基于表格的自动问答研究与展望
2021-07-14杨赋庚奚雪峰
李 智,王 震,杨赋庚,奚雪峰
1.苏州科技大学,江苏 苏州215009
2.苏州市公安局,江苏 苏州215000
自动问答是自然语言处理中重要的研究任务。针对用户以自然语言形式提出的问题,自动问答系统面向检索源获取用户答案。为了精确获取答案,通常对问句进行深层次语义挖掘,获取问句中丰富的潜在信息,从而提取用户需要的答案。
表格又称表,是一种可视化的交流模式与组织整理数据的手段,更是一种结构化的知识库。表格的构建需要挖掘、分析、显示各个表格实体之间的相互关系,清晰表示知识库信息。
基于表格的自动问答任务通过挖掘表格实体信息与问句之间的潜在联系,获取生成的结构化查询语句。与传统的搜索引擎相比较,基于表格知识库的信息检索,不再生成非结构化知识库问答的简单排序列表,而是通过智能语义分析,获取查询语句,通过查询语句生成用户需要的问题答案。
本文依次从基于表格的自动问答数据集,问答模型、问答评测方法、问答模型的难点与挑战开展分析与讨论。
1 基于表格的自动问答数据集
自动问答最早可追述到20 世纪50 年代。图灵在1950 年提出通过观察机器是否具有正确回答问题的能力,以此验证机器是否具有智能[1]。1966 年,麻省理工学院的Weizenbaum[2]设计出名为ELIZA的聊天机器,实现了机器与人类的简单问答。随后大量的研究成果相继出现如:Parry[3]、ALICE[4]、Jabberwacky[5];2011年,IBM公司设计研发的超级机器人“沃森”在美国电视智力节目《危险边缘》中战胜两位顶尖的人类选手,被视为人工智能发展的重要节点。不过,上述成果并不代表着机器对于自然语言真正的理解。2011 年,华盛顿大学的Etzioni 发表文章“Search needs a shake-up”指出:“以直接并且准确的形式回答用户的自然语言问句的自动问答系统将构成下一代搜索引擎的雏形”[6]。因此自动问答系统被视为未来信息智能服务的关键性技术之一。
近年来,伴随着用户对于智能应用的迫切需求,许多公司及机构例如谷歌、百度、维基等通过获取高质量数据,采用自动或者而半自动化方法设计一系列完备的表格知识库问答系统,例如Weir等人[7]开发了DBPal工具,Google开发了Analyza系统[8]、NLIDBS[9-10]。同时,以深度学习为代表的算法技术以及GPU等硬件计算能力的提升,为自动问答提供了有利的发展条件。
当前大量文献围绕自动问答任务展开,同时,问答系统的实现离不开数据集。当前成熟的英文问答数据集有WikiSQL[11]、Spider[12]、WikiTableQuestions[13]、ATIS[14]等等。如表1所示,WiKiSQL数据集是2017年由Salesforce提出的大型标注的NL2SQL数据库,是目前最大的NL2SQL数据集;它包含24 241张表,80 645条自然问句以及相应的SQL 语句;WiKiSQL 目前的预测准确率达91.8%。Spider数据集是2018年耶鲁大学提出的一个大规模、跨领域、复杂的NL2SQL数据集;数据集包含10 181条自然问句,分布在200 个独立数据库中的5 693 条SQL,内容覆盖了138个不同领域;Spider引入SQL的高阶用法,更加贴合真实问答场景。WikiTableQuestions数据集是2015年斯坦福大学针对维基百科中半结构化表格问答开发的数据集。该数据含有22 203 条问答句子以及2 108张表格;数据来源于维基百科,因此表格信息没有经过归一化处理,一个自然语言问题内包含多个实体或者含义。