基于改进YOLOv3的煤矸识别方法研究
2021-07-09雷世威肖兴美
雷世威,肖兴美,张 明
(中煤科工集团重庆研究院有限公司,重庆 400039)
我国能源结构的现状为富煤、贫油、少气,而清洁能源尚处于发展阶段,目前煤炭在我国能源结构中仍处于主体地位[1]。煤和矸石分选是煤炭生产中的重要环节,有助于提高原煤品质,也可避免矸石因发生自燃、雨淋、泥化等情况对环境造成危害[2]。
传统选煤方法存在成本高、自然资源消耗大、环境污染大等诸多问题,煤矸分选的机械化、自动化、智能化已成为煤炭生产中亟待研究的重要课题,其中煤矸的准确识别是实现自动分选的首要任务和关键技术。目前煤矸识别方法主要有密度识别法、硬度识别法、射线识别法、图像识别法[3]。图像识别法相较于其他的识别方法具有安全、系统简单、易于维护等优点,是目前煤矸识别的一个重要发展方向。传统的图像识别技术[4-11]主要运用图像处理技术对煤和矸石的灰度和纹理等参数进行提取,通过不同的算法建立特征值模型,分析并优化分割参数,最终实现煤和矸石的识别,但在特征的选取和阈值的确定过程中需要通过人为分析确定,其实用性和适应性不强。近年来,深度学习技术已逐渐应用于煤矸识别的研究中,曹现刚等[12]提出了一种基于GoogLenet深度学习网络的煤矸识别方法,采用Inception 模型,并通过迁移学习共享已训练模型卷积层权值和偏差,取得了较高的分类准确率;王冠军等[13]采用Tengine深度学习框架中的VGG16深度学习模型对煤矸图像进行训练识别,提升了网络识别精度。采用GoogLenet、VGG16等深度学习网络避免了人工确定特征参数,在识别的准确率上相较于传统图像识别方法有较大提升,但相较于在VOC和COCO数据集上表现良好的R-CNN[14-17]、SSD[18]、YOLO[19-21]等目标检测算法的识别效果还有一定差距。R-CNN系列算法属于两阶段目标检测方法,先使用卷积神经网络产生候选区域,然后将候选区域进行分类和回归,其准确率高但处理效率偏低;SSD及YOLO系列算法属于一阶段目标检测算法,使用回归算法直接预测不同目标的类别与位置,满足实时性要求,但其准确率偏低。YOLOv3在前两个版本的基础上,优化了网络结构及参数,相较于其他目标检测算法,在识别准确率及识别速度的综合表现上具有较大优势。近年来深度学习技术发展迅速,但在煤矸识别领域尚未得到较好的应用,针对上述问题,结合煤矸识别的应用场景,笔者提出一种基于改进YOLOv3的煤矸识别方法,可对煤与矸石进行准确识别,并具有较快的识别速度。
1 YOLOv3算法
1.1 YOLOv3算法原理
YOLOv3吸收了当前优秀检测框架的思路,提出了DarkNet-53网络结构,如图1所示。

