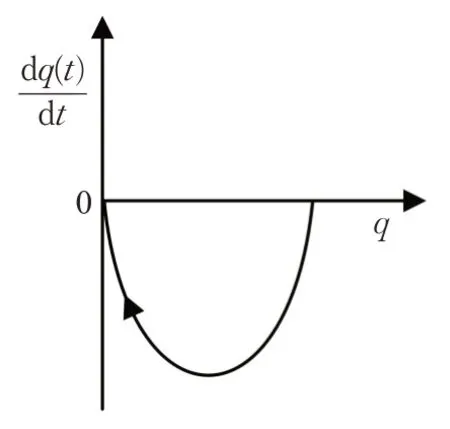
图6 当时,防御者的复制动态相位图

图7 当时,防御者的复制动态相位图
当攻防双方的策略不固定时,它们的策略变化如图8所示。当初始策略在区域A 时,系统不会趋于稳定状态Y4,而是会演化到区域D;当初始策略在区域B 时,系统不会趋于稳定状态Y3,而是会演化到区域A;当初始策略在区域C 时,系统不会趋于稳定状态Y1,而是会演化到区域B;当初始策略在区域D 时,系统不会趋于稳定状态Y2,而是会演化到区域C。

图8 复制动态变化
综合分析,当攻防双方的策略变化时,系统不存在稳定状态。防御者只能根据攻击者的策略动态改变策略,这样才能更有效地检测入侵行为。
4.3 最优防御策略选取算法
根据攻防博弈模型及演化均衡分析,在攻防双方的策略不固定的基础上,设计了入侵检测系统最优防御策略选取算法。其基本思想是根据建立的攻防复制动态方程,防御者根据攻击者的策略动态选取防御策略,算法描述如下所示。


5 仿真实验
仿真实验使用Python 编程语言对无线传感器网络的恶意传感器节点攻击行为进行仿真模拟,在监测区域内随机部署100个传感器节点,传感器节点一旦部署成功就不可移动并且它们的能量不可恢复,而基站位于监测区域外部,其能量可恢复。无线传感器网络使用LEACH[22]分簇协议对网络拓扑结构进行划分,设定节点被选举为簇头的概率为0.1,那么网络中将会存在大约10 个簇头,网络中有3 个恶意传感器节点,它们对所属的簇头发起攻击。仿真参数如表3所示。

表3 网络参数
如图9是网络未分簇时的网络拓扑图,如图10是网络采用LEACH分簇协议后的网络结构。

图9 网络未分簇结构

图10 网络分簇结构
攻防博弈的参数设置为Ca1=0.1,Ca2=0.15,Cd1=0.1,Cd2=0.2,Ba1=0.4,Ba2=0.6,α=0.9,β=0.9。求解得到Y5=[0.488,0.433]T。图11和图12分别是攻击者和防御者的复制动态方程三维图示,其中平面为X=0.488 以及Y=0.433。