ATIS(Air Travel Information System)是由德克萨斯仪器公司在1990 年提出的,该数据集源于关系型数据库Offical-Airline-Guide,包含27张表格以及小于2 000次的Query,Query内容涵盖航班、费用、城市、地面服务等信息。中文问答数据集有首届中文NL2SQL挑战赛数据集[15]、CSpider[16]。首届中文NL2SQL挑战赛数据集,由追一科技在2019年举办的首届中文NL2SQL挑战赛提出,使用金融领域的表格数据作为数据源,提供标注的自然语言问题与SQL语句的匹配对。2019年,Min等人[16]为填补当前中文表格问答的空白,针对目前中文分词问题、句型、汉语零代词问题,将Spider数据集转换为中文,开发出CSpider数据集。

表1 基于表格知识库的问答数据集
Yu等人[17]在2019年公开第一个基于表格的多轮问答数据集SParC,该数据集覆盖138 个领域。SParD 有两大特点:(1)SParC 具有复杂的上下文语义相关性;(2)SParC由于跨领域的性质并且在测试过程中看不到表格信息。目前SParC 的最佳模型的精确匹配度仅为20.2%;Yu 等人[18]在2019 年也公开了基于表格的多轮问答数据集CoSQL。CoSQL 被视为Spider 的多轮对话版本,但是与SParC 相比较,CoSQL 专注于对话双方的交互问答、场景更加丰富,涵盖领域更加广泛。
2 基于语义解析的自动问答方法
基于语义解析的自动问答方法通过构造规则或者模板,对于问题文本进行匹配,形成查询表达式。规则与模板是语义解析方法的具体显示。通过预设置查询模板或者规则,实现查询语句的生成方法具有简洁、准确性高的优点,适用于简单查询。目前,所有的表格问答模型中均在不同程度上使用语义解析方法。
语义解析方法的关键在于对自然语言问句进行成分解析,将查询问句转化为逻辑表达式,再利用表格知识库的语义信息,将逻辑表达式转换为表格知识库的查询结果,最终得到用户的目标答案。在结构化的知识库上进行查询,最高效的方法就是利用结构化查询语句,类似SQL语句等。然而对于普通用户而言,设计规范化的查询语句存在困难。因此基于表格知识库的语义解析问答系统应运而生,如图1 所示,系统实现需要两个关键的步骤:(1)使用语义解析器将问题转化为计算机能够识别和理解的语义表示;(2)使用语义产生结构化查询语言,对表格知识库进行查询。
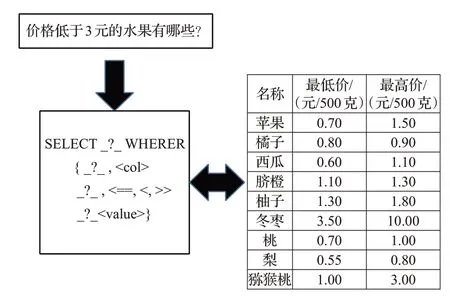
图1 基于语义解析的表格问答过程
常用的语义解析方法有两类:基于规则的语义解析和基于神经网络的语义解析。
2.1 基于规则的语义解析方法
基于规则方法由Woods[19]提出,它依靠语法规则,通过增强转移网络(ATN)进行语义解析,通过上下文无关文法描述自然语言问句的文法结构与文法中产生式的对应语义动作,执行相应的语义结果,最终生成结构化查询语句。2008年,Djahantighi等人[20]基于NLIDB系统,通过识别任何语言的同义词,以此实现专家系统,该系统便于非专业用户使用查询语句处理数据库。2010年,Gauri等人[21]将工作转向混合方法,将基于经验语料库的方法与传统符号方法相互结合,使得英语问句生成SQL成为可能。
2015 年,Humera Khanam 等人[22]提出基于数据库的自然语言接口这一概念,考虑作者母语(泰卢固语)的特征,保证用户提出自然语言问题,问答系统都能给出正确答案并节省问答时间。2016 年,Pasupat 等人[23]面向WikiTableQuestions 数据集,针对语义解析器的核心问题开展研究。这里的核心问题是指有限搜索空间条件下,受限的规则集限制了模型的表达能力。他们的研究工作考虑了最具有表现力的一类逻辑形式,并展示了如何使用动态编程有效地表示一整套统一的逻辑形式。