图1 DarkNet-53网络结构简图
图1中:DBL为卷积、BN(Batch Normalization)、Leaky ReLU三层的组合;DBL为卷积层的基本组件,DBL后面的数字为组件数量;Res为残差模块,上采样使用的方式为上池化,使用元素复制扩充的方法扩大特征尺寸;Concat操作即通道的拼接,和FPN中使用的元素相加不同,Concat是在上采样后将深层与浅层的特征图进行拼接。
由图1可见,该特征提取网络由52个卷积层和1个全连接层组成,DarkNet-53网络默认使用416×416×3的输入,DarkNet-53在基础网络中大量使用了残差网络连接,使得网络结构可以设计得很深,并缓解了训练过程中出现梯度消失的问题,增加了模型的收敛能力。通过上采样与Concat操作,将深层特征与浅层特征进行融合,最终输出3种尺寸的特征图用于后续的预测,多层特征图有助于对多尺度目标与小目标的检测。DarkNet-53网络与其他网络的性能比较见表1。
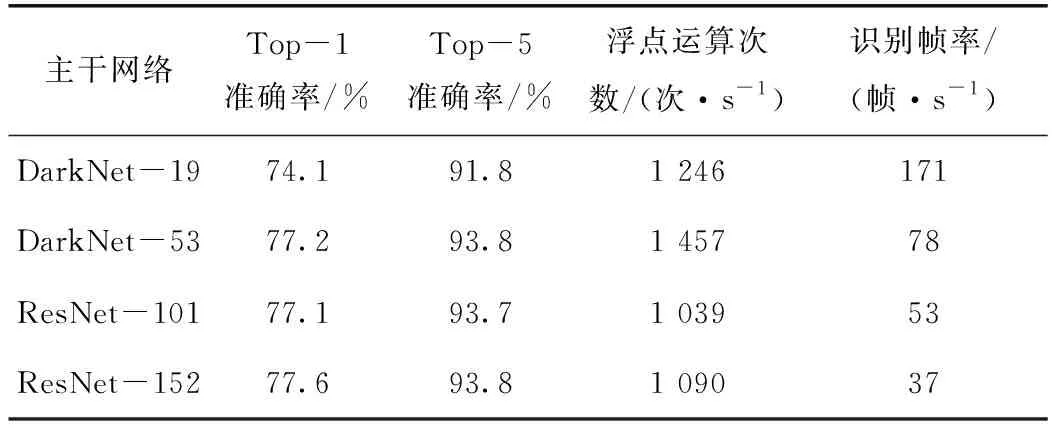
表1 DarkNet-53网络与其他网络的性能对比
由表1可知,DarkNet-53网络在Top-1和Top-5识别的准确率和ResNet-101、ResNet-152相当,网络对GPU的硬件资源利用率较高,浮点运算次数可达到1 457次/s。同时,DarkNet-53网络具有较快的检测速度,在DarkNet-19的基础上对网络性能进行了平衡,在满足实时检测要求的情况下,提高了识别准确率。
1.2 YOLOv3损失函数计算
损失函数表示的是模型的预测值与真实值的不一致程度,是判别模型是否收敛和优化模型的重要参数,损失函数的计算值越小,说明模型的预测值和真实值的差距越小,识别的准确率和鲁棒性越高。对于YOLOv3的损失函数原论文作者Redmon J没有明确的讲解,笔者根据YOLOv3论文实现的源码DarkNet归纳总结出YOLOv3的损失函数为:
(1)
式中:floss为YOLOv3的损失函数;λobj为目标系数,在特征图网格单元中存在目标时为1,若不存在目标则为0;wtru、htru是经过标准化及归一化后目标宽和高的真实值;rtru是真实位置;rpre是预测位置;c是预测类别值;ctru是真实类别值;Pc是预测类别概率值;Ftru是真实置信度;Fpre是预测置信度。
由于网络存在3个检测尺度,每个检测尺度的特征图网格单元存在3个预设的锚框,因此需要计算3×(13×13+26×26+52×52)即10 647个锚框的损失值。
2 改进的YOLOv3算法
2.1 网络结构改进
更深的卷积层数及更深的网络结构可增强对目标特征提取和识别的效果。由于煤和矸石在图像特征上非常相似,相较于COCO数据集和VOC数据集中的飞机、自行车、椅子、船等日常生活中的物体,煤和矸石的目标较小且两者之间的辨识度较低,结合算法本身的结构深度,笔者对YOLOv3算法的特征提取网络DarkNet-53进行了改进,在网络中增加 2个 1×1和3×3的卷积层。增加卷积层可提升卷积神经网络特征提取能力[22],具体体现在以下几个方面:降低卷积核通道维数与参数,简化卷积神经网络;在不损失分辨率的情况下增加非线性特征表达,丰富信息表现形式;在获得相同的感受野与捕捉更多的语言信息的同时,较小的卷积核可在加深网络的同时提高网络表达能力;较小卷积核的卷积层比较大卷积核的卷积层拥有更多层的非线性函数,可增强网络的泛化能力[23]。改进后的YOLOv3网络结构参数如图2所示。

