基于交通夜视场景的改进YOLOv3轻量化网络模型
2021-07-05郭飞
郭飞
(合肥工业大学电子科学与应用物理学院 安徽省合肥市 230601)
随着基于深度学习的目标检测在军事,工业,智能监控,人脸识别,自动驾驶等领域应用广泛,具有重要研究意义。
在2014年之前,目标检测算法处于传统目标检测算法时期,此后基于深度学习的目标检测算法飞速发展起来。基于深度学习的目标检测算法分为两种,一种为基于R‐CNN 系列模型的Fast R‐CNN[1],R‐FCN[2]等双阶段(two‐stage)目标检测算法,双阶段算法的主要特点是先产生一个目标的候选框,候选框包含有目标的位置信息,之后再对这些候选框分别进行分类和线性回归[3]。另一种目标检测是为单阶段(one‐stage)目标检测算法,例如:在2016年之后逐渐兴起的You Only Look Once(YOLO)系列[4],SSD 系列[5]等,YOLOv1 和SSD 都在2016年被发布。此后,越来越多的基于深度学习目标检测算法被提出。
1 YOLOv3网络模型简介
YOLOv3 的属于典型的单阶段结构。YOLOv3 的骨干网络为Darknet‐53,起到特征提取作用。整个网络结构以DBL(Darknetconv2d_BN_Leaky) 结构为基础,DBL 由1×1 与3×3卷积层,一个批量归一化层(Batch Normalization)以及一个激活函数Leaky ReLU 层组成。整个网络结构由三条支路分别输出13×13×255,26×26×255 以及52×52×255 三种尺度的图片。
2 改进YOLOv3网络模型
改进的YOLOv3 网络模型的思想有两点,一是将主干网络(Backbone)由Darknet53 替换成GhostNet 模块,另一个是将损失函数中的边界框损失函数(bbox_loss)由IoUloss 替换成GIoUloss。改进的网络模型结构框图如图1所示。
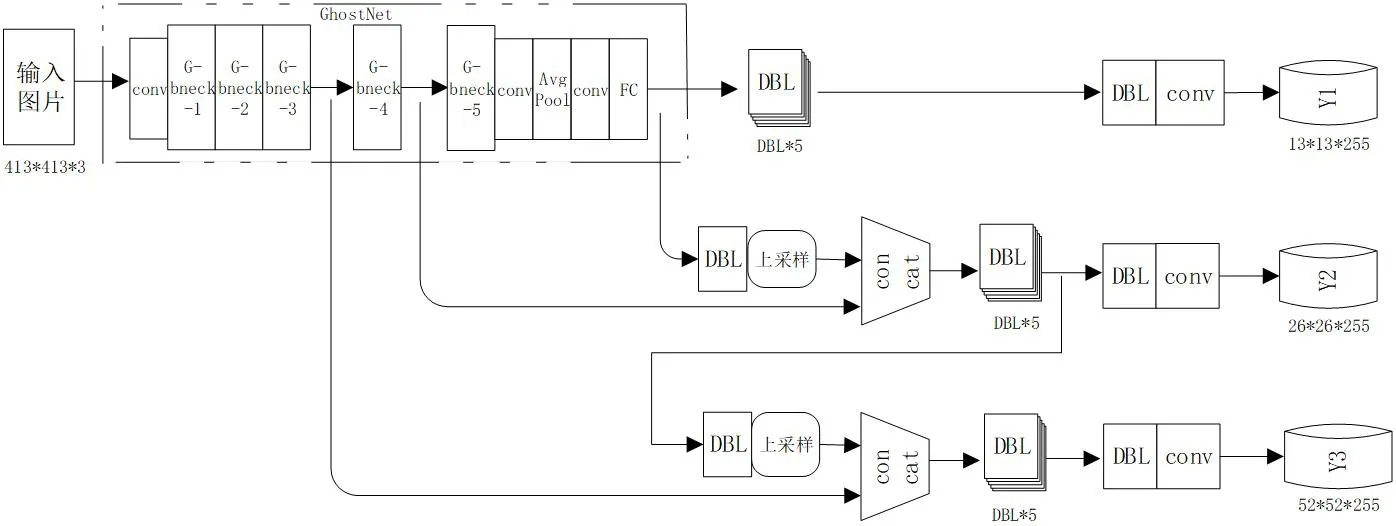
图1:提出的改进YOLOv3 的网络模型结构框图

