面向卷积神经网络的硬件加速器设计方法
2021-07-14孙明,陈昕
孙 明,陈 昕
同济大学 电子与信息工程学院,上海201804
卷积神经网络是一种以特征提取为主要方式的深度学习算法,被广泛用在图像分类、对象检测和语义分割等领域[1]。但其参数过于庞大,运算过程需要使用大量的算力。适用于CNN 高密度计算的主流硬件有GPU、ASIC和FPGA[2]。与前两者相比,FPGA作为并行化的计算密集型加速硬件,功耗低、可灵活编程、开发周期短,在加速CNN上,获得了更广泛应用。
研究人员主要集中在两方面优化:减少所需的内存带宽和降低推理计算复杂度。Chung等人[3]采用了将奇异值分解与剪枝方法组合使用的方案来对模型进行压缩,从而减少网络参数。Zhang等人[4]提出一种Caffeine框架,将卷积和全连接运算转换为通用矩阵相乘,实现了100 倍性能提升。Liang 等人[5]和Prasanna 等人[6-7]采用快速算法Winograd 和FFT 将卷积变换到特殊域(如频域)完成,将乘法数量减少到n2。Alwani 等人[8]采用fusion计算模式逐层推理,减少高达90%的片内外传输。上述方法存在以下问题:对模型修剪[3]或卷积层融合[8]时,虽减少了内存用量和降低带宽压力,但片上计算资源利用率低;并行计算程度较高[4]或降低运算复杂度[5-7],但造成冗余数据复制,对片上缓存容量要求高。
本文旨在克服上述不足,主要贡献如下:
(1)对卷积6 个循环进行设计空间探索,以确定循环分块因子,提高数据复用程度以减小带宽需求。
(2)通过展开分块充分挖掘4 种计算并行度:层间并行、层内并行、核间并行、核内并行。
(3)将加速方法包装成RTL 组件,向外提供Python接口,给定器件规格和网络配置,可实现深度学习加速算法到板级FPGA部署的自动代码生成。
本文第1章描述了CNN加速框架设计流程和CNN加速器整体架构;第2章详细介绍了具体加速方法;第3章展示了实验结果;第4章得出了结论。
1 加速器架构设计
1.1 CNN加速框架设计流程
如图1 所示,本设计流程可分为训练和生成两步,前一步的输出作为后一步的输入。

图1 CNN加速框架设计流程图
训练阶段:与卷积神经网络训练过程相同,对于一个目标网络.prototxt,用户采用caffe 在CPU 或GPU 上进行反向传播,当迭代次数达到给定值或验证集准确率符合期望时,得到训练后的权重文件.caffemodel。
生成阶段:首先对前一阶段的权重信息文件.caffemodel 和网络模型定义文件.prototxt 进行解析,获得各层类型(如:Conv、Activation、BN、Shoutcut等)和卷积核尺寸,将网络各层进行模块化分解,映射到对应的预制IP库中各RTL块(如乘累加器、循环计算模块、激活函数模块、数据流控制器、输入输出处理模块等),通常情况下,一个卷积层由多个基本RTL组件构成。在优化阶段,基于设计空间探索,对实现卷积计算的6 个循环进行分块,并将循环分块展开(详见第2 章),本过程是生成加速器的核心,此外,还对整体网络层的流水线进行了细粒度优化,在同一时间点各层也能进行同时计算。进入组件整合阶段,生成器将预构建的各RTL 网络组件、各层数据流控制器、读写控制模块等进行组装以形成CNN实现,各个模块或组件均是高度可重构,以确保对不同结构的CNN 的适应性和扩展性。最后,在代码生成阶段输出适用于目标FPGA 开发板的CNN 加速器的Verilog代码。
若综合和实现后,当前CNN 时延过大或各层的BRAMs 数/DSPs 数比率差异大等,用户可更新网络设计,例如修改网络层、更换位宽量化策略、改变计算并行度等,经过训练和生成的几次迭代,最终的网络配置结构和优化方法能契合预期性能。
1.2 生成的CNN加速器整体架构
生成的加速器总体架构如图2所示,采用层并行模式。主要包括卷积计算引擎、片上缓存、外部存储、内部互联总线、多个控制器等。片外DDR 用于存储训练好的模型参数和初始输入图片、推断结果。片上缓存包括各个权重缓存单元和输入输出缓存池,用于保存通过DMA 读取的权重值、各层输入输出特征图和中间计算结果。卷积计算阵列,由多个处理单元组成,每个处理单元的构成元素是级联的乘累加器,负责并行计算。互联总线用于前后层的控制信号传输。控制器负责网络各层计算顺序和缓存流向。