基于规则的语义解析问答方面,国内的研究人员也取得相应成果,许龙飞等人[24]采用汉语数据库首先提出自然语言查询界面NLCQL,运用数据库E-R 汉语查询模型,将汉语查询语句与对应数据库模型语义以及背景知识相互结合。在语法方面,NLCQL 采用语言模板作为中间语言MQL[25]到SQL的自动转换规则。其基本思想是通过对输入的汉语自然语言进行分词操作等处理,生成对应的汉语句型词组结构树,最终变换成中介语言MQL。再实现中介语言向SQL 的映射,从而执行基于数据库的实际查询。系统相较于传统的句型匹配法有更好的理解能力,同时具有更好的实用性。
陶艳瑰等人[26]从简化语法语义处理过程的角度考虑,设计集合汉语文化背景的数据库自然语言查询界面RchiQL,通过对查询语句进行受限操作以及ER语义特征文法规则[27],提升接口模型识别词汇的准确度。其限制系统所识别的词汇量与句式,进而减少词汇的二义性,避免出现用户构造过于复杂的查询语句;同时为了尽可能处理用户的查询,不过分增加系统实现的复杂度,提出了对于查询问句做预处理的思路。
孟小峰等人[28]针对中文数据库面临的可移植性和可用性两大问题,设计出中文语言查询系统Nchiql,Nchiql 具有良好的可移植性、高效性和鲁棒性。如图2所示,Nchiql 系统根据中文自然语言查询的特点,提出基于数据库语义分词的方法,通过回溯机制、相关语义确定,有效解决分词中出现的歧义词与未知词的问题;同时提出数据库语义依存模型和迭代依存分析方法,获取查询目标之间的关系以及查询条件内部的层次关系,便于系统向SQL语句和自然语言的同步转换。
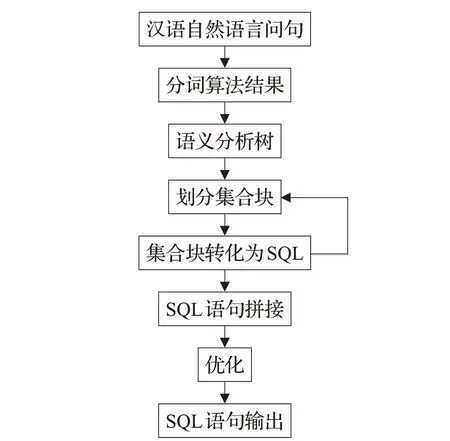
图2 Nchiql流程示意图
综上所述,基于规则的语义分析法可解释性强、结构清晰,在限定领域问答方面达到很好的效果;但是重要部分(如产生式、规则集合)需要人工编写。面对大规模表格知识库的情况下,该方法存在以下不足:(1)资源标注费时费力,在训练数据有限的情况下,性能有限;(2)语义表示与知识库联系不紧密,无法在解析过程中利用知识库进行约束;(3)大规模知识库开放域特性使得文本歧义问题严重。
2.2 基于神经网络的语义解析方法
基于神经网络的方法将自然语言以及对应生成的语义视为两种不同的语言,语义分析任务被看作机器翻译任务,利用端到端模型,实现将问句翻译成对应语义的结构化表示序列,如图3所示。

图3 Encoder-Decoder模型示意图
LeCun 等人[29]在神经网络的基础上提出深度学习的概念,深度学习已经广泛应用于问答系统中子任务的实现。本文将当前基于神经网络的问答任务分为四类:基于分块机制的问答方法、基于类型信息的问答方法、基于草图的问答方法、基于词嵌入的问答方法。
2.2.1 基于分块机制的问答方法
伴随着神经网络技术的发展,研究人员认为目标SQL 语句可以通过分块依次生成。分块机制目前包含两种方法:第一种为槽位填充方法。该方法将SQL语句分解为不同子句,将子句预测结果进行拼接成目标SQL。预测方法包含文本分类、实体识别。第二种为分块解码器方法。该方法对于不同的子句设置不同的解码器,每个子句的编码器由语法规则进行定义。
在槽位填充方法方面,文献[30]提出基于Attention机制的SEQ2SQL模型[11],其核心思想是:首先通过将问句文本与表格信息作为输入,将SEQ2SQL 模型分为聚合分类器、Select Column Pointer、Where条件解码器三部分,分别预测目标语句的操作符号、选择列名、Where子句;最终将上述子句拼接形成完整的查询语句。SEQ2SQL模型如图4所示。

