基于步态序列的跨视角步态识别
2021-07-03李凯曹可凡沈皓凝
李凯曹可凡沈皓凝
(1.河北大学 网络空间安全与计算机学院,河北 保定 071002;2.湖南大学 电气与信息工程学院,湖南 长沙 410082)
步态识别是一种很有潜力的生物识别技术,具有在远距离、低分辨率情况下完成识别对象的特性,与传统的指纹识别、虹膜识别、人脸识别不同的是,该方法无需被识别对象的配合即可完成身份验证,因此,步态识别技术在身份识别、安检监控和预防犯罪等领域具有广泛的应用前景.然而,由于步态识别往往受到很多因素的干扰,因此其识别性能将会显著降低,这些因素主要包括步态序列的采集角度,被识别行人的服装、鞋子和背包,其中对识别准确率干扰较大的是采集角度的变化,如图1所示,图1a和图1b的步态轮廓图拍摄自同一个行人的0°和90°视角,图1c的步态轮廓图拍摄自不同行人的90°视角.步态识别的难点在于同一个行人在不同视角中所拍摄步态轮廓图像间的差异远大于不同行人在相同视角下拍摄的步态轮廓图像间的差异.

图1 行人步态轮廓Fig.1 Pedestrian gait silhouette
为了克服视角变化对识别准确率的影响,研究人员提出了不同的方法,它们主要分为3类:1)试图从行人的步态图像中提取行人的三维结构[1-2],此方法对环境具有严格的要求,同时计算复杂度较高;2)使用手工提取特征的方式获取一些与视角无关的特征[3],然而,此方法在视角变化较大的情况下,步态识别准确率会大幅下降;3)使用转换或投影方法将步态特征在不同视角中进行转换.例如,Makihara等[4]提出的视角转换模型(view transformation model,VTM)能够将步态特征从一个视角转换到另一个视角.Kusakunniran等[5]提出了使用截断SVD 的方法进一步克服视角转换模型的过拟合问题.Hu等[6]提出与视角无关的判别投影方法(ViDP),通过迭代策略并使用线性投影来提高多视角步态特征的判别能力,且在识别过程中无需获得被识别行人的视角信息.Yu等[7]提出使用身份判别器来保证GANs生成的轮廓图包含行人的身份信息.同时一些学者提出了基于卷积神经网络(convolutional neural network,CNN)的步态识别方法[8-9].为了保留更多的动态信息,Castro等[10]提出了使用CNN 从步态图像的光流分量中学习高级特征描述符.Wolf等[11]将光流法和3D 卷积神经网络相结合,使得模型在视角跨度较大时仍具有较好的准确率.为了利用步态序列中的时间信息,Feng等[12]将CNN 和长短期记忆网络(LSTM)相结合,使得CNN 产生的人体姿态标记传入LSTM 进而完成分类.度量学习通过计算样本特征之间的相似度或距离来判断相似性.Tong等[13]提出使用三元组损失函数(triplet loss)训练卷积神经网络,在每轮迭代中,通过对较难分类样本的采样来提升模型对视角变化的鲁棒性.Huang等[14]将注意力机制和三元组损失函数(triplet-loss)引入到卷积神经网络中,利用嵌入学习在OU-LP和OU-MVLP数据集上获得了较好的实验结果.为了提高跨视角步态识别的准确率,本文研究了基于步态序列的跨视角步态识别,提出了一种基于步态序列的跨视角步态识别模型,该模型由1个编码器、1个生成器和2个判别器组成,编码器主要对步态序列进行编码,为了保证获取的步态特征有效,通过判别器对生成器生成的包含特定步态信息与时间信息的图像,利用连续帧判别损失以及三元组损失对模型进行修正.
1 生成式对抗神经网络与跨视角步态识别模型
1.1 生成式对抗神经网络GANs
生成式对抗神经网络(GANs)[15]是一种新颖的数据分布建模方法,它主要由生成器G和判别器D构成.其主要思想是利用生成器从分布z~Pz产生一个假数据,而判别器D是将假数据从真实的数据中区分出来.假设真实数据的分布是x~Pdata, 生成器G和判别器D利用式(1)通过迭代技术进行优化
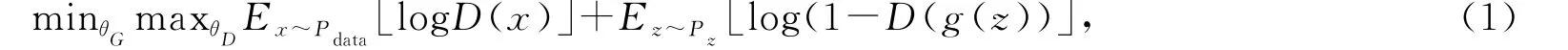
其中θG和θD分别是生成器G和判别器D的参数.由于原始GANs的训练往往受到低质量、不稳定和模型崩溃等因素的影响,因此,学术界提出了许多GANs的变种来解决这些问题[16-19].
