基于大数据聚类算法K-means的用户分群
2021-07-04苏进
苏 进
(中国联通安徽分公司,安徽 合肥 230000)
0 引言
运营商之间竞争愈发激烈,盲目的进行市场营销不仅成功率较低,而且浪费了大量的人力、物力资源,更有甚者会给用户带来负面感知,导致用户转网。同时运营商拥有海量的用户级数据,如何将用户数据深入分析,进而支撑市场营销及网络资源投放,成为运营商之间市场竞争的关键。
本文将基于大数据挖掘算法,将用户进行分群,不同的群体用户基于其特征进行不同的营销方案,通过精准营销克服盲目性,吸引新用户,留住老用户。同时锁定目标用户群进行有效网络资源投放,降本增效,获得更有利的市场渗透。
1 数据建模
商业营销方案中,聚类可以帮助数据分析人员根据消费者的自身属性、消费特征划分为不同的消费群体,并总结出每一类消费群体的消费习惯,进而支撑市场进行有针对性的营销方案。Clustering(聚类)目的即把数据分类,但是事先我们是不知道如何去分的,完全是算法自己来判断各条数据之间的相似性,相似的就放在一起。在聚类的结论出来之前,我们完全不知道每一类有什么特点,一定要根据聚类的结果通过人的经验来分析,看看聚成的这一类大概有什么特点。聚类是数据挖掘中使用较广泛的算法之一,可用来从海量的样本点中挖掘出一些深层信息,基于每一类的特点,可将注意力放在自己关注的特征上做进一步的分析。聚类分析是通过挖掘样本点之间的关系进而达到数据分组的目的,组内的样本点相似性越强,组间差异化越大,聚类效果越好。本文将采用聚类分析中最广泛使用的算法K-Means,将XX局点500万+用户进行聚类,并针对每一类的特点进行总结,进而支撑市场营销及网络资源投放。
K-Means是一种无监督的机器学习算法,也叫K-均值、K-平均,是聚类算法中的最常用的一种,概括是说是“物以类聚、人以群分”,算法运算速度快,适合连续型的数据,但在聚类前需要手工指定要分成几类。[1]
K-Means基本思想是将多个样本根据其属性划分为K个簇,初始K个簇的中心点是随机选定,再通过计算每个样本点到K个簇中心的距离,按照最近邻原则把每个样本点划分到K个簇中,然后将每个簇中所有样本点的坐标值进行平均,作为每个簇的新中心,如此进行迭代,直到簇中心的位置不再移动(即簇中心移动距离小于给定值),具体步骤如下:①将原始杂乱无章的样本点划分K个簇,簇中心随机选择。②计算每个样本点到K个簇中心的距离,将样本划分到距离最近的簇中心对应的簇中。③初始K个簇划分完成后,计算K个簇中所有样本点的坐标平均值,更新每个簇的簇中心。④重新按照②、③中的方法,将原始样本点进行簇划分,并且重新计算新的簇中心。直到新的簇中心与上一次的簇中心之间的距离不再变化,或者小于某个给定值,则聚类过程结束。
根据上述K-Means算法过程,我们在应用K-Means算法之前需确定几个关键点:距离如何计算;K值如何确定各维度单位如何换算。
(1)距离如何计算:K-Means算法中要迭代进行每个点到聚类中心的距离,距离的计算一般有图1两种方法:

图1 距离的计算方法
(2)K值如何确定:K值得取值不是固定的,一般是根据聚类的结果,评估是否满足业务分析的目的,可尝试多个K值,聚类的结果通过实践验证最优K值,或者可以把各种K值算出的SSE做比较,取最小的SSE的K值。
(3)各维度的单位必须要一致:如果K-Means聚类中选择欧几里德距离计算距离,数据集一定要进行数据的标准化(normalization),即将数据按比例缩放,使之落入一个特定区间内。[2]去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行计算和比较。
标准化方法最常用的有两种:
第一种:min-max标准化(离差标准化):对原始数据进行线性变换,是结果落到[0,1]区间,转换方法为X'=(X-min)/(max-min),其中max为样本数据最大值,min为样本数据最小值。
第二种:z-score标准化(标准差标准化):处理后的数据符合标准正态分布(均值为0,方差为1),转换公式:X减去均值,再除以标准差。
2 用户分群分析结果
选取用户消费特征、用户行为以及用户感知共11类特征,作为本次进行分群的特征向量,用户样例如表1所示:

表1 用户样例
针对XX局点550万+用户通过特征选取,异常数据筛除后,应用K-Means聚类分析方法进行全量用户分析,对原始数据本文采用min-max标准化方法进行线性变换,同时选取欧几里德距离作为距离依据,选择K=8时,分群结果如图2所示:

图2 分群结果
根据用户分群结果,针对不同特征聚类的用户结合市场营销方案,更易于提高营销成功率,同时可识别出高价值低感知用户进而投入更多的网络资源,比如当K=8为时,cluster_3用户喜欢投诉,爱好浏览网页,游戏时间中等,但游戏时延感知较差,该类用户的套餐较低,ARPU值中等,可建议针对该类通过赠送游戏类权益,提高用户感知,降低用户投诉量,同时该类用户更易引导提升套餐。
表2、表3是本次聚类结果以及从服务等级、权益、套餐以及网络资源四个方面提出的建议方案:

表2 本次聚类结果
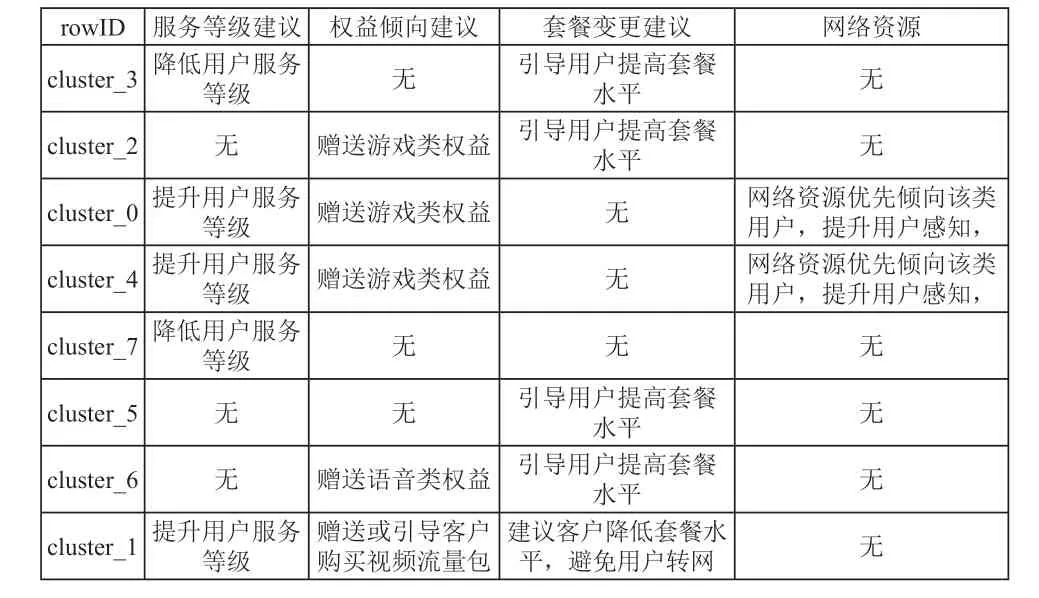
表3 建议方案
3 结束语
本文通过K-Means聚类分析方法对XX局点全量用户进行聚类分析,并根据聚类特征给予市场及网络侧的建议方案,支撑市场侧营销以及网络侧资源投放,但K-Means聚类算法本身也存在一定的缺陷性,比如:K值需要人为设定,不同K值得到的结果不一样;对初始的簇中心敏感,不同选取方式会得到不同结果;对异常值敏感;样本只能归为一类,不适合多分类任务;不适合太离散的分类、样本类别不平衡的分类、非凸形状的分类。这将导致聚类的不同特征用户适配为错误的营销策略,降低市场营销成功率。