图2 生成的CNN加速器概览
运算过程中,在将图片像素从片外DDR 中读入计算阵列前,先将各层的权重通过DMA 控制器读到权重缓存中,若参数量小,则一次性将其全部保存,运行过程中不再传输权重,当参数规模较大则需要实时传输。之后,启动PE 阵列计算。为达到高效计算和节省ROM/RAM资源,配置两个片上缓存池,各层在输入和输出缓冲池中均有两个可重用的乒乓缓冲区,缓冲区的数量小于层数,通过覆盖计算时间来避免加/卸载数据所需要的时间开销。缓冲控制器负责输入和输出缓冲池中的数据读取写入,上层输出缓存区中的写入数据即为本层待输入的特征图。结合卷积计算的循环分块技术,在得到部分输出结果时,即可开始下一层运算,主控制器用来支持整个网络的细粒度流水线顺序。
2 加速方案设计
CNN 网络中卷积计算可视为一个多维嵌套循环,如图3所示。其中Rin=(Rout-1)×S+K,Cin=(Cout-1)×S+K。

图3 卷积层伪代码
采用分块技术分割循环中的迭代空间可有效缓解片上内存紧张,而可行的分块维度包括平面卷积窗口运算(K×K)、输出特征图尺寸(Rout×Cout)和输入输出通道数(M×N),因为K值一般都很小(通常为[3,11]),故采用对后两个维度进行分块操作,如图4所示。

图4 循环分块原理图
其各维度对应的分块尺寸为Tro、Tco、Tn、Tm完成一个卷积层的执行周期数为:

未分块的图3所示的卷积层所需的操作总数为:

在采用后续的循环展开操作以及忽略流水线开销的影响时,Rooflinemodel[9]中的ComputationalRoof 可由下式计算:
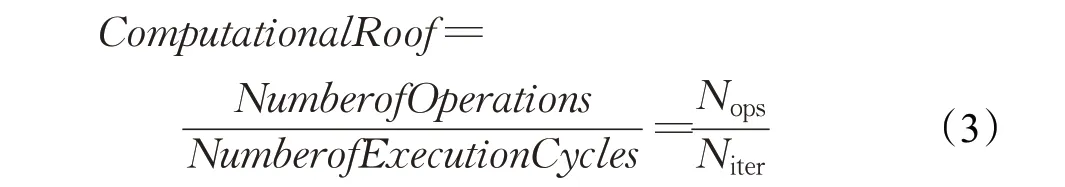
而对于具有Npe个处理单元的计算通路,通常有如下限制条件:
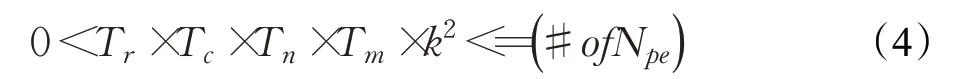
最优的架构是最大化ComputationalRoof,等效于最小化执行周期数。
在采用w位宽量化策略时,图4中循环分块对输入输出特征图和权重缓存尺寸的要求为:

其中BRAMcapacity为片上内存容量。
分块后需要对输入输出特征图和权重进行片外读取的次数为:

Computation to Communication(CTC)ratio 用来表征每次内存访问能支持的计算操作数量,是衡量数据重用水平的一个指标,其定义如下:

由公式(3)和公式(10)可得出,在给定分块策略
由于生成的加速器采用层间流水线架构,为达到最大吞吐量性能,在考虑各层复杂度、数据重用行为的情况下,需使各流水线段的负载平衡,以使时延大致相等[10]:

