结合概率图模型与DNN的DDoS攻击检测方法
2021-07-14王文涛李树梅吕伟龙
王文涛,李树梅,汤 婕,吕伟龙
1.中南民族大学 计算机科学学院,武汉430074
2.湖北省制造企业智能管理工程技术研究中心,武汉430074
3.南京理工大学 计算机科学与工程学院,南京210094
在物联网发展过程中,尽管网络的存储和虚拟化技术得到了长足的进步,但由于物联网的异构性导致物联网难以管理。同时,安全性极低的物联网设备容易被黑客控制,构成庞大的僵尸网络,易于向云环境等物联网平台发起布式拒绝服务(Distributed Denial of Service,DDoS)攻击[1]。从传统网络到物联网,DDoS 攻击的种类繁多,其中最常见的一种是SYN洪范攻击[2]。SYN洪范攻击发生在TCP/IP 协议的三次握手阶段,攻击者向攻击目标发送SYN 请求,服务器为此次连接分配特定的网络资源并向请求者回应相应的ACK 确认;但由于攻击者并没有想要获取真正的服务,会对服务器的ACK 确认置之不理;服务器在等待一段时间后仍未收到攻击者的确认消息,才会释放掉之前分配给攻击者的资源。因此,攻击者以耗尽服务器资源为目的向攻击目标持续发送SYN 请求,导致服务器无法为合法用户提供正常服务。
DDoS检测是DDoS防御工作的重要环节。因为大多数情况下,攻击者伪装成正常用户向网络发送数据,导致一般检测系统难以检测出DDoS 流量。与其他攻击方式不同的是DDoS 流量和正常流量非常相似,通常,检测系统将闪拥事件和DDoS 攻击事件混为一谈[3]。在早期攻击流量不足的情况下,检测系统甚至将攻击流量视为合法行为,允许他们访问目标网络,随着攻击流量强度的增加,目标系统的任务负载越来越重,导致系统网络资源耗尽。攻击者也会采用IP欺骗的方式,将随机源IP地址分配到伪造的网络数据包中,以避免检测系统的源IP追溯。研究者尝试很多种方式来检测DDoS攻击,这些方法可以分为基于统计分析的检测方法[4-5]、基于熵值的检测方法[6-7]和基于机器学习的检测方法[8-10]。
统计分析的检测方法是将传入网络的报文与无攻击期间收集到的数据进行对比,如果发现异常,则会触发警报;基于熵值的检测方法中,研究者为了衡量系统中源IP 地址和目的IP 地址分布的不确定性,把信息论中的“熵”概念引入到DDoS攻击检测工作之中;机器学习的检测方法将网络入侵检测的问题转换为对网络数据分类的问题,通过使用机器学习算法的分类器把网络流量分成攻击流量和正常流量。随着网络数据的指数型增长,由于统计分析和熵值的检测方法需要大量的实验来获取准确的先验知识,因而不能够自适应地检测出DDoS 流量。然而,机器学习的方法可以通过数据挖掘的方式剖析网数据,同时根据网络环境的变化调整算法自身参数。因此,基于机器学习的方法越来越受研究者的青睐[11]。
传统的机器学习的方法对输入特征的依赖性过高,分类结果的优劣取决于选择的特征,而且在网络数据量过多的情况下,机器学习算法容易呈现不稳定状态。深度学习算法虽然适用于大量数据的情况,但是由于算法自身复杂度过高而对设备资源的占用率较大。为了在占用有限资源的情况下提高检测DDoS流量的准确率,提出概率图模型与DNN 算法的DDoS 检测方案。此方案汲取了机器学习和深度学习算法的优点,并且最终提高了DDoS 流量检测准确率,降低了误报率和漏警率。本文创新点如下:
(1)分析DDoS 攻击流量,从网络流量中提取与DDoS攻击相关的统计特征。使用随机森林算法对特征重要性排序,挖掘检测DDoS流量的重要特征。
(2)创新性的提出HMM-DNN 的DDoS 检测方案。该方案包含数据处理模块和攻击检测模块。在数据处理模块中使用HMM 算法过滤掉网络中异常的数据,DNN算法对进入检测模块中的流量进行攻击检测。经过测试和训练该方案提高了检测准确率、降低了检测漏爆率。
(3)使用入侵检测评估数据集CICDoS 验证所提方案的有效性。实验结果表明,HMM-DNN检测方法可以较好地检测出不同攻击比例下的DDoS攻击流量。
1 相关工作
软件定义网络(Software Defined Networking,SDN)作为新型的网络架构,解耦了网络的控制平面与数据平面;其中控制平面具有网络的全局视图,控制平面中的逻辑集中控制器可以通过软件的形式直接管理网络;数据平面具有数据转发的功能,数据平面的交换机会根据控制平面的决策将数据进行转发。虽然SDN网络并不是专门为解决网络安全问题而创建的,但SDN 网络架构及OpenFlow协议为识别和防御网络攻击提供了更多的可能性[12]。文献[13],为了保护物联网设备将SDN网络部署在物联网网关之中以防御DDoS 攻击。它使用自组织映射算法检测出DDoS 攻击源后通过POX 控制器操纵流规则,阻止流规则发送到OpenFlow 交换机。该方法能有效地检测出物联网网关中存在的DDoS 攻击,即使对它进行了防御。
文献[14-16]研究了云环境下DDoS 攻击。他们认为攻击者能够在云环境中轻而易举发起攻击是因为僵尸网络的爆发、网络的广泛接入和资源池的使用[14]。Phan等人[15]为解决云计算中DDoS攻击,提出结合机器学习和IP过滤的检测方法。他们使用支持向量机和自组织映射算法的新型混合的机器学习方法以提高网络流量的分类。陈兴蜀等人[16]研究了云环境中LDDoS攻击,针对云环境中的周期性LDDoS攻击和非周期性LDDoS 攻击从通讯和频率方面提取出5 个方面的十维特征,同时提出基于贝叶斯网络的LDDoS 攻击检测方法。虽然该方案能够有效地检测出云环境中的LDDoS攻击,但是云环境中有多种不同类型的DDoS 攻击,它不能保证对其他类型的DDoS攻击同样有效。
机器学习的方法有利于更加智能的对网络流量进行分类,因此文献[17]提出网络双向流量特征的前提下,设计了增长型分层自组织映射检测算法识别攻击流量。由于在正常情况下网络请求和应答是双向的而在攻击产生时,攻击者的会频繁发起网络请求,从而导致在网络流量中请求数据包的比例远高于应答数据包。当对网络流量只进行一次检测时容易产生检测准确率低、误报率高和漏报率高的问题,因此目前越来越多的研究者把熵检测方法、统计分析检测方法和机器学习的检测方法结合在一起以提高网络流量的分类精度[18-26]。
文献[18-20],结合熵值检测方法和机器学习的方法检测对网络流量进行两次检测。他们计算源IP地址、目的IP地址的熵值对网络流量做出初步判断,对其结果使用C4.5决策树、DNN和PSO-BP神经网络进一步的对网络流量分类。与其不同的是文献[21]虽然同样也提出基于条件熵和增长型自组织映射算法的检测方法,但从网络流量中提取了源IP地址、目的IP地址、源端口和目的端口网络数据报四元组并计算出他们的条件熵,将四元组条件熵作为GHSOM 算法的输入特征检测网络流量。文献[22]提出两种机器学习算法混合的KNN-SVM检测模型。由于传统机器学习算法对输入特征的依赖性过高,因此文献[23]提出DCNN 和DSAE 两种深度学习算法混合的检测模型。然而,在通过机器学习算法检测DDoS攻击时,检测模型会根据输入特征自适应的学习网络的输入特征,研究者们认为使用机器学习的方法进行攻击检测时可以只考虑对网络流量分类有用的特征,因此文献[25-26]首先将从网络流量中提取的特征进行重要性排序,然后使用关键的特征作为检测算法的输入从而检测网络中存在的攻击。
结合以上研究,本文提出的基于概率图模型和DNN 的检测方法,首先使用随机森林的算法对提取的网络统计特征计算重要性,然后将HMM-DNN 检测算法用于检测DDoS 流量。该方案在一定程度上能够提高系统中DDoS 攻击的检测率同时也降低了误报率和漏报率,有效地避免系统遭受DDoS攻击。
2 特征提取
不同的DDoS攻击的数据包呈现不一样的特点,因此从DDoS攻击种类的角度,提取出22个数据包级别的统计特征,表1中列出所有统计特征及其特征描述。