图4 SEQ2SQL运行流程图
上述模型优势是对于不同的问题可以复用,生成目标灵活,缺点是需要针对于不同的问答数据集制作对应的模板;同时生成模板对于数据集依赖性较大。上述模型将目标SQL 语句划分为三个子模块分别预测生成。随着神经网络的不断发展,问答模型将SQL语句分解任务不断细化。文献[11]基础上提出的SQLNet 模型[31]引入Seq2Item(集合到序列)和Column-Attention(列注意力)两种思想;SQLNet 利用各个槽位预测对象的依赖性,填充预先设置SQL语句中的槽位,通过生成槽位的拼接,提升SQL 生成的准确度,SQLNet 模型如图5 所示。Shi等人[32]考虑到存在多个具有相同或相似语义的正确SQL查询语句的情况,使用预定义清单中可行性的操作逐步填充SQL 查询的插槽;从句法解析技术中汲取了灵感,提出使用非确定性序列到动作的模型;面对Spdier 数据集中复杂的嵌套查询,Choi 等人[33]提出一种基于递归生成思想的新网络架构RYANSQL,通过基于草图的槽填充算法来递归预测嵌套查询;该模型在Spider上取得58.2%的准确度,模型效果明显,更便于生成含有子查询的SQL语句。

图5 SQLNet模型图
在分块解码器方法中,Lee等人[34]基于Spider数据集,针对复杂查询问题,提出SQL 子句解码结构RCSQL。该结构基于self-attention 机制的数据库模式编码器,其编码器负责语义表示任务;每个子句的解码器由一组子模块组成,子模块由每个子句的语法定义构建形成。该方法在多表情况与问题文本跨域条件下实现了复杂查询语句的生成。
2.2.2 基于类型信息的问答方法
针对用户采用自然语言表示的问题,研究人员提出使用类型信息进行目标SQL 语句的生成。2017 年,针对输入自然语言问句中的类型信息,文章“Pointing out SQL queries from text”提出一种基于注意力和复制两种机制的新型表格自动问答模型。模型基于简单类型规则,采用Seq2Seq 架构[35]以控制每个编码步骤的解码模式,根据SQL语法专门设置内置词汇对于操作符号进行标记。在要求生成列名或常数的情况下,模型强制进行Copy操作;其余情况下,模型将隐藏信息投影到一个内置词汇表,获取内置词汇表的运算操作符号。上述模型虽然利用自然问句中的类型信息,提升模型对自然语言问题的理解能力,但是类型信息有限,如何利用标注技术进行问句标注成为新课题。2018年,文献[36]借助类型信息表示,提出新的问答模型TypeSQL;利用类型信息理解自然语言问题中特殊实体,对输入问句逐一进行类型标注,将问句中数字和日期分为四个部分(整数、浮点数、日期、年份)。为了识别问题中实体,模型设置五种类型实体(Place、Country、Person、Origination、Sport),将基于表格的问答模型视为填充插槽任务,以此生成高质量的结构化查询语句,TypeSQL最大限度地融合文本类型,便于自然语言问题的解构。
2.2.3 基于草图的问答方法
针对问答任务需要生成SQL,研究人员提出基于草图指导目标SQL生成的想法,草图为部分生成的结构化语句。2018年,Wang等人[37]基于神经语义解析,提出执行引导(Execution Guidance)思路,即利用SQL的语义,在解码(Decoder)过程中,通过部分生成SQL 来检测和排除错误的SQL 生成语句;在出现解析错误(Parsing Error)和运行错误(Runtime Error)两种情况下,解码不会得到正确结果;运行错误包含运算符类型不一致、空输出等错误情况。