基于机器学习算法的金融公司信用风险预测模型
2021-07-05胡庆锋
胡庆锋
(深圳市企鹅网络科技有限公司 广东省深圳市 518000)
1 数据预处理
1.1 样本数据概况
本次研究的Z 公司主营业务是消费金融,这是一家互联网科技企业,于2014年正式运营。该企业利用网络信息技术和大数据风险控制技术为用户建立完整的信用档案,并且对银行等金融机构提供用户信用信息,帮助金融机构降低信贷业务风险,提高信贷绩效。B 公司属于国内著名的网络中文搜索企业,该企业经过长期的网络经营已经具备了大量的客户信息。利用这些数据匹配帮助B 公司建立账户数据信用风险模型。Z 公司借助信息共享机制分享B 公司建立的风险模型和相关的信息。经过协商之后,双方公司判定理想化用户指的是Z 公司信贷客户群体中并未出现逾期违约行为的客户,判定不理想用户指的是在Z 公司信贷客户群体中,信贷分期产品的用户还款超出了60 天规定时间,剩余的还款超出规定时间的1‐59天用户被称为中间样本。这种分等级的客户信用划分可以提高金融服务过程中对客户基本信息的识别能力。根据用户信息的时间指标划分用户样本种类,其中2019年5‐7月份申请用户群体定义为建模样本,2019年3月份申请用户群体定义为跨时间窗验证样本。本次信用风险模型建设项目属于Z、B 公司合作项目,其中前者负责用户信息收集和整理,后者负责数据模型建设。本次研究从B 公司建模负责人的角度出发分析模型建设相关数据的预处理和具体的模型建设问题。
对用户信用数据展开去重、筛选和匹配之后提取有用的用户信息,形成的样本定义和样本特征如下:
(1)y=1:定义的样本群体是分期产品还款超时60 天的客户样本,规模为1800;y=0 定义的样本群体是分期产品还款从未超时的客户样本,规模为5755。将上述数据带入逾期率计算公式得出:
1800/(1800+5755)=23.8%。
(2)特征时间窗口指的是2019年5‐7月份之间在Z 公司平台中提出申请的客户群体,按照客户申请时间点前一个月的时间段为基准,匹配B 公司中的对应客户信息,比如客户照片、其他B 公司产品的注册信息、客户反馈信息和论坛回复情况、LBS、电子钱包相关信息以及用户这一个月时间段中通过B 平台检索过的关键词等。
1.2 特征变量的筛选
模型中IV统计量单纯的值一个变量信息,信息价值(information value)的出现需要建立在相对熵的基础上。相对熵D(1|q)度量指的是当以p 为真实分布情况,以q 为假定分布情况,p 对q 的无效性。因此q 的编码可以在平均指标范围内比p 编码长D(p||q)比特。这一概念按照信息论的内容理解可以定义公式为:
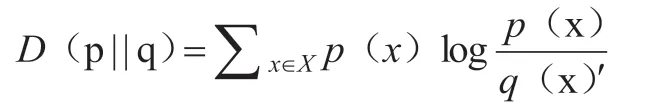
总结相对熵的特性可以得出如下内容:
(1)使用相对熵可以衡量两个正数函数之间存在相似性。
(2)相对熵数值大小可以表示两个函数或者是分布的差异性。比如当数值为0 的时候代表两个函数相同,或者是随机分布。当数值越大,代表着两个函数分布差异越明显。
计算IV 统计量首先应当区分变量类型。按照变量性质相近的变量值作为同一组,性质远的作为不同组出现。完成分组后需要分别计算每一组的违约率和履约率,分别记为p1i、p0i。那么相应组中的IV 表示为:
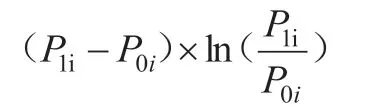
按照模型建设的思维分析,模型建设人期望p1、po存在明显的分布差异,但是如果p1、po两个指标的分布和建模人的期望相反,分布距离近,那么可以说明该变量并没有理想的区分用户样本种类的能力。假设p1、po两个指标的之间的差距较大,那么可以说明该变量用作区分用户样本种类的过程中具有理想的效果。为了将p1、po两个指标量化,则需要引入相对熵概念:
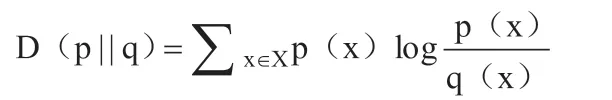
按照相对熵概念公式可以得出,p1、po两个指标的相互相对熵如下:
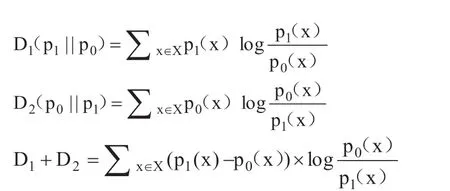
因此,每一组有:
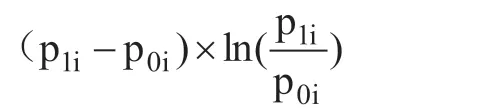
这也说明,使用IV 值可以衡量该变量影响目标变量的程度。按照机器学习建模的思维逻辑分析,计算所有变量的IV,并且选择超过0.02 的IV 值对应变量构建模型,或者是进行其他计算。
本次研究课题中,变量筛选的原有样本是B 公司的1795 个变量数据,对应Z 公司提供的客户身份信息、年龄信息和性别信息等,在这些变量数据的分组和IV 统计量的计算中,使用R 语言包的ctree()函数,通过数据处理得出,前20 位IV 统计量对应的变量信息作为重要变量,展示在表1 中。