1.2 跨视角步态识别模型
为了提取行人的有效步态特征,较常用的方法是使用步态能量图进行提取,通过对二值轮廓图像取平均以此来得到步态特征的表示,然而,这种方法却忽略了步态周期中的动态信息.为了有效保留步态中的时间信息,进一步提高跨视角步态识别的准确率,本文研究了基于步态序列的跨视角步态识别,也就是说,为了提取步态中的时间信息,将步态序列作为模型输入,以此提取步态特征.
假设给定一个具有N个行人的步态序列数据集{Si},其中每个行人的标签定义为yi,i∈{1,2,…,N}.对于行人i,定义其步态序列为取自某视角下的一组连续步态轮廓图像,Si={xij|j=1,2,…,nf},即Si代表行人i的一个步态序列,另外,定义S+i表示与样本序列Si标签相同的样本序列,S-i表示与样本序列Si标签不同的样本序列,提出的步态识别模型如图2所示.该模型主要由编码器、生成器和判别器构成.编码器将步态序列转换为潜在空间中的步态特征向量,同时使用triplet-loss损失函数确保具有不同标签的样本在潜在空间中的分布尽可能远离;生成器G将一组潜在空间中的步态特征向量生成固定视角的步态轮廓序列;判别器主要由2部分组成,即真伪判别器和步态帧连续判别器,它们分别用于判断生成序列^S的真伪和生成的步态序列的连续性.
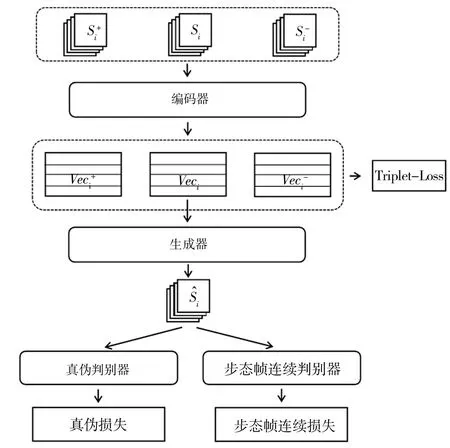
图2 步态识别模型Fig.2 Gait recognition model
2 基于GANs的步态识别模型
2.1 编码器
为了抽取与视角无关的步态特征,在步态识别模型中,编码器使用了卷积神经网络对步态序列进行编码,它主要由4个卷积层和1个全连接层构成,其输入为1个n×64×64的步态图像序列,其中n是步态序列的帧数,通过编码器将步态序列映射到潜在空间,该编码器的结构如图3左半部分所示.
假设Si为一个步态序列,将步态序列中的每帧图像作为编码器的输入,通过编码将得到潜在空间中的一个向量,而该步态序列可以转换为潜在空间中的特征向量集合Veci,即

其中E(·)为编码器.使用max函数对潜在空间中的特征向量集合Veci中每个向量计算每一维度上的最大值,从而获得步态序列在潜在空间中的向量表示.为了尽可能保留更多的步态识别信息,训练中使用triplet-loss损失函数最大化具有不同标签的样本之间在特征空间中的距离,而具有相同标签的样本在特征空间中的距离尽可能接近.
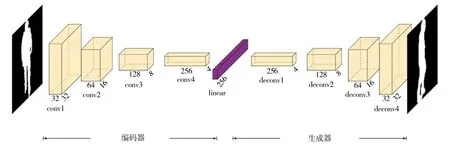
图3 模型结构Fig.3 Model structure
2.2 生成器
生成器目标是将编码器编码后获得的向量集生成固定视角的尽可能真实的步态轮廓图像.生成器由4个反卷积层组成,反卷积操作能够将低维特征向量采样为高维的数据[15],生成器结构如图3右半部分所示.当一个任意视角、任意穿着与携带下的步态图像序列Si输入编码器将得到1组潜在空间中的特征向量Veci,将该组的每一个向量通过生成器生成1张固定视角且正常条件下的二值步态轮廓图像,从而获得1个固定视角下的步态图像序列^Si.
2.3 判别器
判别器主要包括真伪判别器与步态帧连续判别器,主要功能如下:
1)真伪判别器
真伪判别器是由包含4个卷积层和1个全连接层的卷积神经网络构成,它的输出是0到1的值,用于表示输入图像接近于固定视角下真实步态图像的程度.真伪判别器的结构如图4所示.在训练中,真伪判别器每次判断一张图像的真伪和视角,通过判别生成步态序列^S中的每一帧图像是否真实,可以得到一组真伪损失,对该组损失进行平均从而获得步态序列^S的真伪损失.