在假定所有查询语句都可以得到结果的情况下,模型生成一部分SQL 语句以后就可以执行,执行的结果反过来又可以指导SQL生成过程,执行指南如图6 所示。上述模型针对SQL 生成错误的情况进行草图构建。面对当前自然语言问句中存在的高低阶信息,研究人员又提出新的草图生成方法。Wang 等人[38]设计了一种基于结构感知的神经结构,该结构将语义解析分为两个阶段:首先给定输入文本,生成相应的草图,草图省略低级信息(如变量名、数值);然后考虑输入文本和草图本身的缺失细节。该模型与一次性解码结构相比,生成草图紧凑且容易生成;在生成草图后,解码器理解问句的基本含义,从而将其作为全局上下文信息,进行最终预测SQL的修改。

图6 执行指南示意图
草图本质上属于问答任务中的中间信息。当前研究者针对于NL2SQL 的中间生成部分提出中间语言的概念。针对于复杂且跨域的NL2SQL 任务,Guo 等人[39]提出了一种称为IRNet的神经网络方法。IRNet并非端到端合成SQL查询,而是将合成过程分解为三个阶段:在第一阶段,IRNet 执行问题和数据库架构之间的架构链接;其次,IRNet 采用基于语法的神经模型来合成SemQ 查询,该查询是设计用来桥接NL 和SQL 的中间表示;最后,IRNet 使用领域知识从综合的SemQL 查询中确定性地推断出SQL 查询。IRNet 旨在解决两个问题:(1)自然语言中表达的意图与SQL 中的实现细节之间的不匹配;(2)大量域外单词导致的预测列的错误。
2.2.4 基于词嵌入的问答方法
伴随着深度学习的发展,预训练模型不断涌现,例如Glove[40]、BERT(Bidirectional Encoder Representation from Transformers)[41],推动了文本语义表示效果的不断提升。由此,越来越多的研究人员认为准确的语义表示是提升当前问答模型效果的关键,并将预训练模型带入问答任务中。
Hwang 等人[42]在2019 年开发出的SQLOVA 系统[42]引入了BERT 预处理模型。在编码器(Encoder)上,模型结合槽位机制与草图方法提出三种结构:第一个结构是Shallow-Layer,基于草图生成SQL 语句的六部分(选择列部分、选择聚合部分、Where 子句数量部分、Where列部分、Where子句操作符号部分、Where子句值部分),每个部分具有独自的编码器;第二个结构是基于Poiner Network 的LSTM 模块[43]来解码生成SQL;第三个结构将BERT的输出作为Embedding。模型将自然语言查询与表格的所有列名进行编码,采用列注意力机制与Selfattention机制,使得自然语言问句语境化,以此显示问句与表两者之间的交互关系,SQLOVA从修正语句的角度考虑,通过对生成的SQL语句进行语法检查,从而提升模型的准确性。2019年,He等人[44]结合槽位机制,设计出基于Bert 预训练的模型X-SQL。该模型将任务分解为6个子任务。相较于传统问答模型,X-SQL模型添加None元素,扩大查找范围,解决了传统模型不能有效对于各个目标进行关系建模的问题。X-SQL 采用一种列表示的全局排序,将所有列放在可比较的空间,使用KL 散度的List-Wise Global Ranking[45]作为目标函数。X-SQL不仅有效构建列之间的关系,同时将六个任务相互结合,更便于SQL 语句的生成。但是X-SQL 模型分解为六个子模块思路仍然存在缺陷,即没有解决Value抽取混乱,Column特征不显著的问题。
当前阶段,图网络表示学习成为自然语言处理的热门技术,Shaw等人[46]基于Spider数据库生成复杂逻辑形式问题,提出利用实体之间的关系,将GNN(Graph Neural Networks)[47]融入相关实体以及关系的表示;结合编码器的复制机制,实现多层嵌套SQL语句的生成,模型考虑数据库信息的异同对SQL语句生成的影响,通过GNN的编码表示,提高模型的准确性。