表1:重要变量统计表
在本次研究课题中,以上述20 个变量为样本建模,根据模型判定下一步的操作流程。
2 模型构建与迭代
针对所有变量筛选,得出前20 位的IV 统计量对应变量,将其进行woe 转码,然后构建Logistic 回归模型。本次研究中模型中使用的相关参数和变量权重涉及到了商业机密,因此在此不做展示。统计该模型各样本集合的AUC 值得出表2 中的内容。

表2:简单模型框架(%)
通过表2 AUC 值分析可见,在本次构建的模型框架中,训练集和测试集的数据先对稳定,剩余一个集合和理想相差很大,相比测试集产生了7 个百分点的偏差。这也说明该模型需要在此基础上进一步优化,确保模型具有较高泛化能力。
本次研究中使用的GBDT 模型为用户原始搜索词,通过用户违约率在回归模型上添加新变量,提高初版模型的泛化能力。GBDT模型的样本建设方法如下:圈定Z 公司提供的2019年5‐7月份用户训练集数据,以覆盖率最高为指标筛选样本集合,得出底层搜索词2500 维,也就是按照搜索词的覆盖率为指标,采用降序方法排列,选择前面2500 维的信息构建模型。y 仍旧作为该模型的目标变量,其定义和初版模型的定义一样,因此得出,y=1 代表的是用户分期产品还款时间超时60 天的用户样本,y=0 代表的是用户分期产品还款时间从没有超过规定时间的用户样本。GBDT 模型的各参数如下:该模型中决策树设置2 层,设置250 次迭代。通过模型调试得出各集合的效果如表3 中的内容。

表3:搜索词模型效果(%)
通过表格模型效果数据可见,GBDT 模型中单纯的以搜索词为建模材料,这样的样本可以在一定程度上作为信用风险的判定标准。假如模型中增加违约率为自变量,那么该指标对信用风险的判定效果更准确。本次研究中收益函数的计算使用了XGBOOST 算法中的R 语言包得出如下内容:

通过这一公式可以通过决策树的变量数据判定每一次分裂造成的损失函数收益大小。也就是说,通过该公式可以判刑模型中变量是否重要。通过排序统计前十的变量信息如表4。

表4:搜索词模型重要变量(%)
分析统计的前十个变量搜索词可见,这些名词基本上都涉及到赌博、欺诈等性质,尤其是“捕鱼”属于近期网络赌博的一种。这一结果和前文中的假设一致,也就是通过用户网络搜索的关键词可以在一定程度上判定用户的个人喜好,能够了解用户的网络使用习惯。通过该模型也可以检测用户是否存在赌博和吸毒等可能性,模型的运算结果可以用于判定用户信用风险。但是该模型中使用的是近一个月的用户搜索词,也就是说,原始搜索词会随着时间发生变化,这就要求模型需要定期迭代,以确保搜索词的时效性。
在初版的模型框架中添加搜索词的结果,也就是用户违约率指标,这样可以从第一版模型的基础上构建第二版模型,通过两个模型的预测结果对比得出表5 中的信息。

表5:模型对比结果(%)
通过三种模型的效果对比可以发现,搜索词模型是另外两个模型的基础,在模型三个集合的效果对比中,该模型相对一初版模型效果更高。就算是跨时间验证集合中的数值较为66.15%,这一结果的AUC 值也符合可接受范围。搜索词和第二版模型比较可见,后者不管是AUC 还是Logistic 回归模型都具有更高的稳定性。这也说明,使用搜索词模型会因为时间因素造成预测的结果和用户真实结果产生偏差。经过综合性分析和各模型的效果对比,终板模型以Logistic 模型展现,并且上线运行。这一种模型在预测不同时间窗口的信用风险过程中,不管是AUC 值还是训练集的效果都不会出现太大的偏差,因此该模型的稳健性较理想,同时也具有很强的扩展能力。
3 总结
本次研究的亮点在于将Logistic 回归模型和GBDT 模型结合起来。经过对比、试验得出两种模型的结合才是最有效的预测模型,原因如下:研究中使用的两种模型均具有很强的稳定性,模型的运算效果理想。在参数求解的过程中,两种模型均使用了梯度下降的手段,尤其是二阶梯度下降中使用了Xgboost 工具,这使得算法效率更高,可以方便建模人更快建模,可以降低建模过程中时间因素对预测效果的影响力,符合现代网络信息更新速度快的特征。
