基于YOLOv3的交通标志检测与识别算法
2021-07-09胡鹏黄辉王琼瑶邹媛媛蔡庆荣
胡鹏,黄辉,王琼瑶,邹媛媛,蔡庆荣
(五邑大学 智能制造学部,广东 江门 529020)
道路交通标志的检测与识别[1]是自动驾驶领域一个非常重要的研究分支.然而,在实际行驶过程中,同一个视觉镜头下会出现多个不同种类的交通标志,而且交通标志图像还会出现顺光、逆光、遮挡和褪色等各种实际问题,这些因素都会在不同程度上影响交通标志的检测效果.因此,对交通标志进行准确、高效和稳定的检测与识别是一个具有很高挑战性的实景目标检测任务.
自LeNet[2]在1998年被提出以来,卷积神经网络(CNN)迅速衍生出基于深度学习的两阶经典检测器RCNN(Region-Convolutional Neural Networks)[3]系列算法、单阶多层检测器SSD(Single Shot Multibox Detector)[4]系列算法和单阶经典检测器YOLO(You Only Look Once)[5]系列算法,这3种系列算法在目标检测方面都各有优势.SSD系列算法准确率高,但检测速度相对较慢.YOLO系列算法则是以检测速度快著称,其中的YOLOv3检测算法[6]通过多尺度预测,提高了算法对常规场景下的小目标的检测能力,因此 YOLOv3的快速检测识别能力正是自动驾驶领域所需要的,但由于其定位准确度仍存在不足,召回率相对偏低,尤其是对于遮挡和拥挤重叠这些较难处理的情况,检测精度仍然存在提升空间.因此,本文选择YOLOv3算法作为基础算法,针对小像素交通标志图像的识别问题,提出一种改进的 YOLOv3算法,以满足自动驾驶对道路交通标志的检测精度和速度的要求.
1 本文改进算法
1.1 针对画面中小像素交通标志的网络结构优化
本文所识别的图片来自车内视角拍摄,每张图像的分辨率为2 560× 1 440 px,图像中的交通标志分辨率在90×90 px之内,均为小像素交通标志图像.基于此,本文提出一种多尺度检测模块,如图1所示.图1中,DBL是YOLOv3网络结构中的最小组件,由卷积层、BN层和卷积函数Leaky relu 3部分组成,res unit代表残差结构,resn结构中的n代表残差结构的个数.
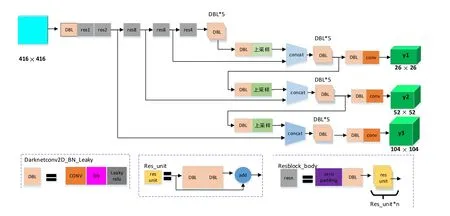
图1 改进的YOLOv3结构图
与原YOLOv3结构相似的是,本文算法通过将高分辨率的浅层特征与高语义信息的深层特征融合,在3个不同尺度的特征上检测物体.不同的是,YOLOv3采用了13×13,26×26,52×52 3个尺度的特征融合,考虑到图像中的远距离交通标志的分辨率一般不会出现超过120×120 px,故在原结构上去掉了13×13这个尺度检测层,并在构建融合层时,通过对深层特征图进行上采样[7],将特征图放大到和浅层特征图相同的尺寸,然后进行张量拼接(Concat)操作,构建了一个104×104的尺度检测层.这样设计的目的是为了加强对小像素交通标志的检测能力,通过去除冗余的结构,以此来减少整个网络模型的计算量,提高训练效率.
1.2 改进的NMS算法
目前大部分的目标检测算法都会用 NMS算法进行最后处理,这种算法简单有效,但缺陷也很明显,就是通过算法保留得分最高的预测框,将其他得分高于给定阈值的预测框强制去掉,当画面中出现的交通标志相对密集时,原本属于两个不同交通标志的预测框中得分偏低的预测框便可能会被强制筛选掉,这样就会导致算法的召回率下降.
本文用到的Softer-NMS是在Fast-RCNN[8]网络结构的基础上添加了一个标准差的预测分支,形成了边框的高斯分布,最终可以获得KL(Kullback-Leibler)散度的预测框回归损失函数的损失值.主要计算过程如下:
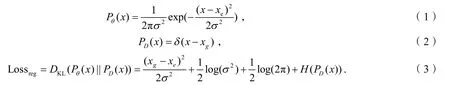
其中,Pθ(x)为预测框的高斯分布,PD(x)是真实框的狄克拉分布,xe代表预测的边框的位置期望,xg是真实边框的位置,σ代表标准差,L ossreg是以KL散度作为边框回归的损失函数.当σ值越趋近于0时,表明预测框与真实框越接近,说明网络对当前预测的边框位置期望持有很高的置信度,可以进行精确定位.
1.3 卷积层与BN层的合并
在训练深度网络模型时,BN层对解决反向传播[9]中的梯度消失和梯度爆炸起到了很明显的效果,而且可以加速网络模型的收敛,并且能够控制过拟合,一般位于卷积层之后.但是在网络前向测试时,BN层的存在不可避免地会增加模型的计算量,从而影响模型的性能,还会占用更多的内存及显存空间.因此,本文在测试时将 BN层的参数合并到卷积层中,以此来减少算法的计算量,提升网络模型前向推断的速度,加快模型的检测速度.
在YOLOv3中,BN算法过程如下:

其中,γ为缩放因子,μ为批处理数据的均值,β为偏置,σ2为批处理数据的方差.为了避免分母为0,本文在实验时将ε取值为0.000 000 1,卷积计算结果xconv如下:

xconv为BN卷积计算的结果,xout为BN算法的计算结果.将卷积层与BN层合并:
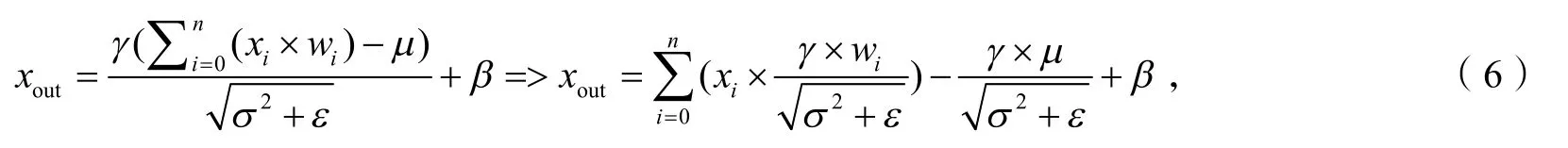
取合并后的权值参数为:

合并后的偏置为:

合并后的计算简化为:

卷积层与BN 层合并后可以与卷积层共用Blob数据,减少内存占用,从而提升检测速度.
2 实验与分析
2.1 数据集的制作与后期处理
本文使用的数据集JM-data是由个人制作完成的.首先,由安装在车辆前端的海康威视F6Pro行车记录仪对路况实景进行拍摄,筛选出有交通标志的视频,运用Python程序从这些视频里每隔7帧截取一张图像,制作成连贯的照片集,这样制成的数据集包含由小到大的不同时刻的交通标志图像,使样本更加丰富.然后,从这些照片中筛选出6 500张作为实验训练数据集(包含顺光、逆光、部分遮挡等情况下的20种交通标志照片),其中5 300张做训练集,1 200张做验证集.通过labelImg图像标注软件对数据集进行手工标注分类,得到每张图片的XML文件,最后,用Python程序分别对训练集和验证集这两个文件各自运行一次,生成相应的TXT文本.
为了提高定位精度,加快收敛,本文使用 K-means聚类算法[10]对已生成的 TXT文本获取YOLOv3算法需要的先验框尺寸信息.因为K-means对初始点敏感,所以程序在每次运行后,所得的先验框结果都有偏差,但是对应的avg iou是稳定的,所以本文统计了多组聚类的结果,最终选择了相对稳定的9个锚点,不同尺度的锚点对应的先验框如表1所示.
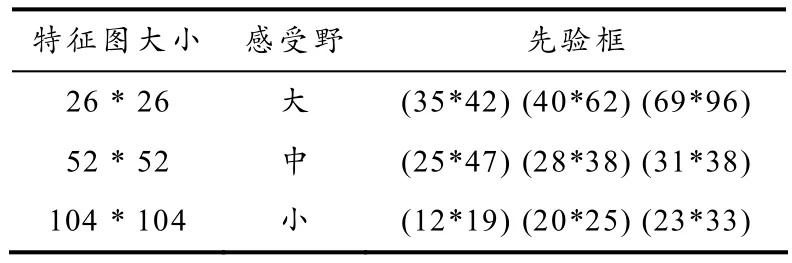
表1 先验框在特征图上的分布
2.2 实验环境配置与网络训练
本文实验环境:Win10操作系统,16 Gb内存,NVIDIA GTX1080TI显卡,显存为11 Gb,CPU为i7-7700.使用Darknet深度学习框架,GPU加速库是基于CUDA10.1的cuDNN7.6.5.
训练初期,动量参数设为0.9,衰减系数设为0.000 5,学习率设为0.001,选择steps这种学习策略来更新学习率,当迭代到9 600次时,学习率衰减 10倍,到11 000次时,学习率在前一个学习率的基础上再次衰减10倍,对于候选框尺寸(anchors),是将通过K-means聚类算法得到的9个先验框,按照从小到大的顺序替换原文件中的anchors,模型训练过程中损失函数曲线如图2所示,精度与召回率曲线如图3所示.
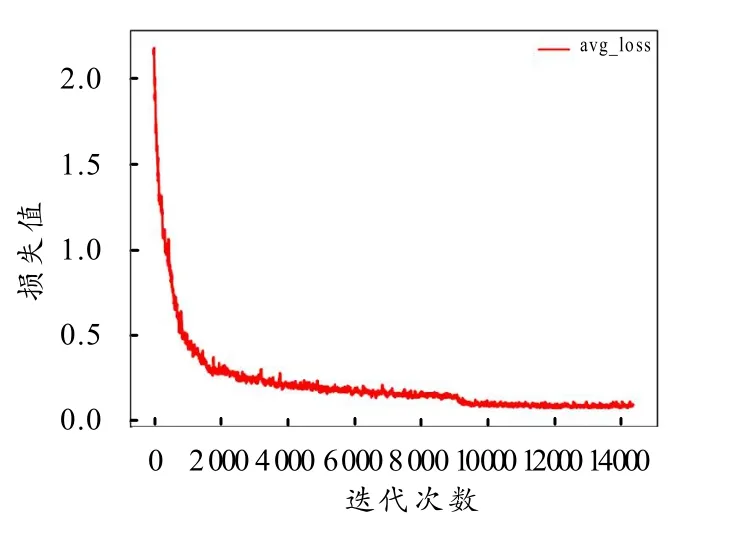
图2 损失函数曲线
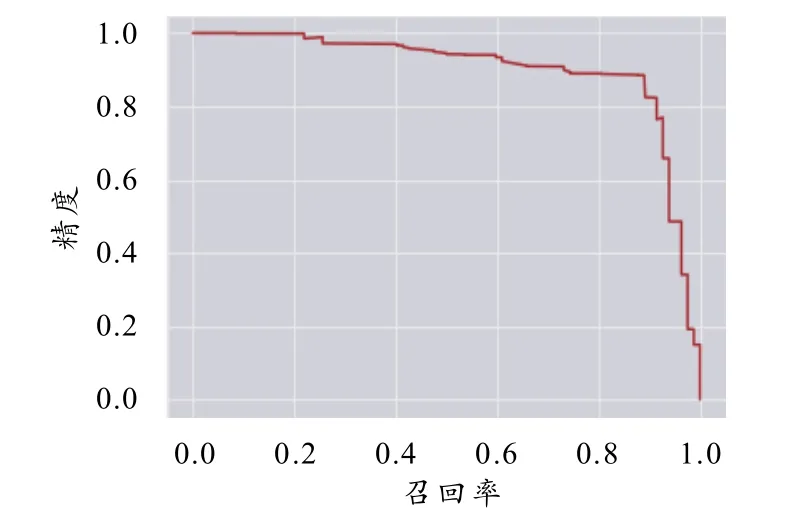
图3 精度与召回率曲线
由图2可以看出,在前2 000次迭代期间,网络快速拟合,在2 000~9 600次,损失函数曲线趋于平缓下降,在9 600次后,由于学习率由0.001降至0.000 1,降低了10倍,所以损失函数曲线再次微弱下降,即损失函数进一步收敛,之后损失函数曲线趋于平稳状态,loss值稳定在0.1附近.
2.3 评价指标
对于改进后的效果,本文从训练后的模型检测的准确率P,召回率R,平均精度(mAP)和检测速度4个方面进行分析:

其中:TP代表正确检测框,即交通标志的预测框与标签框正确匹配,两者之间的IoU大于0.5.FP代表误检框,即把背景预测成了交通标志.FN代表漏检框,即原本需要检测出的交通标志,但实际没有检测出来.mAP计算公式为:
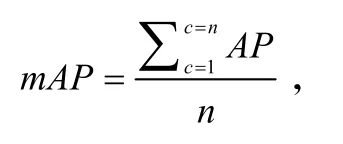
其中,AP为单个类别的平均准确率,n为类别数目,本文的类别数为20.
2.4 测试结果
4种算法的检测效果如图4所示,其中从左到右的3列对应的情况分别为遮挡、常规场景和不同大小的同一种标志.左图检测到的是限速标志,中间图检测到的是小心行人和允许调头的标志,右图检测到的是保持向右.

图4 4种方法对交通标志检测识别的效果对比
2.5 定量评估
用本文改进的算法、YOLOv2、YOLOv3和YOLOv4 4种算法对数据集进行训练,在对应的cfg文件中,将输入图像全部设置为416×416.表2为4种算法的实验结果对比.

表2 算法实验的结果
针对同一测试集,本文改进的算法与YOLOv3相比,在准确率、召回率、mAP3个评估指标上分别提高了7.88%、4.04%和7.59%,在速度上快了10.95%;与YOLOv2相比,本文算法在这3个指标上已经具备了明显的优势,但由于两者之间在网络结构的复杂程度上存在明显差异,所以本文算法在检测速度上处于劣势,但仍满足实时检测的要求;相对于YOLOv4,本文算法除了在召回率上低了1.18%,在其他3个指标上都更具优势.
3 总结
本文提出了一种改进的YOLOv3交通标志检测方法.实验结果表明,本文算法改善了检测边框的位置精度,提高了小像素交通标志图像的检测精度和速度.通过实验证明,对于行驶中的汽车,重点检测远距离小像素交通标志进行提前识别,弱化近距离大像素交通标志的检测能力,剔除不必要的网络结构,在一定程度上减少计算量,提高训练效率,是完全可行的设计方案.下一步我们将结合模型量化、剪枝等方法,精简网络结构,降低模型的大小,以便在普通的嵌入式处理器上应用.