图11 攻击者的复制动态方程

图12 防御者的复制动态方程
当恶意节点总是使用同一攻击策略,簇头节点经过学习和模仿,不断调整策略,最终达到稳定状态。如图13 和图14 表示,当p=1 时,即恶意节点总是使用常用攻击,经过演化,最终簇头节点会一直启用误用检测模块;当p=0 时,即恶意节点使用新型攻击,最终簇头节点会一直启用异常检测模块。
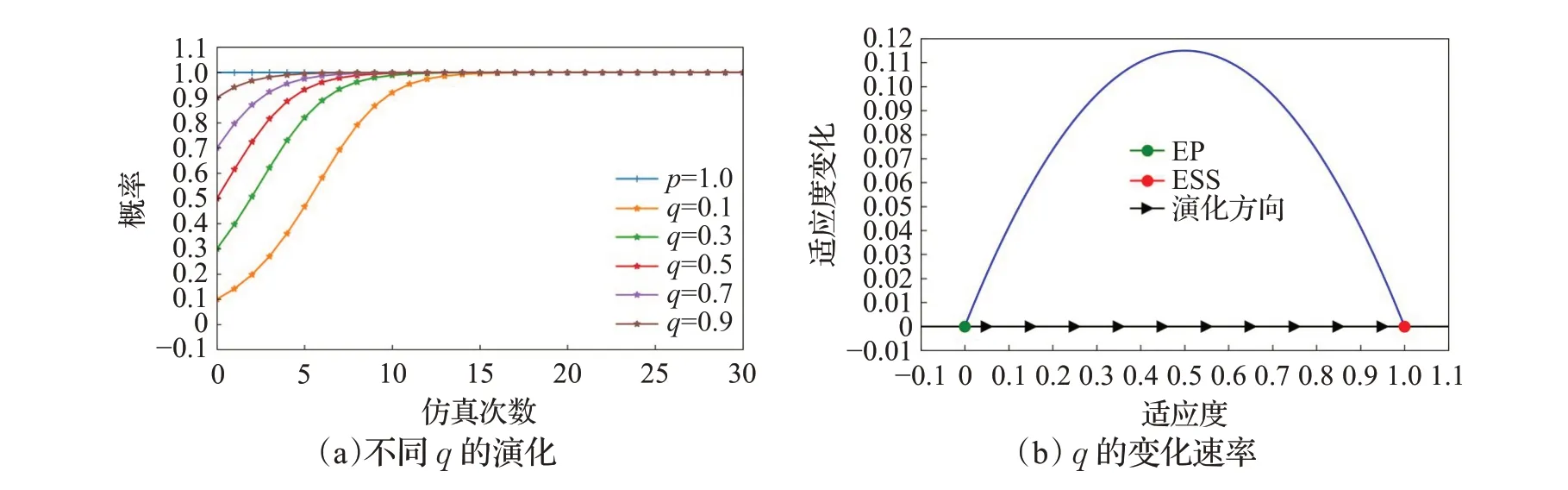
图13 p=1 时q 的演化
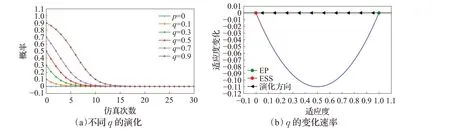
图14 p=0 时q 的演化
当簇头节点总是使用同一防御策略,恶意节点经过学习和模仿,不断调整策略,最终达到稳定状态。如图15 和图16 所示,当q=1 时,即簇头节点总是启用误用检测模块,经过演化,最终恶意节点会一直使用新型攻击;当q=0 时,即簇头节点启用异常检测模块,最终恶意节点会一直使用常用攻击。
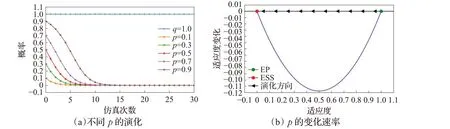
图15 q=1 时p 的演化

图16 q=0 时p 的演化
如图17 所示,当初始攻防策略为混合策略Y5=[0.488,0.433]T时,随着演化推进,双方策略保持不变。而当初始状态偏离平衡节点后,短期内双方会靠近演化稳定策略解,却无法稳定,随着博弈次数增加,策略选择呈现周期性的波动,如图18所示。
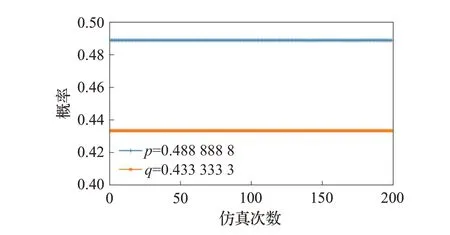
图17 初始状态为Y5 的变化