除了上述总结的四种方法,针对于问答模型存在的其他问题,研究人员提出众多有效的解决方案或新模型。在问答数据方面,Huang 等人[48]针对于问答模型难以适用于所有训练样本的问题,提出基于域依赖的相关函数,通过将原始问句简化为元学习场景,以此加快模型收敛速度;Wang等人[49]基于自动注释机制,采用分离数据及其模式的方法,将数据模式与数据分开,通过定制序列模型,将带有注释的自然问句转换为SQL语句;在模型改进方面,针对于目前的语义解析器依靠自动回归编码,一次发出一个符号的问题,Bogin等人[50]提出语义解析器全局考虑输出查询的结构,根据上下文进行更多的数据库常量的信息选择;McCann 等人[51]提出新的多任务问答网络(MQAN),基于多指针生成器的解码提高问答任务中语义解析的效果;YU 等人[52]提出了语法树网络SyntaxSQLNet,使用具有SQL 生成路径历史记录以及基于SQL 特定语法的解码器;Dong 等人[53]提出基于注意力增强的编解码器的方法,将输入的语音编码进行矢量表示,并通过调节编码矢量上的输出序列来生成逻辑形式。
国内也有很多研究者,致力于构建表格知识库以及设计问答系统。在构建知识库方面,2019 年,Min 等人[16]为填补当前中文表格问答空白,针对目前中文分词问题、句型问题、汉语零代词问题,将Spider数据集转换为中文形式,开发出CSpider 数据集,并且利用Syntax-SQLNet 作为基线模型进行效果测试。同年,追一科技举办首届中文NL2SQL大赛。在设计问答系统方面,面向NL2SQL数据集,张啸宇设计一种多任务的表格问答系统,将生成目标进行分解,提高下游子任务的准确性,同时考虑到value 抽取特征不明显的情况,提出结合信息增强算法以及数据预处理的方法,在2019 年的中文NL2SQL大赛上,取得第一名的成绩。
在2018 年,联想AI 实验室设计了一种基于合成思想的问答系统[54],用SQL-Query 的结构、双向注意力机制[55]、字符级嵌入、卷积神经网络CNN[56],将NL2SQL模型分为聚合器选择模块、列名选择模块、Where 子句模块;针对每个子模块设计特定神经网络;系统中自然语言问题和Column 信息全部经过BiLSTM 模块,再通过双向注意力机制进行映射最终获取预测对象,模型考虑到问答中实体数量对准确度的影响,通过设置子任务提升SQL语句生成时间与精度。模型如图7所示。
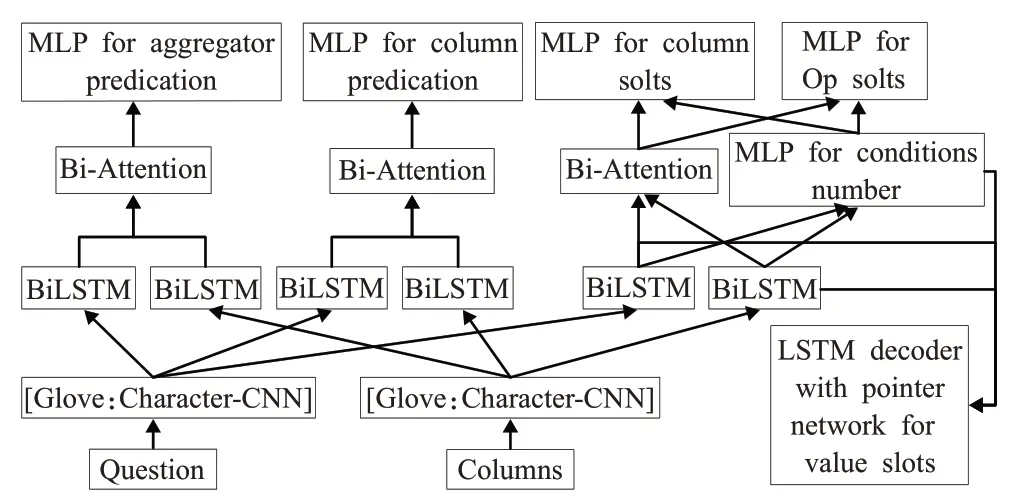
图7 模型运行流程图
综上所述,如表2 所示,基于语义解析的表格知识库问答方法,核心任务是将自然语言转化为机器能够理解和执行的语义表示。在基于规则的语义方法中,语义表示缺乏灵活性,在分析问句语义的过程中,易受到符号之间语义鸿沟的影响;同时从自然语言问句得到结构化语义表示需要进行多步操作,多步之间的误差传递对于问答准确度易造成影响;而基于神经网络的方法,受限于数据集的匮乏。因此基于语义分析的问答系统在开放域上取得的效果不尽人意。此外,无论是基于规则的方法或者基于神经网络方法都需要标注语料,耗费大量人工,因此构建低成本的模型也是目前问答任务的研究方向之一。表3 展示了当前主流的问答模型及其性能。

表2 基于规则与基于神经网络的方法比较

表3 WikiSQL数据集中问答模型的性能对比 %
3 基于表格知识库的自动问答系统评测