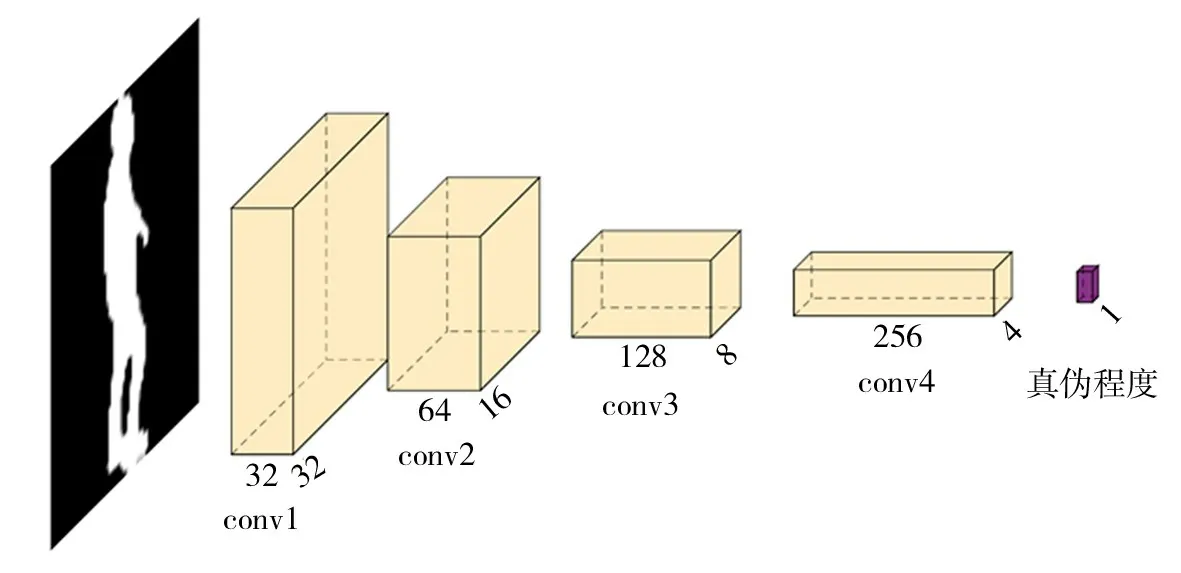
图4 真伪判别器结构Fig.4 Structure of authenticity discriminator
2)步态帧连续判别器
步态帧连续判别器实际上是一个由4个卷积层和1个全连接层的卷积神经网络构成,该网络结构如图5所示.对于此判别器,在训练模型时需要先预先训练.其训练过程是从1个步态序列样本中任意选取3帧步态轮廓图像送入步态帧连续判别器,如果该3帧步态图像在时间顺序上连续,则判别器的输出为真,详细训练过程见算法Dtrain.当完成该判别器的训练后,即可开始训练步态识别模型.也就是说,对于^Si中的每一帧图像,依次判断它是否与前后各帧图像在时间顺序上连续.利用此种方法,对于步态序列将得到一组帧连续损失,然后对这组损失求平均从而得到步态序列的帧连续损失.
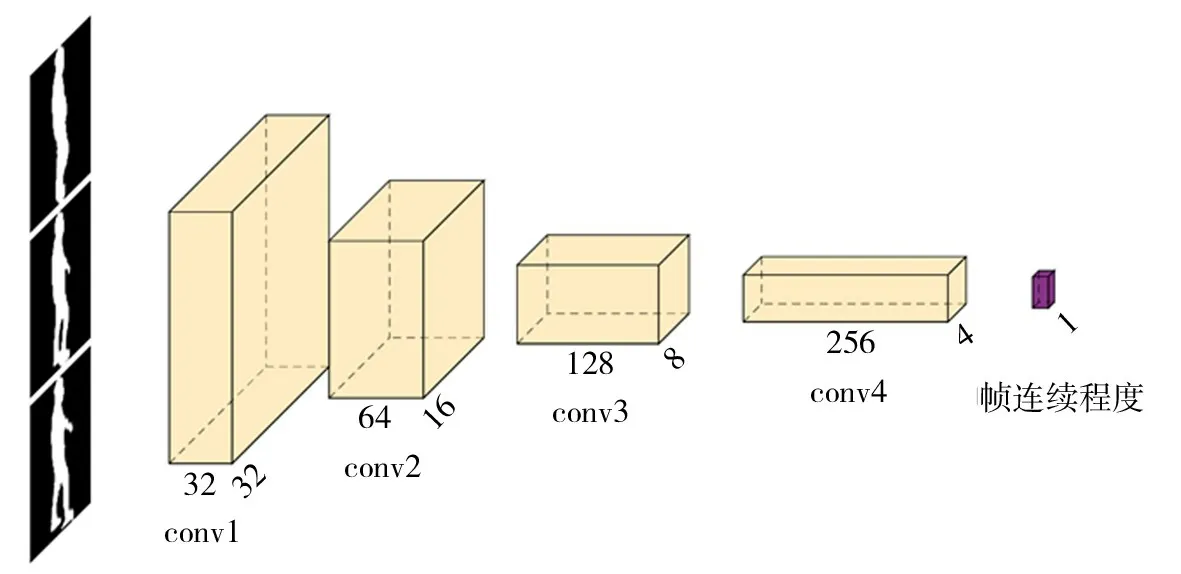
图5 步态帧连续判别器结构Fig.5 Gait frame continuous discriminator structure
步态帧连续判别器算法Dtrain
输入:t=0;初始化步态帧连续判别器参数W;学习率η;训练轮数T;每个样本循环的次数ntimes;D(·)表示步态帧连续判别器.
