一种基于评分卡的健康测度方法:以桂林市民健康调查为例
2021-07-08尚长春雷璐华许远杏刘丙柒陈浩天
尚长春,雷璐华,许远杏,刘丙柒,苏 琦,陈浩天
(桂林理工大学 理学院,广西 桂林 541004)
《“健康中国2030”规划纲要》中提出,要把健康融入政策,推进健康中国建设,实现全民健康[1]。既往研究显示,我国大学生基本健康素养状况不容乐观,大学生中拥有健康素养的比例为14.0%,即便是体育类大学生健康素养水平也仅为16.19%[2-3]。研究证实,饮食习惯、作息时间、锻炼频率等生活方式对健康状况会产生影响[4-6]。自测健康评定级表(self-rated health measurement scale, SRHMS)虽提供了一套标准化量表系统,但涉及变量较多,无法量化每个变量对健康的影响程度,且随着时代进步,影响居民健康的新因素无法在标准化量表中具体体现,因此引进一套更加灵活多变的健康测度的新方法至关重要。本研究以桂林市为例,通过对不同居民群体的抽样调查,分析运动、饮食、行为习惯、睡眠等影响因素与健康状况之间的关系,并借鉴信用风险评分思想,提出采用健康评分卡对居民健康进行测度,为各级部门了解居民健康提供工具。
1 对象与方法
1.1 研究对象 在桂林市6个市辖区(秀峰区、叠彩区、象山区、七星区、雁山区、临桂区)采用无放回的不等概抽样方法,对样本地区常住人口进行调查,共发放问卷692份,回收有效问卷685份,有效回收率为98.99%。
1.2 调查工具 参考相关研究[7]自行编制调查表。内容包括:研究对象基本信息(性别、年龄、职业、文化程度)、身体健康状况、健康状况影响因素。身体健康状况采用自评的方法,从9个症状(容易头痛或者头晕、经常眼睛干涩、颈椎酸痛、肌肉酸痛、容易患上一般性感冒、心律不齐、容易胸闷、容易腰痛、肠胃不舒服)对健康状况程度进行衡量,将症状严重程度分为没有、很轻、中等、偏重、严重的5级制度量;健康状况影响因素从运动、饮食、行为习惯、睡眠4个方面共计20个子维度进行考量。
1.3 统计学方法 数据采用R语言进行处理,列联表数据采用χ2检验;采用Logistic回归分析健康状况影响因素。P<0.05为差异有统计学意义。
2 结果
2.1 调查对象一般情况 685名被调查对象中,男性324人(47.30%),女性361人(52.70%);年龄18岁以下36人(5.26%),18~25岁528人(77.08%),26~35岁91人(13.28%),36~50岁28人(4.09%),50岁以上2人(0.29%);学历初中及以下24人(3.50%),高中48人(7.01%),中专33人(4.82%),大专102人(14.89%),本科446人(65.11%),本科以上32人(4.67%);职业学生480人(70.07%),政府工作人员34人(4.97%),公司职员79人(11.53%),个体工作者31人(4.53%),文体工作者19人(2.77%),工人、农民22人(3.21%),其他20人(2.92%)。居民健康自评中,健康443人(64.67%),不健康242人(35.33%)。
2.2 健康状况单因素分析 对研究对象的运动、饮食、行为习惯、睡眠等影响因素与健康状况构成列联表,进行独立卡方检验,结果显示,各维度对健康状况的影响均具有统计学意义(均P<0.05)。见表1。
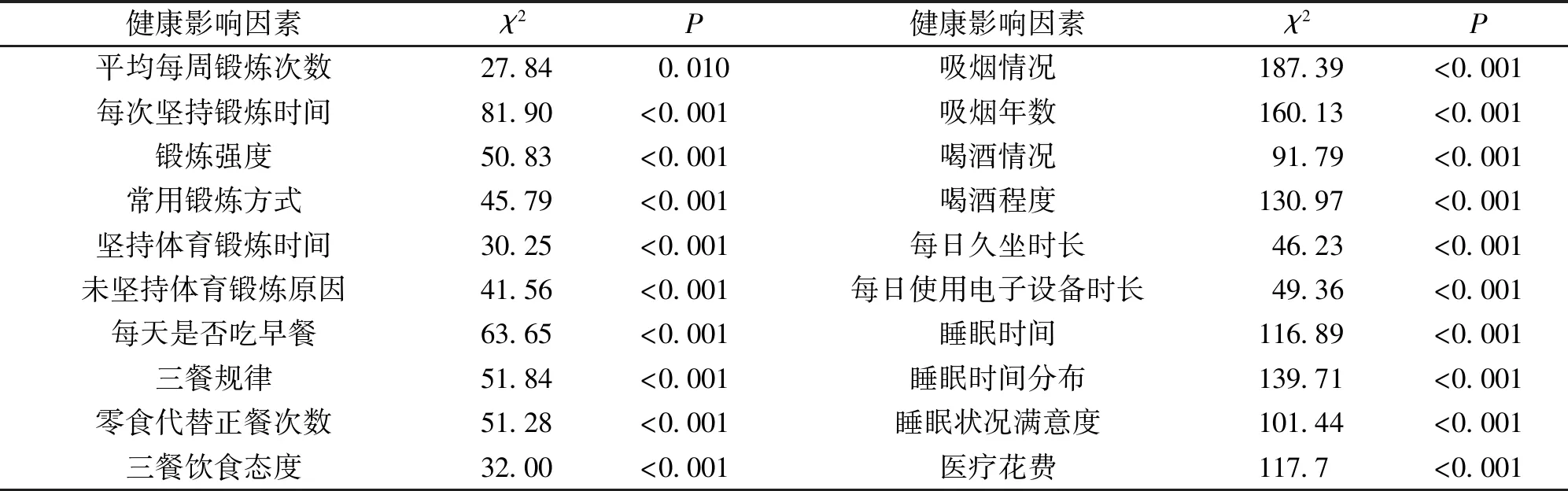
表1 健康影响因素与健康状况的独立性检验(n=685)Table 1 Independence test of health influencing factors and health status (n=685)
2.3 健康状况与生活方式的Logistic回归分析 对出现症状的严重程度测量采用5级李克特量表进行评估,当对被调查划分为健康与不健康2个极端情况,选择将量表中等、偏重和严重作为不健康,没有、很轻作为健康(不健康赋值“1”,健康赋值“0”);自变量为单因素分析中有统计学意义的变量,对自变量进行证据权重[8]变换。根据变换后的数据集依8∶2比例进行切割为训练集和测试集,训练集有548个样本、测试集137个样本,利用训练集构建Logistic回归模型,并采用后向剔除法对变量进行选择,结果显示,睡眠时间与健康状况正相关(P<0.05),饮酒程度、久坐时长、熬夜状况、睡眠状况满意度、医疗花费与健康状况负相关(均P<0.05)。见表2。

