人脸超分辨率网络(FSRNet)的改进
2021-07-03段燕飞王瑞祥咬登国
段燕飞 王瑞祥 咬登国 张 航
(成都信息工程大学 软件工程学院, 成都 610225)
从观测到的低分辨率图像重建出相应的高分辨率图像,这是在人脸图像识别过程中需要解决的一个基本问题。超分辨率(SR)技术对于大多数与面部相关的应用来说是非常重要的。单图像超分辨率方法[1]依赖于图像空间中的像素级均方误差(MSE)损失,可将输出像素级推向更接近真实的高分辨率(HR)图像。但采用这样的方法往往会产生模糊和平滑的输出,缺少一些纹理细节。作为普通图像SR的特殊情况,面部图像中存在特定于面部的先验知识,这对于面部SR是关键的,而对于普通图像SR则不可用[2]。如面部对应字段可以帮助恢复准确的面部形状[3],而面部成分则可以显示丰富的面部细节[4]。
人脸超分辨网络(FSRNet)由粗糙和精细SR网络构成,有4个模块。通过分析FSRNet各模块的作用,发现最后输出的SR图像在各项硬指标和视觉质量上存在不足,原因在于粗糙SR网络模块和损失函数设计上还有欠缺。FSRNet方法过度集中在面部标志的定位上,没有充分考虑标志周围区域的面部属性。我们针对这两个部分的问题,对FSRNet进行了改进:首先,通过引入面部注意力损失,将注意力集中在预测目标区域周围的面部细节上;其次,鉴于FSRNet把插值后的低分辨率图像输入网络而带来了复杂的计算开销问题,我们改为输入低分辨率图像,然后引用转置卷积(Deconv)实现上采样操作,以降低复杂度;其三,因粗糙SR网络生成的SR图像直接影响先验估计的准确性,我们采用渐进的训练方式,先单独训练粗略SR网络,再训练剩余网络部分;同时,为了使粗糙SR网络能输出较高质量的图像,在两步训练中都增加面部注意力损失和热图损失,并进行对抗性损失训练。运用文献[5]提出的压缩版人脸对齐网络(FAN)来提取人脸关键点热图,用于监督训练。
