运用数据挖掘技术实现低功耗广域网组网方法的研究
2021-07-04金华滨
金华滨
(福州数据技术研究院有限公司,福建 福州 350200)
0 引言
根据全球移动通信系统协会发布的预测显示, 未来五年内低功耗广域网将超过传统的2G/3G/4G 移动网络成为物联网的主流连接方式。截至2018 年底,6.94亿物联网终端通过传统移动网络进行连接,仅0.66亿通过低功耗广域网方式进行连接。到2025年,这个局面将得到彻底的扭转,通过传统移动网络连接的物联网终端数量将增加至13亿,而通过低功耗广域网连接的终端数量将突破18亿。面对如此之快的增速,如何优化低功耗广域网的网络拓扑,在建设最少低功耗广域网基站的同时,提升其覆盖面积和网络质量,是亟需研究的问题。低功耗广域网按照工作在授权频段和非授权频段进行分类,NB-IoT、EC-GSM是工作在授权频段的技术,而Lora、SigFox是工作在非授权频段的技术。总的来说,低功耗广域网技术具有覆盖广、功率低的特点,单个基站的覆盖范围在几千米至几十千米之间,非常适合物联网的发展场景[1]。
1 系统模型分析
低功耗广域网多以星型拓扑的形式呈现,根据网络的覆盖情况,若干个物联网终端连接至一个低功耗广域网网关,网关的作用是负责接收各个终端上传的数据,并负责指定各条链路的回程连接,最终达到多链路上传和转发的目的。传统移动网络仍需要负责服务器与网关之间的通信链路,服务器则主要负责介质访问层网关的路由选择、连接进程确认等相关工作的处理。在低功率广域网的组网过程中,首先需要对实际测量数据库中的数据进行初级的筛选和分析,将那些包含大量重复或者含有缺省值的属性剔除,并使用统计学模型找出影响低功耗广域网网络覆盖质量的主要特征,然后将数据输入到人工智能学习模型中进行数据挖掘,最终获得最为合理的低功耗广域网基站布置图。当然这里所说的人工智能机器学习模型既包括预测模型,也包括规划模型。基站站点需要根据实际的覆盖情况和网络质量进行调整,模型计算出来的位置较为理想,一些后期干扰因素并未完全排除[2]。
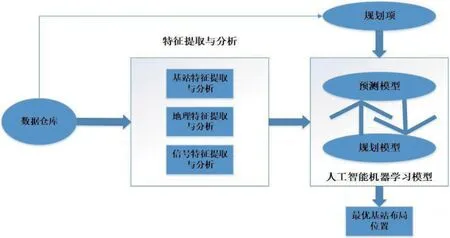
图1 基于数据挖掘的低功耗广域网组网规划系统框架图
2 低功耗广域网信号覆盖范围预测模型的建立
低功耗广域网组网最需要解决的问题是信号覆盖范围,重点解决信号覆盖盲区以及个别位置信号覆盖较差的问题。其中涉及到三方面比较重要的因素:一是基站自身的因素,如基站的功率额、天线的情况等;二是信号在传输过程中是否会受到干扰;三是干扰对覆盖范围的定量影响效果。
2.1 输入数据的特征提取
基站自身的属性包括基站的经度、维度和高度,还有其发射功率、天线挂高、基站名称、部署地区编号、最后连接的时间和地址、上行链路的PDU误码率、信噪比、信噪比盈余、扩频因子、信噪比与预定值之间的误差和网络状态。测试点的属性则包括下行链路接收信号强度指示器和传输一个SDU 的平均扩频因子以及测试点的经度和维度。在确定好需要提取的特征属性后,需要对得到的数据进行初步的去除和分析,一些重复性的属性需要被移除,比如经纬度信息在地理位置中已有所体现,不需要再单独列出。
2.2 信息覆盖范围的预测模型建立
这里采用了人工智能机器学习中常用的BRT回归算法来预测信息覆盖范围,该算法能同时组成多个决策树,具有更加优质的泛化能力,能提高预测模型的精确度。BRT模型可以用N棵决策树的加法模型,如式(1)所示:

3 低功耗广域网信号覆盖范围规划模型的建立
对于低功耗广域网信号覆盖范围规划模型的建立,一般使用均值聚类算法,该算法将数据库划分成x个点,并按照等距相似度的划分原则, 将原来的数据库A={a1,...,ax}转 变 为K个 簇 集 合B={b1,...,bk}。把最小化簇内位置误差平方和作为目标函数,即可得到每个数据点对定位簇中心的位置,从而获得基站建设的规划位置。当然数据挖掘的目的并不是简单的数据转换,而是需要在数据转换的基础上进行加权问题的处理,这样得到的目标函数会更加精确。运用数据挖掘的算法需要的输入包含若干个终端数据点的位置和所有基站初始点的位置信息数据,把二者作为聚类目标函数的初始化值。首先需要通过对距离进行归类来判定数据点的族类,待数据点分配完成后再通过迭代的方式实现对基站建设位置的调节。低功率广域网信息覆盖的范围以能覆盖位置到基站的距离为最大覆盖半径,期间会受到建木筑物阻挡、信号传播干扰等多方面的影响。另外还需要考虑距离对于信号质量的影响程度,所以对于本身覆盖较差的终端会赋予其对基站建设位置影响更大的权重,这样才能在多次的迭代过程中,让基站完美的覆盖这些信号盲点[3]。当然在实际情况中,经常出现通过加权算法仍然不能得到最佳组网结果的案例,就需要重复建立预测模型,并再次对基站的位置进行优化,直到满足最优的目标函数,从而得到覆盖范围最佳的网络拓扑实践。在完成最佳的网络拓扑设计后,还应通过仿真分析和性能评估的方法对其进行验证,方可将模型投入到实践中。
4 结束语
综上所述,本文提出了一种基于数据挖掘技术实现的低功耗广域网组网方法,其主要原理是通过机器学习的回归算法提取和分析已获得的数据值, 并通过均值聚类和多次迭代的方法找到目标函数的最优解,从而获得最佳的组网方案。在实际的组网过程中,每条链路的数据量均不相等,需要在今后的研究过程中加以考虑,以便能获得更精确的组网方案。