输出:步态帧连续判别器参数W.

2.4 损失函数
在步态识别模型的训练中,主要涉及2种类型的损失函数,它们分别为编码器产生的Triplet损失和判别器产生的判别损失.
1)Triplet 损失函数
Triplet 损失函数是由Florian等[20]提出,通过合页损失(hinge loss)能够减少所查样本与正例样本间的特征距离,并且增大所查样本与负例样本间的特征距离.模型中使用的triplet 损失函数定义如下:

其中E(·)是编码器,fmax(·)函数为对一组潜在空间中的向量求每一维度上的最大值后形成的向量.
2) 判别损失函数
判别损失来源于2种判别器所产生的损失,一种是由真伪判别器产生的损失,另一种是由步态帧连续判别器所产生的损失.对于2个判别器,它们所产生的损失定义为
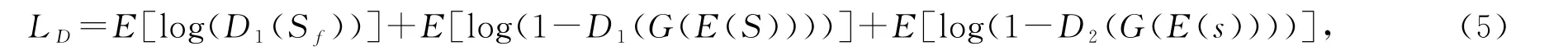
其中G(·)和E(·)分别代表生成器和编码器,D1(·)为真伪判别器,D2(·)为步态帧连续判别器.Sf表示同一行人采集固定视角下的真实步态序列.
步态识别模型的总体损失函数定义为

3 实验研究
3.1 实验数据与方法
为了验证提出方法的有效性,实验中选取了步态数据库CASIA-B与OU-MVLP.Dataset-B数据集由中科院自动化所采集,由124个行人步态样本组成.每个行人的步态样本有3种行走状态,每种行走状态有11个视角.OU-MVLP是一个样本数量较多的步态数据集,包含10 308个行人.通过使用7个不同视角的摄像机对行人采集2次得到14个视角,之后再重复一次共得到288 596条步态图像序列.实验中输入的步态轮廓图像被裁剪成64×64大小,每个步态序列所包含的连续帧数为16.编码器的每层卷积核的大小均为4×4个像素,卷积步长为2,通过一个全连接层将编码器提取的特征投影到256维的潜在空间中.生成器组件则是将利用潜在空间中的特征向量生成步态图像,通过反卷积操作将得到视角转换后的步态图像序列.在步态识别模型的训练中,学习率为10-4,迭代次数为600 000,分类器使用最近邻分类算法.
3.2 实验结果与分析
针对CASIA-B数据集,选取前74个行人样本作为模型的训练集,其余的50个行人样本作为测试集.在测试过程中,取测试集中每个行人正常行走姿态的前4条序列作为标签已知的匹配库样本(即gallery样本),剩余2条正常姿态的序列作为标签未知的待识别样本(即probe样本).数据集包含11种不同视角,将特定视角的匹配库样本和待识别样本进行了交叉组合,共获得121种视角组合.实验过程中分别对正常行走、携带背包行走、穿着大衣行走3种状态的2条行走序列进行识别,以此测试模型的识别准确率.实验结果如表1~3所示,其中表的每一行对应匹配库样本图像的视角,每一列对应待识别样本图像的视角.