其中Ci代表层i的计算复杂度(见公式(2)),Ri表示层i所消耗的计算资源(公式(4)乘以每个PE 所需DSP 数量),片上可用的计算计算为Rtotal,而层i的时延Di为:

其中λ是与硬件工作频率有关的常量。网络整体吞吐量受限于具有最大计算时间的卷积层:

因此,本加速器采用公式(12)~(15)指导网络对各层进行计算资源分配。
经过循环分块后,图3 最里层的6 个小循环所涉及的计算任务不仅具有数据来源的相关性和结果的独立性,而且被划分为更小的计算单元,完全可能在片上实现并行化计算,使资源和带宽得到更充分利用,如图5~8所示。

图5 层间并行
图5展示了层间并行,以分块为基本流水段的细粒度流水线可以实现同一时间段所有层的并行计算,减小了启动延时。图6中是层内并行,该并行是通过输入像素复用实现的,当计算输出特征图像上不同通道相同位置的区域,所需要的输入特征图像数据是固定区域,唯一的区别是各个输出通道对应的卷积核不相同,该种并行度为Tn×Tm。图7 描述了核间并行,该并行是通过权重数据复用实现的,输出特征图像中的同一个通道的不同位置像素,所使用的是同一组权重数据,对应该种并行度为Tro×Tco。图8 是核内并行,输入特征图每一通道的卷积窗口与对应卷积核平面计算涉及大量乘加操作,这些运算都是可并行的,并行度为K×K。
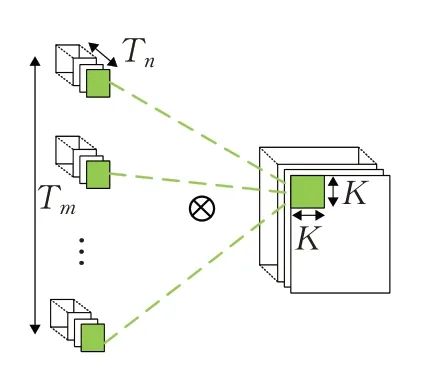
图6 层内并行
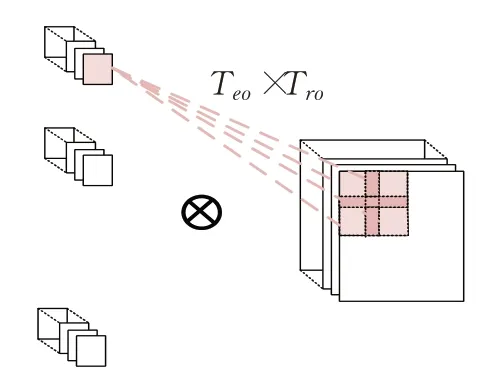
图7 核间并行

图8 核内并行
本加速器计算引擎采用上述4种并行性后的结构,如图9所示。图中,Pix和W代表像素和权重,一个乘法器和一个加法器组成一个基本处理单元,后面连接一加法器树。每个灰色填充区域代表一个卷积窗口和对应卷积平面点乘,对应核内并行;Tn个灰色区域为一组,用黑色实线框住,可以生成一个输出像素值。而红色虚线包围的计算处理引擎共享相同的特征图像数据,能够实现层内并行,Tm×Tn×K×K表示小工作集像素值复用和核内并行下的乘法器个数,可同时生成Tm个输出像素。左边蓝色虚线区域的处理引擎不同的像素值与相同的权重相乘,实现了核间并行,Tro×Tco×Tn×K×K表示小工作集权重复用和核内并行下的乘法器个数,可同时生成Tro×Tco个输出像素。