1 FSRNet工作原理
1.1 网络结构
FSRNet的整体结构如图1所示,包括粗糙SR网络(Coarse SR Network),精细SR编码器(Fine SR Encoder),先验估计网络(Prior Estimation Network)和精细SR解码器(Fine SR Decoder)共4个模块。用插值算法将尺寸为16×16×3低分辨率图像放大至目标图像尺寸128×128×3后再输入到网络中,最后的输出是其SR图像。输入图像首先经过粗糙SR网络,不改变图像的尺寸,目的是预先快速生成一个粗略的SR图像,这样先验估计网络才能提取到相对准确的人脸关键点和解析图。若没有粗略的SR网络模块,先验估计网络无法直接从低分辨率图像中提取到有用的先验信息。经过粗糙SR网络输出的粗略SR图像,被送入先验估计网络和精细SR编码器。先验估计网络的任务是预测人脸解析图和关键点热图,并对输入图像进行降采样处理。残差网络(ResNet)已在SR中得到成功应用,精细SR编码器可利用残差块进行特征提取,将特征下采样为64×64像素。先验特征和图像特征串联起来作为精细SR解码器的输入,精细SR解码器将特征上采样到128×128像素,然后恢复最终的HR图像。
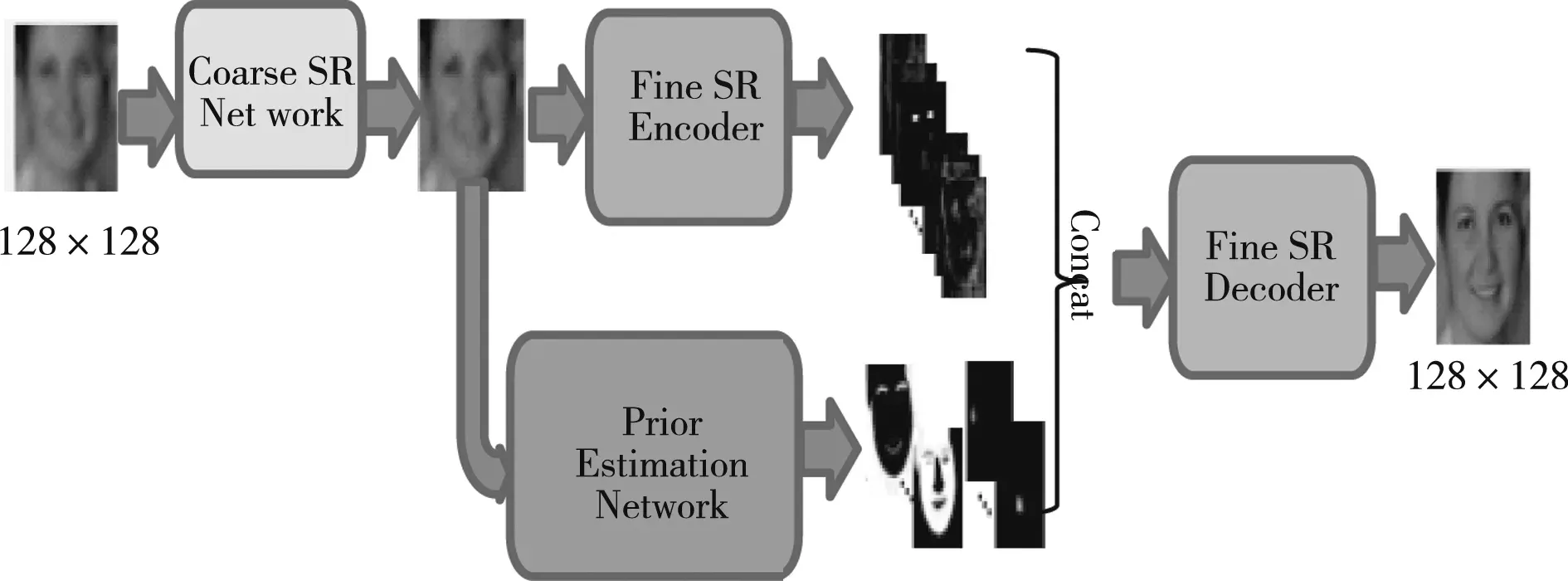
图1 FSRNet网络结构
1.2 目标函数
低分辨率的输入图像,可能对于先验的估计而言太模糊,因此首先构建粗略的SR网络,以恢复粗略的SR图像。以x表示低分辨率输入图像,y和p分别表示恢复的高分辨率图像和FSRNet估计的先验信息。
yc=C(x)
(1)
式中:C表示通过粗糙SR网络从低分辨率(LR)图像x到粗略SR图像yc的映射。
然后,将yc分别输入至先验估计网络P和精细SR编码器F。
p=P(yc),f=F(yc)
(2)
式中:f是由精细SR编码器F提取的特征。