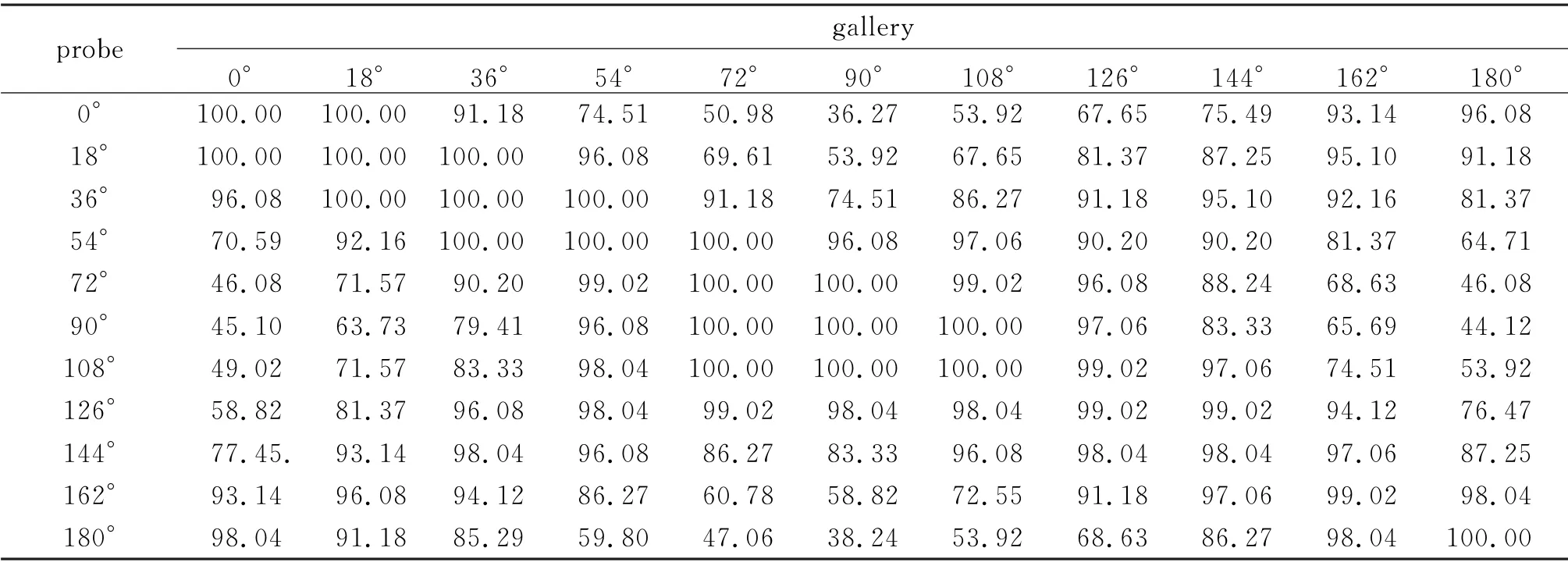
表1 CASIA-B数据集在正常条件下的跨视角识别准确率Tab.1 CASIA-B dataset cross-view recognition accuracy under normal conditions%
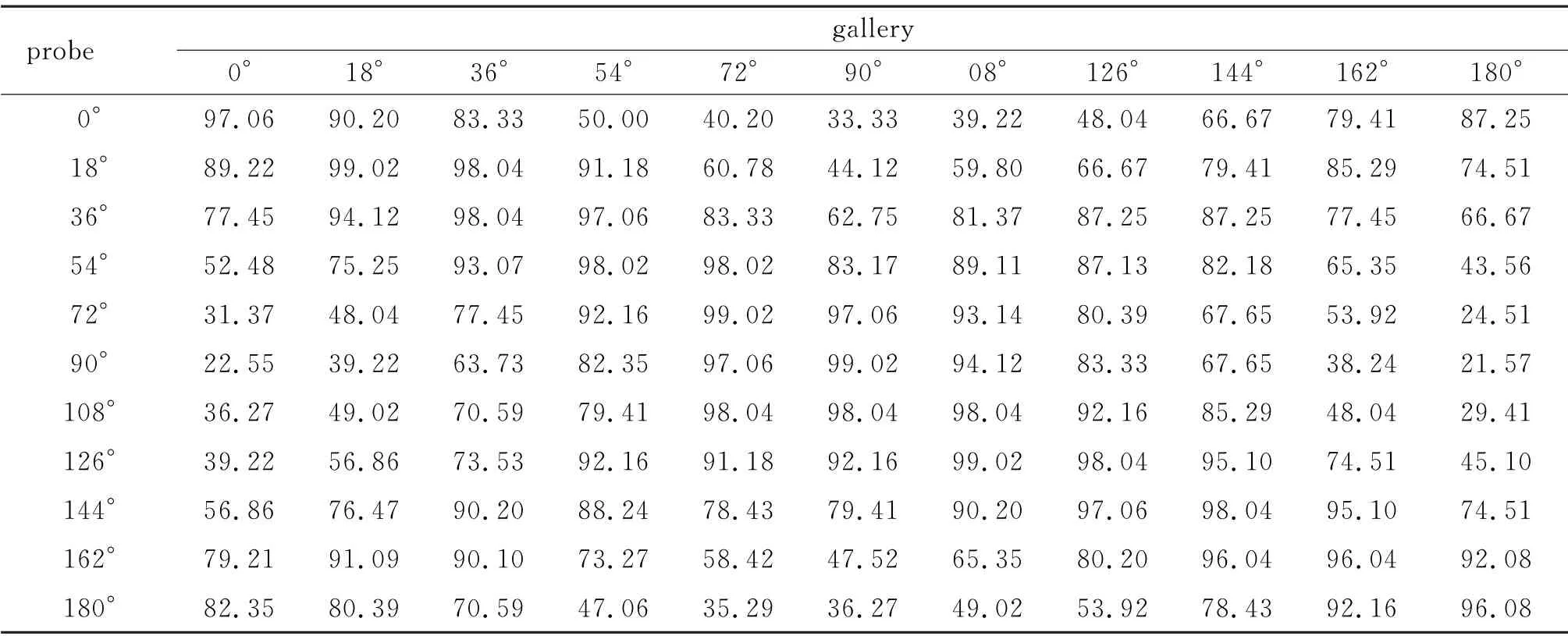
表2 CASIA-B数据集在携带背包条件下的跨视角识别准确率Tab.2 CASIA-B dataset cross-view recognition accuracy under carrying bag conditions%