图18 初始状态偏离Y5 变化
如图19是当恶意节点和簇头节点的策略不固定时,不同初始状态下它们的策略变化。当它们的初始策略在A 区域、B 区域、C 区域和D 区域时,系统最终不会趋于稳定状态,而是随着时间变化呈现周期性的波动。
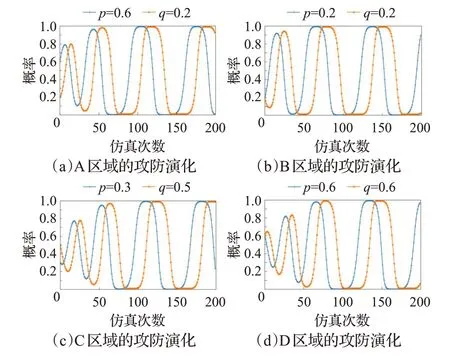
图19 各区域的攻防演化
将基于演化博弈的最优防御策略算法(EGT 防御算法)与固定防御、全面防御、随机防御以及流量预测等入侵检测算法进行对比。固定防御算法采用固定的防御策略进行入侵检测;全面防御算法同时运行误用检测和异常检测模块;随机防御算法在簇头节点上随机启用误用检测或异常检测模块;流量预测算法在簇内流量最大的簇头节点上同时开启误用检测和异常检测模块。
如图20 为各个入侵检测算法的入侵检测率对比。从图中可以看出,使用全面防御算法的入侵检测准确率维持在90%左右,这是由于它同时启动两个模块,能够检测出所有的攻击类型,因而它的准确率最高。固定防御策略的检测率只有40%左右,这是因为攻击者会根据防御者的固定策略有针对性地调整攻击方式,使检测率降至最低。随机防御策略随机启用一个检测模块,在检测模块准确率都为90%的前提下,它的检测率在45%左右。流量预测算法的入侵检测率不稳定,平均值大约为23%,这主要是因为攻击与网络中流量的大小无关。基于演化博弈的防御策略有较高的检测率,在52%左右。它每次只启用一个检测模块,因此检测率低于全面防御策略;相比于固定防御和随机防御,它会根据攻击者的攻击策略相应地动态调整防御策略,防止攻击者的针对性攻击,因而检测率较高。如图21 和图22 是随着时间推移未启用防御、启用全面防御、随机防御以及演化防御后,网络节点平均剩余能量以及生存节点数量的变化。未启用防御时由于没有额外的能量消耗,网络生存时间最长。启动全面防御时需要同时开启两个模块,导致簇头节点能量消耗急剧加大,使网络的生存时间减少。而基于演化博弈的防御策略每次只开启一个检测模块,与全面防御策略相比,它减少了簇头节点的资源开销,使节点能量消耗降低,有效延长了整个网络的生存时间;演化防御和随机防御在网络攻防过程中开启入侵检测和误用检测模块次数相近,这令它们的能量消耗相差无几,从而使得网络节点平均能量和生存数量曲线相似。

图20 不同算法的入侵检测率

图21 节点平均能量

图22 生存节点数量
因此,基于演化博弈的防御策略在保证检测率的前提下,有效延长了网络的生存时间,平衡了入侵检测系统的准确性与能效性。
6 结束语
本文从入侵检测过程中攻防双方的有限理性出发,应用演化博弈理论描述并分析恶意传感器节点和入侵检测系统之间的交互过程,针对攻击方式的不同,构建攻防演化博弈模型。利用复制动态方程分析了多种攻击方式下攻防双方策略的演化趋势,实现了最优防御策略选取算法。根据演化规律,防守者主动动态地调整防御策略来实现最有效的防御,减少了资源消耗,平衡了系统的能效性和准确性,不仅延长了节点的使用寿命还保证了整个网络能够长久安全的运行。基于有限理性的入侵检测攻防演化博弈模型,与实际无线传感器网络攻防情况相符合,仿真实验说明了该演化模型的合理性和算法的有效性,对于无线传感器网络的入侵检测系统的应用具有重要意义。
但是演化博弈模型的学习速率由基础复制动态方程给出,这和真实的无线传感器网络攻防场景存在一定的差异,实际的攻防策略变化过程复杂,不易量化。建立更加符合实际情况的改进复制动态方程,将是后续研究的一个新挑战。