图9 全并行模式下的计算引擎结构
3 实验结果评估
本文实验首先在ubuntu18.04 系统和python2.7 环境下,采用caffe 训练AlexNet[11]网络模型,将训练后的权重.caffemodel、网络定义文件.prototxt 以及FPGA(Virtex7 690t)各资源参数值作为CNN 加速框架输入,得到分割并转换后的各层权重二进制.coe文件、加速器verilog 源代码和仿真测试数据。之后在ubuntu14.04 系统和vivado2013.4的非工程模式下,调用其multiplier和ROM/RAM memory IP 核生成用于各层乘加运算和存储结果的模块。最后,在配备有Intel i5-7400 CPU,显卡为HD Graphics 630的Win10系统下,通过vivado2018.3和modelsim10.1c 的联合仿真(200 MHz 工作频率)、综合及布局布线,实现了3个网络的正向传播。考虑到过度参数化的CNN 模型中存在大量冗余连接[12],为了有效减少片内外存储需求,加速器使用动态4-8-16位量化策略,top-5准确率仅下降不到2%。
3.1 FPGA映射结果
根据FPGA(Virtex7 690t)的硬件资源参数值和AlexNet模型的网络配置,CNN加速框架输出verilog语言形式的CNN 加速器。采用Vivado2018.3 工具集完成布局布线和仿真,得到图10 中的AlexNet 加速器,图11是图10 中的第五个卷积层结构的原理图,可见加速器的整体架构采用层并行模式以层间流水线形式存在,各卷积层IP通过由乘累加器组成的vector_muladd模块实现并行计算。表1 显示了部署后的资源利用率和实现性能,加速器高效地利用了FPGA的硬件资源。在批处理尺寸为11,采用4-8-16 位动态精度数据量化策略[13],工作频率为200 MHz时,每秒能处理93.7张227×227×3的图像最高可达1 493.4 Gops 计算峰值,而仅使用了2 562 块DSP 和688 块BRAM 参与前向推理,分别占用片上存储和计算资源总数的46.8%和71.2%。

表1 Virtex7 690t@200 MHz下实验结果

图10 AlexNet网络加速器原理图

图11 卷积层结构原理图
本文对关键资源DSP 的利用效率进行了评估。引入DSP 效率来表示参与运算的DSP 的实际与理论最大性能的比率,定义为:
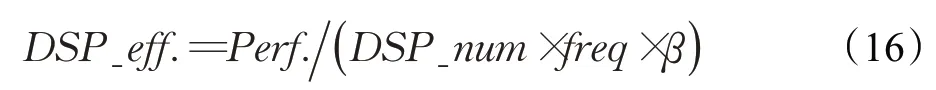
当采用定点数16,8,4 时,β=2,4,8,表示一个DSP 与其相应的逻辑单元在一个时钟周期可进行的算术操作次数[10]。DSP_num×freq×β是在给定频率下,所有DSP能达到的理论最大算力,分子Perf.为表1 中的实际性能。因为其不依赖于FPGA 平台的片上DSP 数量且消除了时钟频率的影响,可以对使用不同FPGA 平台和CNN模型的并行优化算法进行公平比较。表中显示在Virtex7上DSP的效率高达0.73(Ops/DSPs/cycle)。
3.2 量化策略评估
令DW/DP 表示,位宽为DW 的数据定点量化后小数点位置为DP。表2列出了主导计算的层的数据量化情况。
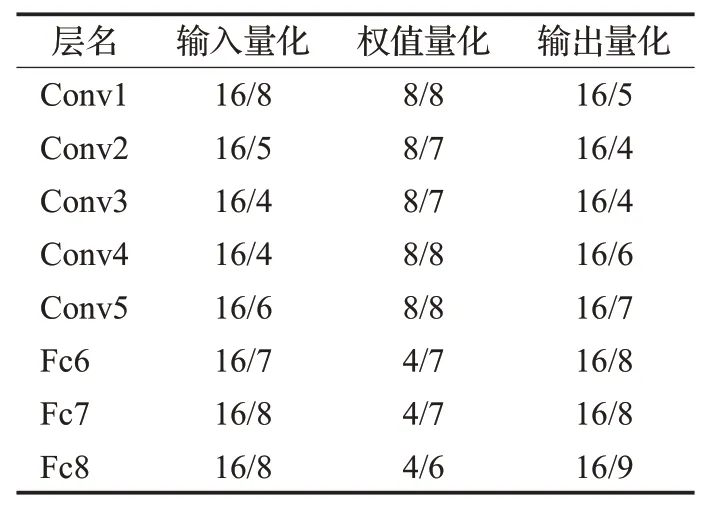
表2 关键层的输入输出与权值量化
未列出的层(如池化等)输出与输入量化保持一致。图12是文献[14]多次训练后得出的AlexNet预测准确度top-1 和top-5 随网络量化位宽的变化曲线(训练后,各层权值截断至相同位宽)。可见,当精度下降到8 bit 以下,准确度急剧下滑,但考虑到全连接层权重密度大、数值小和存在冗余连接多,本策略仍然对全连接层权值采用较激进的4 bit位宽。与采用32位浮点方案相比,本方案在Ristretto caffe[15](caffe的扩展,可以有限数据精度训练、微调和测试网络)训练后的top-1和top-5准确度下降幅度均在2%以内,分别为从55.7%下降到53.9%,79.0%到77.9%。
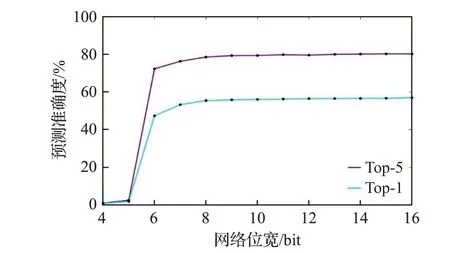
图12 预测准确度与网络量化位宽关系
进一步针对于具体图像采用上述量化方案在FPGA上正向传播过程中产生的误差进行分析,由于AlexNet层数较多,图13 仅展示Conv1 第一个特征图和最后一个全连接层Fc8的输出情况。