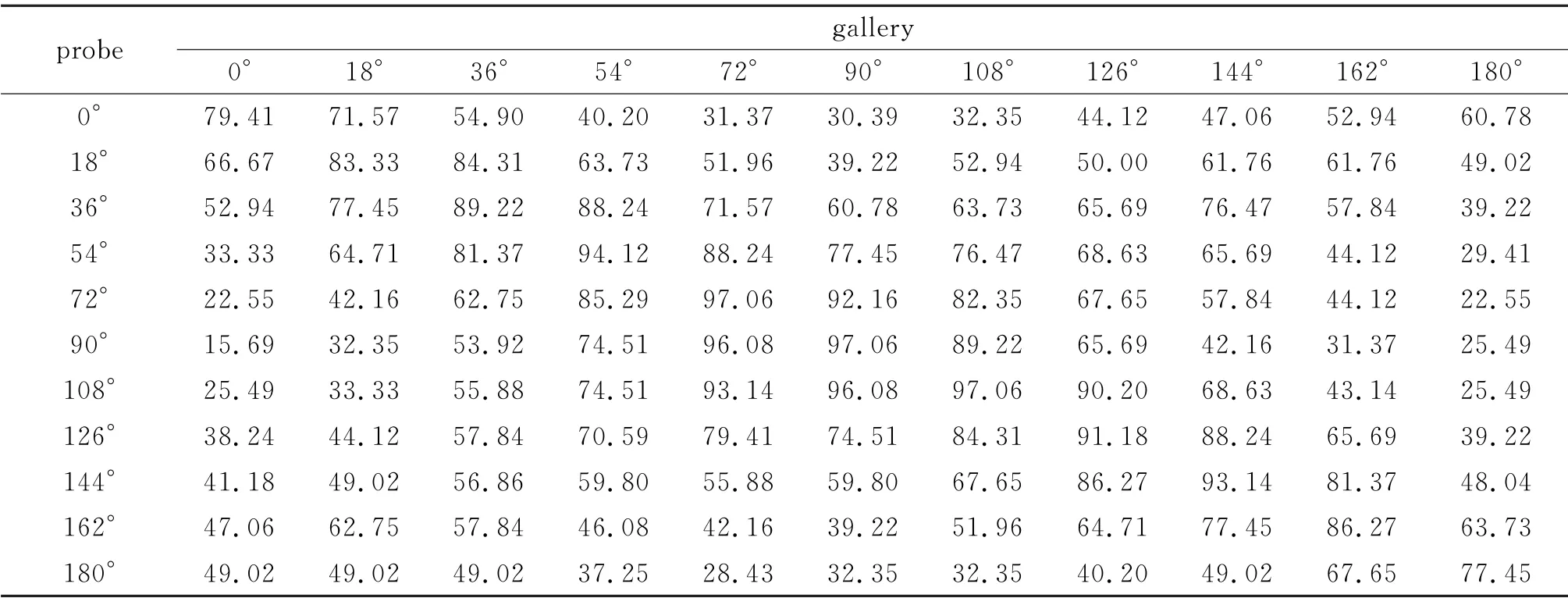
表3 CASIA-B数据集在穿着大衣条件下的跨视角识别准确率Tab.3 CASIA-B dataset cross-view recognition accuracy under wearing cloak conditions%
对于OUMVLP数据集,将前5 153个样本作为模型的训练集,剩余的5 154个样本作为测试集.在测试过程中,将编号为00的步态图像序列作为标签已知的匹配库样本(gallery样本),编号为01的步态图像序列作为标签未知的待识别样本(probe样本).通过将数据集中14种不同视角进行交叉组合得到196种视角的组合.实验结果如表4所示.