图2 改进后的YOLOv3网络结构参数图
为了区分原始网络和改进后的网络,便于对比改进前后的网络性能,将改进网络结构后的YOLOv3网络命名为YOLOv3-A。
2.2 边界框回归损失函数改进
YOLOv3对每个边界框输出4个预测值,分别记为tx,ty,tw,th。通过公式(2)~(5)计算得到边界框在特征图上的中心坐标bx、by及宽高bw、bh:
bx=σ(tx)+cx
(2)
by=σ(ty)+cy
(3)
bw=wpetw
(4)
bh=hpeth
(5)
式中:tx、ty为网络预测的偏移量值,经过Sigmoid运算将其缩放到[0,1]区间;cx、cy为特征图网格单元左上角的坐标值;wp、hp为预设锚框映射到特征图中的宽和高;tw、th为网络预测的尺度缩放值,由于在预测时tw、th经过了log运算缩放到了对数空间,故需要经过指数运算进行转换。
通过位置偏移、缩放偏移值的预测,让预设锚框尽可能地接近真实框,通过置信度过滤掉低分的预测框,然后对剩下的预测框进行非极大抑制(Non Maximun Suppression, NMS)处理,得到网络最终的预测结果。边界框预测公式如图3所示。
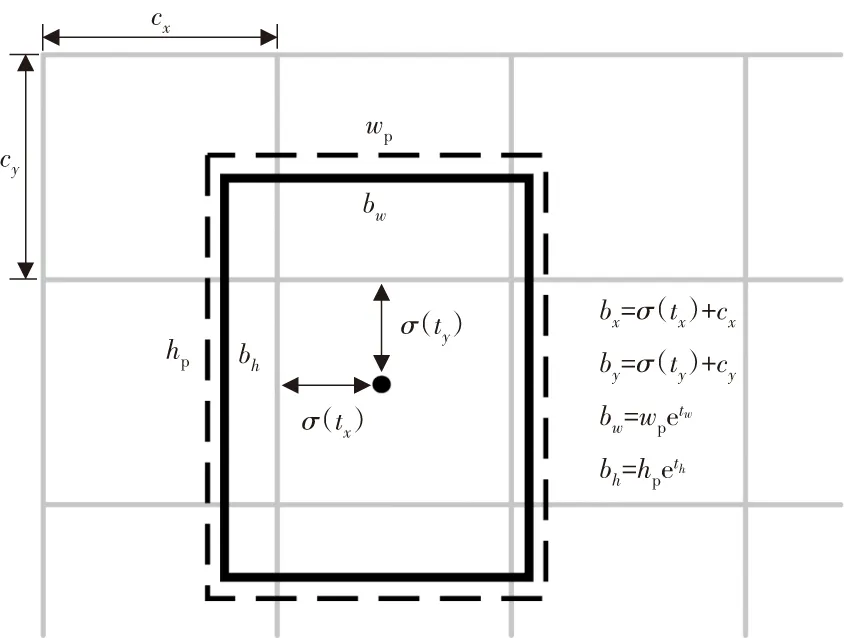
图3 边界框预测公式
由图3边界框(bounding boxes)预测公式可知,在不同大小的预测中,相同像素值的位置偏差,对小边界框的IOU的影响更大。而经过均方误差的计算,大边界框和小边界框相同尺寸的误差对损失值的影响却相同,这将影响到小边界框预测回归的精确度。在YOLOv3中增加了尺度修正,采用λm=2-wtruhtru来加大对小框损失的计算,这在一定程度上补偿了小框损失对损失值的影响,但这个修正参数值域范围小,不便于调整参数,而且对于不同尺度的特征值,这个补偿参数是相同的。由于特征值尺度越小,其特征像素点对应到原始图像的感受野就越大,所以小尺度的特征图用于预测较大的目标,而大尺度的特征图用于预测较小的目标。笔者针对不同尺度的特征图对损失进行修正,给出了修正位置回归的计算方法,如式(6)~(8)所示:
(6)
Fs=λs(1/(1+exp(wtru+htru)))
(7)
Fl=λl(1/(1+exp(-1/max(ws/wl,hs/hl))))
(8)
式中:Lerr为单个预测框的位置回归损失函数;Fs为目标尺度修正参数;Fl为特征图尺度修正参数;λs、λl分别为目标尺度和特征尺寸修正系数;ws、hs分别为输入图片的宽和高;wl、hl分别为特征图的宽和高。
修正参数的设计采用类似Sigmoid的计算方式将值缩放到[0,1]区间,为了平衡参数之间对损失值贡献度,本文取λs=4,λl=2。将改进网络结构和损失函数的YOLOv3网络命名为YOLOv3-M。
3 实验验证与分析
3.1 实验平台与模型参数
硬件平台为台式计算机,处理器为Intel Core i5-7500,主频为3.40 GHz,16 GB内存,1 TB 硬盘,显卡为NVIDA GeForce GTX1080Ti,11 GB显存。软件环境为Ubuntu 16.06 64位操作系统,编程语言为C++、Python,采用Darknet深度学习框架。
主要模型配置参数如下:网络输入尺寸width×height为416×416;网络输入通道数channels为3;动量因子Momentum为0.9;权重衰减因子Decay为0.000 5;学习率Learning_rate为0.001;批次样本数Batch为64;细分次数subdivisions为16;最大迭代次数Max_batches为50 200;学习率调整策略Policy为steps;学习率衰减因子Scales为0.1。
3.2 实验数据集
以煤、矸石为研究对象,采用矿用防爆摄像头(型号KBA127A)对煤矸图像进行采集,共收集到不同形态、不同光照、不同角度的煤矸图片约360张。其中将240张作为训练集,60张作为验证集,60张作为测试集,每张图像的煤矸数量为1~6个不等,采用YOLO_MARK工具对数据进行标注。
3.3 网络训练与评价指标
平均损失变化曲线如图4所示。