在编码之后,图像特征f和先验信息p进行Concat连接,输入到SR解码器D,恢复最终SR图像。
y=D(f,p)
(3)

(4)
式中:Θ表示参数集;λ指先验损失的权重;y(i)和p(i)分别指第i个恢复的HR图像和估计先验信息。
2 对FSRNet的改进
2.1 粗糙SR网络改进
FSRNet将放大后的低分辨率图像输入到网络中,因输入图像尺寸较大,计算开销就较大,假设图像要放大n倍,计算复杂度则上升到了n2。我们减小输入图像的尺寸,直接输入16×16像素的低分辨率图像。在粗糙SR网络,最后采用转置卷积(Deconv)把图像尺寸放大为128×128×3。FSRNet在粗糙SR网络中使用了3个残差块来提取特征,这里对此不做改变。然后,在最后增加一个转置卷积层放大图像。改进后的粗糙SR网络结构如图2所示。
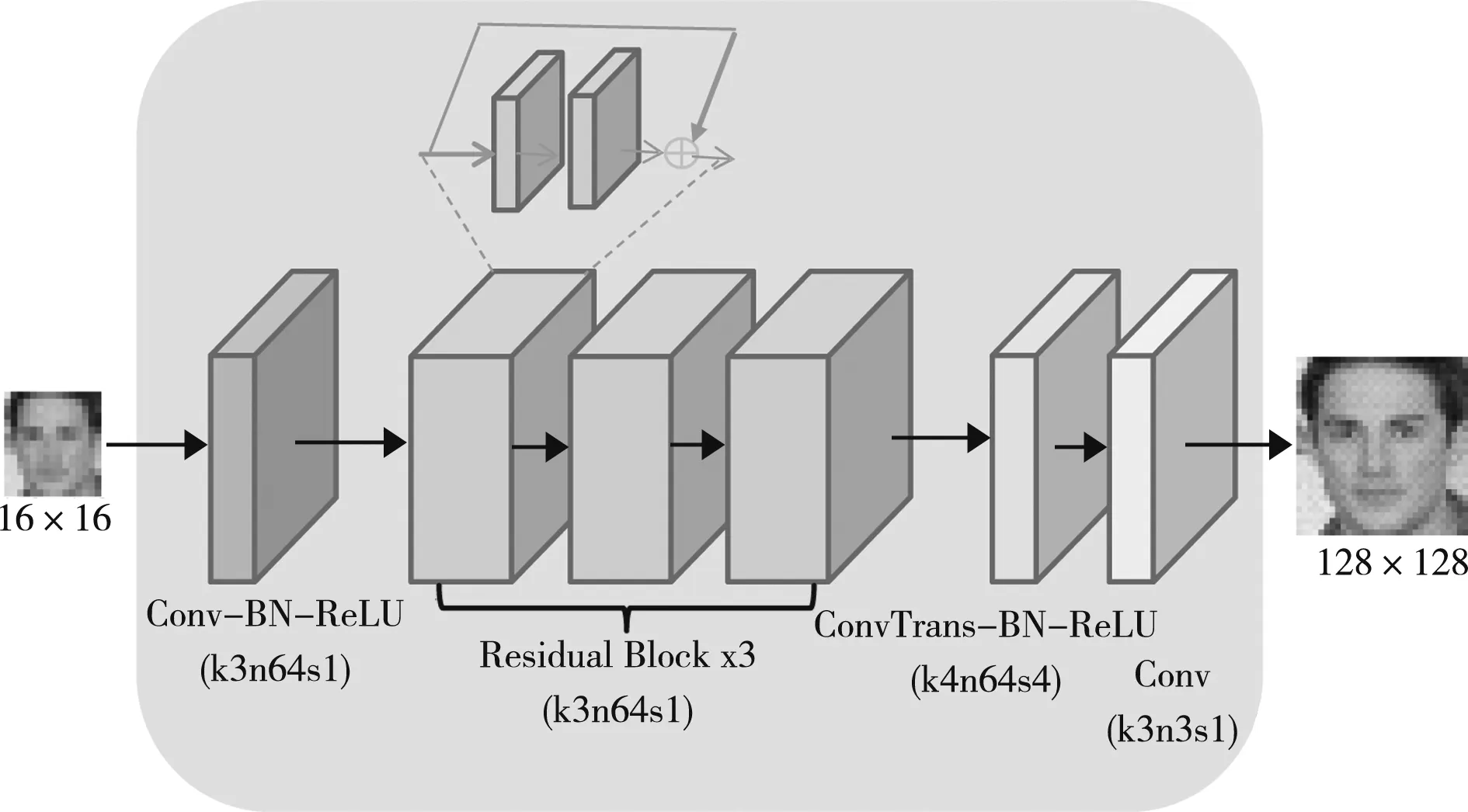
图2 改进后的粗糙SR网络结构
2.2 两步训练法
FSRNet是端到端的训练,这样可降低训练的复杂度,但粗糙SR网络训练的结果却并不好,得到的粗略SR图像质量差,面部结构并不清晰,存在伪影。因此,我们提出两步训练法:先单独对粗糙SR网络进行训练,然后再训练剩余网络部分。按照此方法,可以对人脸关键点区域施加强约束,更精确地还原面部细节。为了让改进后的网络拥有更好的性能,我们采用渐进式训练法[6-9],并且加入对抗损失训练,以生成更加逼真的面部细节。为了获得面部注意力损失信息,采用文献[5]提供的面部对准网络(FAN)提取热图。
改进后的网络结构如图3所示,它由生成器网络(人脸SR网络)和鉴别器网络组成。生成器网络中,除了粗糙SR网络模块,其余部分基本和FSRNet一致。鉴别器网络由卷积层(Conv)、平均池化层(AvgPool)和Leaky ReLU激活函数组成。
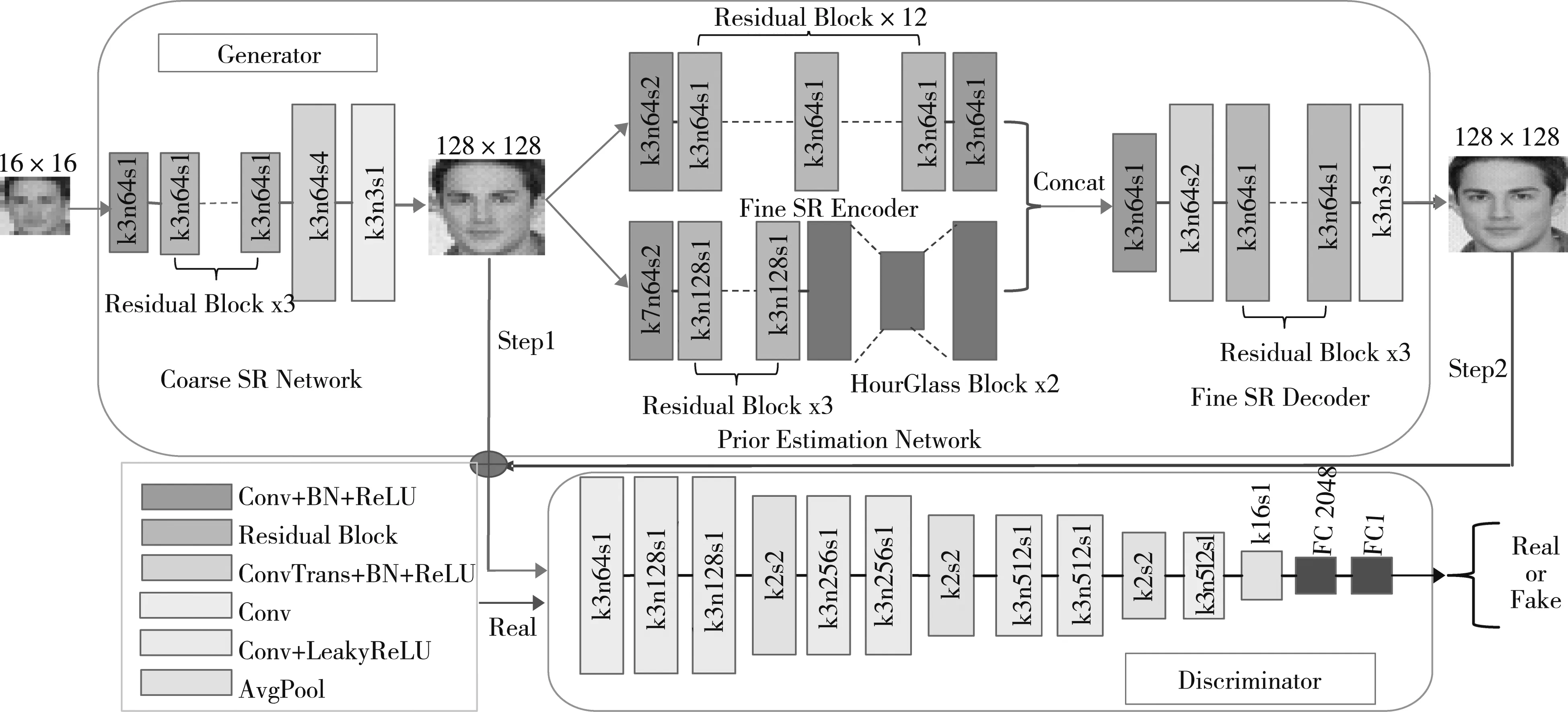
图3 改进后的网络结构