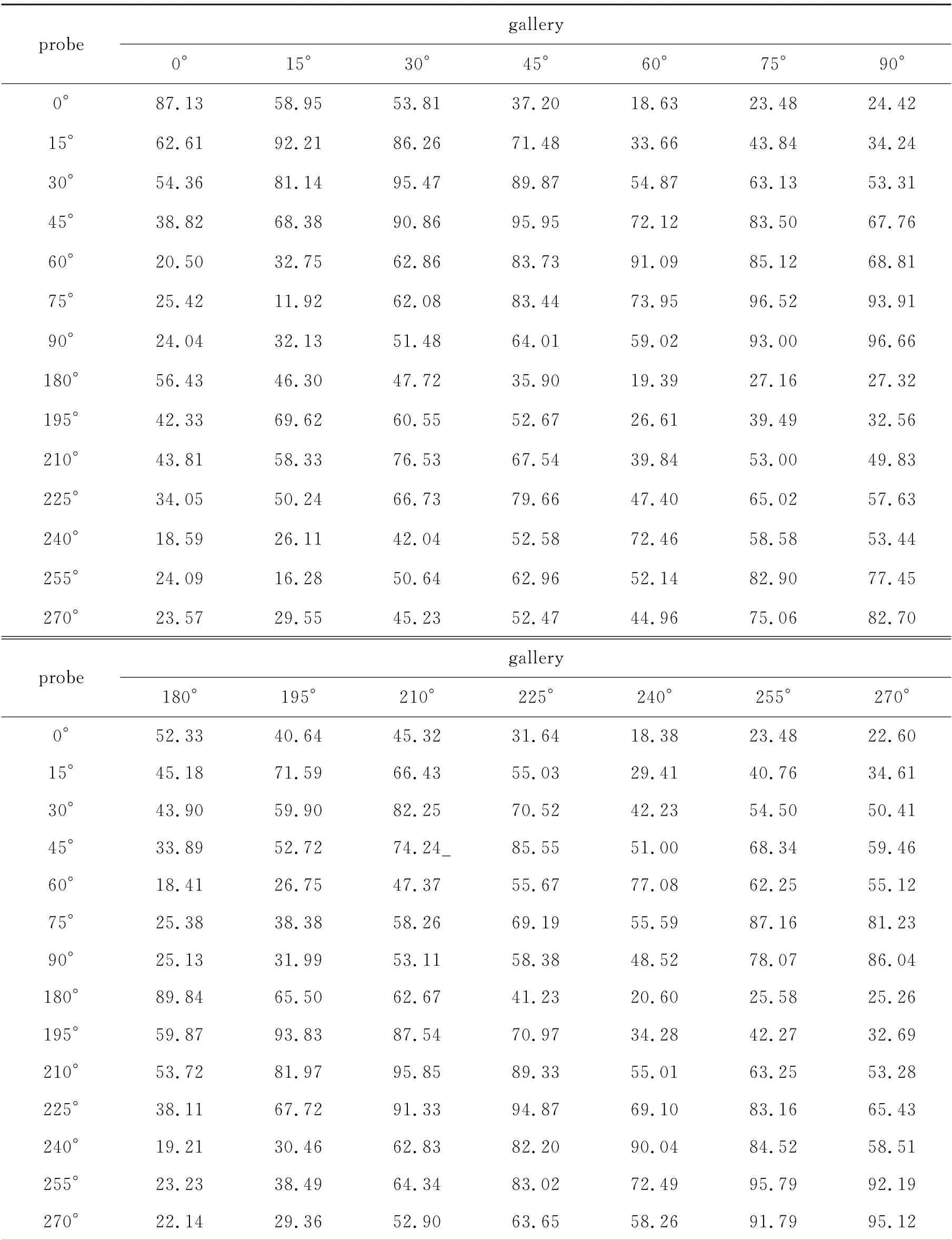
表4 OU-MVLP数据集的识别准确率Tab.4 Recognition accuracy of OU-MVLP dataset%
由表1~4可以看到,当步态视角为90°时,获得了较高的识别率,在表1~4 中它们分别为100%、99.02%、97.06%和96.66%.
同时针对CASIA-B数据集对提出的模型进行了比较实验,实验中使用前62个行人样本作为模型的训练集,剩余样本作为测试集.与Gait GAN[11]、MGANs[21]和SPAE[22]方法进行了对比,实验结果如表5所示,其中每行数据为Gallery集中0~180°的每个视角与Probe中0~180°所有视角下识别准确率的平均值.