图4 平均损失变化趋势
由图4可知:训练开始时的损失函数值极大,随着训练迭代次数的增加,损失函数值逐渐减小,并逐渐趋于平稳;训练迭代到2 000次时,损失函数在0.14上下浮动,从平均损失的收敛情况来看,训练结果比较理想,此时停止训练,用训练生成的模型进行煤矸识别。
对煤矸识别准确率的评价需要同时考虑精确率(Precision)和召回率(Recall)[24],其定义如下:
(9)
(10)
式中:P为精确率;R为召回率;ntp为实际是煤或矸石并且被识别为煤或矸石的个数;nfp为实际是背景或其他物体却被识别为煤或矸石的个数;nad为所有检测到的目标数量;nfn为实际是煤或矸石但没有被识别为煤或矸石的个数;nagt为所有待识别的目标数量。
将模型识别出的目标置信度(属于煤或矸石的概率值)由大到小进行排序,逐个把目标加入进行预测,得到一组P、R序列,代入式(11)、式(12),求得Pa(Average Precision)值:
(11)
(12)

将煤和矸石二者的Pa值取平均值,作为识别准确率的评价指标。
3.4 结果与分析
采用改进网络结构和损失函数的YOLOv3-M对煤、矸进行识别,部分煤(coal)、矸(gangue)识别效果如图5所示。
由图5可知:YOLOv3-M网络可以较为准确地识别并定位煤和矸石,在不同背景、不同大小、不同形态、不同光照强度的情况下,也能进行准确识别,其鲁棒性、泛化能力较强。
原始网络YOLOv3、改进网络结构的YOLOv3-A,以及改进网络结构和损失函数的YOLOv3-M部分煤、矸检测效果对比如图6所示。

(a)YOLOv3

(b)YOLOv3-A

(c)YOLOv3-M
由图6可知:YOLOv3在光照条件好、煤和矸石的辨识度较高的情况下预测结果比较理想,而在光照较弱、煤和矸石的辨识度较低的情况下原始网络YOLOv3易出现漏检的情况;YOLOv3-A由于网络深度的提升,故比YOLOv3有更强的识别能力,可以识别出YOLOv3部分漏检的目标;YOLOv3-M在加深网络深度的情况下优化了损失函数,使得模型对不同环境下煤矸图像的适应性更强,在识别准确率和锚框精度上都优于YOLOv3-A和YOLOv3。
此外,使用基于传统识别算法的支持向量机SVM、高斯混合模型Gaussian Model,以及基于深度学习网络的Inception V3、VGG16、YOLOv3等识别算法,与笔者提出的算法进行对比,对比结果如表2所示。

表2 各种煤矸识别算法对比
由表2可知,煤矸识别网络YOLOv3-A、YOLOv3-M的单张图像识别时间与原始YOLOv3相当,在对煤矸识别的准确率上分别有0.9%和2.2%的提升;YOLOv3-M在识别速度上比其他类别的网络具有较大的优势,可以达到实时检测的目的。综上所述,基于改进YOLOv3的煤矸识别网络YOLOv3-M具有较强的适应性,较好地平衡了识别准确率和识别速度。
4 结论
1)加深神经网络结构,可加强对煤和矸石的特征提取性能,提升对煤和矸石的识别准确率。
2)改进边界框损失函数,可优化边界框回归过程,提升预测框的识别和定位准确率。
3)煤矸识别网络YOLOv3-M模型收敛速度快,对不同背景、不同大小、不同形态、不同光照强度的煤矸具有较强的适应性和泛化能力。
4)煤矸识别网络YOLOv3-M在识别速度和识别准确率上取得了较好的平衡,可满足工程应用的准确性、实时性要求。