第一步,对粗糙SR网络进行训练,并学习将图像放大4倍。来自生成器的这些4倍放大图像,经过一个卷积层后送入鉴别器相应部分。最后,将输出图像与目标图像进行比较。
第二步,将第一步的输出图像送入剩余的网络部分,进行最终的SR训练。最后的SR输出送入鉴别器,与相应的目标图像进行比较。
2.3 目标函数构建
为了生成面部关键区域的热图,采用人脸对齐网络(FAN)提取人脸热图,进行监督训练。
2.3.1 面部注意力损失
在训练阶段,引入面部注意力损失,以便更好地恢复面部标志相邻区域的属性。把包含关键点位置信息的关键点注意力热图M*和放大图像与目标图像之间的距离逐元素相乘,使面部SR网络把注意力集中在面部关键区域周围的面部细节上。面部注意力损失定义为:
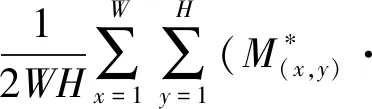
(5)
式中:Lattention指面部注意力损失;G代表生成器,即人脸SR网络;IHR是真实的高分辨率图像,ILR是超分辨率生成的图像。
在第一步训练时,G表示为粗糙SR网络G1;第二步训练时,G代表除C之外的其余网络G2。HR和LR分别指目标人脸图像和输入的图像。关键点注意力热图M*是从目标面部图像生成的目标热图M的各个通道最大值。为了补偿界标之间的差异,热图M归一化为[0,1]。热图M的尺寸为N×W×H。其中,N指关键点的数量。在无特别说明时,W和H是指图像的宽度和高度,均为128像素。为了使注意力集中在具有足够信息的图像上,在两步训练中均加入面部注意力损失。
2.3.2 MSE损失
使用逐像素均方误差(MSE)损失,最小化HR和SR图像之间的距离。
(6)
式中:Lpixel指均方误差损失。
2.3.3 先验损失
先验估计网络P负责预测人脸先验信息,通过最小化生成的人脸先验信息和数据集提供的目标人脸先验信息之间的距离,为SR网络提供特定于人脸结构的先验信息。先验损失定义为:
(7)