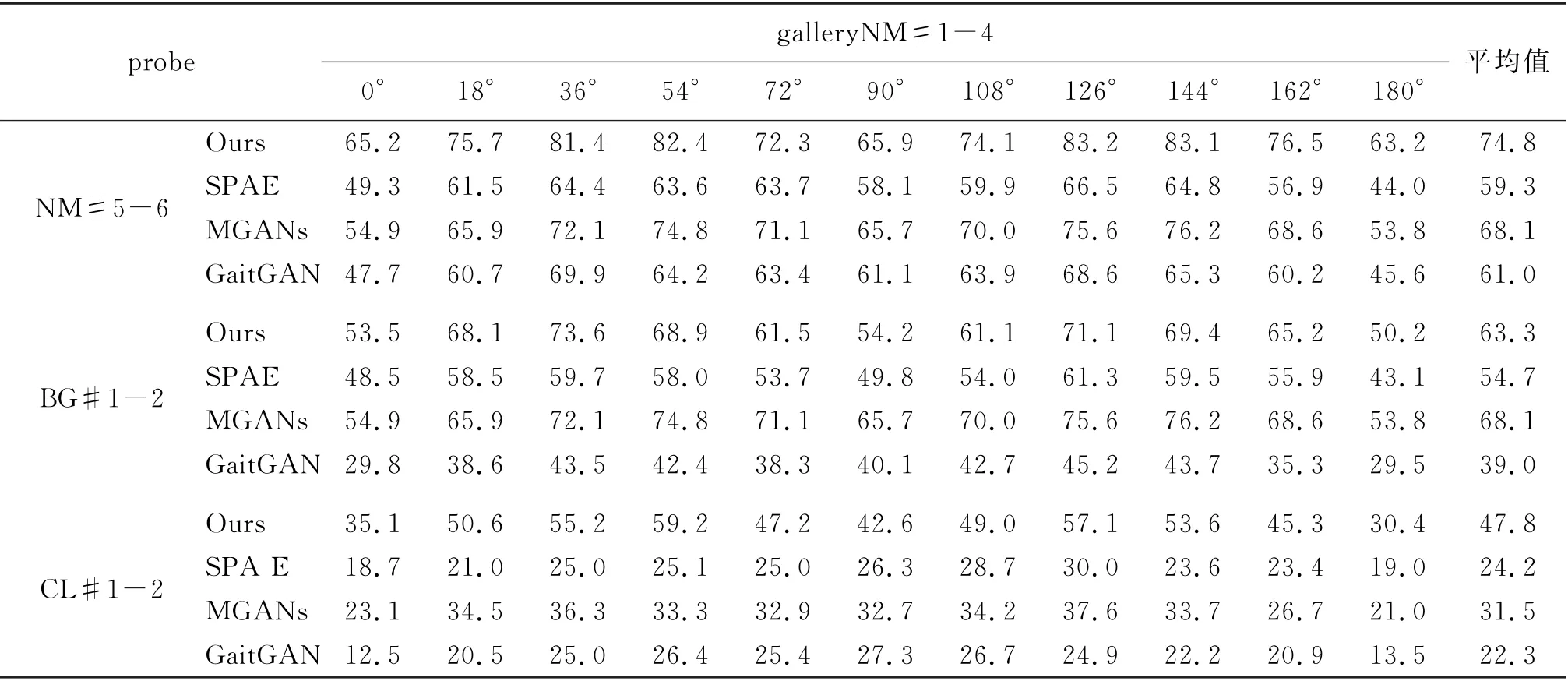
表5 不同方法的比较Tab.5 Comparison of different methods%
实验结果表明,在正常行走和穿着大衣行走的条件下,提出的方法其识别率高于GaitGAN、MGANs和SPAE 3种方法;而在携带背包条件下,提出的方法其识别率高于Gait GAN 和SPAE 2种方法,且略低于MGANs方法.
4 结论
针对跨视角步态识别问题,提出了一个步态识别模型,将步态序列作为模型的输入,通过使用真伪损失和连续帧判别损失,利用生成器生成视角转换后的连续步态序列,迫使编码器提取含有时间信息且不随视角改变的步态特征.同时引入triplet-loss损失函数,使得不同样本在潜在空间中的嵌入具有更好的可区分性.在识别时,将待识别行人的步态序列通过编码器提取一组潜在空间上的特征向量,将这组向量在每个维度求极大值得到能够表示行人步态序列的一个特征向量,并使用最近邻方法得到Probe样本的标签,通过实验验证了提出的方法在CASIA-B和OU-MVLP数据集上的有效性,并且在步态条件改变时具有一定的鲁棒性.