图13 Conv1和Fc8的输出
从图3可定性得出,真实数据(caffe浮点数输出)和仿真数据(modelsim10.c定点数输出)的分布基本一致,将仿真数据减去真实数据可得误差值的分布情况,如图14所示。

图14 Conv1和Fc8的误差分布
定义公式(17)对误差定量分析:

sim、real分别表示各层特征图像素的仿真和真实数据值,可得Conv1第一个特征图和Fc8输出的误差分别为0.001 101、0.002 413。仿真数据与真实数据的差值很小,误差影响可忽略。同理,介于Conv1 与Fc8 之间的隐藏层情况类似,网络整体的平均量化误差为0.003 2,说明上述的量化策略可取。
动态4-8-16位量化策略可有效减少存储需求:
(1)片外DRAM 用于存储源图像、AlexNet 权重和推理结果,表2 显示,输入特征图和网络推理结果量化为16 bit,而卷积层和全连接层权值分别量化为8 bit和4 bit。AlexNet 一共有60 965 224 个可训练参数,输入为标准227×227×3彩图,输出是1 000个分类概率,当采用4-8-16 量化策略后,加速器对片外存储空间需求从244 483 244 Byte(233.2 MB)下降到31 960 826 Byte(30.5 MB),节省87%的DRAM存储。
(2)片上RAM/ROM 用于保存推理运行中的权重、中间结果和各层输入输出特征图,本加速器采用层并行模式下的细腻度流水线架构,乒乓缓存数据传输,仅需获得上层输出的部分分块数据和部分权重即可开启本层运算,对片上内存需求大大减少。图15 比较了本文片上内存管理方法与传统设计(特征图和权重完全保存)对BRAM需求的差异。

图15 本文方法与传统设计的内存需求比较
从图15 可知,本加速器部署前8 个卷积和池化层,使用394个BRAM,而传统的将特征图和核权重全部存储在片上的方法,使用1 915 个BRAM。传统设计比本文方法最低多消耗1.34倍存储资源(pool5),最高为6.21倍(conv4)。最后3个全连接层占据了96%的权重,传统设计方法无法一次性将其保存至片上,故本文未对其加以分析,而在细腻度流水线架构和输入输出缓存池技术下,本方法在Fc6、Fc7、Fc8 层分别仅消耗166、68、43 个BRAM,至少会节省80%存储资源。
进一步地,探究了在本文内存管理方法下,数据有无进行动态4-8-16位精度量化对内存需求的变化,如图16所示。