式中:Lprior指先验损失;网络P的输出是经过降采样的,所以W和H均为64像素;ILR是粗糙SR网络输出的图像,IHR是真实高分辨率图像。
2.3.4 感知损失
使用预训练的卷积神经网络VGG16的高级特征(即relu5_3层的特征),引入感知损失[10],可以防止生成模糊和不真实的面部图像,并获得更逼真的HR图像。

φ(G(ILR))(x,y))2
(8)
式中:Lpercepual指感知损失;φ指提取高级特征的VGG16网络。
2.3.5 对抗性损失
生成对抗网络(GAN)在超分辨率方面表现出了强大的力量。与基于MSE的深度模型相比,GAN在生成任务方面取得了成功,并被证明可以有效地恢复高保真和具有逼真视觉效果的图像。其关键思想是:使用判别网络区分超分辨图像和真实高分辨率图像,并训练SR网络欺骗辨别器。
为了生成逼真的高分辨率人脸图像,我们引入对抗损失来生成逼真的面部图像。建立一个鉴别器D,运用WGAN的成功经验来稳定训练过程。在WGAN中,损失函数定义为目标IHR~Pr分布与生成的图像ISR~Pg分布之间的Wasserstein距离[11]。为了进一步提高训练的稳定性,我们采用WGAN-GP中提出的Gradient Penalty项[12],强制了鉴别器的Lipschitz - 1条件。因此,损失函数的表达式为:
LWGAN=EIHR∶Pr[D(IHR)]-EISR∶Pg[D(ISR)]+
(9)
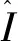
2.3.6 热图损失
通过最小化生成图像和目标图像的热图之间的距离,改善面部图像的结构一致性[13]。热图损失函数描述如下:
Fd(G(ILR))(x,y))2
(10)
式中:Lheatmap指热图损失;N是关键点的数量;Fd指预训练的热图提取网络,即人脸对齐网络(FAN)。
训练分2步进行:第一步训练粗略SR网络,第二步训练剩余网络部分。具体的训练损失表示如下:
Lstep1=αLpixel+βLperceptual+γLWGAN+
λLheatmap+ηLattention
(11)
Lstep2=αLpixel+βLperceptual+γLWGAN+
λLheatmap+ηLattention+εLprior
(12)
式中:Lstep1是第一步训练的损失函数;Lstep2是第二步训练的损失函数;α、β、γ、ε、λ、η是权重。
3 实验及结果分析
3.1 实验准备
选择数据集CelebAMask-HQ[14]进行实验,这是一个大规模的面部图像数据集。从中选择30 000张高分辨率面部图像,每个图像具有对应于CelebA的面部属性的分割蒙版。图像尺寸调整为512×512像素,手动标注为19类,包括面部所有组件,如皮肤、鼻子、眼睛、眉毛、耳朵、嘴巴、嘴唇、头发、帽子、眼镜、耳环、项链、脖子和衣服。我们剪裁图像的面部区域,将其尺寸调整为128×128像素,作为目标图像,并进行双线性下采样到16×16像素,作为LR输入。用29 000张图像来进行训练,将剩下的 1 000张图像用来对照评估。
直接输入下采样的16×16像素的低分辨率图像,经过粗糙SR网络后的输出就与高分辨率图像尺寸相同。采用PyTorch框架来实现SR网络,使用Adam优化器以2.5×10-4的学习率和16的批量大小来训练网络。
3.2 消融研究
3.2.1 损失函数的影响
为了验证引入的面部注意力损失、热图损失和感知损失的有效性,做了3个实验来进行消融研究。以平均峰值信噪比(PSNR)和结构相似性(SSIM)来评估各个损失的影响。
表1中的数据,显示了引入不同损失在数据集上的实验结果。第一次实验,是只有像素损失和感知损失并进行对抗性训练的结果;第二次实验,加入了热图损失;第三次实验,引入了面部注意力损失。可以看到,在加入面部注意力损失和热图损失后,PSNR和SSIM值都有明显上升,说明改进后的方法生成的SR图像质量更高。