表1 网络数据包统计特征
攻击者在发起DDoS 攻击时会篡改TCP 数据包的包头信息。例如,在TCP 连接三次握手过程中出现的SYN 洪范攻击和ACK 洪范攻击;四次挥手阶段的FIN洪范攻击。攻击者在这类攻击中,改写TCP数据包头部的标志位信息形成用于攻击的恶意数据包。因此本文根据TCP 数据包标志位的变化,分别统计了syn、ack、psh、urg、fin、rst标志位出现的数据包平均个数:
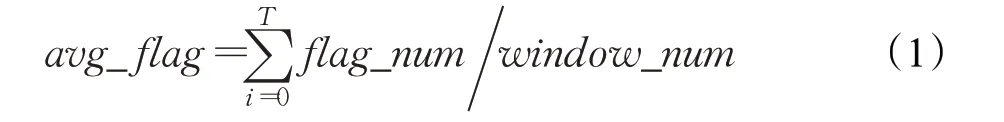
其中,avg_flag指的是TCP数据包六个标志位其中一个的平均个数。T代表一个采集周期的时长,flag_num代表某个标志位出现的个数,window_num是采集窗口的个数。攻击者根据不同的协议类型发起不同种类的DDoS 攻击。本文针对常见的TCP 洪范和UDP 洪范攻击,统计了系统中TCP 数据包和UDP 数据包的平均个数:

攻击者为了消耗目标系统资源往往在较短的时间内发起大量的数据包,导致数据包之间的时间间隔通常会比较短。因此,本文统计了一条流的持续时长:

同样,在持续时间方面,计算了平均时长,最长时长,最短时长以及时长的标准差。其中,packetlisti.time表示数据包流中第i个数据包的到达时间。攻击者并没有想真正访问攻击目标,所以攻击包所携带的数据负载较小并且数据包长度一般较短。因此也统计了数据包负载和长度的平均数、最大值、最小值、标准差。
3 基于概率图模型与深度神经网络的DDoS攻击检测
3.1 DDoS攻击检测模型总体架构
DDoS攻击检测模型总框架如图1所示。本文提出的基于概率图模型和深度神经网络结合的DDoS 攻击检测模型由数据预处理和攻击检测两部分组成。数据流在访问服务器之前首先要经过检测模块,检测模块对异常的数据流进行过滤,同时将正常的数据流发送至目的地址。在检测模块中,预处理阶段先将网络数据包解析,提取22个统计特征信息,再经概率图模型的隐马尔科夫算法进行聚类。聚类结果分成攻击与正常两类,其中攻击数据包的源IP地址存储到攻击源名单中,正常数据包被发送至攻击检测模块中的DNN检测模型当中。

图1 DDoS攻击检测模型总框架
3.2 隐马尔科夫模型
隐马尔科夫模型(Hidden Markov Model,HMM)是对随机变量的时间序列,即随机过程的研究。它是对隐藏的马尔科夫链的扩展,通过不可见的马尔科夫链生成可观测的观测状态随机序列。它对随机过程做了两点假设,即任意时刻的隐状态只依赖于前一时刻的状态,与其他因素无关和任意时刻的观测状态只依赖于此刻的隐状态。HMM模型如图2所示。此模型可由五元组λ=(S,O,A,B,π)表示。其中,S表示隐状态序列S=(s1,s2,…si,…,st),隐状态中的任何一个si取值于包含所有可能的隐状态空间Q={q1,q2,…,qn};O表示观测状态序列O=(o1,o2,…,oi,…,ot),其值取自于包含所有可能的观测空间V={v1,v2,…,vM};A表示隐状态转移概率矩阵;B表示观测状态概率矩阵;π表示初始状态概率向量。