基于表格知识库的自动问答系统评测与之前的传统知识库问答评测相比,既有相同之处,也有特殊之处。由于表格问答系统生成SQL语句的不同,导致其不同数据集设置的评测指标各异。目前评测的指标主要包含两种评价方式:
(1)逻辑形式准确率(Logical form Accuracy),将模型合成的SQL 查询与真值进行比较;(2)查询匹配准确率(Query-Match Accuracy),将合成的SQL 语句与真值转化为规范表示并进行比较,其中各个子句中的列名的出现顺序不影响准确率的计算;(3)执行结果准确率(Execution Accuracy),生成的SQL 语句与真值执行的结果的比较。

其中,N表示数据量,SQL′和SQL分别代表预测和真实的SQL语句,Accif代表逻辑形式匹配准确率。

其中,N表示数据量,SQL′和SQL分别代表规范化预测和规范化的真实SQL语句,Accqm代表查询匹配准确率。
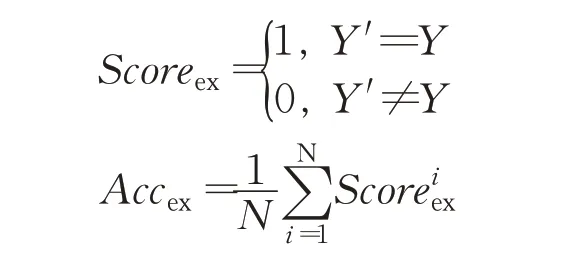
其中,N表示数据量,Y′ 和Y分别代表预测和真实SQL语句的执行结果,Accex代表执行结果准确率。
逻辑形式匹配度包含各个模块(聚合函数匹配、选择列匹配、条件列匹配、值匹配)的匹配精准度。查询匹配度(Accqm)因需要将生成SQL规范化后进行比较。伴随现有问答数据集的发展,未来的评测指标将会不断细化。对于结构化语言生成任务而言,评测指标包含的自动生成答案的可推理性评估、可读性评估、流畅性评估将会愈加重要。表4 为当前各个数据集下评价指标下的最新效果。

表4 问答数据集中验证集的指标效果
4 表格自动问答系统的问题与挑战
当前,基于表格问答任务在WikiSQL等传统数据集的准确率已达91.8%,然而实际应用中仍然存在很多问题亟待解决和优化。本章结合研究中遇到的问题,分析表格自动问答系统的问题与挑战。
4.1 单表操作的问题
现有基于表格知识库的自动问答技术,在单一的表格知识库上已经取得优异的效果,然而在实际的问答场景下,面对用户的复杂问题,需要外联两个甚至多个数据表才可以得到目标答案。但是,主流数据集WikiSQL中的自然语言问题结构过于简单并且其中的单表问答不符合现实场景中的需求。
针对单表操作的局限,现有模型采用扩大表格规模的方式来避免单表操作带来的信息局限。虽然这种方式会增加时间复杂度,不过能够保证查询语句的简易性,提高表格问答任务的精确度。上述方案涉及关系数据库融合技术以及在数据信息扩充情况下,如何保证问答检索速度等难点,需要研究人员进行深入探索。
4.2 自然语言问题的信息解析局限
目前自然语言问题的理解是基于表格问答的重点。一个规范化的问答语句将提高生成SQL 语句的准确度。不规范NL2SQL问题语句表现在错别字、口语化输入、模糊信息等多方面。错别字方面,例如将“芈月传”错写成“半月传”。口语化方面,输入的问题文本中含有大量口语化的信息,需要人工或深度学习方法进行转换或剔除。模糊信息方面,例如“今年三月”,问答模型无法判断今年究竟是哪一年,因此需要问答模型进行泛化操作。另外由于数据库中通常是以数字形式存储数据信息,在自然问句中,“三月”这类汉语数字信息应该转换为“3月”,即阿拉伯数字信息。针对上述情况,研究人员通过预处理操作将原有问题文本的缺失信息添加到相应的位置,从而提升文本的判别效果;同时基于正则表达式,将相应的中文数字信息转换为数据库可识别的数字信息,提升模型值预测的准确度。
4.3 多轮对话表格知识库问答
近年来,关于表格知识库上的单轮问答任务基本得到解决。从对话角度看,当前学术界更加重视包含多轮对话的问答任务。由于自然问题与表格知识库的多样性和复杂性,多轮表格知识库的问答仍然是一项具有挑战性的任务。