图2:输入尺度为416 时GhostNet-GIOU-YOLOv3 在部分测试示意图
2.1 GhostNet特征提取器简介
GhostNet[7]特征提取网络是由华为诺亚方舟实验室的工程师们在2020年发表在顶级会议CVPR(IEEE Conference on Computer Vision and Pattern Recognition,即IEEE 国际计算机视觉与模式识别会议)的研究成果。其核心思想是以更少的参数来生成更多特征。其结构如图1 中GhostNet 特征提取器部分所示,核心模块是Ghost模块,在不改变输出特征图尺度大小的前提下,确保参数总量与计算复杂度得到有效降低。
同时,GhostNet 引入了SE 注意力机制模块,一共插入了7 个SE 模块在一系列G‐bneck 模块结构中。通过注意力机制,使得提取的特征针对性更强,特征利用更充分。
2.2 GIoUloss边界框损失函数
由于YOLOv3 所用的损失函数IoUloss 存在以下不足:预测框与真实框不相交时,IoU=0,此时无法反映预测框与真实框之间的距离大小(重合度);IoU 无法精确的反映两者的重合度大小,当预测框与真实框处在不同位置相交时,却可以有相同的IoU 值。因此,本文引入GIoUloss:

公式(1)中C 代表包围A,B 的最小矩形框。可得:当A,B重叠时,,此时,GIoU=IoU=1。当A,B 没有重叠时,且IoU=0。
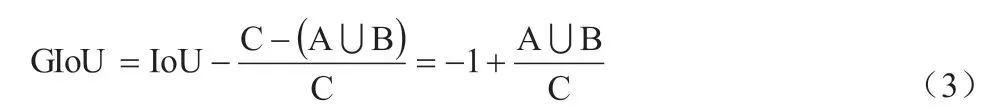
因此,A,B 不重叠且相聚无穷大时,GIoU=‐1,所以GIoU 取值范围是[‐1,1]。综上,IoU 只能反应预测框和真实框有重叠的情况,GIoU 既能反应预测框与真实框重叠的情况,也能反应不重叠的情况。
3 实验与分析
本节实验的实验平台是:Win10 操作系统,pycharm‐community‐2018.3.2,Anaconda3‐4.4.0,GPU 用的是6G 显存的RTX2060。
3.1 自制交通夜视场景数据集
实验数据集用的是自制交通夜视场景数据集,此数据集一共有6 类目标,分别是:卡车,汽车,摩托车,电瓶车,自行车,行人。数据集共有600 张图片,其中420 张用作训练集,180 张用作测试集,训练集:测试集=7:3,自制数据集的格式与VOC的数据集格式一致。
3.2 输入图片尺寸大小对于网络模型性能的影响
GhostNet‐SE‐GIoU‐YOLOv3轻量化网络模型,分别设置416和608 作为网络模型图片输入尺寸进行训练与测试实验。
由表1 可知,416 尺度相比608 尺度更有利于网络模型GhostNet‐GIoU‐YOLOv3 的目标检测的性能提高。

表1:GhostNet‐GIoU‐YOLOv3 在416 与608 输入尺度下对比
3.3 边界框损失函数对网络模型性能的影响
本节实验基于GhostNet‐YOLOv3轻量化网络模型,分别运用IoU,CIoU,DIoU 以及GIoU 四种边界框损失函数在自制交通夜视场景进行训练与测试实验。
由表2 可知,使用GIoUloss 比使用IoUloss,DIoUloss 或CIoUloss 更有利于性能指标的网络模型的提高。

表2:GhostNet‐YOLOv3 在416 尺度输入时四种损失函数下的性能
4 结论
提出了一种面向交通夜视场景的改进YOLOv3 目标检测轻量化网络模型GhostNet‐GIoU‐YOLOv3。在自制交通夜视场景下进行训练与测试,以416 为输入尺度的时,mAP 达到了95.3%,权重文件为89.9M,比YOLOv3 的权重文件324M 降低了72.25%。并验证了416 尺度比608 尺度更有利于改进的网络模型性能,以及GIoUloss 比IoUloss,DIoUloss 与CIoUloss 更适合用于改进的模型和自制交通夜视场景数据集。