图2 HMM模型


如上述公式所示,隐状态转移概率矩阵A表示在时刻t处于隐状态qi的条件下在时刻t+1 转移到隐状态qj的概率。观测状态概率矩阵B表示在时刻t处于隐状态qj的条件下生成观测状态ok的概率。初始状态概率向量表示时刻t=1 时处于隐状态qi的概率。
在实际的攻击检测问题中,通过隐马尔科夫算法的预测问题将网络流量聚类成攻击与正常两类,即由描述网络流量的随机变量X作为观测状态,通过求解预测问题,聚类结果作为隐状态序列输出(如图2)。本文先用Baum-Welch 算法训练模型,再用维特比算法对网络流量聚类。
3.3 深度神经网络模型的检测
深度神经网络(Deep Neural Network,DNN)可以自学习多维特征,从不同维度提取特征中隐含的信息,根据特征之间的相关性等特点对所输入的数据进行分类。DNN网络中,输入是由一组向量X=[x1,x2,…,xi]T组成,每一层都包含了权重向量W和偏移矢量B,计算每层的输出Al:

其中,bl、wl分别是第l层的偏置向量和权重矩阵。为了缓解梯度消失问题选用ReLU非线性激活函数。对输出层使用softmax函数并计算交叉熵得出输出的误差向量:

训练时,利用后向传播算法计算隐含层神经元误差值:

使用Adam优化算法计算并保存权重更新值:

其中,yi表示第i个数据包的真实标签,表示第个i数据包的预测结果;分别是输出层两个神经元的损失量;表示第l层第i个神经元的损失量;β1、β2表示梯度衰减速率;α为步长。如图3 为DNN 网络的结构图。

图3 DNN网络结构
4 实验结果分析
4.1 实验环境及评估指标
本文实验是基于python3.5.4 完成的,使用Intel®Cor™i3-8100 CPU @ 3.60 GHz四核的处理器,Nvidia GeForce GTX 1060 3 GB 的显卡计算机,操作系统是Ubuntu16.04版本。
本文实验采用的是CICDoS 数据集[27]。从CICDoS数据集中提取20万个攻击包和100万个正常数据包,并且将攻击包与正常数据包按照0.2、0.4、0.6、0.8、1.0的比例混合,得到最终用于实验的DDoS攻击数据集。计算准确率(Acc)、误警率(FA)、漏警率(MA)和检测时间作为检测模型性能的评价指标。其中,TP(True Positive)表示将攻击流量预测为攻击流量的样本数;TN(True Negative)为将正常流量预测为正常流量的样本数;FP(False Positive)为将正常流量预测为攻击流量的样本数;FN(False Negative)为将攻击流量预测为正常流量的样本数。
准确率表示模型判断正确的数据数量占总数据的比,即:
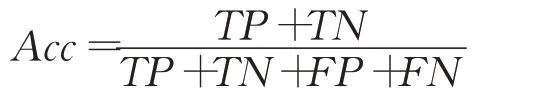
误警率表示正常流量被模型判断为攻击流量的数量占样本中被检测为攻击流量的比,即:

漏警率表示攻击流量被模型判断为正常流量的结果占样本实际攻击流量数据的比,即:

4.2 实验分析
本节包含特征可行性对比实验和模型性能对比实验。在特征可行性对比实验中,首先分析了统计特征的分布规律,由于数据集中有较强的噪音,从特征分布无法精确地获得数据规律,因此使用随机森林算法对22个特征进行重要性排序。然后将本文提取的统计特征与网络数据包四元组Renyi熵特征进行对比分析。在模型性能对比实验中,加入经典的支持向量机[28]算法和K近邻[29]算法与本文的概率图模型HMM算法进行性能比较分析;最后将HMM-DNN检测模型与最新的DDoS攻击检测模型[19,23,26]进行性能比较分析。
4.2.1 特征可行性对比实验
使用随机森林的算法[30]对提取的26 个特征进行特征重要性排序,发现其中有4 个特征无利于检测流量。用于实验的22个特征重要性排序如图4所示,图中横坐标表示特征类型,纵坐标表示特征重要因子。

图4 特征重要性排序
根据特征排序结果22 个特征中平均syn 数据包个数重要性最强。特征数据负载的协方差的重要性最弱。观测22 个特征的分布发现特征之间有互相补充作用,如图5所示。

图5 特征分布图
图中的脉冲部分代表有攻击产生,虽然从特征的分布较难看出数据的规律,但是图5(a)和图5(b)可以看出0到50秒之间平均syn数据包的个数较少而平均psh数据包的个数较多。这表明,当通过特征平均syn数据包个数检测不到系统中DDoS攻击时平均psh数据包个数能够检测到DDoS流量。
特征个数对检测准确率有一定的影响,特征个数越多检测准确率越高。如图6数据所示,按照特征重要性排序的仅前5个特征的检测准确率可达89%,表明提取特征的准确性较高。
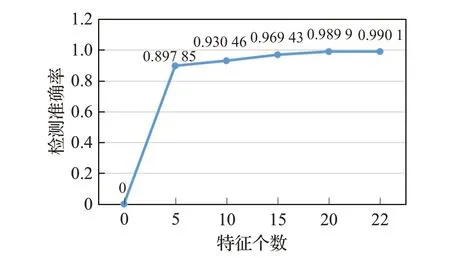
图6 特征个数对检测准确率的影响
22 个统计特征与四元组Renyi 熵特征进行对比发现,本文特征在准确率、误报率和漏警率方面都优于Renyi 熵特征。如图7、图8、图9 所示,展示了两种特征的检测准确率、误报率和漏警率的数据。

图7 四元组熵和22个统计特征在检测准确率的对比

图8 四元组熵和22个统计特征在检测误警率的对比

图9 对比四元组Renyi熵和22个统计特征的检测漏警率
当攻击比例为0.2 时,统计特征的检测准确率达到0.883 9,比Renyi 熵特征提高了0.102 9。当攻击比例为1时,四元组Renyi熵特征检测误报率到达0.145 6,而统计特征得到的误报率值仅仅是0.027 5。当攻击比例为0.2 时,统计特征的误报率为0.001 8,比Renyi 熵特征降低了9.13%。统计特征在攻击比例为0.6时漏警率有最大值0.194 1,相对于Renyi 熵特征降低了29.64%;在攻击比例为0.2 时有最小值0.122 0,相对于Renyi 熵特征降低了68.95%。
4.2.2 模型可行性对比实验
对于HMM-DNN检测模型,使用攻击比例为1.0的数据进行训练。在初始化DNN参数时输入神经元个数为22,隐含层神经元个数为300,输出层神经元个数为2。其余的参数初始化如表2所示。

表2 DNN网络的配置
选择聚类模型时,首先选择四元组Renyi 熵作为聚类模型的输入特征,将经典机器学习算法中的SVM 和KNN 模型与HMM 模型进行对比。表3 是当攻击比例为0.8、0.2 时基于四元组Renyi 熵特征的KNN、SVM、HMM 模型的检测结果。实验结果表明,HMM 模型的准确率高于其他模型,例如在攻击比例为0.8 时HMM的准确率为0.794 0,比SVM 的检测结果高于0.15%。误警率方面,HMM 的表现是最好的,在0.8 时的误警率为0.004 1,这比同等条件下的SVM的检测结果低5.21%,在0.2时HMM的误警率比SVM的误警率低5.54%。但是,在漏警率方面Hmm 模型的表现欠佳,高于KNN、SVM 的检测结果:攻击比例为0.8 时HMM 的漏警率高于SVM 的漏警率14.24%。攻击比例为0.2 时HMM 的漏警率比SVM的漏警率高8.8%。