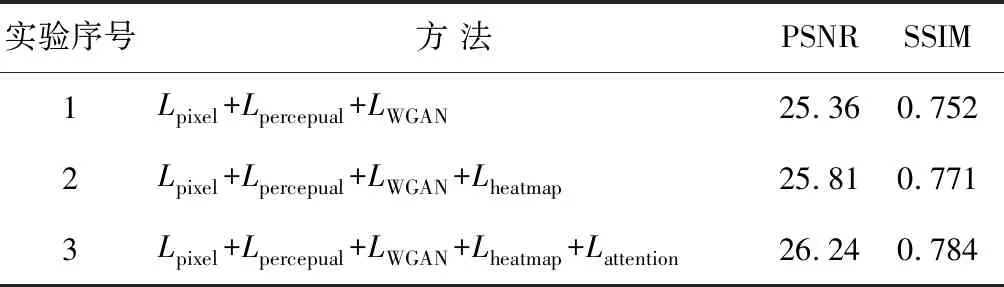
表1 消融研究的PSNR和SSIM值
3.2.2 粗糙SR网络的影响
为了验证改进后的粗糙SR网络的性能,将粗糙SR网络改进后的实验结果与原FSRNet的实验结果进行对比。我们输入的低分辨率图像像素是16×16,原FSRNet的则是128×128,所以粗糙SR网络改进后的计算复杂度较之前降低了42倍。实验结果显示,在粗糙SR网络改进前,PSNR和SSIM值分别为24.16、0.667;在粗糙SR网络改进后,PSNR和SSIM值分别上升为24.92、0.702。这说明改进后的粗糙SR网络性能,优于改进前的性能。
3.3 不同方法的测试结果
运用不同的人脸超分辨率方法,在CelebAMask-HQ数据集上进行测试。实验结果显示,按PSNR和SSIM指标来评价,我们改进后的方法(Ours)都具有一定的优势(见表2)。原FSRNet生成的SR图像,存在伪影和部分模糊的面部成分;采用我们改进后的方法,能够恢复精确面部特征,具有更逼真的面部视觉效果(见图4)。
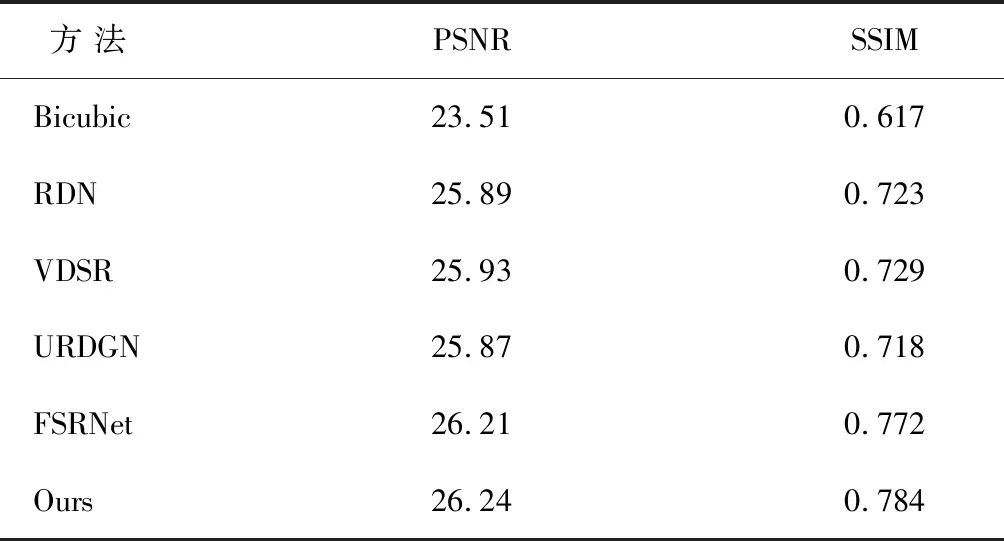
表2 不同方法的PSNR和SSIM值

图4 不同方法下生成的SR图像对比
4 结 语
我们改进后的人脸超分辨率网络,保留了原有的先验估计网络,将其用于为精细SR网络提供人脸先验信息,以生成更逼真的面部细节。通过改进粗糙SR网络,减小输入分辨率,在网络最后放大图像,降低了计算复杂度;通过加入面部注意力损失、热图损失和对抗性损失训练,提升了网络性能。实验结果证明,这种改进有助于生成更加逼真的粗略SR图像,使先验估计网络能预测更准确的先验信息。采用两步训练法:先单独训练粗糙的SR网络,得到更好的SR图像;然后再训练剩余部分,从而生成精细的SR图像。运用改进的方法,可以生成面部细节更加清晰的高质量人脸图像。