表2 Logistic回归模型估计系数Table 2 Logistic regression model estimated coefficients
2.4 健康评分卡的设计 借鉴消费金融领域的信用风险评分卡思想构建测度居民健康的评分卡,基于Logistic回归,评分卡模型简化成式(1):
(1)
其中A表示偏移量,B为不健康概率翻倍评分,即当模型系数不变的情况下,证据权重每增加一个单位,得分将增加一倍;log(odds)代表的是Logistic回归模型方程右侧的影响因素的线性组合。评分卡模型对于A和B的设定没有特殊要求,以实际情况而定。当Logistic模型仅包含截距项(即没有影响因素时),此时不健康与健康的对数发生比log(odds)=0.42时,设定开始得分score为300分,且不健康与健康的比例增加一倍,相应的得分便减少50分。故得式(2):

(2)
化简结果为式(3):
(3)
最后计算结果得A=330,B=72.13。然后将A和B带入式(1),当加入影响因素时(如喝酒程度),不同居民饮酒程度不同,则其log(odds)也不一样,因此会直接影响不同居民的最终健康评分。基于此,通过计算,健康评分卡如表3所示。

表3 健康评分卡Table 3 Health score card
根据健康评分卡计算居民健康得分,得分等于基础分加上各变量分数,得分越高说明该研究对象越健康,反之则越不健康。由于版面所限,随机抽取10名调查者的健康评分,不健康为“1”,健康为“0”, 为清晰展示健康组成员和不健康组成员的评分分布情况,画小提琴图如图1。经计算可知,不健康成员的平均得分为449.6分,健康成员平均得分为475.6分;不健康组的中位数评分为418分,健康组的中位数为485分。

图1 评分分布图Figure 1 Score distribution map
3 讨论
研究结果证实,饮酒程度、久坐时长、睡眠时间、熬夜状况、睡眠状况满意度、医疗花费是影响居民健康的因素(均P<0.05)。基于健康评分卡设计,提供如下健康促进措施:(1)少量饮酒(过过酒瘾)有助于健康(104分),但每次完全喝醉对身体有严重损伤(-51分);(2)每日连续长时间久坐办公大于6~8小时则对身体不利(6~8小时-16分,8~10小时-33分,10小时以上-42分),因此对于久坐办公人员应该适时活动,避免连续久坐;(3)应该保持充足的睡眠,睡眠时间大于6~8小时对身体有益(4小时以下-30分,4~6小时-8分);(4)尽可能在24:00之前睡觉,熬夜对身体有严重危害(0:00—2:00为-35分,2:00后为-69分);(5)尽量保证睡眠质量,睡眠质量不满意也会影响健康(不满意-15分,非常不满意-39分)。
本研究思路与SRHMS自评健康量表不同,而是寻找影响当前居民生理健康的因素并依托影响因素构建健康评分卡系统,从而估算当前的健康状态。与SRHMS相比,评分卡的优势在于不用构建标准化的量表系统,研究者仅需寻找制约所研究问题的关键因素(如研究居民的心理健康影响因素、研究居民的社会健康影响因素等),即可构建相应的评分卡得到结果(如心理健康评分卡、社会健康评分卡等),此法具有很强的普适性和灵活多变性,可以测量标准量表中不能测量的因素,为健康状况测度提供了有益补充。
不健康成员的最终健康评分普遍较低,健康成员的最终得分普遍较高,说明基于评分卡的健康测度具有合理性和实际意义。但研究仍发现不健康成员中存在高分者,究其原因可能是因为健康评分卡的构建依赖于Logistic回归模型,故回归模型的好坏以及变量的选择直接决定评分的合理与否,该研究进入模型的仅有6个变量:喝酒程度、久坐时长、睡眠时间、熬夜状况、睡眠状况满意度、医疗花费,且主要涉及日常行为习惯,其他相关影响因素不显著,说明问卷设计中相关变量设置有待优化。