表3 KNN、SVM、HMM模型的检测结果对比
从以上实验结果可知,当以四元组Renyi 熵作为HMM 模型的输入时,除了漏警率其他3 个指标都优于SVM 和KNN。导致漏警率高的原因有两种:其一是选取的特征不准确,其二是检测模型的性能不佳。因此,最后使用本文提出的22个统计特征作为检测模型的输入,同时在HMM模型聚类结果之后使用轻量级的DNN算法进行进一步分类。
如表4 为将22 个统计特征作为输入时HMM 和DNN 模型与HMM-DNN 检测模的结果。实验数据表明,HMM模型的准确率低,误警率高,漏警率高,虽然,使用单独的DNN 模型也能够改善HMM 存在的缺陷,但是使用HMM-DNN模型的检测效果更佳。

表4 HMM、DNN、HMM-DNN模型的检测结果
如图10给出HMM-DNN算法和HMM、SVM、KNN算法在测试集上的检测时间比较。结果表明,HMMDNN 算法的检测时间小于SVM 和KNN 算法的检测时间,与HMM算法的检测时间相当。

图10 各算法测试集检测时间的比较
将HMM-DNN 算法与最新的DDoS 攻击检测算法对比发现,在不同攻击比例下,本文提出的HMM-DNN模型的Acc 高于XGBoost-DNN 模型,FA 和MA 都低于XGBoost-DNN 模型。如表5、表6、表7 分别显示了XGBoost-DNN 模型与HMM-DNN 模型检测准确率、误报率以及漏警率。

表5 HMM-DNN、XGBoost-DNN模型的检测准确率
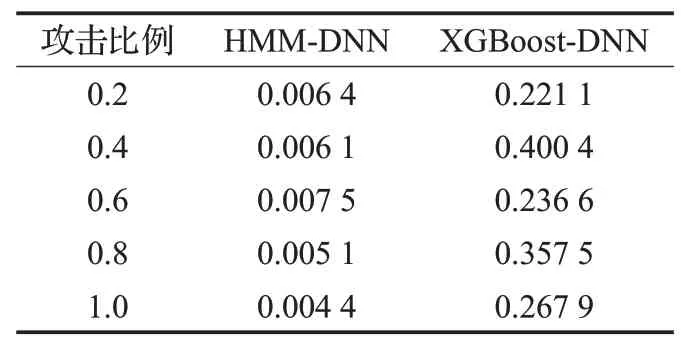
表6 HMM-DNN、XGBoost-DNN模型的检测误报率

表7 HMM-DNN、XGBoost-DNN模型的检测漏警率
由于文献[19]和[23]的数据集中包含的攻击数据包个数和正常数据包个数与本文的攻击比例为0.8时的数据对应。因此,表8 将本文所提方案在攻击比例为0.8时与其他相关研究工作进行了比较。文献[19]和[23]的数据为原文数据。实验数据表明,HMM-DNN算法的在占用最少的检测时间下得到最高的检测准确率。

表8 本文研究与其他文献比较
5 结束语
本文为提高DDoS 攻击的检测率,研究了DDoS 攻击数据包特点,将使用随机森林特征选择算法过滤掉对检测攻击流量无用的特征,最终保留了能鉴别DDoS攻击包与正常数据包的22 个统计特征,并提出概率图模型的隐马尔可科夫算法和深度神经网络的DDoS 攻击检测方案。首先在特征选取过程中,对比分析了数据包四元组Renyi 熵特征与22 个统计特征对检测工作的影响。然后,在检测模型的数据预处理阶段,使用概率图模型的HMM 算法对统计特征进行聚类。最后使用轻量级的DNN 模型对聚类数据进行攻击检测。实验结果表明,该模型能够在较短的时间内以准确率高达99%,误报率达0.51%,漏警率为39%的效果检测出DDoS攻击。