图16 两种量化方案对内存需求的差异
在32位浮点情况下,AlexNet加速器需要占用2 552个BRAM,是4-8-16位量化的3.81倍。注意到,3个全连接层Fc6、Fc7、Fc8 的压缩比率较高,分别为5.35、5.49、3.81 倍,主要原因是全连接层存在大量冗余连接,权值接近0,采用较激进的4 bit量化可在不降低推理准确度的前提下减少片上存储压力。
3.3 与基于CPU/GPU/FPGA的CNN加速器比较
Zhang等人[9]在Intel Xeon CPUE5-2430上运行AlexNet模型中,开启多线程执行,在103.48 ms 内完成正向传播,达到12.84 Gops的峰值性能。从Nvidia官方文档可知,采用16 位浮点,批尺寸为2,AlexNet 模型在GPUTX2[16]上的帧率为250 frame/s。图17比较了CPU、GPU与FPGA在计算性能上的差异。本文设计的AlexNet加速器在FPGA 上的计算性能分别是CPU 和GPU 上的115.8 倍和4.1 倍,一方面是因为FPGA 更适合计算密集型任务,另一方面是本加速器更充分挖掘了CNN 可并行计算的空间和进行了有效内存管理。
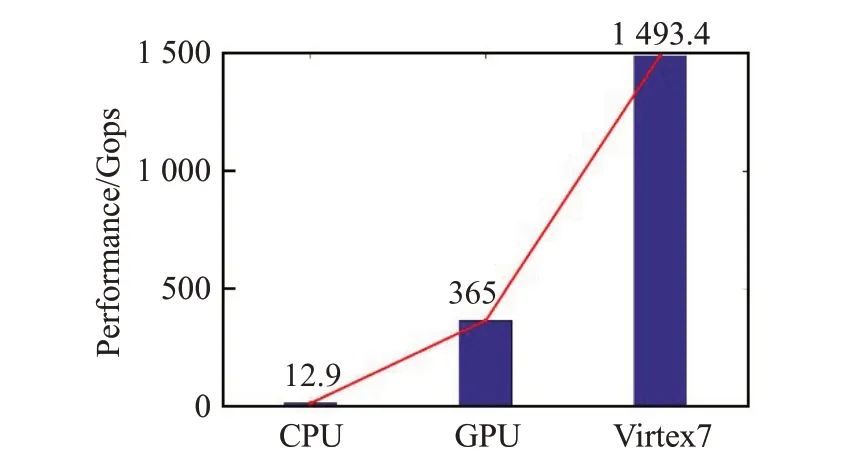
图17 CPU、GPU与FPGA之间的性能比较
此外,本文将Virtex7 690t上的加速器实验结果与3个最近的具有分类功能的基于FPGA 的CNN 加速器进行比较,如表3 所示。在Virtex7 690t 上达到的峰值性能为1 493.4 Gops,比其他3个参考结果都要高,最低为4.2 倍,最高达到24.2 倍。由于不同的实验利用不用规所格示的。FPGA 平台,所使用的CNN 模型和时钟频率也不一样,为了能公正客观衡量各个设计方法的优劣,下表进一步列出了DSP效率,其用来评估每一个参与运算的DSP利用的充分程度。

表3 与基于FPGA的CNN加速器的比较
在Virtex7 690t 平台,本文设计方法的DSP 效率均比其他文献中采用的方法要高,分别是他们的1.7 倍、2.6 倍和1.2 倍。说明本加速器采用的方法能提高硬件资源利用率和数据重用机会,充分挖掘了FPGA并行计算能力。
4 结论
本文提出一个针对卷积神经网络加速的CNN加速框架,生成的加速器可实现高性能和高效率。为了提高计算吞吐量,采用基于设计空间探索的方法确定卷积分块因子,并将分块进行展开,从而提高计算并行性。该方法可增大CTC 率,减少外部存储访问带宽需求,提高数据复用程度。对整个网络采用细粒度流水线架构,考虑到有限的片上内存容量,用内存池、乒乓缓存和4-8-16位精度量化策略进行数据传输,以减少启动和输出延时。基于上述的设计方法,与其他基于CPU/GPU/FPGA的方法相比,本文达到了最高吞吐性能峰值1 493.4 Gops,DSP效率超过了其他设计方法,本文加速器高效且性能优异。