2019年,Zhang等人[57]专注于跨域文本到SQL生成的任务[57]。基于观察到相邻自然语言问题通常在语言上是依赖的,并且它们对应的SQL 查询趋于重叠的思路,通过编辑先前的预测查询,利用交互历史来提高生成质量;同时利用编辑机制将SQL视为序列,并以简单的方式在令牌级别重用生成结果。此外,为了处理不同域中的复杂表结构,采用表感知解码器来合并用户话语和表模式的上下文信息。
2019年,Yu等人[52]提出新的方法。方法分为两点:一是使用语法树网络SyntaxSQLNet[52],以解决多轮对话中跨域文本到SQL生成的任务。SyntaxSQLNet使用具有SQL 生成路径历史记录和column-attention 编码器。二是使用数据库拆分设置,其中在训练期间看不到测试集中的数据库。2020 年,Cai 等人[58]针对多轮问答任务只集中于历史用户输入的问题,除了利用编码器捕捉用户输入的历史信息,模型还提出了基于历史信息的数据库模式编码器。在译码阶段,通过引入了权衡机制,权衡不同词汇的重要性,然后制造SQL标记的预测。Hui等人[59]提出了一个动态图框架,该框架能够在对话进行时有效地建模上下文话语、令牌、数据库模式及其复杂的交互。该框架采用了动态记忆衰减机制,结合了归纳偏差来整合丰富的上下文关系表示。
综上所述,多轮表格问答的问题主要分两点:一是问句信息问题;二是上下文问题。问句信息问题指的是在多轮问答限定表格知识库的情况下,问句出现指代模糊、实体信息省略的情况,这类问题的解决需要联系上下文实体,才能找到实体答案。上下文问题指的是上文问答的结果对于下文问答的结果是否具有影响。在问答过程中,当前模型对于上文依赖不断增加时,可能导致结尾问答过程出错的情况。多轮的表格知识问答是当前的研究难点与热点问题,还需更多探索。
4.4 中文NLSQL数据集的生成与应用
2019 年前,中文表格问答数据集还是相对匮乏的。首届中文NL2SQL 大赛数据集和Spider 中文版数据集(CSpider)的出现缓解了数据集匮乏的困境。但是这上述数据集仅仅涉及金融、经济领域,并且CSpider数据集格式复杂(涉及高阶操作),研究者较少。当前如何利用各个领域存在的表格知识库,基于深度学习的大规模、可学习的优点,构建跨领域知识库是中文自动问答系统迫切需要解决的问题。
基于目前中文表格问答数据集,可以利用已公开的问答模型,基于特定领域问答数据的标注特点,构建空白领域问答数据集,从而实现中文表格问答在特定领域的应用。
4.5 问答模型自然答案的生成
现存许多问答数据集的问答任务实际上是答案抽取模型,通过这种方法获取的答案十分生硬,未有任何加工修饰,不够自然。例如,根据用户的自然语言问句“今年苹果卖多少钱”,仅仅将答案实体“3”作为答案是不足的,用户往往更加接受自成一体的答案形式。为解决答案不自然的问题,2016年,Yin等人[60]首先提出自然答案生成这一概念并且提出GenQA模型。He等人[61]在2017 年提出端到端的问答系统COREQA,以生成复杂问句的自然答案。但是上述模型均是基于文本知识库问答,并未涉及表格知识库。将自然答案生成视为槽位填充任务,将抽取答案与自然语句进行拼接,是目前表自然答案生成的一种有效的解决思路。自然答案生成示意图如图8所示。

图8 自然答案生成示意图
5 结束语
伴随智能时代的来临,海量数据充斥人类生活的每个角落,用户对于自动问答需求越来越强烈。然而现有问答系统还处在起步阶段,仅仅具备简单的逻辑推理能力,无法充分满足用户应用需求。基于表格知识库的自动问答系统作为自动问答的重要方向,其技术发展趋势从限定领域向开放领域发展,从单一数据源向多源数据发展,从浅层语义分析向深度推理发展,不断提升自动问答各类性能指标,以满足不同行业的智能问答需求,更好服务于用户。
